【1】Anaconda基本命令以及相关工具:jupyter、numpy、Matplotilb
目录
一、Anaconda
◼ anaconda命令行操作
二、jupyter notebook
1 jupyter的基础使用
◼ jupyter的启动
◼ ipynb文件的新建、重命名、删除
◼ 菜单说明
◼ 运行cell单元块
◼ 编写文档笔记
2 jupyter的高级使用:常用魔法命令
◼ writefile pycat run
◼ timeit time
◼ whos lsmagic magic
三、Numpy
1 Numpy基础:安装与性能对比
◼ 导入Numpy
◼ Numpy与原生Python的性能对比
2 Numpy数组创建:特定数组、等差数组、随机数组
◼ 创建数组以及Numpy数组的属性
◼ 创建等差数组
◼ 创建随机数组
一、Anaconda
◼ anaconda命令行操作
conda -V # 查看版本
conda update conda # 更新软件包
conda env list # 查看当前存在哪些虚拟环境
conda create -n your_env_name python=X.X # 创建虚拟环境
conda activate your_env_name # 激活虚拟环境
conda deactivate # 退出虚拟环境
conda remove -n your_env_name --all # 先退出虚拟环境,再删除虚拟环境以及其各种依赖包
conda list # 查看当前安装的依赖包
conda install package_name # 安装依赖包
conda search package_name # 搜索依赖包的版本
conda uninstall python_pakage # 卸载依赖包
conda remove --name your_env_name package_name # 卸载某个虚拟环境中的依赖包
二、jupyter notebook
Jupyter Notebook 是一款开源 Web 应用程序,可用于创建和共享包含实时代码、方程式、可视化和文本的文档。Jupyter 附带 IPython 内核,允许使用 Python 编写程序,但目前还有 100 多个其他内核可供使用。
(1)首先说一下交互式,
jupyter notebook中一个非常重要的概念就是cell,每个cell能够单独进行运算,这样适合于代码调试。
