Linux常用命令 shell脚本for QA-数据脱敏版2
由于博客官网存在图片上传失败的bug https://blogdev.blog.csdn.net/article/details/94006575 故此我之前的【Linux常用命令】的博客不可以编辑了https://blog.csdn.net/weixin_42498050/article/details/81037479,故此新建个博客吧~~
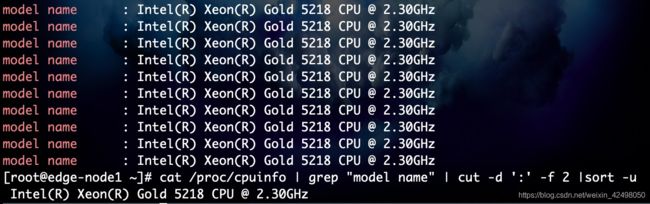
98. cat /proc/cpuinfo | grep "model name" | cut -d ':' -f 2 |sort -u
- -b :以字节为单位进行分割。这些字节位置将忽略多字节字符边界,除非也指定了 -n 标志。 byte
- -c :以字符为单位进行分割。 char
- -d :自定义分隔符,默认为制表符。 define
- -f :与-d一起使用,指定显示哪个区域。 fields 一般用以指定分隔符后的第几列
- -n :消分割多字节字符。仅和 -b 标志一起使用。如果字符的最后一个字节落在由 -b 标志的 List 参数指示的
范围之内,该字符将被写出;否则,该字符将被排除
97. awk打印除某列之外的所有列
cat 1.txt| awk '{x=2;while(x<=NF){printf "%s ", $x;x++;}printf "\n"}' > nice.txt
cat 1.txt|awk '{$1 = null ;print}' > nice.txt
47 listeners="org.uncommons.reportng.HTMLReporter,org.testng.reporters.FailedReporter" >
48
49
50
51
52
53
96. 计算cpu利用率的shell脚本
[root@edge-node1 tmp]# cat /proc/stat 查看CPU
cpu 125094388 160 19646788 3863197092 1316929 22008021 20012906 0 105025966 0
cpu0 2300773 0 316963 59961223 28218 350919 322074 0 1989117 0
cpu1 1885273 2 1076616 59629637 19424 345949 333747 0 261688 0
cpu2 1777766 2 382328 60422289 24439 351985 339369 0 1086476 0
cpu3 1591870 11 367656 60620419 20955 352620 342047 0 1049030 0
cpu4 1573398 0 352758 60652301 21908 352368 340665 0 1072780 0
各个参数的具体解释:
第一排是cpu总计,下面是2个4核cpu的参数,故有8行数据
user (494881706) 从系统启动开始累计到当前时刻,用户态的CPU时间(单位:jiffies) ,不包含 nice值为负进程。1jiffies=0.01秒
nice (19) 从系统启动开始累计到当前时刻,nice值为负的进程所占用的CPU时间(单位:jiffies)
system (67370877) 从系统启动开始累计到当前时刻,核心时间(单位:jiffies)
idle (876689477) 从系统启动开始累计到当前时刻,除硬盘IO等待时间以外其它等待时间(单位:jiffies)
iowait (17202366) 从系统启动开始累计到当前时刻,硬盘IO等待时间(单位:jiffies)
irq (200116) 从系统启动开始累计到当前时刻,硬中断时间(单位:jiffies)
softirq (0) 从系统启动开始累计到当前时刻,软中断时间(单位:jiffies)
CPU利用率技术脚本:本脚本持续显示cpu的利用率
知道了/proc文件的内容之后就可以计算cpu的利用率了,具体方法是:先在t1时刻读取文件内容,获得此时cpu的运行情况,然后等待一段时间在t2时刻再次读取文件内容,获取cpu的运行情况,然后根据两个时刻的数据通过以下方式计算cpu的利用率:100 – (idle2 – idle1)*100/(total2 – total1) 其中total = user + system + nice + idle + iowait + irq + softirq
#!/bin/bash
while(true)
do
# $1 $2 $3 $4 $5 $6 $7
CPU_1=$(cat /proc/stat | grep 'cpu ' | awk '{print $2" "$3" "$4" "$5" "$6" "$7" "$8}') #打印第一行cpu每列,user nice system4 idle iowait irq softirq
SYS_IDLE_1=$(echo $CPU_1 | awk '{print $4}') #打印第4列idle,从系统启动开始累计到当前时刻,除硬盘IO等待时间以外其它等待时间
Total_1=$(echo $CPU_1 | awk '{printf "%.f",$1+$2+$3+$4+$5+$6+$7}') #打印cpu全部列之和
sleep 2 #等待2秒
CPU_2=$(cat /proc/stat | grep 'cpu ' | awk '{print $2" "$3" "$4" "$5" "$6" "$7" "$8}') #再次取最新的列
SYS_IDLE_2=$(echo $CPU_2 | awk '{print $4}') #再次打印第4列idle,从系统启动开始累计到当前时刻,除硬盘IO等待时间以外其它等待时间
Total_2=$(echo $CPU_2 | awk '{printf "%.f",$1+$2+$3+$4+$5+$6+$7}') #第二次打印cpu全部列之和
SYS_IDLE=`expr $SYS_IDLE_2 - $SYS_IDLE_1` #expr命令是一个手工命令行计数器,用于求表达式变量的值,一般用于整数值,也可用于字符串 > expr length “this is a test” 为14(算上空格了)
Total=`expr $Total_2 - $Total_1` #2次cpu总和的差值
TT=`expr $SYS_IDLE \* 100` # (idle2 – idle1)*100
SYS_USAGE=`expr $TT / $Total` # (idle2 – idle1)*100/(total2 – total1)
SYS_Rate=`expr 100 - $SYS_USAGE` #cpu利用率为100 – (idle2 – idle1)*100/(total2 – total1)
echo "The CPU Rate : $SYS_Rate%"
echo "------------------"
done

复制粘贴以下
#!/bin/bash
while(true)
do
CPU_1=$(cat /proc/stat | grep 'cpu ' | awk '{print $2" "$3" "$4" "$5" "$6" "$7" "$8}')
SYS_IDLE_1=$(echo $CPU_1 | awk '{print $4}')
Total01=$(echo $CPU_1 | awk '{printf "%.f",$1+$2+$3+$4+$5+$6+$7}')
sleep 2
CPU_2=$(cat /proc/stat | grep 'cpu ' | awk '{print $2" "$3" "$4" "$5" "$6" "$7" "$8}')
SYS_IDLE_2=$(echo $CPU_2 | awk '{print $4}')
Total_2=$(echo $CPU_2 | awk '{printf "%.f",$1+$2+$3+$4+$5+$6+$7}')
SYS_IDLE=`expr $SYS_IDLE_2 - $SYS_IDLE_1`
Total=`expr $Total_2 - $Total01`
TT=`expr $SYS_IDLE \* 100`
SYS_USAGE=`expr $TT / $Total`
SYS_Rate=`expr 100 - $SYS_USAGE`
echo "The CPU Rate : $SYS_Rate%"
echo "------------------"
done求cpu利用率的平均值
cat 1.txt |cut -d ':' -f 2|awk '{sum+=$1}END{print "Average = ", sum/NR*2}'

94. vim使用(三):.viminfo和.vimrc
viminfo
在vim中操作的行为,vim会自动记录下来,保存在 ~/.viminfo 文件中。
这样为了方便下次处理,
如:vim打开文件时,光标会自动在上次离开的位置显示。
原来搜索过的字符串,新打开文件时自动高亮显示。
~/.viminfo 文件是系统自动生成。
vimrc
vimrc文件是vim的环境设置文件。
整体的vim的设置是在 /etc/vimrc 文件中。
不建议修改/etc/vimrc 文件,每个用户可以在用户根目录中设置vim,新建 ~/.vimrc.
vim的配置选项较多,
:set all
93. cat less more的区别
less比grep不占内存
cat是一次性显示整个文件的内容,more和less一般用于显示文件内容超过一屏的内容,并且提供翻页的功能。more比cat强大,提供分页显示的功能,less比more更强大,提供翻页,跳转,查找等命令。而且more和less都支持:用空格显示下一页,按键b显示上一页。
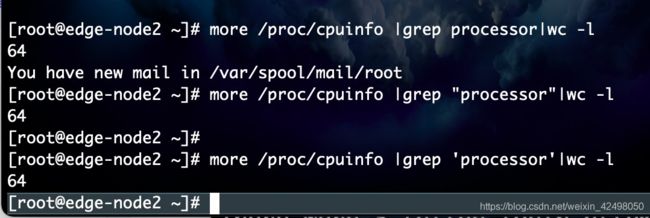
92. more /proc/cpuinfo |grep 'processor'|wc -l
91. 全局查找某个字符
grep --color=auto -rns "findName" *
grep -rn可以关键词查找符合条件的文件的行;去重文件名,然后xargs替换模式
grep -nr "centos-5-x64"
适用场景:我们经常会碰到一个报错但是却不知道配置文件的路径在哪里,这时候用rn就能轻松解决

[xx@xx ~]# grep -nr "centos-5-x64"
kubespray/tests/cloud_playbooks/create-do.yml:25: - centos-5-x64
Binary file kubespray-edge-develop-xx-v1.0.6.tar matches
-n, --line-number,---常用
在显示 行前,标上行号 。
ex: $ grep-npanda file
显示结果相似于下:
行号:符合行的内容
-r, --recursive,---常用
递归地 ,读取每个资料夹下的所有档案,此相当于 -d recsuse 参数。
linux输出文件的指定行
1.获取第k行(以k=10为例)
要注意的是,如果文件包含内容不足10行,应该不输出.
# Read from the file file.txt and output the tenth line to stdout.
# 解法一,使用awk
awk 'NR == 10' file.txt
# 解法二,使用sed(个人测试结果:sed方法比awk快)
sed -n '10p' file.txt
# 解法三,组合使用tail与head
tail -n+10 file.txt | head -n1
# 另外,以下这种方法不符合要求
head file.txt -n10 | tail -n1 # 因为如果文件包含内容不足10行,会输出最后一行[xx@xx ~]# sed -n '25p' kubespray/tests/cloud_playbooks/create-do.yml
- centos-5-x64
[root@node1 ~]# awk 'NR==25' kubespray/tests/cloud_playbooks/create-do.yml
- centos-5-x64
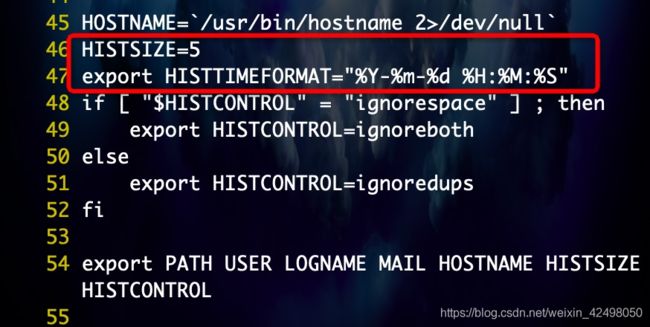
90. 修改history展示日志条数,为 history 增加时间戳
vi /etc/profile
46 HISTSIZE=5 修改数目为5则显示50条日志
47 export HISTTIMEFORMAT="%Y-%m-%d %H:%M:%S"
"%Y-%m-%d %H:%M:%S " 等价于 "%F %T"
保存完毕后,source /etc/profile
查看最近10 20条日志
history 10
history 20
Linux查找以前输入的命令
1.上下键
2.history命令
3.用 Ctrl+r 快捷键,反向查找历史命令(reverse-i-search)
按下 Ctrl+r 快捷键后,进入了反向搜索状态,这时你输入一个字符,系统会找到最近一个包含这个字符的命令,如果不是这条命令的话,可以再按下 Ctrl + R,Bash 会向前搜索有输入的字符的命令
找到你想要的命令后,你可以按回车执行这条命令。还可以按上下键查找该命令前后的命令,按左右键移动光标并修改这条命令
89. vim模式下忽略大小写查找字符串 如文件中有A a希望查找a结果A也可被查找出
vim模式下,输入命令 set ignorecase,在没关闭该文件前提下,字符串的查找都将不区分大小写
88. Linux中vi vim模式下让set nu在每次启动vi时候自己自动生效 vim模式打开的文件默认显示行号设置
# vim /etc/vimrc
在文件最后一行添加 set nu
不需要source
87. 多个文件内容写到一个文件 cat file1 file2 file3 > fileAll
# cat c1n4to5.txt c2n4to5.txt c3n4to5.txt > node4tonode5.log
# wc -l node4tonode5.log 统计文件行数
5427 node4tonode5.log
86. Linux命令之control快捷键组合
ctrl+a:光标移到行首。
ctrl+b:光标左移一个字母
ctrl+c:杀死当前进程。
ctrl+d:退出当前 Shell。
ctrl+e:光标移到行尾。
ctrl+h:删除光标前一个字符,同 backspace 键相同。
ctrl+k:清除光标后至行尾的内容。
ctrl+l:清屏,相当于clear。
ctrl+r:搜索之前打过的命令。会有一个提示,根据你输入的关键字进行搜索bash的history
ctrl+u: 清除光标前至行首间的所有内容。
ctrl+w: 移除光标前的一个单词
ctrl+t: 交换光标位置前的两个字符
ctrl+y: 粘贴或者恢复上次的删除
ctrl+d: 删除光标所在字母;注意和backspace以及ctrl+h的区别,这2个是删除光标前的字符
ctrl+f: 光标右移
ctrl+z : 把当前进程转到后台运行,使用’ fg ‘命令恢复。比如top -d1 然后ctrl+z ,到后台,然后fg,重新恢复
esc组合
esc+d: 删除光标后的一个词
esc+f: 先按esc再按f 不可以同时按。往右跳一个词
esc+b: 先按esc再按b 不可以同时按。往左跳一个词
esc+t: 交换光标位置前的两个单词。
85. vim下统计字符串出现的次数
关键命令:
:%s/pattern//gn
参数说明:
% :指明操作区间,%表示全文本;可以使用1,$或者行区间代替
s:substitute,表示替换
pattern:要查找的字符串
//:替代文本应该放在这里,两个斜杠中间没有任何字符表示无替代文本
g:替换该行所有出现的字符串,如果没有该参数则只替换该行第一次出现的地方
n:表示匹配的行数
84. 查看服务器系统以及版本 一般公司都是用centos 有的Ubuntu debain
# cat /etc/redhat-release
CentOS Linux release 7.5.1804 (Core)
# uname -a
Linux lxco 3.10.0-862.el7.x86_64 #1 SMP Fri Apr 20 16:44:24 UTC 2018 x86_64 x86_64 x86_64 GNU/Linux
el7就是系统了
查看服务器系统
# hostnamectl
Static hostname: xx
Icon name: computer-vm
Chassis: vm
Machine ID: xxxx
Boot ID: xx
Virtualization: kvm
Operating System: CentOS Linux 7 (Core)
CPE OS Name: cpe:/o:centos:centos:7
Kernel: Linux 3.10.0-862.el7.x86_64
Architecture: x86-64
83. hostname -i 显示当前机器的 ip 地址
82. 查找iperf3服务器路径 which iperf3
81. 服务器 8C16G为8核16G
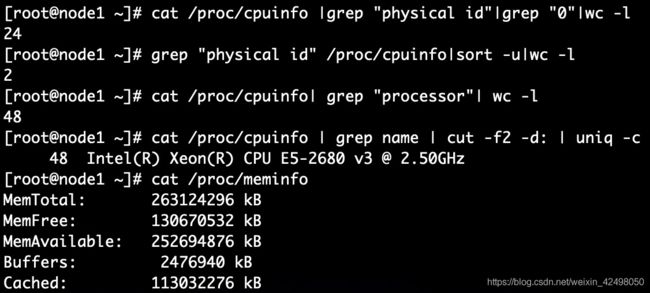
查看CPU核数 more /proc/cpuinfo |grep "physical id"|grep "0"|wc -l
查看磁盘 free -g

