根据历史数据预测未来数据_如何利用以往的营销数据来预测未来营销的结果?...
全文共 12174字,预计学习时长 25分钟甚至更长

摄影|Anika Huizinga图源|Unsplash
本文将为大家讲解如何针对数字营销中的广告曝光量来构建、训练以及评估预测模型。其中所有的技术都可用于解决其他回归问题,尤其是预测不同的性能指标,比如在产品上市前预估市场未来的销售状况,亦或者选定最佳参数,好比营销中的时间表或预算大小等。
用Python编写代码时,可以使用自己的营销数据或提供的数据集。除了所有源代码,本文还要给大家介绍一款简单好用的App,它能在买卖营销市场中预测广告曝光量、点击量以及产品交易的情况。
App获取: https://predictor.stagelink.com/
代码说明: https://github.com/kinosal/predictor

概述
1.要求
2.确立目标
3.准备数据集
4.初步浏览
5.数据预处理
6.训练模型
7.评估模型
8.预测下一轮竞争结果
9.福利:训练过的即用模板
要求
利用以往的营销数据来预测未来营销的结果时,通常来讲,数据越多(即营销次数越多),预测结果就会越准确。准确的数据有赖于同性质的营销活动,不出意外的话会需要至少几百次的营销实例。此外,由于预测自己期望的未来营销结果时会应用到监督式学习技术,所以输入的内容要保持一致,即这些营销的规模和特征需相同。
如果现在没有合适的即用数据集也不要紧:可以下载一份含有本文提到的数据样本的CSV文件。
文件下载:https://github.com/kinosal/predictor/blob/master/model/impressions.csv
确立目标
说到成功的营销或营销业绩,我们真正关注的是什么?很明显,答案取决于特定的境况。本文会试着去预测单个营销活动的广告曝光量,同样,客户点击量及交易额也可预测出来,以便构成经典的漏斗式营销模型:
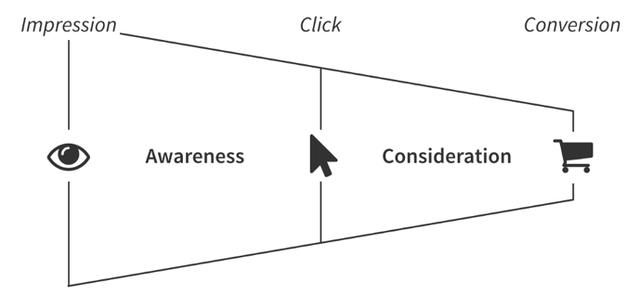
准备数据集
这里提供了一份表格,横向数据表示每次的活动信息,每列表示不同的方面,其中不只有想要预测的非独立变量,也包括独立变量和一些特征:
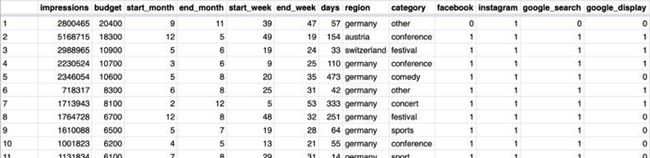
因为想要预测的营销活动尚未开始,所以在这种情况下,不会涉及任何性能数据,有的只是一些可观察到的特质。通常在事先不知道什么样的特征适合进行预测的情况下,本文推荐大家也去使用那些看起来与活动联系非常小的变量,再花些时间寻找或构建新的特征。尽管有些声音表示要减少特征的参考,但特征在之后的步骤中还是会经常用到的。
大家可以下载CSV文件,通过下列简单的函数操作将其存到一个Pandas数据框架中:
import pandas as pddata = pd.read_csv('impressions.csv')初步浏览
在构建或训练预测模型之前,笔者都会先浏览一下数据,了解要处理的内容是哪方面的,辨识出的特性有哪些。样本数据可用来预测某一营销活动的广告曝光量,因为“曝光.csv”文件中每一活动都对应的有一行数据,其中各自的曝光量、度量标准以及不同类别的特征都可用来预测未来营销的曝光量。为了证实这一点,加载数据,呈现其数据形态,以及文件的前五行内容:
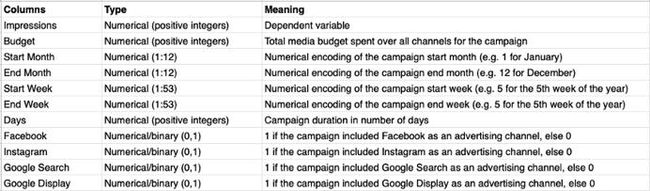
>>> data.shape(241, 13)>>> data.columnsIndex(['impressions', 'budget', 'start_month', 'end_month', 'start_week', 'end_week', 'days', 'region', 'category', 'facebook', 'instagram', 'google_search', 'google_display'], dtype='object')>>> data.head(5)impressions budget start_month ... google search google_display9586 600 7 ... 1 0...第一列是非独立变量(即将预测的)——“曝光量”,文件总共有12列乘241行的内容。使用data.describe()函数可以计算出每个度量列的和、平均值、标准差、取值范围以及四分位数。