我们开发一个完整的脚本时变量会随着代码执行的结束而从内存中释放,如果我们想看中间的变量或者结构,我们只能通过断点或者输出日志信息的方式进行调试,这样无疑是非常繁琐的,如果一个程序运行很多这种方式还可行,如果运行时间长达几个小时,这样我们调试一圈耗费的时间就太长了。
而在jupyter notebook中我们可以把代码分隔到不同的cell里逐个进行调试,这样它会持续化变量的值,我们可以交互式的在不同cell里获取到我们想要测试的变量值和类型。
(2)然后说一下富文本,
开发代码不仅是给机器去“阅读”,也需要让其他的同事、同学能够很容易的阅读,因此,注释就在开发过程中变的非常重要,一个完善的注释能够让周围人更加容易理解,协作效率也更高,避免重复性劳动。在大多数IDE中都可以进行注释,但是几乎都是相同的,只支持一些简单的文本格式注释,这显然是不够的,jupyter notebook支持Markdown编辑,它的cell不仅可以用于编码,还可以用于书写文本,Markdown可以轻松完成标题、数学公式等格式的编辑,更加有助于解释代码,适用于教学等场景。
(3)最后在说一下轻量、触手可及,
开发过程中我经常需要测试一个小的代码块或者函数,这时候有两个选择:
- 在IDE中新建一个测试脚本;
- 打开命令行下的Python。
我觉得这两个都不是好的选择,如果在项目下新建一个脚本后续还需要记住把它清理掉,如果写一个完善的测试脚本用于Alpha、beta测试这显然是低效不现实的。而选择在命令行下,界面不友好,操作不灵活,体验更差。
这时候就显现出jupyter notebook的优势,只需要输入jupyter notebook就会在流量器中打开一个网页,能轻量、快捷的进行开发验证,效率很好。
此外,我们还可以通过搭建jupyter notebook服务使得它一直在服务器下运行来避免每次需要时都要在命令行下重复打开,我们只需要在浏览器打开对应的网页即可,这一点下文会详细介绍。
(4)其实,除了这些我们耳熟能详的优点之外,jupyter还有很多令人惊叹的亮点:
- 丰富的插件
- 主题修改
- 多语言支持
1 jupyter的基础使用
◼ jupyter的启动
命令行输入命令jupyter notebook,
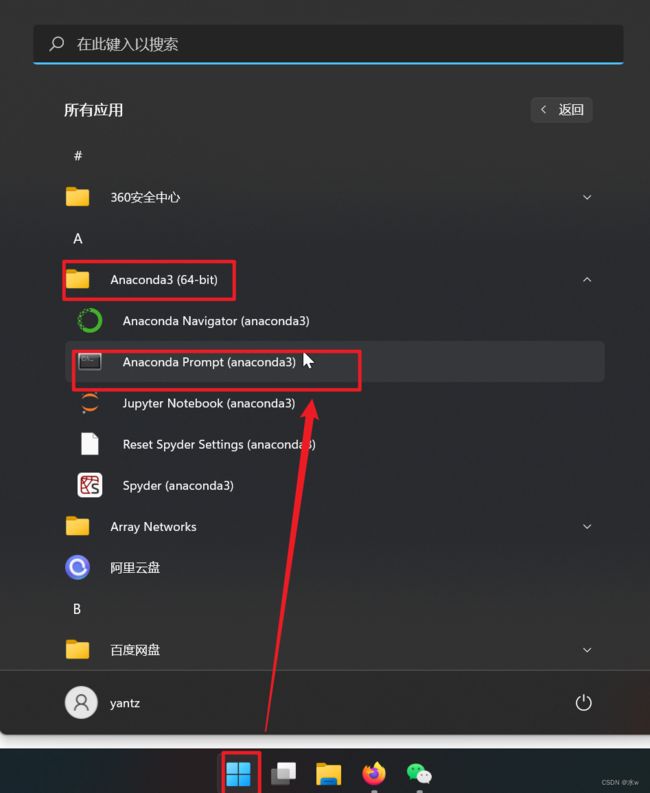
conda install jupyter notebook # 安装jupyter notebook内核
jupyter notebook # 输入之后回车:启动jupyter notebook
# Ctrl + c:关闭jupyter notebook或者直接点击“jupyter notebook”,也可以进入,