参考博客https://blog.csdn.net/weixin_39628256/article/details/111551427
# cat /proc/cpuinfo 查看物理cpu
有多少physical id 就有多少个cpu,我们的服务器是8个
有多少个core id就有多少核 --8个物理内核
总的CPU物理内核数 = 物理CPU数 * 每颗物理CPU的内核数 8*8=64
cat /proc/cpuinfo |grep "physical id"|grep "0"|wc -l 查看物理CPU个数
24
grep "physical id" /proc/cpuinfo|sort -u|wc -l
2
cat /proc/cpuinfo| grep "processor"| wc -l 查看逻辑CPU个数 逻辑CPU内核
48
cat /proc/cpuinfo | grep name | cut -f2 -d: | uniq -c
48 Intel(R) Xeon(R) CPU E5-2680 v3 @ 2.50GHz
cat /proc/cpuinfo| grep "cpu cores"| uniq 查看每个物理CPU中core的个数(即核数)
cpu cores : 6
80. 批量创建文件夹
mkdir -p /mnt/simth/sdk/daystar
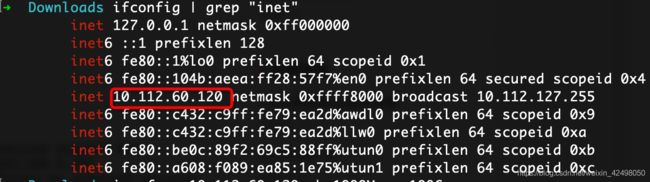
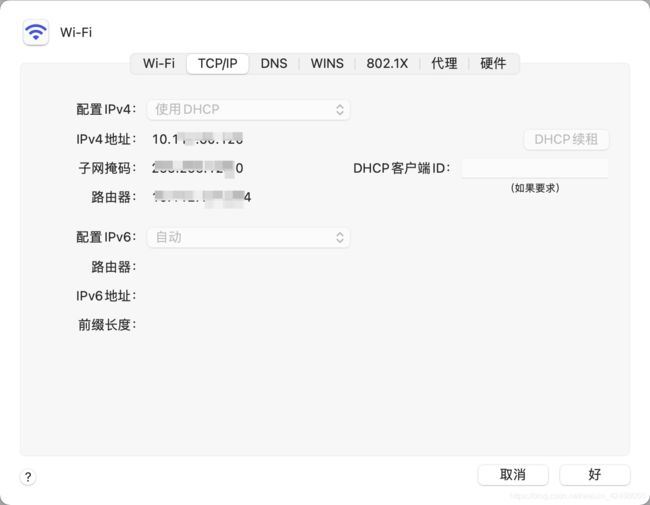
78. Mac查看本机ip地址
77. vim设置编码格式
:set ff 查看当前文本的模式类型,一般为dos,unix
:set ff=dos 设置为dos模式, 也可以用 sed -i 's/$/\r/'
:set ff=unix 设置为unix模式,也可以用一下方式转换为unix模式:sed -i 's/.$//g'
:set fileencoding查看现在文本的编码
:set fenc=编码 转换当前文本的编码为指定的编码
:set enc=编码 以指定的编码显示文本,但不保存到文件中
常用:set enc=utf-8
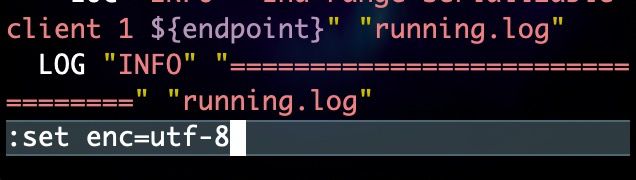
76.
.表示执行的意思,就是执行这个文件。
./表示执行当前目录下的某个文件,就比如当前目录有一个脚本a.sh,那么./a.sh就表示执行它
75. GDB学习https://www.cnblogs.com/arnoldlu/p/9633254.html
GDB调试的三种方式:
1. 目标板直接使用GDB进行调试。
2. 目标板使用gdbserver,主机使用xxx-linux-gdb作为客户端。
3. 目标板使用ulimit -c unlimited,生成core文件;然后主机使用xxx-linux-gdb ./test ./core。
74. 内存不足,解决办法:杀进程 扩内存
free -m

free -g

73. 今天通过日志来统计系统的执行情况,通过uniq -c之后发现还是存在重复列
查看uniq的说明,uniq去重,应该是行之间连续的重复。所以先进行排序 sort,在uniq -c 进行统计
➜ Downloads cat origin
a
c
c
d
e
d
➜ Downloads cat origin|awk '{print $1}'|uniq -c >quchong 按照文本里的内容顺序正序显示 把连续的行数去掉 如cc 为2c 非连续的行d与d之间有e 显示1d 1e 1d 显示行号+内容
➜ Downloads cat quchong
1 a
2 c
1 d
1 e
1 d
➜ Downloads cat origin|awk '{print $1}'|uniq -c |sort >quchong 按照文本里的内容顺序正序显示 但按照次数从低到高展示 把连续的行 非连续的行都去重了 显示行号+内容
➜ Downloads cat quchong
1 a
1 d
1 d
1 e
2 c
➜ Downloads cat origin|awk '{print $1}'|uniq -c |sort -nr >quchong 按照文本里的内容顺序逆序显示 但按照次数从高到底展示 把连续的行 非连续的行都去重了
➜ Downloads cat quchong
2 c
1 e
1 d
1 d
1 a
➜ Downloads cat origin|awk '{print $1}'|sort -u >quchong 按照文本里的内容顺序正序显示 不显示出现的次数 只显示去重后的内容
➜ Downloads cat quchong
a
c
d
e

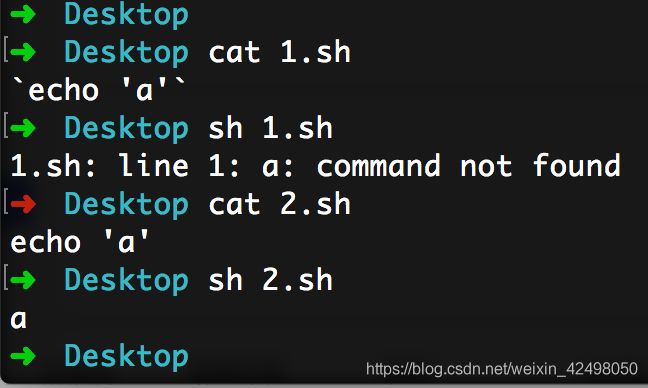
72. shell脚本sh文件里的内部要打印的echo内容不能写 ` ` 如果是定义的变量可以写 如 pid=`netstat -atnp 2>/dev/null|grep 8080|grep LISTEN|awk '{print $7}' |awk -F'/' '{print $1}'`
➜ Desktop cat 1.sh
`echo 'a'`
➜ Desktop sh 1.sh
1.sh: line 1: a: command not found
➜ Desktop cat 2.sh
echo 'a'
➜ Desktop sh 2.sh
a
71.多个命令可连着用 用;分割 如 pwd;ll
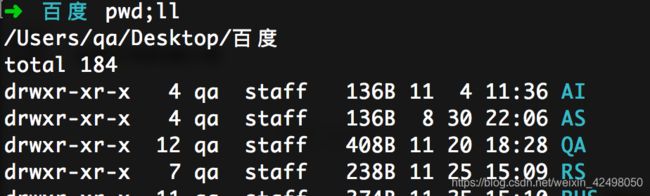
70. 如果要把文件解压到指定的目录下,需要用到-d参数
unzip -d /filepath/xx test.zip
或者unzip -d ./test test.zip
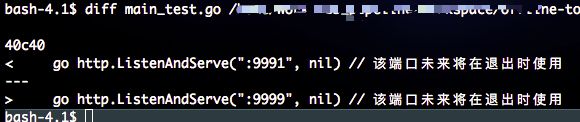
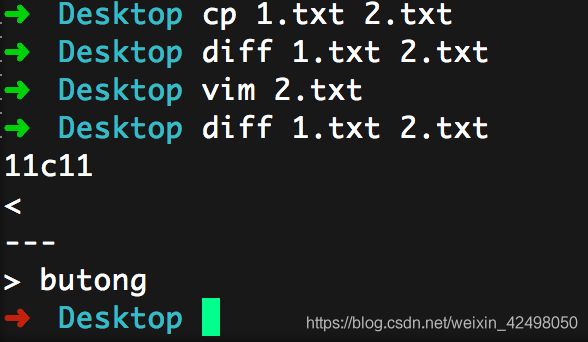
69. diff filenameA filenameB
显示不同的行信息
68. ➜ Desktop ls -l|grep '\d*.txt$'
查找本地文件以数字开头 .txt结尾的文件
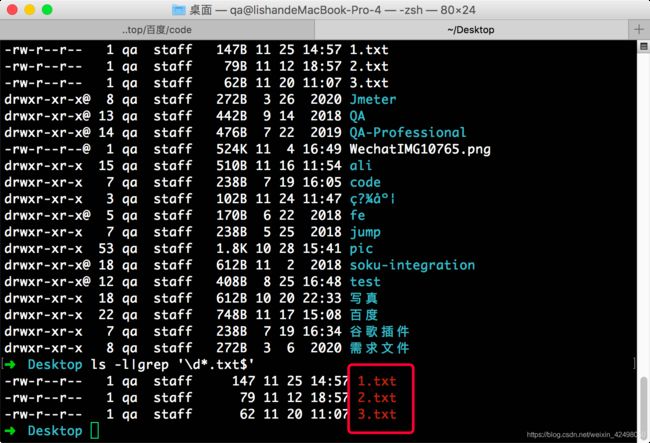
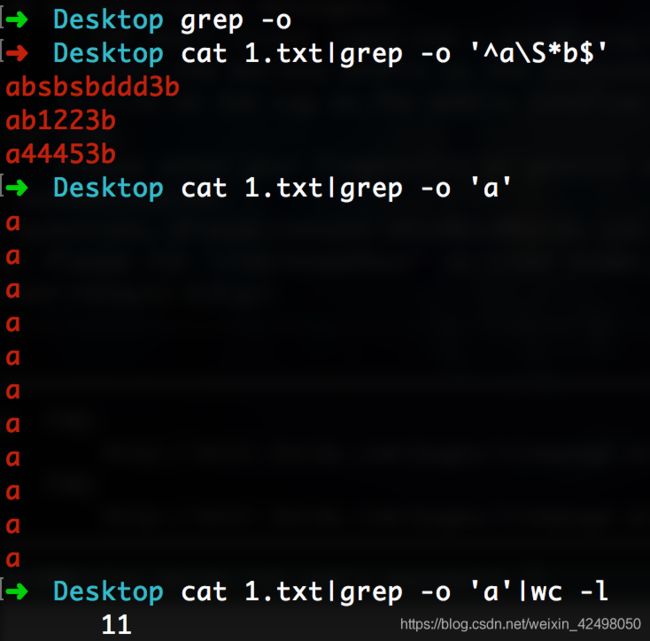
查找以a开头b结尾的行
➜ Desktop cat 1.txt|grep '^a\S*b$'
查找a出现的次数
➜ Desktop cat 1.txt|grep -o 'a'|wc -l
67. 软链接
把文件路径/文件名称软链接到 文件名称
ln -s ../filename/filepath/xx.sh xx.sh
$ ln -s A/a.sh a.sh