进一步观察会发现,我们处理的是十个数字特征和两个分类特征,其中有四个数字列都是二进制的:
现在要绘制出数字特征的直方图,该过程会借助两个非常便于操作的可视化数据库:Matplotlib和Seaborn(后者基于前者而建立):
import matplotlib.pyplot as pltimport seaborn as snsquan = list(data.loc[:, data.dtypes != 'object'].columns.values)grid = sns.FacetGrid(pd.melt(data, value_vars=quan), col='variable', col_wrap=4, height=3, aspect=1, sharex=False, sharey=False)grid.map(plt.hist, 'value', color="steelblue")plt.show()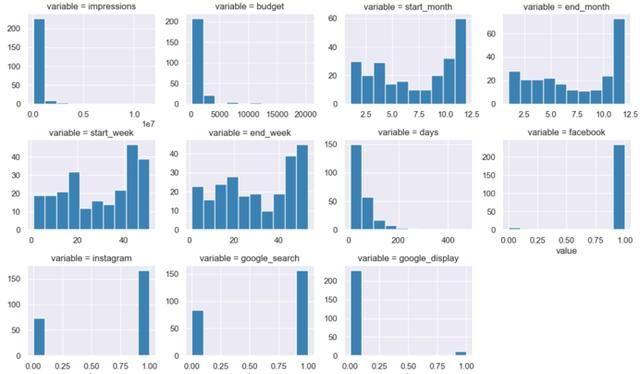
最后浏览一遍数字特征间的线性关系。首先,我们先来通过Seaborn热图将这些关系可视化:
sns.heatmap(data._get_numeric_data().astype(float).corr(), square=True, cmap='RdBu_r', linewidths=.5, annot=True, fmt='.2f').figure.tight_layout()plt.show()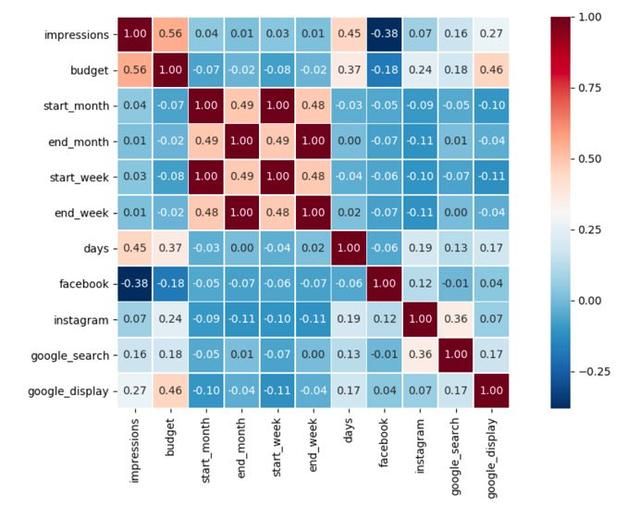
此外,利用非独立变量也可以输出每个特征的关联性:
>>> data.corr(method='pearson').iloc[0].sort_values(ascending=False)impressions 1.000000budget 0.556317days 0.449491google_display 0.269616google_search 0.164593instagram 0.073916start_month 0.039573start_week 0.029295end_month 0.014446end_week 0.012436facebook -0.382057看到这,可以发现曝光量与预算大小和营销持续时间成正相关,与利用脸书而选择的二进制成反相关。不过,这只展示了成对的线性关系,只能作为粗略的初步观察结论。
数据预处理
在构建预测模型之前,需要确保数据都是需要的,而且是可用的,这里体现的就是“垃圾进,垃圾出”的理念。
很幸运,提供的数据集结构都相当好。尽管如此,依然需要以最快的速度进行一系列的预处理操作,来面对到来的挑战:
1.只保留非独立变量大于零的行,因为我们只想要大于零的预测结果(理论上讲,值等于零是有可能的,但对我们的预测起不到任何作用)。
2.检查缺失数据的列,决定是放弃这些空格还是进行补救。如果丢失的数据多于50%,就放弃这一列,因为这些特征对模型不会起到多少参考价值。
3.检查丢失数据的行,决定是要放弃还是填补空格(并不会借助于样本数据)。
4.将特殊类别的数据值都放入到“另一个”库中,以防模型对于这类特殊状况出现过度拟合的情况。
5.因为即将使用的模型必须具备数值输入,所以要将类别数据编码成独热哑变量(one-hot dummy variables)。编码的方式多种多样,本文也给有兴趣深入学习的人提供了比较完善的概述。
6.详列出非独立变量和独立变量的矩阵。
7.将数据集拆分成训练部分和测试部分,以便在训练过后合理地评估模型的拟合优度。
8.根据模型的需要对功能进行缩放。
下面是预处理中会用到的完整代码:
import pandas as pdfrom sklearn.model_selection import train_test_splitfrom sklearn.preprocessing import StandardScalerdef data_pipeline(data, output): """ Preprocessing pipeline part 1: Transform full data frame Arguments: Pandas dataframe, output column (dependent variable) Returns: Modified dataframe """ data = cost_per_metric(data, output) if 'cost_per' in output else data[data[output] > 0] data = drop_columns(data, output, threshold=.5) data = data.dropna(axis='index') data = create_other_buckets(data, threshold=.1) data = one_hot_encode(data) return datadef split_pipeline(data, output): """ Preprocessing pipeline part 2: Split data into variables Arguments: Pandas dataframe, output column (dependent variable) Returns: List of scaled and unscaled dependent and independent variables """ y, X = data.iloc[:, 0], data.iloc[:, 1:] X_train, X_test, y_train, y_test = train_test_split( data.drop([output], axis=1), data[output], test_size=.2, random_state=1) X_scaled, y_scaled, X_train_scaled, y_train_scaled, X_test_scaled, y_scaler = scale(X, y, X_train, y_train, X_test) return [X, y, X_train, y_train, X_test, y_test, X_scaled, y_scaled, X_train_scaled, y_train_scaled, X_test_scaled, y_scaler]def cost_per_metric(data, output): """Create 'cost_per_...' column and remove data where output is 0 or NaN""" metric = output.replace('cost_per_', '') + 's' data = data[data[metric] > 0] data.insert(0, output, [row['cost'] / row[metric] for index, row in data.iterrows()]) return datadef drop_columns(data, output, threshold=0.5): """Drop columns with more than threshold missing data""" rows = data[output].count() for column in list(data.columns): if data[column].count() < rows * threshold: data = data.drop([column], axis=1) return datadef create_other_buckets(data, threshold=0.1): """Put rare categorical values into other bucket""" categoricals = list(data.select_dtypes(include='object').columns) for column in categoricals: results = data[column].count() groups = data.groupby([column])[column].count() for bucket in groups.index: if groups.loc[bucket] < results * threshold: data.loc[data[column] == bucket, column] = 'other' return