◼ ipynb文件的新建、重命名、删除
启动 Notebook 服务器之后就可以开始创建笔记了。
在base下的jupyter notebook换好文件夹之后打开如下,会弹出一个新的网页选项卡。
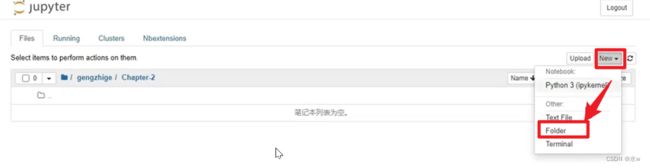
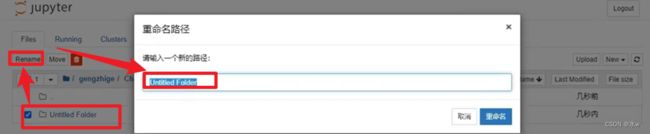
页面顶部是Untitled一词,这是页面的标题和笔记本的默认名称,是可以修改的。

◼ 菜单说明
- -『File』,可以创建一个新的笔记本或打开一个预先存在的笔记本。这也是重命名笔记本的地方。菜单项 Save and Checkpoint 这允许创建可以在需要时回滚的检查点。
- - 『Edit』,剪切、复制和粘贴单元格内容。也可以删除、拆分或合并单元格,也可以在此处重新排序单元格。此菜单中的某些项目是灰色的,原因是它们不适用于当前选定的单元格。
- - 『View』,用于切换标题和工具栏。还可以打开或关闭单元格内的行号。
- - 『Insert』,插入菜单仅用于在当前选定单元格的上方或下方插入单元格。
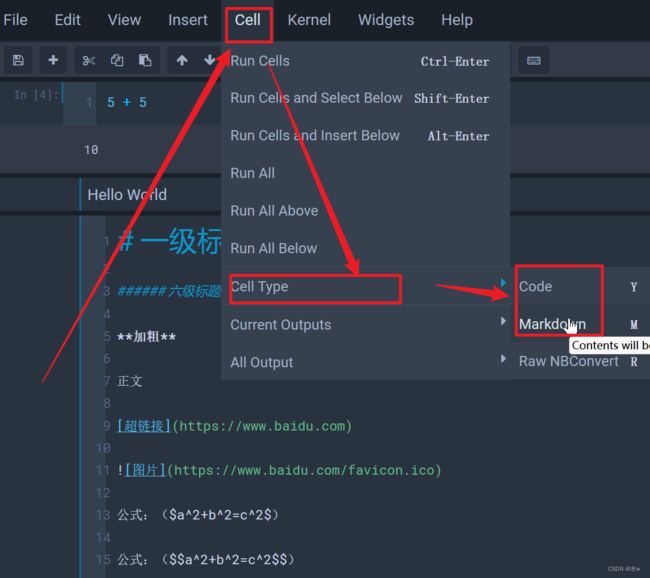
- - 『Cell』,允许运行一个单元、一组单元或所有单元。也可以在这里更改单元格的类型。另一个方便的功能是能够清除单元格的输出。如果打算与其他人共享的笔记可能需要先清除输出,以便下一个人可以自己运行单元格。内核单元用于处理在后台运行的内核,可以重新启动内核、重新连接、关闭,甚至更改的 Notebook 正在使用的内核。
- - 『Kernel』,在调试笔记本时会发现需要重新启动内核。
- - 『Widgets』,小部件菜单用于保存和清除小部件状态。小部件基本上是JavaScript小部件,可以将其添加到单元格中,以使用 Python(或其他内核)制作动态内容。
- - 『Help』,可以了解 Notebook 的键盘快捷键、用户界面导览和大量参考资料。
选项卡操作注意:使用 Jupyter 的时候切记不要关闭 shell 命令行窗口,关闭时需要确保数据已经保存。
◼ 运行cell单元块
(1)运行代码单元:将代码添加到该单元格,点击上方的“Run”,或者可以使用 Shift+Enter 执行。
运行单元格时单元格左侧的 [n] 。方括号将自动填充一个数字,该数字指示运行单元格的顺序。例如打开一个新笔记本并运行笔记本顶部的第一个单元格,则方括号将填充数字1。

(1) 执行当前ipynb文件中的所有cell,

◼ 编写文档笔记
Jupyter Notebook 支持 Markdown,是一种标记语言,是 HTML 的超集。
(1)选择“Markdown”,将新单元格设置为 Markdown,然后将以下文本添加到单元格中。

(2)输入“Hello World”,按住shift + enter执行,以文档形式呈现,
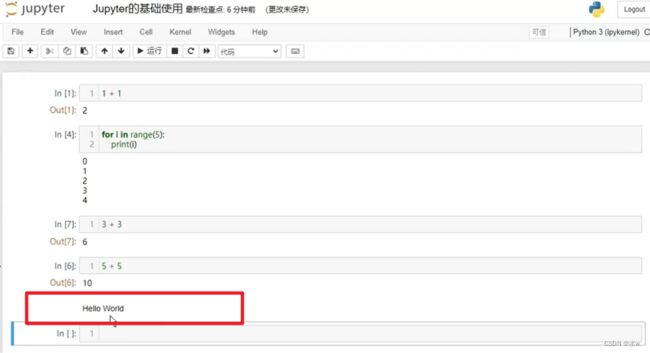
(3)其他格式:
- 正文:什么都不加;
- 标头:使用 # 创建标题,也可以用于区分目录层级;
- 加粗:**;
- 创建列表:使用破折号(-)、加号(+)或星号(*)来创建列表;
- 超链接:[]
- 图片:!
- 行内公式:$
- 独立公式:$$

执行结果,
(4)如果我们想把它变成单元块,只需要修改cell的type就可以了。
2 jupyter的高级使用:常用魔法命令
◼ writefile pycat run
%%writefile保存cell内容到外部文件。
%pycat正好相反,导出单元格的内容/显示外部脚本的内容。
%run,执行python代码。
(1)%%writefile方法可以将脚本代码写入本地Py文件。
将当前cell的所有内容输出到指定的文件中,
%%writefile test.py
def Test(name):
print("Test", name, "success")