硬链接 :硬链接(hard link,也称链接)就是一个文件的一个或多个文件名。再说白点,所谓链接无非是把文件名和计算机文件系统使用的节点号链接起来。因此我们可以用多个文件名与同一个文件进行链接,这些文件名可以在同一目录或不同目录
硬链接就是让多个不在或者同在一个目录下的文件名,同时能够修改同一个文件,其中一个修改后,所有与其有硬链接的文件都一起修改了
Linux系统下,硬链接和软链接的区别
1.在Linux系统中,有硬链接和软件链接两种“特殊”的文件存在的。
硬链接:通过文件系统的inode来产生新档名,而不是产生新档案。
软链接:看作是Windows中的快捷方式,可以让你快速链接到目标档案或目录。
2.创建方法都很简单:
软链接(符号链接) ln -s aa bb
硬链接 (实体链接)ln aa bb
3.链接数目是不一样的,软链接的链接数目不会增加;
4.文件大小是不一样的,硬链接文件显示的大小是跟原文件是一样的。而这里软链接显示的大小与原文件就不同了,BBB大小是95B,而BBBsoft是3B。因为BBB共有3个字符
66. sh -x xx.sh
-x 显示shell执行过程中的命令
65. 统计一个文件hello出现的次数
➜ Desktop cat 3.txt|grep -c 'hello'
2
➜ Desktop cat 3.txt|grep 'hello'|wc -l
2
某个目录文件夹下查找某个文件
➜ Desktop ll|grep ali

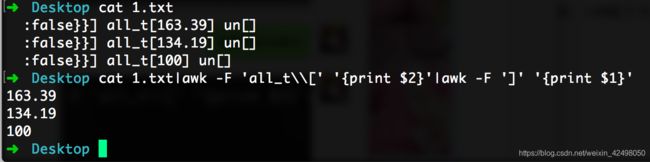
64. shell对日志接口耗时的统计,正则符号[的过滤 需要加\\转义
➜ Desktop cat 1.txt
:false}}] all_t[163.39] un[]
:false}}] all_t[134.19] un[]
:false}}] all_t[100] un[]
➜ Desktop cat 1.txt|awk -F 'all_t\\[' '{print $2}'|awk -F ']' '{print $1}'
163.39
134.19
100
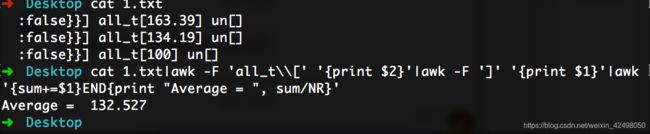
shell多行求和,多行求平均值。如需求:求压测接口的平均耗时
cat 1.txt|awk -F 'all_t\\[' '{print $2}'|awk -F ']' '{print $1}'|awk '{sum+=$1}END{print "Average = ", sum/NR}'
63. 查看文件的md5
md5sum xx.tar.gz
62. 多人在服务器部署自己的服务 重启
ps -ef|grep server|grep username|awk '{print $2}'|xargs kill -9
61. vim模式 按单词删除 dw == delete word
删除单个字符x
按单词跳转w
复制多行:nyy 如3yy 复制3行 按下p粘贴
查看vim下搜索历史: ? + shift + command + H 上下箭头选中历史记录query
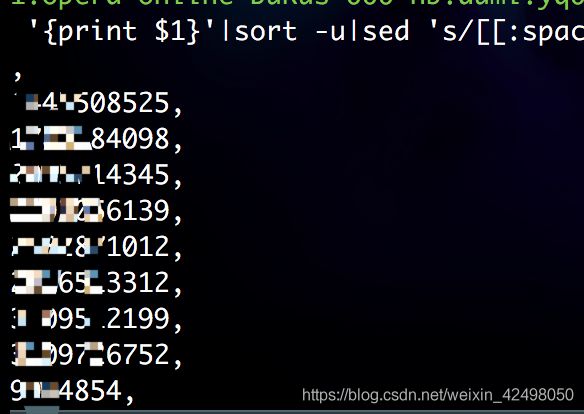
60. 打印日志中的userid去重并去除空格并在每行后面追加,
head -10 request.log|awk -F 'realUserId":"' '{print $2}'|awk -F '",' '{print $1}'|sort -u|sed 's/[[:space:]]//g'|sed 's/$/,/g'
59. shell从第一个字符截取到最后一个(,)字符中间。echo ${a%,*}
创建1.sh的文件
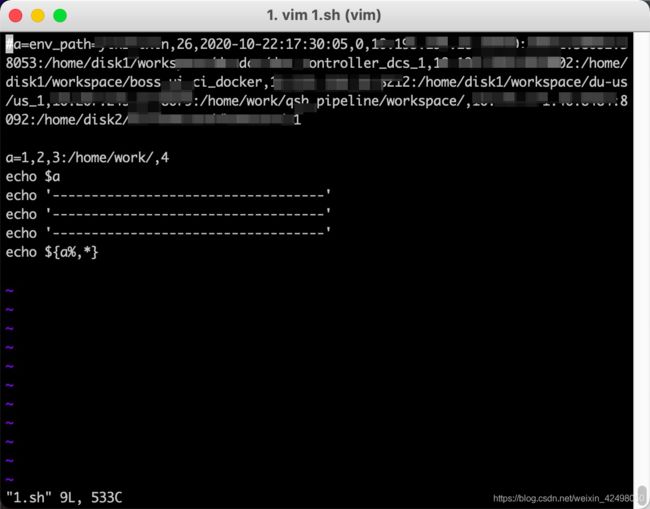
a=1,2,3:/home/work/,4
echo $a
echo '-----------------------------------'
echo ${a%,*}
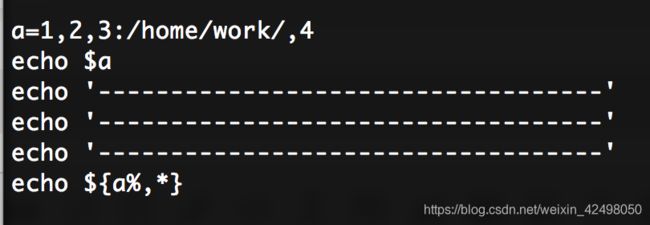
结果
1,2,3:/home/work/,4
-----------------------------------
1,2,3:/home/work/

2) 使用 % 截取左边字符
使用%号可以截取指定字符(或者子字符串)左边的所有字符,具体格式如下:
${string%chars*}
请注意*的位置,因为要截取 chars 左边的字符,而忽略 chars 右边的字符,所以*应该位于 chars 的右侧。其他方面%和#的用法相同,这里不再赘述,仅举例说明:
- #!/bin/bash
- url="http://c.biancheng.net/index.html"
- echo ${url%/*} #结果为 http://c.biancheng.net
- echo ${url%%/*} #结果为 http:
- str="---aa+++aa@@@"
- echo ${str%aa*} #结果为 ---aa+++
- echo ${str%%aa*} #结果为 ---
58. 端口查询进程查询项目路径
netstat -nap|grep 8129
ll /proc/688/cwd

57. 查看端口号对应的进程号,只打印进程号这一列
1> 查端口时
netstat -nap|grep 8011
tcp 0 0 0.0.0.0:8011 0.0.0.0:* LISTEN 21486/servername
第7列为 进程pid/服务名称
只打印进程pid
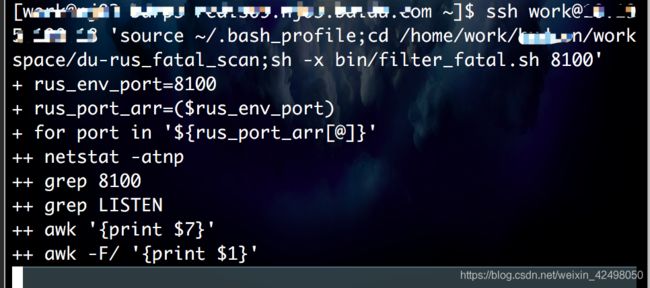
netstat atnp 2>/dev/null|grep 8011|grep LISTEN|awk '{print $7}'|awk -F'/' '{print $1}'
结果为 21486
netstat -nap 可以grep端口 进程 servename
2> 查进程时
netstat -nap|grep 21486
tcp 0 0 0.0.0.0:8123 0.0.0.0:* LISTEN 21486/servicename
tcp 0 0 127.0.0.1:21486 127.0.0.1:793 TIME_WAIT -
3> 查服务器名称时
ps -ef|grep servicename
work 21404 12433 0 20:58 pts/6 00:00:00 grep servicename
work 21486 1 14 20:48 ? 00:01:30 /home/xx/servicename
shell脚本 根据端口查询服务进程 根据进程查询服务路径
pid=`netstat -atnp 2>/dev/null|grep ${port}|grep LISTEN|awk '{print $7}'|awk -F'/' '{print $1}'`
if [[ $pid == '' ]]; then
continue
fi
env_path=`ls -l /proc/${pid}/cwd|awk '{print $11}'`
解释:ll /proc/21486/cwd 的执行结果为
lrwxrwxrwx. 1 work work 0 Oct 21 20:48 /proc/21486/cwd -> /home/xx/servicename/xx
服务器路径为从左往右数第11个字符(lrwxrwxrwx. 为第1个字符 1为第2个字符 work为第3个字符。过滤空格逐个数)
4> 日志文件截取错误日志并去重
grep ERROR log/xx/xx.log.wf*|awk -F 'ERROR:' '{print $2}'|sort|uniq -c
56. shell脚本 更新代码
shell 中if [ -e/d/f ..... ] 详解
文件表达式
-e filename 如果 filename存在,则为真
-d filename 如果 filename为目录,则为真
https://blog.csdn.net/lukabruce/article/details/98845437
#!/bin/bash
port=$1
# 如果filename1文件夹不存在则git clone拉取仓库代码
if [ ! -d filename1 ];then
git clone ssh://xx.com
else
# 如果存在文件夹说明非第一次拉取代码,保证版本一致才reset?则需要更新RD代码
git reset --hard
git pull
# 有几个 if 就对应有几个 fi。到下面一段完整的if else fi结束
fi
# 更新第二个仓库
if [ ! -d filename2 ];then
git clone ssh://xx
else
git reset --hard
git pull
fi
# update env port
sed -i 's/80xx/'${port}'/g' xx/xx/xx/xx.toml
sed -i 's/80xx/'${port}'/g' xx/xx/xx/yy.conf
55. 如果发送的是http://ip:port/online_uid.txt 这种的链接,可以用wget下载
54. vim模式下删除某段,某行,或者全部删除的命令
1.先打开某个文件
vim filename
2.转到文件尾行
直接在命令模式下输入 G
3.转到第 N 行
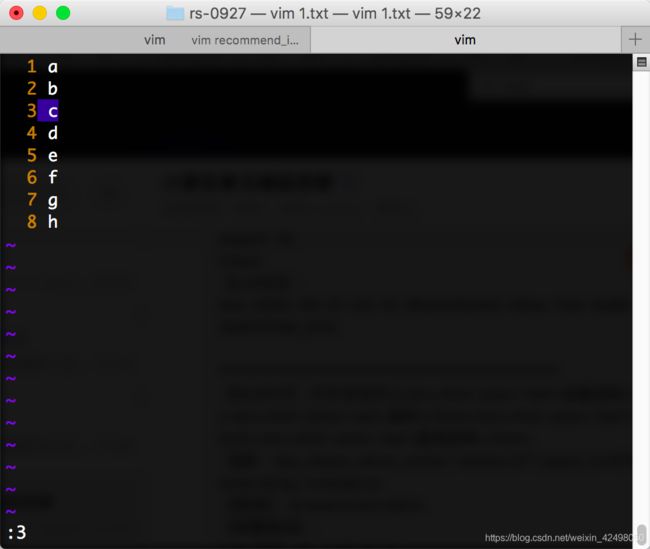
在命令模式下,输入 NG (N代表第几行)
4.删除所有内容
先在命令模式下输入 G 光标跳转至行尾
再输入
:1,.d
5.删除第n行到第m(m>n)行的内容 删除多行 删除指定的行
先在命令模式下输入 mG (将光标移动至该行, 也可以使用+来进行光标移动)
再执行如下命令
:n,.d(表示删除从第n行到当前光标所在行)
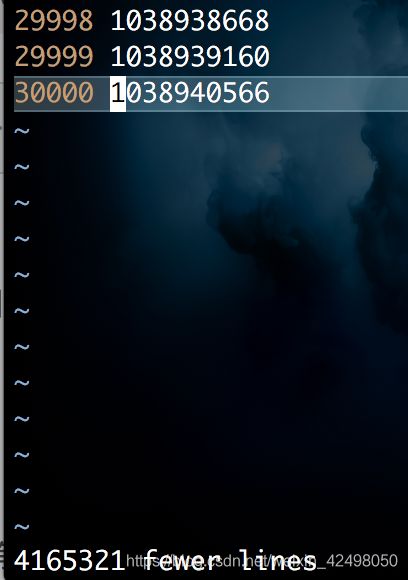
如删除1181到1830行
先:1830跳到第1830行 再:1811,.d
删除完成左下方显示 20 fewer lines
6.关于删除的一些说明
* 在vim中,"."表示当前行,“1,.”表示从第一行到当前行,“d”表示删除。
* 如果只是想删除某一行,直接将光标移至该行,输入dd即可。
7.设置显示行号
在vim里执行
:set number