datadef one_hot_encode(data): """One-hot encode categorical data""" categoricals = list(data.select_dtypes(include='object').columns) for column in categoricals: if 'other' in data[column].unique(): data = pd.get_dummies(data, columns=[column], prefix=[column], drop_first=False) data = data.drop([column + '_other'], axis=1) else: data = pd.get_dummies(data, columns=[column], prefix=[column], drop_first=True) return datadef scale(X, y, X_train, y_train, X_test): """Scale dependent and independent variables""" X_scaler, y_scaler = StandardScaler(), StandardScaler() X_scaled = X_scaler.fit_transform(X.values.astype(float)) y_scaled = y_scaler.fit_transform( y.values.astype(float).reshape(-1, 1)).flatten() X_train_scaled = pd.DataFrame(data=X_scaler.transform( X_train.values.astype(float)), columns=X.columns) y_train_scaled = y_scaler.transform( y_train.values.astype(float).reshape(-1, 1)).flatten() X_test_scaled = pd.DataFrame(data=X_scaler.transform( X_test.values.astype(float)), columns=X.columns) return [X_scaled, y_scaled, X_train_scaled, y_train_scaled, X_test_scaled, y_scaler]训练模型
最后,可以继续构建并训练多个回归量,实现最终的预测(非独立变量的值),也就是我们所求的营销活动中的曝光量。期间会尝试四种不同的监督式学习技术——线性回归、决策树、随机森林(由决策树形成)以及支持向量回归,同时会用Scikit-learn库提供的不同模型进行操作,而且这些模型在预处理中都已经缩放或拆分过数据了。
在构建回归量的时候会有更多的模型有可能被用到,比如人工神经网络,它预测出的结果会更准确。但是本文主要侧重于解释那些通俗易懂(大部分情况)的方式中的核心原则,而不在于最精准的预测。
线性回归
传送门:https://towardsdatascience.com/introduction-to-linear-regression-in-python-c12a072bedf0
借助Scikit-learn库建立一个线性回归一点也不难,只需要两行编码、输入Scikit模型类中指定的函数来处理一个变量即可:
from sklearn.linear_model import LinearRegressionlinear_regressor = LinearRegression(fit_intercept=True, normalize=False, copy_X=True)之所以想保留默认参数是因为需要计算截距(所有特征值为0产生的),我们不需要标准化的结果,而是可解释的数据。回归量的计算就是通过最小化误差平方和的方式来计算独立变量系数和截距,即真实结果与预测的偏差。该法被称为最小二乘法。
也可以输出这些系数及各自的p值,和与特定特征(系数为0的虚假设)独立(也有不相关的情况)的可能性大小,因此也有了统计显著性度量(值越低显著性越高)。