(2)
%pycat test.py可以看到,jupyter在下面将我们刚写好输入到文件中的内容显示出来了,

(3)%run,在notebook中可以直接执行Py文件,通过%run方法来实现。
%run test.py
Test("Jupyter")![]()
还有一些其他调用方法,

◼ timeit time
%time或%timeit:计算当前行的代码运行时间。
%time的计算结果包括:CPU time(CPU运行程序的时间), Wall time(Wall Clock Time,墙上挂钟的时间,也就是我们感受到的总的运行时间)。%timeit:计时更为精确,这一命令会运行代码 r 次,每次 n 遍,再对 n*r 遍的结果取平均后,得到运行一遍代码的时间。
- 会根据执行代码的不同,动态调整设定次数
(1)可能你的代码需要精确的时间控制,如果要评估单条语句的运行时间,那么%timeit方法可以帮到你,
![]()
(2)如果要评估整个cell的运行时间,需要使用%%timeit,

(3)timeit会根据执行代码的不同,动态调整设定次数。那么我们如果不想测那么多次,只测一次就可以了, 我们需要把timeit改成time就可以了,而且用法与timeit一样。

◼ whos lsmagic magic
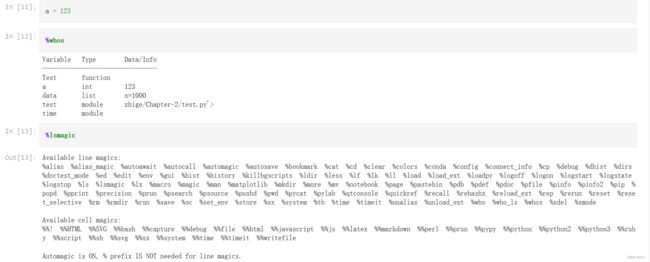
(1)whos可以将前面引入的包、定义的函数和变量都打印出来,同时可以看到其对应的值。
(2)如果我们想查询更多的魔法命令,可以输入%lsmagic 执行 。
(3)如果想要看具体的魔法命令,可以输入%magic 执行。
三、Numpy
Python 库 ——
NumPy,是 Python 科学计算的基本包,几乎所有用 Python 工作的科学家都利用了的强大功能。此外,它也广泛应用在开源的项目中,如:Pandas、Seaborn、Matplotlib、scikit-learn等。
1 Numpy基础:安装与性能对比
◼ 导入Numpy
import的时候没有出现任何报错信息,说明运行成功了。

◼ Numpy与原生Python的性能对比
数组x是由 1~n数字组成,我们求数组x的中所有数的平方之和。
n = 1000000
(1)先用Python原生语法实现,求数组x的中所有数的平方之和。