需求:线上日志流程回放 改为我们需要的最新传参如uid cuid 类型,2w行数据要包含3种类型。因此批量替换后还需要各种组合
取前7000行数据写到新的文件A,原始文件删除前7000行。取第二个7000行再替换成新的类型写到新的文件B。依次循环,最后把文件ABC写到一个文件All
:%s/first:"/first:"小品/g
head -7000 req_file_7_xx >req_file_7_xx_xiaopin
:%s/小品/相声/g
head -7000 req_file_7_xx >req_file_7_xx_xiangsheng
:%s/相声/广场舞/g
cat req_file*>req_file_7_xx
cat req_file* > all_file_old
cat all_file_old |wc -l
40000
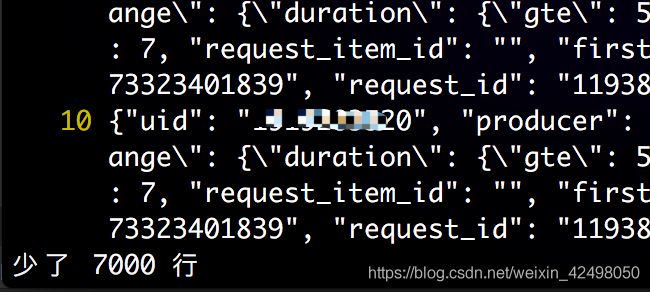
如删除文件前7000行
:set nu
:7000
:1,.d
执行完了提示少了7000行
用sed命令 删除10001到29999行
sed -i '10001,29999'd req_file7no.bak
53. 捞取线上日志 灌数据
$0整行 $1分隔后的第一列 $2分隔后的第二列
从第一个-F截取到第二个-F 取截图的部分作为需要的数据
cat xx.log.notice |awk -F 'uid: "' '{print $2}' |awk -F '"' '{print $1}'|sort -u>uid.txt
cat xx.log.notice |awk -F 'cuid: "' '{print $2}' |awk -F '"' '{print $1}'|sort -u>cuid.txt
找到以xx开头的 从第二列开始截取 ,找到以yy结尾的 截取第一列
52. 截取字符串中的某个字符,去重写到新的文件

cat new.txt |awk -F 'pre_xx"' '{print $2}'|awk -F '],' '{print $1}'|sed 's#:\[##g'|sort -u>sortnew.txt
cat new.txt |awk -F 'pre_xx"' '{print $2}'|awk -F '],' '{print $1}'|sed 's/:\[//g'|sort -u>sortnew.txt
cat xx.dict|awk -F 'history_bots":' '{print $2}'|awk -F '],' '{print $1}'|sort -u
51. head : -n 指定获取前几行。 例如命令: ifconfig |head -n2 表示只查看ifconfig的前两行,而tail -n 是指定查看后几行。如果想要查看ifconfig的第二行,则先输入命令:ifconfig |head -n2 用enter键确认,然后在输入命令:ifconfig |head -n2 |tail -n1 即可。就可以实现只看ifconfig 的第二行
cat filename |head -n5|tail -n2
Linux如何通过命令查看日志文件的某几行(中间几行或最后几行)
linux 如何显示一个文件的某几行(中间几行)
【一】从第3000行开始,显示1000行。即显示3000~3999行
cat filename | tail -n +3000 | head -n 1000
【二】显示1000行到3000行
cat filename| head -n 3000 | tail -n +1000
*注意两种方法的顺序
分解:
tail -n 1000:显示最后1000行
tail -n +1000:从1000行开始显示,显示1000行以后的
head -n 1000:显示前面1000行
【三】用sed命令
sed -n '5,10p' filename 这样你就可以只查看文件的第5行到第10行
50. linux中利用find命令分析日志,统计包含某字符串的行数
一、日志中,包含某条件的行数
find access_log.20160423.txt | xargs cat | grep .*POST\\s\\/upload\\/zyb-prd.*|wc -l
例子说明:统计含"POST /upload/zyb-prd"字符串的总行数
二、日志中,不包含某条件的行数
find access_log.20160423.txt | xargs cat | grep -v .*HEAD\\s\\/favicon.ico.*|wc -l
例子说明:统计不含"HEAD /favicon.ico"字符串的总行数
额外技能:查找文件夹下,查找包含某一个字符串的文件
# find
-type f 说明,只找文件
-name "*.c" 表示只找C语言写的代码,从而避免去查binary;也可以不写,表示找所有文件
实际操作:
需求一个词典文件,一共多少行。统计包含entities的行是此次的新协议支持的格式,不包含entities的行是老的协议。分别写到不同的文件
首先查看词典文件总行数
cat filename.dict|wc -l 997行
查找文件下不含entities的行,统计次数,写到文件
find filename| xargs cat | grep -v entities|wc -l 或者 cat filename|grep -v entities|wc -l 2行
find filename| xargs cat | grep -v entities>old.txt 或者 cat filename|grep -v 'entities'>old.txt
查找文件下含entities的行,统计次数,写到文件
find filename| xargs cat | grep entities|wc -l 或者 grep -c 'entities' filename 995行
find filename | xargs cat | grep entities>new.txt 或者 cat filename|awk -F 'entities' '{print $0}'>new.txt
49. vim模式下输入tab键盘拆分字符串

先按下 :set noex按下tab
会变成:set noexpandtab
此时在b bbb中间按下tab即可插入tab分割
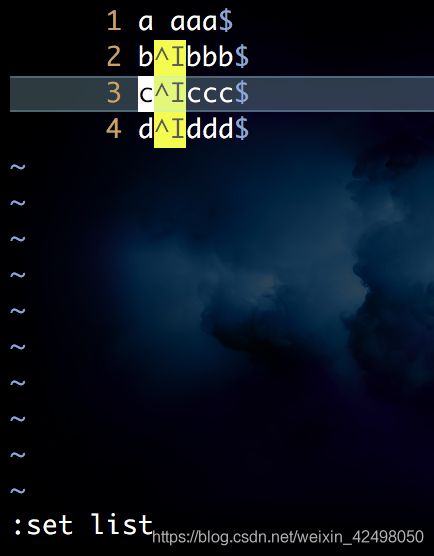
插入tab后按下:set list即可展示tab ,a aaa中间为空格不为tab

按下:set nolist 展示如上
:set list
发现空格大量存在 需要替换为tab
:%s/ /^I
1、文件中有 TAB 键的时候,你是看不见的。要把它显示出来:
:set list
:set list2.设定tab的位置
:set tabstop=4
:set tabstop=43.输入tab时自动将其转化为空格
:set expandtab
:set expandtab48. vim模式下查找字符,不想模糊查找如LP20 有的为LP201也会被命中 则查询的时候在LP20 后加个tab表示空格
47. 显示日志中第N行 如第2行 sed -n '2p' 1.txt
显示日志中从第M行到第N行 如第1行到第3行 sed -n '1,3p' 1.txt
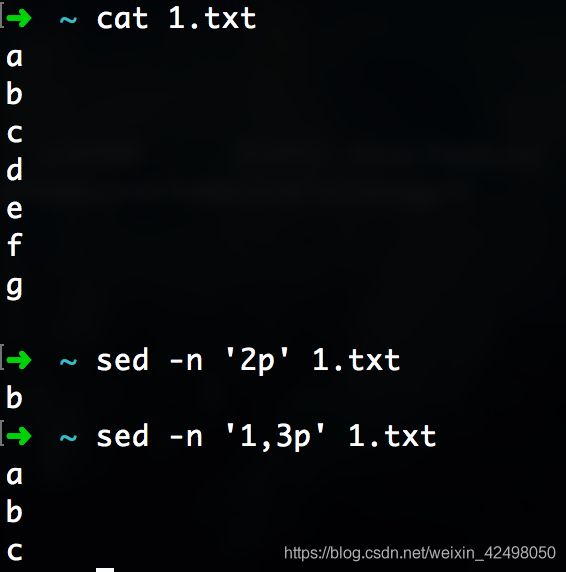
显示第240339到240342行日志
sed -n '240339,240342p' rpc.log
46. linux文件夹打包命令
压缩文件夹
tar -zcvf report0305.tar.gz report0305/
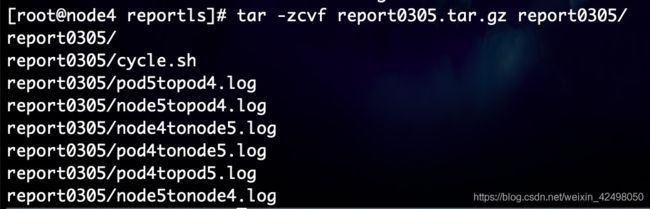
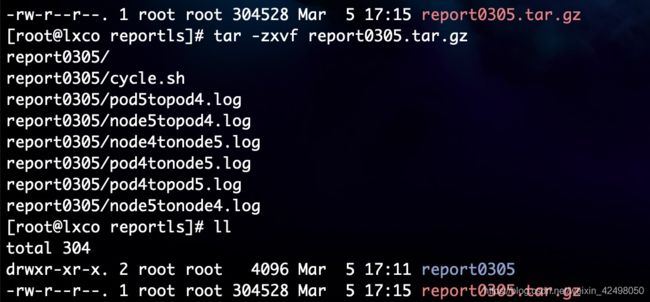
解压缩文件夹
tar -zxvf report0305.tar.gz
.tar
解包:tar xvf FileName.tar
打包:tar cvf FileName.tar DirName
(注:tar是打包,不是压缩!)
---------------------------------------------
.gz
解压1:gunzip FileName.gz
解压2:gzip -d FileName.gz
压缩:gzip FileName
.tar.gz
解压:tar zxvf FileName.tar.gz
压缩:tar zcvf FileName.tar.gz DirName
---------------------------------------------
.tgz
解压:tar zxvf FileName.tgz
压缩:未知
.tar.tgz
解压:tar zxvf FileName.tar.tgz
压缩:tar zcvf FileName.tar.tgz FileName
45. 文件为2列,只取第一列,并在第一列后面增加逗号, 转成自动化代码需要的格式
cat dict.txt | awk '{print $1}' > 1.txt
sed 's/$/,/g' 1.txt >2.txt
或者一条命令也可以
cat dict.txt | awk '{print $1}' | sed 's/$/,/g' 1.txt > 3.txt
处理为如下格式
11 LP_4993,
12 LP_348,
13 LP_554,
处理词典 cat skill_list_dict |awk '{print $1}'|sed 's/$/,/g' > skill_list_dict.deal
处理词典库 cat xx_skill_dict |awk '{print $1}'|sed 's/$/,/g' > xx_skill_dict.deal

截取systemId字段
cat skill_list_dict |awk -F '"systemId": "' '{print $2}'|awk -F '",' '{print $1}' > systemId.txt
在文件每行后添加,
cat skill_list_dict |awk -F '"systemId": "' '{print $2}'|awk -F '",' '{print $1}'|sed 's/$/,/g'> systemId.txt
在文件每行后添加, 生成的文件去重
cat skill_list_dict |awk -F '"systemId": "' '{print $2}'|awk -F '",' '{print $1}'|sort -u |sed 's/$/,/g'> systemId.txt

44. vim模式下删除当前行后面所有的行
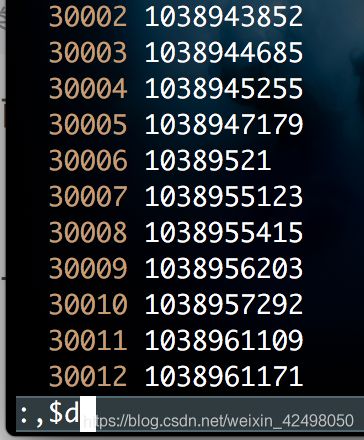
按下esc :
,$d
如400万行,找到3万行 :set nu (显示行数) :30000 (跳到第3万行)
vim模式下删除第一行到当前行
按下esc :
1,.d
命令行模式下按b,将光标定位到单词首字母
按 dw 即可删除单词
43. ll几个比较常用的参数
-t 按最后修改时间排序
-S 按文件大小排序(大写的S)
-r 排序时按倒序
-h 显示文件大小时增加可读性 (例:1K 234M 2G)
如果这个aa是个普通文件,2就代表这个文件有2个别名(这个文件被人创建了一个硬链接文件)
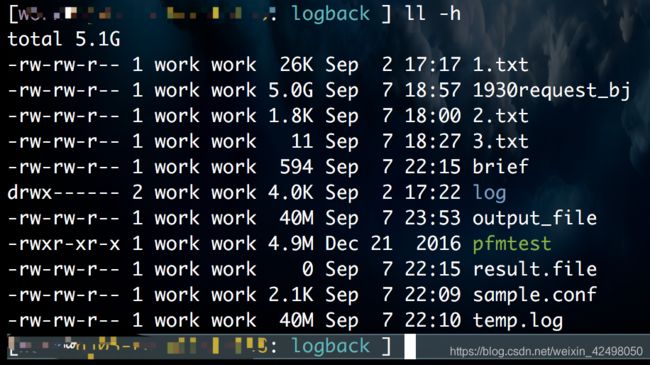
42. cat 2.txt|awk -F 'userid:qa_test_lishan10_' '{print $2}'|awk -F ']' '{print $1}' | sort -u >3.txt
找到 以为userid 的字符 截它取从后面的第二个$2 |找到以 ] 结束的字符。把找到的字符串去重。最终按一行$1打印出来
文本中可能有重复的userid,文件文本去重
sort -u filename1.txt >filename2.txt
截取日志文件里的请求。最后一个]去不掉
cat debug_trace.log |awk -F '\\[ai.xxt\\] \\[ouput\\:' '{print $2}'|awk -F '{print $(NF-1)}' '{print $1}'|sort -u >rslog.txt
echo ${$(cat headlog.txt|awk -F '\\[ai.xx.bot.xx_request\\] \\[ouput\\:' '{print $2}'|awk -F '{print $(NF-1)}' '{print $1}'|uniq)%?}
截取日志中的userid
head -10 request.log|grep realUserId|awk -F 'realUserId":"' '{print $2}'|awk -F '",' '{print $1}'|sort -u
41. 如遇
[user@hostname xx]$ rm -rf xx
mv: invalid option -- r
Try `mv --help' for more information.
不知道是谁配置了alias
vim ~/.bashrc
找到rm
alias rm = 'trash'; 删除
记得source ~/.bashrc
参考博客 https://blog.csdn.net/bug_love/article/details/78496590
40. linux根据进程查端口,端口查进程
根据进程pid查端口:netstat -nap | grep pid
根据端口port查进程:netstat -nap | grep port
根据pid查找文件的启动位置 ps aux | grep 进程,把找到的pid在/proc/pid|port的下方有一个为cwd对应的路径就是程序启动的路径
根据服务查进程 -- 根据主进程查端口,注意是主进程(第一列) -- 根据端口查服务路径

