【数据挖掘】薪酬分段对应工作经验/学历画柱状图【招聘网站的职位招聘数据预处理】
文章目录
- 一.需求背景
-
- 1.1 需求分析
- 二.数据处理(对给定职位,汇总薪酬分段对应工作经验要求数据,画柱状图;)
-
- 2.1 事前准备
- 2,1 处理开始
- 三.数据处理(对给定职位,汇总薪酬分段对应学历要求数据,画柱状图;)
- 四.附源码
一.需求背景
过程中需要的数据下载地址:
https://download.csdn.net/download/weixin_52908342/87263841
招聘网站的职位招聘数据预处理。
在此之前:
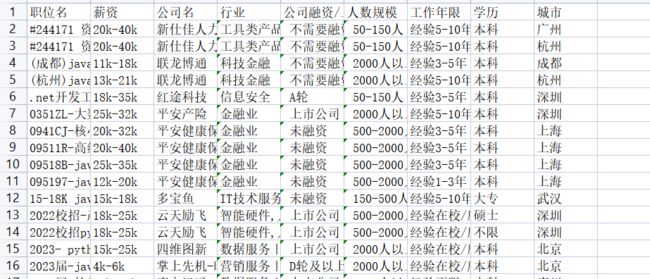
我已经写了一段爬虫,爬取的某勾和某无忧的有效职位数据4000条(数据清洗之后)
本次任务需求:
-
对给定职位,汇总薪酬分段对应工作经验要求数据,画柱状图;
-
对给定职位,汇总薪酬分段对应学历要求数据,画柱状图;
1.1 需求分析
下面的这俩个需求类似,我们可以看做是一个任务:首先,我们给定职位(已Java岗位为例),先使用分箱法,查看一下薪酬分段。然后使用排除重复查看一下工作经验(学历要求)有几种。然后得到3个特征值,画一个多柱状图。
-
对给定职位,汇总薪酬分段对应工作经验要求数据,画柱状图;
-
对给定职位,汇总薪酬分段对应学历要求数据,画柱状图;
二.数据处理(对给定职位,汇总薪酬分段对应工作经验要求数据,画柱状图;)
2.1 事前准备
1.先把相关的包导入。
import re
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from pylab import mpl
2.指定默认字体:解决plot不能显示中文问题。解决保存图像是负号’-'显示为方块的问题
mpl.rcParams['font.sans-serif'] = ['STZhongsong']
mpl.rcParams['axes.unicode_minus'] = False
3.读取有效数据:
data = pd.read_csv("A-06-最终有效数据.csv",encoding="gbk")
2,1 处理开始
1.使用java关键字将java的数据提取出来:然后经过"\d+.?\d*"把薪资的最高值和最低值提取出来。然后使用(最高值+最低值)/2的方式。
算出每一个数据的薪资代表值。将这几个数据分别存入xingzhi={},zhiwei = [],xueli = [],last_xin=[]
xingzhi={}
zhiwei = []
nianxian = []
last_xin=[]
for i in range(len(data)):
if "java" in data.iloc[i]['职位名']:
a = re.findall("\d+\.?\d*", data.iloc[i]['薪资'])
# print(data.iloc[i]['职位名'])
zhiwei.append(data.iloc[i]['职位名'])
nianxian.append(data.iloc[i]['工作年限'])
last_xin.append((int(a[0])+int(a[1]))/2)
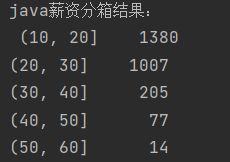
2.分箱 检查离群点及光滑数据;
bins2=[10,20,30,40,50,60]
score_cat = pd.cut(last_xin, bins2)
print("java薪资分箱结果:\n",pd.value_counts(score_cat).values)
结果如下:
3.去重查看学历有几种:
print(list(set(nianxian)))
![]()
4.根据上面的分箱结果,将数据分为以下几个阶段:
第1段 10-15 第二段15-20 第三段 20-25 第四段25-30
a={'经验5-10年':0, '经验1年以下':0, '经验在校/应届':0, '经验1-3年':0, '经验3-5年':0, '经验10年以上':0, '经验不限':0}
b={'经验5-10年':0, '经验1年以下':0, '经验在校/应届':0, '经验1-3年':0, '经验3-5年':0, '经验10年以上':0, '经验不限':0}
c={'经验5-10年':0, '经验1年以下':0, '经验在校/应届':0, '经验1-3年':0, '经验3-5年':0, '经验10年以上':0, '经验不限':0}
d={'经验5-10年':0, '经验1年以下':0, '经验在校/应届':0, '经验1-3年':0, '经验3-5年':0, '经验10年以上':0, '经验不限':0}
6.循环遍历,把该目标值的数据遍历之后,存入对于的字典里:
for i in last_xin:
if int(i)>=10 and int(i)<15:
a[nianxian[int(i)]]=a[nianxian[int(i)]]+1
if int(i)>=15 and int(i)<20:
b[nianxian[int(i)]]= b[nianxian[int(i)]]+1
if int(i) >= 20 and int(i) < 25:
c[nianxian[int(i)]] = c[nianxian[int(i)]] + 1
if int(i) >= 25:
d[nianxian[int(i)]] = d[nianxian[int(i)]] + 1
7.输出,看一眼结果:
print(a)
print(b)
print(c)
print(d)

8.将刚刚上面的结果,转换为列表,方便后面的画图:
xin1=[]
xin2=[]
xin3=[]
xin4=[]
for i in a.values():
xin1.append(i)
for i in b.values():
xin2.append(i)
for i in c.values():
xin3.append(i)
for i in d.values():
xin4.append(i)
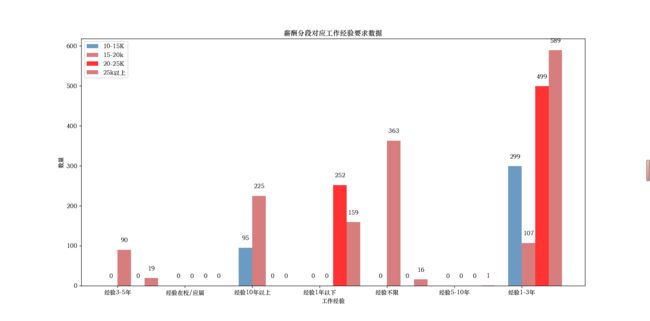
9.开始画图
设置,X坐标的值,这里的’经验3-5年’, ‘经验在校/应届’, ‘经验10年以上’, ‘经验1年以下’, ‘经验不限’, ‘经验5-10年’, ‘经验1-3年’,是前面进行数据去重之后的结果。
bar_width是宽度设置,防止,图重合。
x_data = ['经验3-5年', '经验在校/应届', '经验10年以上', '经验1年以下', '经验不限', '经验5-10年', '经验1-3年']
bar_width=0.2
10.分别画四个柱状图,在一个图例,使用+0.2、+0.4等等来控制它的位置,避免重合。就是bar_width、1+bar_width、2+bar_width…这样就和第一个柱状图并列了。将X轴数据改为使用np.arange(len(x_data))+bar_width,
plt.bar(x_data, height=xin1, label='10-15K',
color='steelblue', alpha=0.8, width=bar_width)
plt.bar(x=np.arange(len(x_data))+0.2, height=xin2, label='15-20k',
color='indianred', alpha=0.8, width=bar_width)
plt.bar(x=np.arange(len(x_data))+0.4, height=xin3, label='20-25K',
color='red', alpha=0.8, width=bar_width)
plt.bar(x=np.arange(len(x_data))+0.6, height=xin4, label='25k以上',
color='indianred', alpha=0.8, width=bar_width)
11.在柱状图上显示具体数值, ha参数控制水平对齐方式, va控制垂直对齐方式
for x, y in enumerate(xin1):
plt.text(x, y+30 , '%s' % y, ha='center', va='top')
for x, y in enumerate(xin2):
plt.text(x+0.2, y+30, '%s' % y, ha='center', va='top')
for x, y in enumerate(xin3):
plt.text(x+0.4, y+30, '%s' % y, ha='center', va='top')
for x, y in enumerate(xin4):
plt.text(x + 0.6, y+30, '%s' % y, ha='center', va='top')
12.设置标题
plt.title("薪酬分段对应工作经验要求数据")
13.为两条坐标轴设置名称
plt.xlabel("工作经验")
plt.ylabel("数量")
14.显示图例
plt.legend()
plt.show()
15.显示效果:
三.数据处理(对给定职位,汇总薪酬分段对应学历要求数据,画柱状图;)
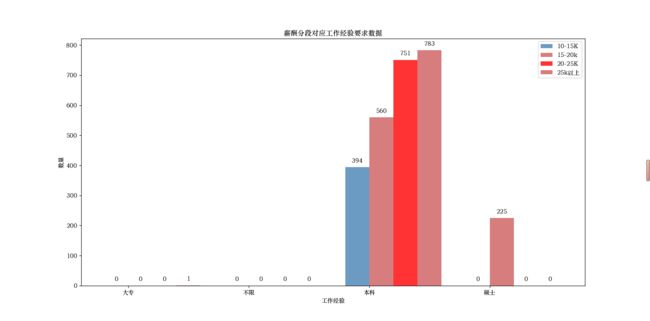
对于这个需求:对给定职位,汇总薪酬分段对应学历要求数据,画柱状图;和上面的基本是大差不差。
只需要修改下面的学历:
xueli.append(data.iloc[i]['学历'])
将X轴的数据改为:‘不限’, ‘硕士’, ‘本科’, ‘大专’
x_data = [‘大专’, ‘不限’, ‘本科’, ‘硕士’]
然后进行绘图,即可得到下面的图像:
四.附源码
import re
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from pylab import mpl
mpl.rcParams['font.sans-serif'] = ['STZhongsong'] # 指定默认字体:解决plot不能显示中文问题