“初步浏览”前期能有数字特征间的可视化关系图的话,预测的“预算”、“天数”、“脸书”特征的p值会相对较小,且“预算”和“天数”的系数为正,“脸书”系数为负。Statsmodels模块针对此数据的输出提供了一条更为便捷的途径:
model = sm.OLS(self.y_train, sm.add_constant(self.X_train)).fit()print(model.summary())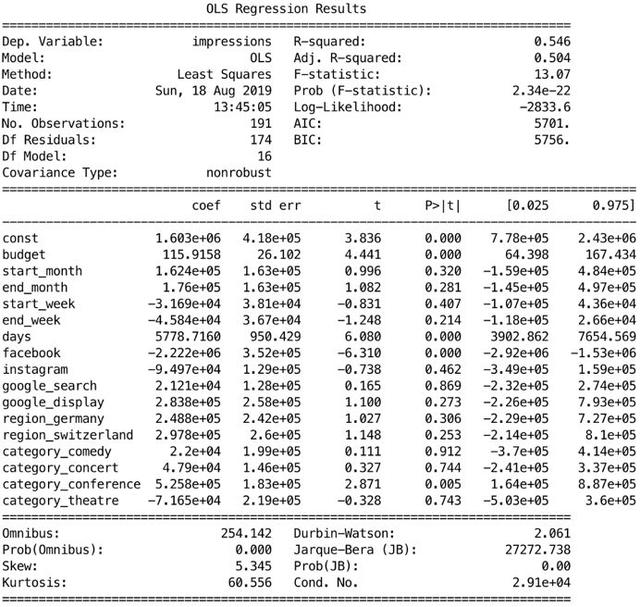
这里的p值是通过t统计或基于t分布的t分数计算得出的。数据的和也直接表明了整个模型拟合的优度和精确度,这是由决定系数R来评判的,其中测量的是输出数据中由输入变量解释的方差占比,此处是54.6%。
但是,为了比较所有的模型,也为了迎接特定的挑战,采取一种别样的平分方式,笔者称之为“平均相对精度(Mean Relative Accuracy)”,公式:1-均值百分比偏差=1-均值(|(预测值-真实值)/真实值|)。显然,此度量法并未考虑到真实值为0的情况,不过好在本例不会受这一点的影响,因为在预处理(看上文)中已经检查过了,所以获得的结果也具有良好的可解释性,且贴合准确度的直观定义。在评分的过程中,会有5层交叉验证,5次随机拆分数据集,再取分数的均值。Scitkit-learn库也提供了一个便于操作的方法:
linear_score = np.mean(cross_val_score(estimator=linear_regressor, X=X_train, y=y_train, cv=5, scoring=mean_relative_accuracy))线性回归的训练分数为0.18;所以此模型能够预测产生的最优拟合只有18%的精确度。祈祷其他的模型能超越这个成绩吧。
决策树
传送门:https://becominghuman.ai/understanding-decision-trees-43032111380f
下一个就是产生于单个决策树的回归量。这里会用到Scikit-learn 函数,所谓的超参数会更多一些,而不只是用线性模型,比如那些还没有按照预期设定的模型。这也就是为什么我们接下来会介绍Grid Search这个概念。Grid Search也来自于Scikit-learn库,确定参数的方格区域或矩阵来测试什么时候训练预测模型能得到最佳参数,即找出分数最高的那一个。照这种方式,就可以为决策树模型测试所有能用的参数,但我们只会关注其中的两个:对一个数列分为两部分的质量的“衡量标准”以及树上一片叶子(节点处)样本(数据点)的最小值。然后帮助我们寻找到合适的模型,里面附有样本数据,且能避免过度拟合的发生,比如无法从训练数据中生成新的样本。从现在开始,也要设置成随机模式,相当于随即计算,这样一来在编码过程中就会接收到相同的值。剩下的一波操作跟我们之前构建的线性回归是类似的:
tree_parameters = [{'min_samples_leaf': list(range(2, 10, 1)), 'criterion': ['mae', 'mse'], 'random_state': [1]}]tree_grid = GridSearchCV(estimator=DecisionTreeRegressor(), param_grid=tree_parameters, scoring=mean_relative_accuracy, cv=5, n_jobs=-1, iid=False)tree_grid_result = tree_grid.fit(X_train, y_train)best_tree_parameters = tree_grid_result.best_params_tree_score = tree_grid_result.best_score_从确定的方格内选出的最佳参数包括了均方误差,该值是决定每个节点最佳分叉位置的标准,也是每片叶子上九个样本的最小值,其中均值相对(训练)精确度达67%,跟线性回归的18%比起来好太多了。
决策树的一个优势在于可以直接看到模型,有个直观的印象。再加上Scikit-learn库和两行代码,就可以生成代表拟合决策树的DOT,该DOT可以接着转换成PNG图片:
from sklearn.tree import export_graphvizexport_graphviz(regressor, out_file='tree.dot', feature_names=X_train.columns)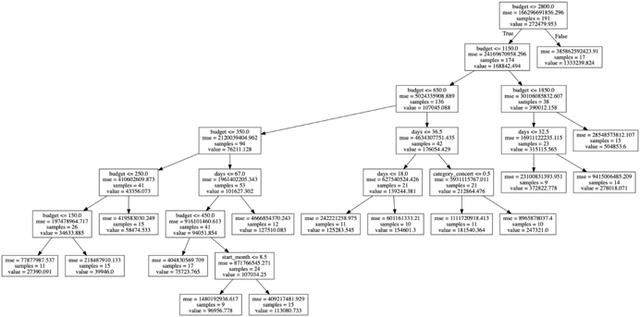