[user@hostname: path ] ps -ef|grep recommend|grep -v grep // 根据服务查进程pid (主子进程)
work 27822 27821 6 06:43 ? 00:50:27 ./bin/recommend
[user@hostname: path ] netstat -nap | grep 27822 // 根据主进程查端口port,注意是主进程
tcp 0 0 0.0.0.0:8116 0.0.0.0:* LISTEN 27822/recommend
[user@hostname: path ] ll /proc/8116/cwd // 根据端口port查服务代码路径path。推荐端口查进行
lrwxrwxrwx 1 work work 0 Sep 4 20:23 /proc/8116/cwd -> /home/path/bin
推荐以上的方法
[user@hostname: path ] ll /proc/27822/cwd // 根据主进程pid查服务代码路径path
lrwxrwxrwx 1 work work 0 Sep 6 17:18 /proc/27822/cwd -> /home/path/rs_audio
[user@hostname: path ] ll /proc/27821/cwd // 根据子进程pid查服务代码路径path
lrwxrwxrwx 1 work work 0 Sep 6 17:18 /proc/27821/cwd -> /home/path/rs_audio
14700为主进程pid 14696为子进程pid

1. 根据进程pid查端口 lsof -i | grep pid 注意pid是主进程!!!
2. 根据端口port查进程 lsof -i:port
3. 根据进程pid查端口 netstat -nap | grep pid 注意pid是主进程!!!
4. 根据端口port查进程 netstat -nap | grep port
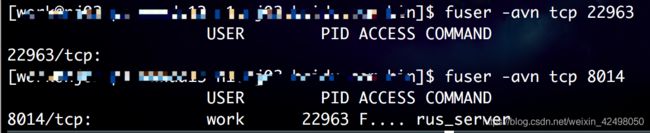
5. 根据端口port查进程 fuser -avn tcp 8014
根据进程pid查端口port
netstat -nap|grep 22963 注意是主进程非子进程pid
第一行LISTEN的就是 ,第二行是配置文件的第二个端口,在第一行基础上+1
tcp最大连接数是1000
当应用程序以socket 端口的形式对外提供TCP服务时,会出现监听句柄LISTEN
外部客户端与服务端建立连接时,会在服务端内部生成连接句柄,而连接句柄根据TCP/IP的三次握手和四次挥手,会有不同的状态机
established 就是客户端与服务器成功建立连接时的一种状态

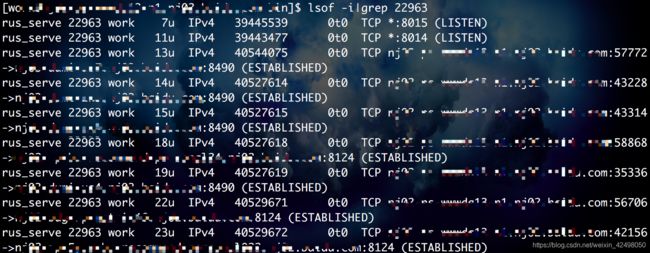
lsof -i|grep 22963 注意是主进程非子进程pid
servername 22963 work 13u IPv4 40544075 0t0 TCP hostname1(现在登录的):57772->hostname2:8490 (ESTABLISHED)
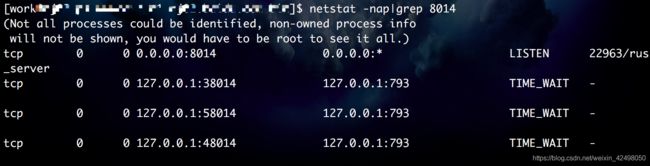
根据端口port查进程pid
netstat -nap|grep 8014
4行
tcp 0 0 0.0.0.0:8014 0.0.0.0:* LISTEN 22963/servername
tcp 0 0 127.0.0.1:38014 127.0.0.1:793 TIME_WAIT -
tcp 0 0 127.0.0.1:58014 127.0.0.1:793 TIME_WAIT -
tcp 0 0 127.0.0.1:48014 127.0.0.1:793 TIME_WAIT -
lsof -i:8014
第二行

COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
servername 22963 work 11u IPv4 39443477 0t0 TCP *:8014 (LISTEN)
fuser -avn tcp 8014
USER PID ACCESS COMMAND
8014/tcp: work 22963 F.... servername
work@hostname ~]$ netstat -nap|grep 8114
(Not all processes could be identified, non-owned process info
will not be shown, you would have to be root to see it all.)
tcp 0 0 0.0.0.0:8114 0.0.0.0:* LISTEN 45012/rus_server
tcp 0 0 ip:8114 172.24.191.68:64585 ESTABLISHED 45012/rus_server
tcp 0 0 127.0.0.1:28114 127.0.0.1:793 TIME_WAIT -
tcp 0 0 127.0.0.1:18114 127.0.0.1:793 TIME_WAIT -
tcp 0 0 127.0.0.1:58114 127.0.0.1:793 TIME_WAIT -
tcp 0 0 127.0.0.1:38114 127.0.0.1:793 TIME_WAIT -
[work@hostname ~]$ netstat -nap|grep 8114|grep LISTEN|awk '{print $7}'|awk -F '/' '{print $1}'
45012
第7列是pid进程id/severname服务名称 找打/前面的算$1
39. Linux中查看当前文件夹下各文件夹大小命令
// 查看系统中文件的使用情况
df -h
// 查看当前目录下各个文件及目录占用空间大小
du -sh *
// 查看各文件夹大小
du -h --max-depth=1
38. tail -n +20 filename 是从文件第二十行开始显示 而不是显示前面二十行
tail -n 10 #输出文件最后10行的内容
tail -n1 filename 输出文本最后一行

37. tcp详解 https://blog.csdn.net/sinat_36629696/article/details/80740678
36. Linux下根据进程号查找程序路径
背景:有一个服务,只知道它占用的端口号是8703,但是不知道它的路径在哪儿。
思路:
- 先根据端口号查找pid(进程号)
netstat -nlp | grep 22
结果如下:
unix 2 [ ACC ] STREAM LISTENING 12249 -
12249就是它的pid(进程号)
- 再根据进程号查找路径,如下:
ll /proc/12499/cwd
cwd后面的路径就是端口号8703程序的路径
实际操作
netstat -nap|grep port
LISTEN后面是pid
ll /proc/pid/cwd
根据进程pid找到程序路径
[user@hostname: path] netstat -nap|grep 8503
tcp 0 0 0.0.0.0:8503 0.0.0.0:* LISTEN 8884/recommend
tcp 0 0 10.xx.67.35:8503 10.xx.xx.xx:62005 ESTABLISHED 8884/recommend
tcp 0 0 10.xx.xx.xx:8503 xx.xx.xx.xx:54394 ESTABLISHED 8884/recommend
tcp 0 0 10.xx.xx.xx:8503 xx.xx.xx.xx:63111 ESTABLISHED 8884/recommend
[user@hostname: path ] ll /proc/8884/cwd
lrwxrwxrwx 1 work work 0 Sep 3 13:57 /proc/8884/cwd -> /home/xx/xx/xx/output

35. 在Linux下用VIM打开大小几个G、甚至几十个G的文件时,是非常慢的
这时,我们可以利用下面的方法分割文件,然后再打开
1 查看文件的前多少行并写入到新的文件
head -10000 /var/lib/mysql/slowquery.log > temp.log
上面命令的意思是:把slowquery.log文件前10000行的数据写入到temp.log文件中
1. 截取时间段
截取 2019-06-25 10:10 到 2019-06-25 10:20 之间的日志记录,apollo-service.log 为你要截取的文件名称, new2.log 截取之后保存日志的文件名称。
sed -n '/2019-06-25 10:10/, /2019-06-25 10:20/p' catalina.out > new1.log
sed -n '/2019-06-25 10:20:47/, /2019-06-25 10:26:47/p' catalina.out > new2.log
sed -n '/2019-06-25 10:20:47.728/, /2019-06-25 10:26:47.728/p' catalina.out > new3.log
说明:时间段可根据自己的需要进行修改,可精确到毫秒。
2. 截取行数
截取 catalina.out 文件中的100 - 500 行的日志, new.log 为截取保存之后的文件。
sed -n '100,500'p apollo-service.log > new.log
2 查看文件的后多少行并写入到新的文件
tail -10000 /var/lib/mysql/slowquery.log > temp.log
3 Linux 或 类Unix 下实现合并多个文件内容到一个文件中
cat req_file_* > all_file_old
head -100 alllog0909 查看文件前多少行
tail -100 alllog0909 查看文件后多少行
查看文件最后一行
34. 查询日志某个时间段的日志
sed -n '/^2018-08-17 14:29/,/^2018-08-17 14:30/p' info.log.20180817|grep 5000
grep "20-09-02 14:26:56" filename.2020090214 --color
我要查shop-bussiness.log.2018-11-06文件中2018年11月6号11:34至11点37之间的日志信息,可以这么做:
grep '2018-Nov-06 11:3[4-7]' shop-bussiness.log.2018-11-06
注意开始和结束在文件要有shell的开始时间和结束时间这行,如日志中没有20-09-03 14:15:33这行则查询不出来
sed -n '/20-09-03 14:14:59/,/20-09-03 14:29:53/p' filename.log.2020090314
sed -n '/20-09-03 14:14:*/,/20-09-03 14:29:*/p' filename.log.2020090314 模糊查找好些
grep -e '2020-09-03 14:14:*' -e '2020-09-03 14:29:*' filename.log.2020090314
33. Linux中在当前目录下查找某个文件
find / -iname centOS-7-x86_64-DVD-1810.iso 精准查找需要输入文件全称
find / -name centOS-7-x86_64-DVD-1810.iso CentOS为大写首字母,精准查找不到,需要用 -iname忽略大小写

find . -name "filename"
find . -name doudi_skill_dict
doudi_skill_dict是在此路径下

linux全局查询文件
在工作中,可能突然需要找到某个文件,但是又不知道在那个位置,需要全局查询一下。下面是命令行:
建议进入某个文件夹减小搜索返回
第一种:
find / -name "*.log" | xargs grep "vl" /:意思是从/开始进行查找。
意思是包含“vl”的行。
不区分大小写
实际操作
find -iname "vod_alias_seg.txt"
find . -name "vod_alias_seg.txt"
find / -name "vod_alias_seg.txt" | xargs grep "vl"

32. linux下全局替换字符
执行如下sed -i "s/len/size/g" `grep len -rl ./`
其中,
len为原字符串
size为目标字符串
-rl是递归查找所有包含字符串len的文件
实际操作
sed -i "s/”/\"/g" `grep ” -rl ./`
把日志中的_t:换成_t: 格式
sed -i "s/_t:/_t: /g" `grep _t: -rl ./xx.log.notice*`
31. vim模式下复制多行
如果有一条数据,直接按数字1999p 显示多了1999行
按500p就是加500行

yy复制一行
在命令行模式下5y回车可以复制5行 如一共1000行,当前在700行,执行500yy p 则复制了300行,一共1300行
p粘贴 复制的内容
删除当前行 dd
删除当前行以下所有行 跳转到指定行如:200 再dG
30. linux 除了某个文件或某个文件夹以外全部删除
find . -maxdepth 1 ! -name 0824all/ -exec rm -f {} \;
删除logs下非当前日期的日志
tail -n 100 info.log.20180531 |grep -E 'userId:434|userId:417|userId:418|userId:433|userId:434'
ls | grep -v -E "0531|sys.log" | xargs sudo rm -f
ls |grep -E -v '0612|sys.log' |xargs sudo rm -rf
29. 普通模式下的快捷键
快捷键 说明
i insert, 在光标所在处输入
I 在当前光标所在行的行首输入
a append, 在光标所在处后面输入
A 在当前光标所在行的行尾输入
o 在当前光标所在行的下方打开一个新行
O 在当前光标所在行的上方打开一个新行
ZZ 保存退出
ZQ 不保存退出
:q 退出
:q! 强制退出,丢弃做出的修改
:wq 保存退出
:x 保存退出
命令模式
di" 光标在" "之间,则删除" "之间的内容
yi( 光标在()之间,则复制()之间的内容
vi[ 光标在[]之间,则选中[]之间的内容
dtx 删除字符直到遇见光标之后的第一个 x 字符
ytx 复制字符直到遇见光标之后的第一个 x 字符
字符间跳转:
h: 左 l: 右 j: 下 k: 上
#COMMAND:跳转由#指定的个数的字符
单词间跳转:
w:下一个单词的词首
e:当前或下一单词的词尾
b:当前或前一个单词的词首
#COMMAND:由#指定一次跳转的单词数
当前页跳转:
H:页首 M:页中间行 L:页底
zt:将光标所在当前行移到屏幕顶端
zz:将光标所在当前行移到屏幕中间
zb:将光标所在当前行移到屏幕底端
行首行尾跳转:
^: 跳转至行首的第一个非空白字符
0: 跳转至行首
$: 跳转至行尾
行间移动:
#G :扩展命令模式下:# 跳转至由#指定行
G:最后一行
1G, gg: 第一行
句间移动:
):下一句(:上一句
终端非vim模式下,按option+键盘左右为向前向后。control+A跳到终端模式下最前面,control+E跳到末尾
28. 查看文件行数 wc -l filename
或者vim模式shift+G