(2)Numpy实现,求数组x的中所有数的平方之和。

(3)Numpy与原生Python的性能对比:
- Python本身含有列表和数组,由于列表的元素可以是任何对象,因此列表中所保存的是对象的指针。对于数值运算来说这种结构比较浪费内存和CPU资源。
- Numpy中的np.arange会限制数据的类型,这样的好处是在处理数据时会更高效;
- 显而易见,numpy的运行所耗费的时间远远小于python,当然数量级越大这种差别就体现的越明显;
2 Numpy数组创建:特定数组、等差数组、随机数组
◼ 创建数组以及Numpy数组的属性
Numpy中定义的数组叫
ndarray,n-dimensions-array 即:n维数组。ndarray是存储单一数据类型的多维数组。
(1)用np.array()函数可以创建数组,
a就是数组,也是numpy.ndarray类对象,该类定义了几个常用的属性:
-
ndarray.ndim:维度的数量,二位数组ndim是 2; -
ndarray.shape:表示数组的形状,每位代表该维度上元素个数; -
ndarray.size:数组中元素总个数; -
ndarray.dtype:返回数组中元素的数据类型; -
ndarray.itemsize:数组中元素存储大小(以字节为单位);
a = np.array([[1,2,3], [4,5,6]]) # 创建ndarray数组
a # 输出数组
array([[1, 2, 3],
[4, 5, 6]])
a.ndim # 维度的数量
2
a.shape # 每位代表该维度上元素个数,元组长度
(2, 3)
a.size # 数组中元素总数
6
a.dtype # 数组中元素的数据类型
dtype('int64')
a.itemsize # 数组中元素存储大小(以字节为单位)
8(2)创建数组的便捷函数,
除了创建数组外,还有下面的方式创建数组,
"""创建以1填充的数组"""
np.ones(2) # 以1填充的一维数组
array([1., 1.])
np.ones((2,3)) # 以1填充的二维数组,默认创建浮点型数据类型float64
array([[1., 1., 1.],
[1., 1., 1.]])
a = np.ones(8,dtype='int64') # 以1填充的二维数组,指定创建整型数据类型
array([1, 1, 1, 1, 1, 1, 1, 1])
np.ones_like(a) # 创建与a形状完全相同的二维数组
array([1, 1, 1, 1, 1, 1, 1, 1])
"""创建以0填充的数组"""
np.zeros(2) # 以0填充的一维数组
array([0., 0.])
a = np.zeros((2,3)) # 以0填充的二维数组
array([[0., 0., 0.],
[0., 0., 0.]])
np.zeros_like(a) # 创建与a形状完全相同的二维数组
array([[0., 0., 0.],
[0., 0., 0.]])
"""创建空的数组"""
np.empty(8) # 空的二维数组,内容为当时内存中的值
array([2.05186965e-316, 0.00000000e+000, 2.41907520e-312, 2.44029516e-312,
2.29175545e-312, 2.27053550e-312, 8.48798317e-313, 8.70018275e-313])
a = np.empty((2,4))
array([[2.05186965e-316, 0.00000000e+000, 2.41907520e-312,
2.44029516e-312],
[2.29175545e-312, 2.27053550e-312, 8.48798317e-313,
8.70018275e-313]])
np.empty_like(a)
array([[2.05186965e-316, 0.00000000e+000, 2.41907520e-312, 0],
[2.29175545e-312, 2.27053550e-312, 0, 0]])
"""创建full填充的数组"""
np.full(8,666) # 创建666填充的数组
array([666, 666, 666, 666, 666, 666, 666, 666])
a = np.full((2,4),666)
array([[666, 666, 666, 666],
[666, 666, 666, 666]])
np.full_like(a, 666) # 创建与a形状完全相同的二维数组
array([[666, 666, 666, 666],
[666, 666, 666, 666]])◼ 创建等差数组
"""创建等差数组"""
np.arange(6) # 创建等差数组,用法跟range函数一样
array([0, 1, 2, 3, 4, 5])
np.arange(1,10,2) # 创建等差数组,起始为1,终止为10,步长为2(默认为1)
array([1, 3, 5, 7, 9])
np.arange(10).reshape(2,5) # reshape改变数据的形状为2行5列
array([ 0. , 2.5, 5. , 7.5, 10. ])
np.linspace(0, 10, num=5) # 创建等差数组,以指定的线性间隔为初值,在0~10(包含)的范围区间内一共生成5个数
array([ 0. , 2.5, 5. , 7.5, 10. ])◼ 创建随机数组
"""创建随机数数组"""
# random
np.random.random() # 返回0~1(不包含)之间的随机数
0.6160962522468241
np.random.random(5) # 返回5个0~1(不包含)之间的随机数
array([0.84127341, 0.48222372, 0.90828922, 0.36954664, 0.22532067])
np.random.random((2,4)) # 返回2行4列个0~1(不包含)之间的随机数
array([[0.27181514, 0.15703565, 0.31419621, 0.08382473],