如你所见,16个特征中只有4个被用于构建模型了:预算、天数、类别以及起始月份。
随机森林
单个决策树的主要难点在于寻找每个节点的最优分割处并对训练数据进行过拟合。二者都可以通过结合多个树形成随机森林来处理。这里,森林中的树会在不同的(随机)子集上训练,在选定树上的每一处节点时都会将拥有某些可能特征的子集考虑在内。
随机森林回归的构建几乎跟决策树的构建没什么区别,只需要增加树的数量(这里叫做估测器)作为参数即可。鉴于不清楚最佳棵树是多少,我们会将另一个元素添入格点搜索,以决定最准确的回归量:
forest_parameters = [{'n_estimators': helpers.powerlist(10, 2, 4), 'min_samples_leaf': list(range(2, 10, 1)), 'criterion': ['mae', 'mse'], 'random_state': [1], 'n_jobs': [-1]}]forest_grid = GridSearchCV(estimator=RandomForestRegressor(), param_grid=forest_parameters, scoring=mean_relative_accuracy, cv=5, n_jobs=-1, iid=False)forest_grid_result = forest_grid.fit(X_train, y_train)best_forest_parameters = forest_grid_result.best_params_forest_score = forest_grid_result.best_score_根据之前确定的格点搜索,森林模型的最佳参数包括绝对均值误差标准、树的样本最小值(叶子)以及80个预测器(树)。有了这些,可以再一次将准确度提升至70%(与单一决策树相比)。
支持向量回归
最后已给要构建的回归量是基于支持向量机的,该理念是由Vladimir Vapnik在上世纪60年代到90年代间提出的,是很美的一个数学概念。不过要解释其运作原理的话就会超出本篇文章的范围,尽管如此,笔者还是极力推荐大家了解它们,麻省理工学院Winston教授的课就是不错的资源(https://www.youtube.com/watch?v=_PwhiWxHK8o),里面讲的很详细。
简单地总结一下:支持向量回归会将给出的样本放至多维度超平面中(顺序按照数字特征来排),超平面的直径由线边界来划分,从而将误差和成本降到最低。
虽说这种类型的模型从根本上跟决策树和随机森林不同,但涉及Scikit-learn库的操作还是大差不差的:
svr_parameters = [{'kernel': ['linear', 'rbf'], 'C': helpers.powerlist(0.1, 2, 10), 'epsilon': helpers.powerlist(0.01, 2, 10), 'gamma': ['scale']}, {'kernel': ['poly'], 'degree': list(range(2, 5, 1)), 'C': helpers.powerlist(0.1, 2, 10), 'epsilon': helpers.powerlist(0.01, 2, 10), 'gamma': ['scale']}]svr_grid = GridSearchCV(estimator=SVR(), param_grid=svr_parameters, scoring=mean_relative_accuracy, cv=5, n_jobs=-1, iid=False)svr_grid_result = svr_grid.fit(X_train_scaled, y_train_scaled)best_svr_parameters = svr_grid_result.best_params_svr_score = svr_grid_result.best_score_还可以使用格点搜索,来找到一些模型参数的最佳值。这里最重要的核心就是,将多个样本转换成维度更高的特征空间,这样数据就可以拆分开或者几乎可以呈线性排列,也就是借助上述超平面的方式。目前我们正在测试一个线性核函数、一个多项式核函数以及一个径向基函数。若线性核函数值为0.08,即预测值与真实值之间的最大距离(按比例调整)在没有误差情况下为0.08,惩罚参数C为12.8,则证明线性核函数性能最佳,达到23%的训练精确度(按比例计算)。