"all_file_old" 13993L, 7078991C
27. rm同时删除多个文件 rm -rf A B C
26. & 放在命令后面表示设置此进程为后台进程
默认情况下,进程是前台进程,这时此进程(命令执行相当于本质是开启一个进程)就把Shell给占据了,我们无法进行其他操作,对于那些没有交互的进程,很多时候,我们希望将其在后台启动,可以在启动参数的时候加一个'&'实现这个目的
不加& 是前台执行,一直到执行结束 或者手动Ctrl+C 中断
加了& 是后台执行,后台执行完 也会在console打印结果(如果你的远程连接一直都在,没有从新连接过)
第一行加了&的 就退到后台去执行了 屏幕输出的 11886 是对应的进程号
所以console看不到执行过程,只会再执行完之后,屏幕给你一个结束的信息
不加& 始终在执行过程中,除非中断。输出的只有任务本身执行的输出信息,不会有进程号
./bin/xx start &
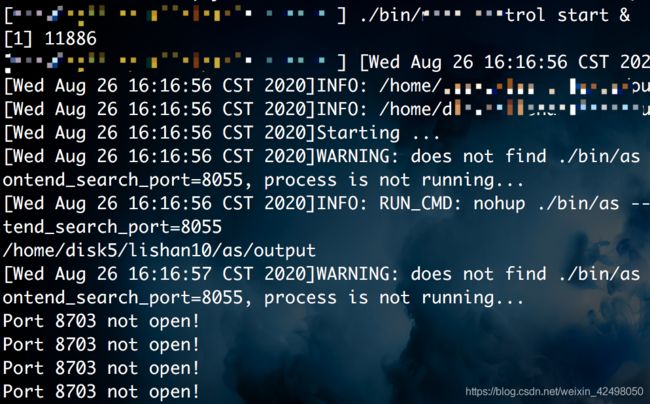
./bin/xx start

25. Linux 或 类Unix 下实现合并多个文件内容到一个文件中
cat req_file_* > all_file_old
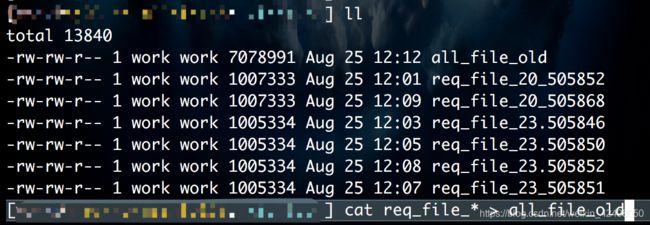
24. Linux统计文本中某个字符串出现的次数
vim模式下 :%s/findName//gn
非vim模式grep -o "findName" req_file.7 |wc -l

grep -o "self_t" ./xx.log.notice*|wc -l
23. vim模式
删除当前行2000,以下的全部行
shift+G到行尾或者2000G,按下shift+:
输入 :2000,.d 删除2000行以后的内容
22. mac地址/物理地址
ifconfig -a
en0下的ether就是物理地址

21. 启动服务后
第一次查询端口占用情况显示未被占用。原因:服务还没启动完成
第二次查询端口占用情况显示一行LISTEN,未显示ESTABLISHED。原因:服务未被请求,不会有ESTABLISHED
ESTABLISHED的意思是建立连接。表示两台机器正在通信。当访问接口后,再次查看端口,此时有了ESTABLISHED
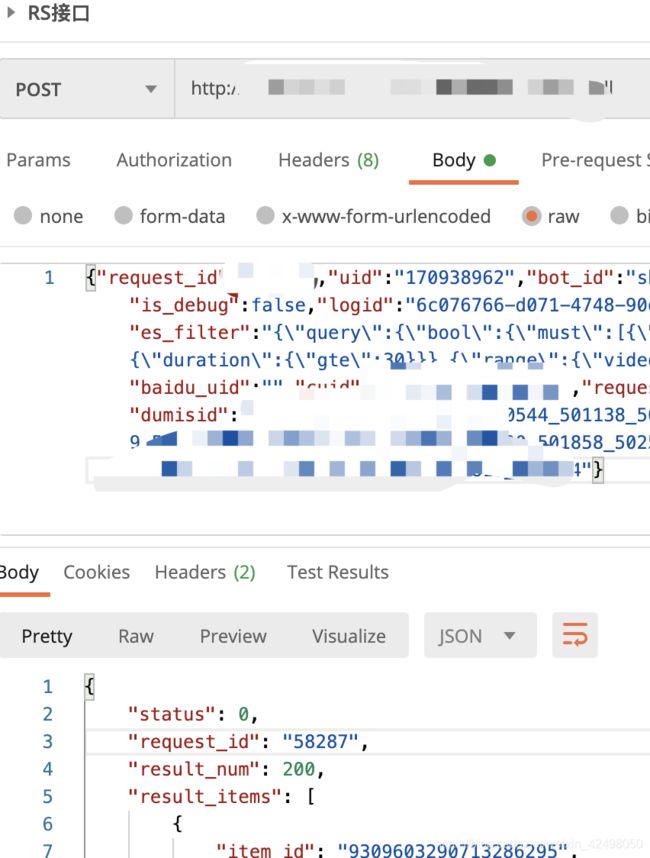
20. 远程机器拷贝
scp filename为文件 scr -r filedict 为文件夹
scp -r A机器的filename或者file路径/ username@ip:/B机器文件的路径
如拷贝A机器的/a/b/c/d到B机器的/e/
B机器的ip为10.10.1.1
登录A机器
scp -r /a/b/c/d [email protected]:/e/f
登录B机器查看/e/f有了d文件
复制目录命令格式:
scp -r local_folder remote_username@remote_ip:remote_folder
或者
scp -r local_folder remote_ip:remote_folder

或者sz rz
拷贝远程机器的文件到本机
scp work@remoteServerName:/home/xx/xx/filename ./
同机器拷贝
cp -r A/ B
如果A文件夹过大,可以去B目录查看字节数以及时间。或者看B的文件夹外层更新时间
drwxrwxr-x 16 work work 4096 Aug 19 13:12 B
drwxrwxr-x 16 work work 4096 Aug 19 13:14 B
等拷贝完成 cp -r A/ B 也会在命令行下出一行回行显示机器的信息
cp显示拷贝进度
一段比较好的显示拷贝进度的shell代码
#!/bin/bash
PARAM_LIST=$*
PARAM_NUM=$#
TOTAL_SIZE=0
for((i = 0; i < PARAM_NUM - 1; i++))
do
[ ! -r $1 ] && echo "Cannot read $1." && exit 1
SIZE=`du -s $1 | awk '{print $1}'`
((TOTAL_SIZE = TOTAL_SIZE + SIZE))
shift
done
TARGET=$1
START_TIME=`date +%s.%N`
cp -a $PARAM_LIST &
echo -ne "Total size: $TOTAL_SIZE KB - %"
while true
do
LEN_PERCENT=${#PERCENT}
for((i = 0; i <= LEN_PERCENT; i++))
do
echo -ne "/b"
done
COPIED=`du -s $TARGET | awk '{print $1}'`
((PERCENT = COPIED * 100 / TOTAL_SIZE))
echo -ne "$PERCENT%"
((PERCENT == 100)) && END_TIME=`date +%s.%N` && break
done
MB_SECOND=`echo $TOTAL_SIZE/1024//($END_TIME-$START_TIME/)|bc`
echo " - SPEED: $MB_SECOND MB/s"
文件 AB同级目录 cp A B B会覆盖之前B的内容
19. 之前的公司Jenkins脚本里有编译go等的shell脚本(拉代码 编译 上传 下载 移动文件夹 重启服务等),如果直接拿源码还需要搭建编译环境,自己编译,产出编译文件。这边直接拿编译后的编译产出wget到服务器
18. php是解释性语言 不需要编译。golang Java C C++ 都需要编译的
17. 解压缩tar.gz文件,tar.gz在macOS和Linux下常见
tar -zxvf output.tar.gz
或者 tar -xf output.tar.gz
格式:tar zcvf 压缩后的路径及包名 你要压缩的文件
z:gzip压缩
c:创建压缩包
v:显示打包压缩解压过程
f:接着压缩
t:查看压缩包内容
x:解压
X:指定文件列表形式排除不需要打包压缩的文件或目录
-exclude:指定排除文件或目录不需要打包压缩的文件或目录(也可以用正则匹配/通配符等)
-C:解压到指定目录
移动文件A到上层目录 mv A/ ./..
解压缩 filename.tgz格式
tar -zxvf filename.tgz -C ./
压缩文件 把当前目录下的tools打包为tools.zip压缩包 zip -r tools.zip ./tools
解压缩 unzip tools.zip
16. Linux查看端口的占用情况并找出并杀死占用进程的方法
fuser -v -n tcp 8702
fuser -avn tcp 8503
fuser 可以显示出当前哪个程序在使用磁盘上的某个文件、挂载点、甚至网络端口,并给出程序进程的详细信息.
fuser只把PID输出到标准输出,其他的都输出到标准错误输出
-a 显示所有命令行中指定的文件,默认情况下被访问的文件才会被显示。
-c 和-m一样,用于POSIX兼容。
-k 杀掉访问文件的进程。如果没有指定-signal就会发送SIGKILL信号。结合 –signal
-signal 使用指定的信号,而不是用SIGKILL来杀掉进程。可以通过名称或者号码来表示信号(例如-HUP,-1),这个选项要和-k一起使用,否则会被忽略。
-l 列出所有已知的信号名称。
-i 杀掉进程之前询问用户,如果没有-k这个选项会被忽略。
-m name 指定一个挂载文件系统上的文件或者被挂载的块设备(名称name)。这样所有访问这个文件或者文件系统的进程都会被列出来。如果指定的是一个目录会自动转换成"name/",并使用所有挂载在那个目录下面的文件系统。
-n space 指定一个不同的命名空间(space).这里支持不同的空间文件(文件名,此处默认)、tcp(本地tcp端口)、udp(本地udp端口)。对于端口,可以指定端口号或者名称,如果不会引起歧义那么可以使用简单表示的形式,例如:name/space (即形如:80/tcp之类的表示)。
-s 静默模式,这时候-u,-v会被忽略。-a不能和-s一起使用。
-u 在每个PID后面添加进程拥有者的用户名称。
-v 详细模式。输出似ps命令的输出,包含PID,USER,COMMAND等许多域,如果是内核访问的那么PID为kernel.
发现此端口对应Nginx的2个进程,需要杀掉进程号28243 28244。截图里的命令笔误输入错了
用户 进程号 权限 命令
8702/tcp: work 28243 F.... nginx
work 28244 F.... nginx
kill -s 9 28243
kill -s 9 28244

批量杀进程
lsof -i:8503|awk '{print $2}'|xargs kill -9

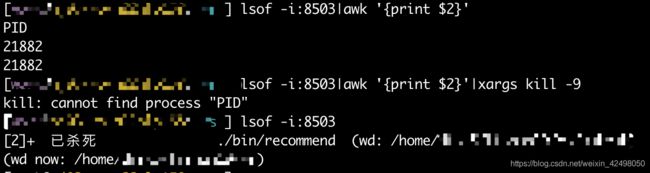
netstat -naptul|grep port用来查看系统当前系统网络状态信息,包括端口,连接情况
用fuser查看哪些用户和进程在某些地方作什么
fuser -v -n tcp 8503
fuser -cu /root 简略显示
fuser -muv /mnt3 分列显示
lsof -i:port的作用是列出当前系统打开文件(list open files),不过通过-i参数也能查看端口的连接情况,-i后跟冒号端口可以查看指定端口信息,直接-i是系统当前所有打开的端口
lsof 拥有更多的功能
# lsof -i 看系统中有哪些开放的端口,哪些进程、用户在使用它们,比 netstat -lptu 的输出详细
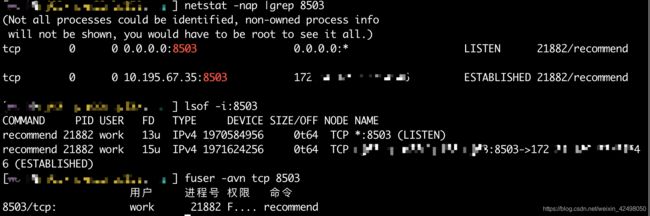
根据端口查看占用进程/服务端 pid
$ netstat -nap|grep 8000
tcp 0 0 0.0.0.0:8000 0.0.0.0:* LISTEN 8183/nginx -g
发现8000端口对应的进程是8183,服务为nginx
查看进程/服务占用情况 ps -ef|grep pid
查看进程主子进程 ps -ef|grep pid|grep -v grep|awk '{print $2}'
批量杀进程ps -ef|grep 8183|grep -v grep|awk '{print $2}'|xargs kill -9
重启服务 如webserver/loadnginx.sh start
启动后,查看8000端口占用情况,此时进程pid变了新的
$ netstat -nap|grep 8000
tcp 0 0 0.0.0.0:8000 0.0.0.0:* LISTEN 14477/nginx -g
15. Linux下有三个命令:ls、grep、wc。通过这三个命令的组合可以统计目录下文件及文件夹的个数
统计当前目录下文件的个数(不包括目录)
$ ls -l | grep "^-" | wc -l
-rw-rw-r--
统计当前目录下文件的个数(包括子目录)
$ ls -lR| grep "^-" | wc -l
-rw-rw-r--
统计当前文件夹下目录的个数(不包括目录)
$ ls -l |grep "^d"|wc -l
drwxrwxr-x
查看某目录下文件夹(目录)的个数(包括子目录)
$ ls -lR | grep "^d" | wc -l
drwxrwxr-x
实际操作