[0.54159785, 0.63871858, 0.66251797, 0.62471311]])
rng = np.random.default_rng(0) # 以随机数创建二维数组
rng.random((2,3))
array([[0.63696169, 0.26978671, 0.04097352],
[0.01652764, 0.81327024, 0.91275558]])
# rand
np.random.rand() # 返回0~1(不包含)之间的随机数
0.8774587965932436
np.random.rand(5) # 返回5个0~1(不包含)之间的随机数
array([0.13384554, 0.21306594, 0.30306473, 0.18566478, 0.69966918])
np.random.rand(2,4,3) # 三维数组,0~1(不包含)之间的随机数
array([[[0.59717132, 0.00826123, 0.29273091],
[0.37695511, 0.47300885, 0.4161377 ],
[0.10521003, 0.45477703, 0.38927769],
[0.96095509, 0.52454654, 0.55049337]],
[[0.79916878, 0.03631291, 0.93487382],
[0.251527 , 0.42738936, 0.8647998 ],
[0.32140807, 0.06587076, 0.72579955],
[0.1023671 , 0.05277878, 0.64963486]]])
# randint
np.random.randint(5) # 返回0~5(不包含)之间的随机整数
1
np.random.randint(5,10) # 返回5(包含)~10(不包含)之间的随机整数
9
np.random.randint(5,10,size=8) # 返回8个5(包含)~10(不包含)之间的随机整数
array([6, 5, 5, 5, 6, 9, 6, 6])
np.random.randint(5,10,size=(2,4)) # 返回2行4列的5(包含)~10(不包含)之间的随机整数数组
array([[8, 6, 5, 7],
[9, 5, 9, 9]])
# seed
np.random.seed(666) # 设置随机种子,传入666
np.random.randint(5,10,size=(2,4)) # 多运行几次,可以看到每次运行的结果都会一样
array([[9, 7, 6, 9],
[8, 8, 9, 9]])
# randn:返回具有标准正态分布的随机数,标准差为1
np.random.randn(5) # 返回5个具有标准正态分布的随机数的一维数组
array([ 0.01902826, -0.94376106, 0.64057315, -0.78644317, 0.60886999])
np.random.randn(2,4) # 返回2行4列个具有标准正态分布的随机数二维数组
array([[-0.93101185, 0.97822225, -0.73691806, -0.29873262],
[-0.46058737, -1.08879299, -0.57577075, -1.68290077]])
# normal
np.random.normal() # 默认均值为0,方差为1的随机数
0.2291852477040214
np.random.normal(10,100,20) # 设置均值为10,标准差为1000,生成20个数
array([-165.66252234, 94.46326187, 37.72198634, 95.2901533 ,
29.4599603 , 141.06377157, 164.38436001, -42.90480243,
-55.64722973, -10.15057011, -60.06158328, 78.71379544,
7.39242436, -72.97583197, 39.65537839, -21.26795036,
-51.13012744, -72.17515048, 99.71227031, 23.60786118])
np.random.normal(10,100,size=(4,5)) # 设置均值为10,标准差为1000,生成4行5列个数
array([[ -15.86548011, 121.07656409, -8.84243873, 5.85107071,
-88.47919123],
[-125.22817585, 29.43238455, 36.72393512, -32.64736981,
154.77350574],
[ -9.63061002, 161.814514 , 17.72218828, 3.60086759,
104.59234072],
[ 130.40910055, -35.12407353, -148.74465098, -176.88554809,
20.03773732]])# uniform:返回具有均匀分布的随机数
np.random.uniform() # 返回具有均匀分布的0~1之间(左闭右开)的随机数
0.5018935081312759
np.random.uniform(1,5) # 生成具有均匀分布的1~5之间(左闭右开)的随机数
2.993092519645257
np.random.uniform(1,5,(3,4)) # 生成3行4列个具有均匀分布的1~5之间(左闭右开)的随机数
array([[1.4150861 , 2.78577246, 4.87675667, 3.95388449],
[3.87820243, 4.57217355, 4.85069873, 1.78820091],
[3.85835986, 1.64769576, 4.46501909, 3.49528099]])如果我们忘记了uniform函数功能,我们可以使用该条代码来查看详细的文档,具体参数的含义,下面还有例子。
np.random.uniform?如果不喜欢弹出的方式查看文档,我们也可以使用help。
help(np.random.uniform)