评估模型
现在已确立了基于训练数据模型的最佳参数,就可以用它们逐个去预测测试的结果,计算各自测试的精确度。首先,需要用想用的超参数调整模型以训练数据。这一次不需要什么交叉验证,调整模型能适应完整的数据集即可。然后用调整后的回归量来预测训练和测试结果并计算其精确度。
training_accuracies = {}test_accuracies = {}for regressor in regressors: if 'SVR' in str(regressor): regressor.fit(X_train_scaled, y_train_scaled) training_accuracies[regressor] = hel.mean_relative_accuracy( y_scaler.inverse_transform(regressor.predict( X_train_scaled)), y_train) test_accuracies[regressor] = hel.mean_relative_accuracy( y_scaler.inverse_transform(regressor.predict( X_test_scaled)), y_test) else: regressor.fit(X_train, y_train) training_accuracies[regressor] = hel.mean_relative_accuracy( regressor.predict(X_train), y_train) test_accuracies[regressor] = hel.mean_relative_accuracy( regressor.predict(X_test), y_test结果如下:
训练精确度: 线性模型为 0.34, 决策树为0.67, 随机森林为0.75, 支持回归向量为0.63
测试精确度: 线性0.32, 树0.64, 森林0.66,支持回归向量0.61
最优回归量当属随机森林模型,其测试精确度高达66%。但还是有些过度拟合,因为训练精确度的偏差相当大。可以自由地对超参数的其他值进行实验,以便进一步优化所有的模型。
在最终保存模型对新数据进行预测前,调整它至适用于所有可用数据(训练和测试集)以收集尽可能多的信息。
预测结果
现在有了模型,就可以预测未来营销活动的情况。只需通过一个特定的特征向量调用预测法,就能得到用于训练回归量的度量的不同预测结果。也可以依据新的模型比较现有数据集中的真实曝光量与预测结果:
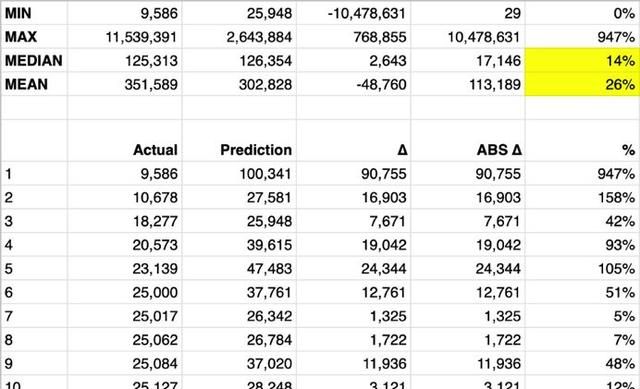
预测值与真实值的平均相对偏差为26%,所以准确率达到了74%,中值偏差只有14%甚至更少。
结语
通过建立并训练回归量,我们可以根据以往的营销数据来预测未来营销活动的曝光量(以及其他类似的性能指标)。
随机森林模型已实现精确度最高的预测
如今我们甚至可以在营销活动开始之前就利用这些预测值来评估新的营销活动。此外,我们也可以得到最佳参数,比如时间轴和预算规模,这得益于可以利用不同的特征值计算预测值。
福利:训练过的即用模型
是不是手边还没有数据来为计划的数字化营销活动构建一个精确的预测模型?别担心:笔者训练过无数的模型来预测曝光量、点击量和交易量,参考的数据来自1000+个营销活动。结合不同的模型,最终预测的精确度高达90%。在predictor.stagelink.com你可以找到一个便于操作的APP,只需输入少量信息即可预测未来营销状况。所有的模型在训练时依据的主要是数字营销活动的数据,推动了活动门票的销售,所以这极有可能是模型最见效的地方。
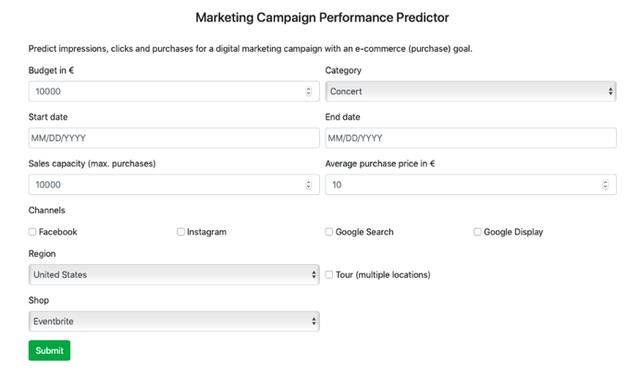
predictor.stagelink.com
此外,你可以在笔者的Github上找到所有用于讨论营销性能预测的代码:https://github.com/kinosal/predictor

留言 点赞 关注
我们一起分享AI学习与发展的干货
如需转载,请后台留言,遵守转载规范