14. hostname 查看host
hostname -i 查看ip地址

13. shell只能用相对路径,绝对路径无法执行的原因?
如 cd /A/B/C
./filename restart
但是./A/B/C/filename restart则会报错
12. 不挂断地运行命令 nohup ./a 2>&1 > /dev/null &
https://www.jb51.net/article/169783.htm
这条命令的意思是将标准输出和错误输出全部重定向到/dev/null中,也就是将产生的所有信息丢弃
后台运行,然后对于输出的内容丢弃不存储。后台运行并重定向输出
nohup命令:如果你正在运行一个进程,而且你觉得在退出帐户时该进程还不会结束,那么可以使用nohup命令。该命令可以在你退出帐户/关闭终端之后继续运行相应的进程。nohup就是不挂起的意思( n ohang up)
该命令的一般形式为:nohup command &
nohup sh rs_log_xx.sh /home/xx/xx/xx/output/log 7 &
执行完显示进程号,结束进程号变为Done

nohup python xx.py v1 v2 &
会输出一个进程号

[1] 34301
nohup: appending output to ‘nohup.out’
查看这个进程 ps -ef|grep 34301
会看到>/dev/null 2>&1
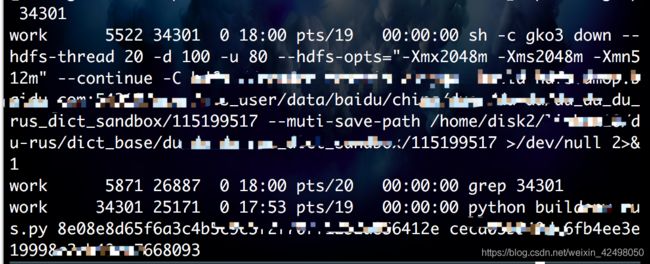
结束会自动显示一行[1]+ Exit 1

11. 解释nohup, /dev/null 2>&1,输出重定向
Linux shell中有三种输入输出,分别为标准输入,标准输出,错误输出,分别对应0,1,2。我们可以直接通过输出重定向>(或>>,表示追加)将某种输出重定向到其他地方,如设备,文件,比如:
1 |
ls > ls.log #标准输出重定向 |
2 |
ls 2> ls.log #标准错误重定向 |
3 |
ls > /dev/null #重定向到null设备,相当于直接忽略输出 |
但是,有时候,我们想把标准输出以及错误输出一起重定向某个文件,这是可以通过 2>&1 实现,也可以通过两个同时重定向到某个文件
1 |
ls >ls.log 2>&1 //标准输出重定向到ls.log,而错误又重定向到标准输出,这两个位置不可换 |
2 |
|
先说一下linux重定向:
0、1和2分别表示标准输入、标准输出和标准错误信息输出,可以用来指定需要重定向的标准输入或输出。
在一般使用时,默认的是标准输出,既1.当我们需要特殊用途时,可以使用其他标号。例如,将某个程序的错误信息输出到log文件中:./program 2>log。这样标准输出还是在屏幕上,但是错误信息会输出到log文件中。
另外,也可以实现0,1,2之间的重定向。2>&1:将错误信息重定向到标准输出。
Linux下还有一个特殊的文件/dev/null,它就像一个无底洞,所有重定向到它的信息都会消失得无影无踪。这一点非常有用,当我们不需要回显程序的所有信息时,就可以将输出重定向到/dev/null。
如果想要正常输出和错误信息都不显示,则要把标准输出和标准错误都重定向到/dev/null, 例如:
# ls 1>/dev/null 2>/dev/null
还有一种做法是将错误重定向到标准输出,然后再重定向到 /dev/null,例如:
# ls >/dev/null 2>&1
注意:此处的顺序不能更改,否则达不到想要的效果,此时先将标准输出重定向到 /dev/null,然后将标准错误重定向到标准输出,由于标准输出已经重定向到了/dev/null,因此标准错误也会重定向到/dev/null,于是一切静悄悄:-)
由于使用nohup时,会自动将输出写入nohup.out文件中,如果文件很大的话,nohup.out就会不停的增大,这是我们不希望看到的,因此,可以利用/dev/null来解决这个问题。
nohup ./program >/dev/null 2>log &
如果错误信息也不想要的话:
nohup ./program >/dev/null 2>&1 &
nohup sh cycleUdp.sh 2>&1|tee node4tonode5UDP.log &
Linux tee命令用于读取标准输入的数据,并将其内容输出成文件。
tee指令会从标准输入设备读取数据,将其内容输出到标准输出设备,同时保存成文件。
10. [文本处理] 多列合并一行的SHELL,以,隔开
➜ ~ awk '{a=a?a","$1:$1;b=b?b","$2:$2}END{print a,b}' 1.txt

9. 在每行的头添加字符,比如"HEAD",命令如下:
sed 's/^/HEAD&/g' test.file
在每行的行尾添加字符,比如“TAIL”,命令如下:
sed 's/$/&TAIL/g' test.file
实际运用:把文件1.txt的内容在每行结尾添加,写到2.txt

➜ ~ sed 's/$/&,/g' 1.txt > 2.txt

8. 批量替换文件夹子文件夹的文件xx为yy
sed -i 's/xx/yy/g' `grep xx -rl ./`
注:后面为esc下面的` 不为'

7. linux命令统计文件中某个字符串出现的次数
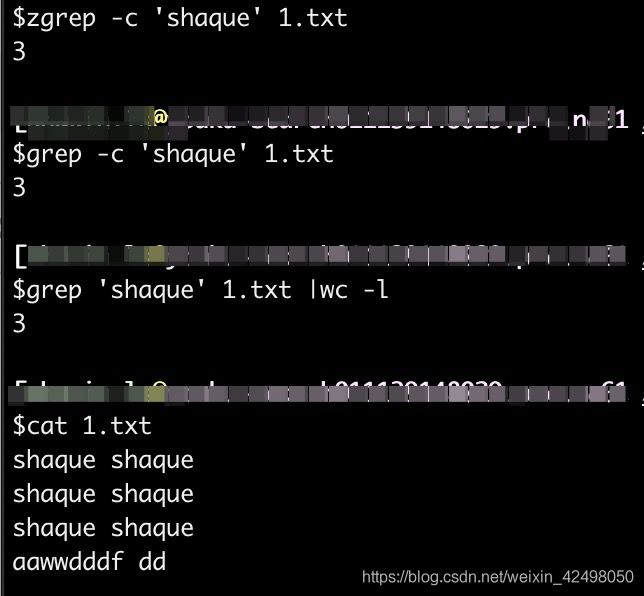
用vim打开目标文件,在命令模式下,输入::%s/object/&/gn
&代表s// 搜索出来的内容
g代表全局替换(而非仅仅当前行)
n代表不执行,只是预览一下会有什么情况发生
执行前效果和执行后效果如图所示:
:%s/xx/&/gn

非vim模式:
zgrep -c 'xx' 1.txt
grep -c 'xx' 1.txt
grep 'xx' 1.txt |wc -l
6. top命令

用 'top -i' 看看有多少进程处于 Running 状态,可能系统存在内存或 I/O 瓶颈,用 free 看看系统内存使用情况,swap 是否被占用很多,用 iostat 看看 I/O 负载情况...
还有一种办法是 ps -ef | sort -k7 ,将进程按运行时间排序,看哪个进程消耗的cpu时间最多
free
1.作用
free命令用来显示内存的使用情况,使用权限是所有用户


**2.格式 **
free [-b-k-m] [-o] [-s delay] [-t] [-V]
**3.主要参数 **
-b -k -m -g:分别以字节(KB、MB、GB)为单位显示内存使用情况。
-s delay:显示每隔多少秒数来显示一次内存使用情况。
-t:显示内存总和列。
-o:不显示缓冲区调节列。
uptime
18:59:15 up 25 min, 2 users, load average: 1.23, 1.32, 1.21
现在的时间
系统开机运转到现在经过的时间
连线的使用者数量
最近一分钟,五分钟和十五分钟的系统负载
参数: -V 显示版本资讯。
vmstat
procs -----------memory---------- ---swap-- -----io---- --system-- ----cpu----
r b swpd free buff cache si so bi bo in cs us sy id wa
0 1 24980 10792 8296 47316 5 19 205 52 1161 698 26 3 1 70
**1 观察磁盘活动情况 **
磁盘活动情况主要从以下几个指标了解:
bi:表示从磁盘每秒读取的块数(blocks/s)。数字越大,表示读磁盘的活动越多。
bo:表示每秒写到磁盘的块数(blocks/s)。数字越大,表示写磁盘的活动越多。
wa:cpu等待磁盘I/O(未决的磁盘IO)的时间比例。数字越大,表示文件系统活动阻碍cpu的情况越严重,因为cpu在等待慢速的磁盘系统提供数据。wa为0是最理想的。如果wa经常大于10,可能文件系统就需要进行性能调整了。
**2 观察cpu活动情况 **
vmstat比top更能反映出cpu的使用情况:
us:用户程序使用cpu的时间比例。这个数字越大,表示用户进程越繁忙。
sy: 系统调用使用cpu的时间比例。注意,NFS由于是在内核里面运行的,所以NFS活动所占用的cpu时间反映在sy里面。这个数字经常很大的话,就需要注 意是否某个内核进程,比如NFS任务比较繁重。如果us和sy同时都比较大的话,就需要考虑将某些用户程序分离到另外的服务器上面,以免互相影响。
id:cpu空闲的时间比例。
wa:cpu等待未决的磁盘IO的时间比例。
iostat
用于统计CPU的使用情况及tty设备、硬盘和CD-ROM的I/0量

查看RAM使用情况最简单的方法是通过/proc/meminfo。这个动态更新的虚拟文件实际上是许多其他内存相关工具(如:free / ps / top)等的组合显示。/proc/meminfo列出了所有你想了解的内存的使用情况。进程的内存使用信息也可以通过/proc/
$ cat /proc/meminfo
MemTotal: 8388608 kB
MemFree: 19404 kB
MemAvailable: 8647836 kB
Buffers: 0 kB
Cached: 3883764 kB
SwapCached: 0 kB
Active: 6426584 kB
Inactive: 1942564 kB
Active(anon): 4485496 kB
Inactive(anon): 1008 kB
Active(file): 1941088 kB
Inactive(file): 1941556 kB
Unevictable: 0 kB
Mlocked: 0 kB
SwapTotal: 0 kB
SwapFree: 0 kB
Dirty: 16880 kB
Writeback: 0 kB
AnonPages: 114106472 kB
Mapped: 3026292 kB
Shmem: 301604 kB
Slab: 7141536 kB
SReclaimable: 6245764 kB
SUnreclaim: 895772 kB
KernelStack: 350208 kB
PageTables: 484640 kB
NFS_Unstable: 0 kB
Bounce: 0 kB
WritebackTmp: 0 kB
CommitLimit: 98901520 kB
Committed_AS: 273028180 kB
VmallocTotal: 34359738367 kB
VmallocUsed: 714472 kB
VmallocChunk: 34358872316 kB
HardwareCorrupted: 0 kB
AnonHugePages: 0 kB
HugePages_Total: 0
HugePages_Free: 0
HugePages_Rsvd: 0
HugePages_Surp: 0
Hugepagesize: 2048 kB
DirectMap4k: 343960 kB
DirectMap2M: 41486336 kB
DirectMap1G: 161480704 kB
5. 根据端口号查找进程号查找程序路径
netstat -nlp | grep 端口号
如下图所示,查询28180端口对应的进程PID-netstat -nlp | grep 28180
得到的8161就是进程PID
![]()
然后通过下面命令查询对应的程序路径
ll /proc/进程号/cwd

cwd — 指向当前进程运行目录的一个符号链接
exe — 指向启动当前进程的可执行文件(完整路径)的符号链接,通过/proc/N/exe可以启动当前进程的一个拷贝
4 .在文件最后一列加,逗号
sed 's/$/\,/g' a.txt
sed 's/$/\,/g' -i a.txt
或者不需要转义 sed 's/$/,/g' a.txt
"^"代表行首,"$"代表行尾
字符g代表每行出现的字符全部替换
如果想导出文件,在命令末尾加"> outfile_name"
sed 's/$/,/g' a.txt > b.txt
实际操作:
把req_file7的类型为7的改为13 并保存到req_file13 如果不加后面的req_file13,则会在当前屏幕一直滚动展示实时数据,且req_file7的内容不会发生变化
sed 's/rec_type": 7/rec_type": 13/g' req_file7>req_file13
或者vim模式下 :%s/rec_type": 7/rec_type": 13/g
vim模式:
:%s/$/,/g
3. 去除文件第一列和最后一列
了解 Hadoop,Hive,Hbase。
了解前端技术 html,css 和 javascript 以及基本的使用。
熟练掌握core Java 。
以上文本想实现效果:
了解 Hadoop,Hive,Hbase
了解前端技术 html,css 和 javascript 以及基本的使用
熟练掌握core Java
sed -e "s/ /""/g" -e "s/。/""/g" 1.txt
-e :直接在命令行模式上进行sed动作编辑,此为默认选项 -e : 可以在同一行里执行多条命令
awk '{$1="";print $0}' 1.txt 去除第一列

公司解析简历的系统很。。。。。。。
去除文件的第一列以及最后一列
sed -e "s/[^ ] /""/g" -e "s/。/""/g" 1.txt

2. Mac下解压rar文件
使用Homebrew安装unrar(有关Homebrew的安装和使用见Homebrew)
brew install unrar
unrar x filename.rar
1. 打开自动化运行后的测试报告,除了直接在idea中右击report.html文件Reveal in Finder外,还可以Copy Path,在iterm中用命令打开。不是说这个有多难,而是换一种思维方式,多种方法思考问题
open /Users/lishan/Desktop/code/UICheck/report.html

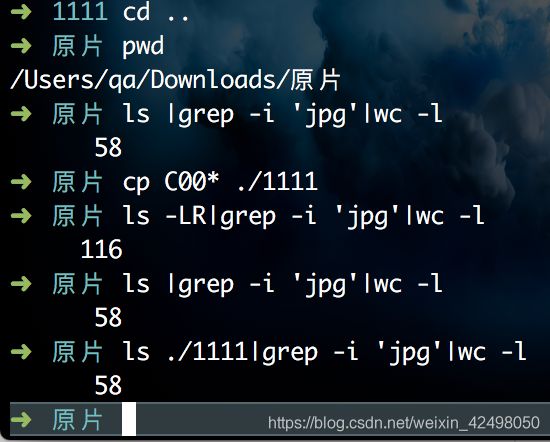
统计文件夹下文件个数
ls -LR|grep -i 'jpg'|wc -l
ls |grep -i 'jpg'|wc -l
参考ls博客:https://blog.csdn.net/zhouxiangbai/article/details/80510834
-L 列出链接文件名而不是链接到的文件。
-N 不限制文件长度。
-Q 把输出的文件名用双引号括起来。
-R 列出所有子目录下的文件。
-S 以文件大小排序。
-X 以文件的扩展名(最后一个 . 后的字符)排序。
-1 一行只输出一个文件
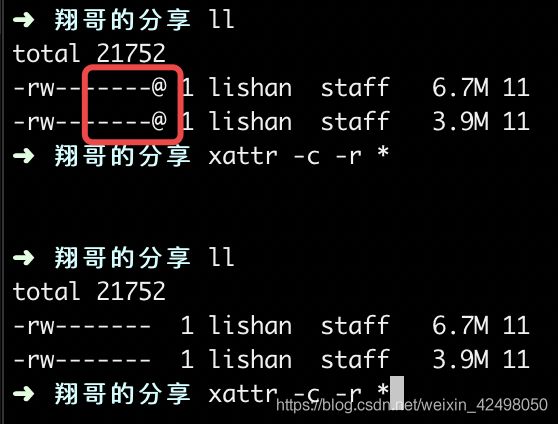
xattr 复制的文件属性去除 发现复制或者下载的文件属性为-rw-------@
这里的@貌似是mac特有的,第一次使用file_put_contents往根目录添加文件成功,
再次添加就提示
failed to open stream: Permission denied
解决方法:
mac终端下执行
xattr -c -r *
执行完merge操作后,没有修改代码
1、命令
1. git reflog
查看merge操作的上一个提交记录的版本号
2. git reset –hard 版本号
这样可以回滚到merge之前的状态
2、示例
误将dev合并到了master分支,现要回滚merge操作
1. 首先git reflog
ee0ee93 HEAD@{0}: merge dev: Merge made by the ‘recursive’ strategy.
7335548 HEAD@{1}: checkout: moving from dev to master
可以看到需要回滚到 7335548 这个提交记录上
2. 执行git reset --hard 7335548
再次查看提交记录:
7335548 HEAD@{0}: reset: moving to 7335548
ee0ee93 HEAD@{1}: merge dev: Merge made by the ‘recursive’ strategy.
亲自实践:
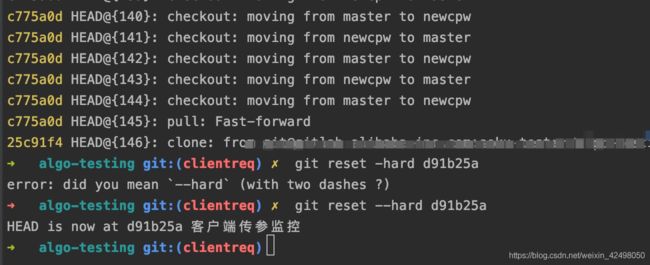
master代码合并到自己的分支clientreq,但想回滚
git reflog
git reset --hard d91b25a
统计字符串出现次数Linux
这里统计某个字符串在文件里出现的次数使用到了-c参数,请见下图案例:
语法:grep -c 'object' fileName

如何通过端口查找出进程所在目录?
一、找到端口对应的进程的号(PID)
[root@benbang ~]# ss -lntup|grep 6379
tcp LISTEN 0 511 127.0.0.1:6379 *:* users:(("redis-server",pid=914,fd=6))二、显示/proc/进程号/cwd
cwd符号链接的是进程运行的目录
[root@benbang ~]# ll /proc/914/cwd
lrwxrwxrwx 1 redis redis 0 Aug 1 15:53 /proc/914/cwd -> /usr/local/redis/varexe符号链接的是执行程序的绝对路径;
[root@benbang ~]# ll /proc/914/exe
lrwxrwxrwx 1 redis redis 0 Jul 22 21:57 /proc/914/exe -> /usr/local/redis/bin/redis-servercmdline就是程序运行时输入的命令行命令;
environ记录了进程运行时的环境变量;
fd目录下是进程打开或使用的文件的符号连接

[root@benbang ~]# ll /proc/914/fd
total 0
lrwx------ 1 redis redis 64 Jul 22 21:58 0 -> /dev/null
lrwx------ 1 redis redis 64 Jul 22 21:58 1 -> /dev/null
lrwx------ 1 redis redis 64 Jul 22 21:58 2 -> /dev/null
lr-x------ 1 redis redis 64 Jul 22 21:58 3 -> pipe:[13725]
l-wx------ 1 redis redis 64 Jul 22 21:58 4 -> pipe:[13725]
lrwx------ 1 redis redis 64 Jul 22 21:58 5 -> anon_inode:[eventpoll]
lrwx------ 1 redis redis 64 Jul 22 21:58 6 -> socket:[13739]1、lsof -i
lsof(list open files)是一个列出当前系统打开文件的工具。在linux环境下,任何事物都以文件的形式存在,通过文件不仅仅可以访问常规数据,还可以访问网络连接和硬件。所以如传输控制协议 (TCP) 和用户数据报协议 (UDP) 套接字等,系统在后台都为该应用程序分配了一个文件描述符,无论这个文件的本质如何,该文件描述符为应用程序与基础操作系统之间的交互提供了通用接口。因为应用程序打开文件的描述符列表提供了大量关于这个应用程序本身的信息,因此通过lsof工具能够查看这个列表对系统监测以及排错将是很有帮助的。
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME init 1 root cwd DIR 8,1 4096 2 / init 1 root rtd DIR 8,1 4096 2 / init 1 root txt REG 8,1 150584 654127 /sbin/init udevd 415 root 0u CHR 1,3 0t0 6254 /dev/null udevd 415 root 1u CHR 1,3 0t0 6254 /dev/null udevd 415 root 2u CHR 1,3 0t0 6254 /dev/null udevd 690 root mem REG 8,1 51736 302589 /lib/x86_64-linux-gnu/libnss_files-2.13.so syslogd 1246 syslog 2w REG 8,1 10187 245418 /var/log/auth.log syslogd 1246 syslog 3w REG 8,1 10118 245342 /var/log/syslog dd 1271 root 0r REG 0,3 0 4026532038 /proc/kmsg dd 1271 root 1w FIFO 0,15 0t0 409 /run/klogd/kmsg dd 1271 root 2u CHR 1,3 0t0 6254 /dev/null
详细了解lsof,可以参考:https://www.cnblogs.com/sparkbj/p/7161669.html
2、netstat命令是一个监控TCP/IP网络的非常有用的工具,它可以显示路由表、实际的网络连接以及每一个网络接口设备的状态信息
netstat -tunlp 显示tcp,udp的端口和进程等相关情况
netstat -anp 也可以显示系统端口使用情况
netstat [选项]
-a或--all:显示所有连线中的Socket;
-A<网络类型>或--<网络类型>:列出该网络类型连线中的相关地址;
-c或--continuous:持续列出网络状态;
-C或--cache:显示路由器配置的快取信息;
-e或--extend:显示网络其他相关信息;
-F或--fib:显示FIB;
-g或--groups:显示多重广播功能群组组员名单;
-h或--help:在线帮助;
-i或--interfaces:显示网络界面信息表单;
-l或--listening:显示监控中的服务器的Socket;
-M或--masquerade:显示伪装的网络连线;
-n或--numeric:直接使用ip地址,而不通过域名服务器;
-N或--netlink或--symbolic:显示网络硬件外围设备的符号连接名称;
-o或--timers:显示计时器;
-p或--programs:显示正在使用Socket的程序识别码和程序名称;
-r或--route:显示Routing Table;
-s或--statistice:显示网络工作信息统计表;
-t或--tcp:显示TCP传输协议的连线状况;
-u或--udp:显示UDP传输协议的连线状况;
-v或--verbose:显示指令执行过程;
-V或--version:显示版本信息;
-w或--raw:显示RAW传输协议的连线状况;
-x或--unix:此参数的效果和指定"-A unix"参数相同;
--ip或--inet:此参数的效果和指定"-A inet"参数相同。
方法1: lsof -i 用以显示符合条件的进程情况,lsof(list open files)是一个列出当前系统打开文件的工具。
以root用户来执行lsof -i命令,如下:
[root@hadoop01 yum.repos.d]# lsof -i
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
rpcbind 1873 rpc 6u IPv4 15228 0t0 UDP *:sunrpc
rpcbind 1873 rpc 7u IPv4 15230 0t0 UDP *:wpages
rpcbind 1873 rpc 8u IPv4 15231 0t0 TCP *:sunrpc (LISTEN)
rpcbind 1873 rpc 9u IPv6 15233 0t0 UDP *:sunrpc
rpcbind 1873 rpc 10u IPv6 15235 0t0 UDP *:wpages
rpcbind 1873 rpc 11u IPv6 15236 0t0 TCP *:sunrpc (LISTEN)
rpc.statd 2017 rpcuser 5r IPv4 15556 0t0 UDP *:921
rpc.statd 2017 rpcuser 8u IPv4 15563 0t0 UDP *:32846
rpc.statd 2017 rpcuser 9u IPv4 15567 0t0 TCP *:42335 (LISTEN)
rpc.statd 2017 rpcuser 10u IPv6 15571 0t0 UDP *:41231
rpc.statd 2017 rpcuser 11u IPv6 15575 0t0 TCP *:56522 (LISTEN)
cupsd 2072 root 6u IPv6 15795 0t0 TCP localhost:ipp (LISTEN)
nginx 11914 nobody 11u IPv4 35803 0t0 TCP *:distinct (LISTEN)
加端口号,查看端口被谁占用
lsof -i:端口号
例如:
注意:这里的9999端口是我自己打开的一个,前面博客提到过,如果自己没有此端口,请更换端口号
[root@hadoop01 yum.repos.d]# lsof -i:9999
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
nginx 3953 root 11u IPv4 35803 0t0 TCP *:distinct (LISTEN)
nginx 11914 nobody 11u IPv4 35803 0t0 TCP *:distinct (LISTEN)
方法2: netstat -tunlp命令用于显示tcp,udp的端口和进程等相关情况
[root@hadoop01 yum.repos.d]# netstat -tunpl
Active Internet connections (only servers)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp 0 0 0.0.0.0:9999 0.0.0.0:* LISTEN 3953/nginx
tcp 0 0 0.0.0.0:111 0.0.0.0:* LISTEN 1873/rpcbind
tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN 2191/sshd
tcp 0 0 127.0.0.1:631 0.0.0.0:* LISTEN 2072/cupsd
tcp 0 0 127.0.0.1:6010 0.0.0.0:* LISTEN 11504/sshd
tcp 0 0 127.0.0.1:6011 0.0.0.0:* LISTEN 11716/sshd
tcp 0 0 0.0.0.0:42335 0.0.0.0:* LISTEN 2017/rpc.statd
tcp 0 0 0.0.0.0:3306 0.0.0.0:* LISTEN 2379/mysqld
tcp 0 0 :::111 :::* LISTEN 1873/rpcbind
tcp 0 0 :::22 :::* LISTEN 2191/sshd
tcp 0 0 ::1:631 :::* LISTEN 2072/cupsd
tcp 0 0 ::1:6010 :::* LISTEN 11504/sshd
netstat -tunlp 会显示所有端口和所有对应的程序,用grep管道可以过滤出想要的关键字段,
列一下9999端口占用的程序:
注意:这里的9999端口是我自己打开的一个,前面博客提到过,如果自己没有此端口,请更换端口号
netstat -tunplp | grep 端口号
例如:
[root@hadoop01 yum.repos.d]# netstat -tunplp | grep 9999
tcp 0 0 0.0.0.0:9999 0.0.0.0:* LISTEN 3953/nginx
使用netstat -anp进行查看
[root@hadoop01 yum.repos.d]# netstat -anp|grep 9999
tcp 0 0 0.0.0.0:9999 0.0.0.0:* LISTEN 3953/nginx
所以这两种方法都可以查看。
待续