mpl.rcParams['axes.unicode_minus'] = False # 解决保存图像是负号'-'显示为方块的问题
#读取
data = pd.read_csv("A-06-最终有效数据.csv",encoding="gbk")
# Java开始
xingzhi={}
zhiwei = []
nianxian = []
last_xin=[]
for i in range(len(data)):
if "java" in data.iloc[i]['职位名']:
a = re.findall("\d+\.?\d*", data.iloc[i]['薪资'])
# print(data.iloc[i]['职位名'])
zhiwei.append(data.iloc[i]['职位名'])
nianxian.append(data.iloc[i]['工作年限'])
last_xin.append((int(a[0])+int(a[1]))/2)
# xin1.append()
# xin2.append(int(a[1]))
# 分箱 检查离群点及光滑数据;
# bins=[10,15,20,25,30,35,40,45,50]
bins2=[10,20,30,40,50,60]
score_cat = pd.cut(last_xin, bins2)
print("java薪资分箱结果:\n",pd.value_counts(score_cat).values)
#去重结果
print(list(set(nianxian)))
#第1段 10-15 第二段15-20 第三段 20-25 第四段25-30
a={'经验5-10年':0, '经验1年以下':0, '经验在校/应届':0, '经验1-3年':0, '经验3-5年':0, '经验10年以上':0, '经验不限':0}
b={'经验5-10年':0, '经验1年以下':0, '经验在校/应届':0, '经验1-3年':0, '经验3-5年':0, '经验10年以上':0, '经验不限':0}
c={'经验5-10年':0, '经验1年以下':0, '经验在校/应届':0, '经验1-3年':0, '经验3-5年':0, '经验10年以上':0, '经验不限':0}
d={'经验5-10年':0, '经验1年以下':0, '经验在校/应届':0, '经验1-3年':0, '经验3-5年':0, '经验10年以上':0, '经验不限':0}
for i in last_xin:
if int(i)>=10 and int(i)<15:
a[nianxian[int(i)]]=a[nianxian[int(i)]]+1
if int(i)>=15 and int(i)<20:
b[nianxian[int(i)]]= b[nianxian[int(i)]]+1
if int(i) >= 20 and int(i) < 25:
c[nianxian[int(i)]] = c[nianxian[int(i)]] + 1
if int(i) >= 25:
d[nianxian[int(i)]] = d[nianxian[int(i)]] + 1
print(a)
print(b)
print(c)
print(d)
xin1=[]
xin2=[]
xin3=[]
xin4=[]
for i in a.values():
xin1.append(i)
for i in b.values():
xin2.append(i)
for i in c.values():
xin3.append(i)
for i in d.values():
xin4.append(i)
print(xin1)
##开始画图
x_data = ['经验3-5年', '经验在校/应届', '经验10年以上', '经验1年以下', '经验不限', '经验5-10年', '经验1-3年']
bar_width=0.2
plt.bar(x_data, height=xin1, label='10-15K',
color='steelblue', alpha=0.8, width=bar_width)
plt.bar(x=np.arange(len(x_data))+0.2, height=xin2, label='15-20k',
color='indianred', alpha=0.8, width=bar_width)
plt.bar(x=np.arange(len(x_data))+0.4, height=xin3, label='20-25K',
color='red', alpha=0.8, width=bar_width)
plt.bar(x=np.arange(len(x_data))+0.6, height=xin4, label='25k以上',
color='indianred', alpha=0.8, width=bar_width)
for x, y in enumerate(xin1):
plt.text(x, y+30 , '%s' % y, ha='center', va='top')
for x, y in enumerate(xin2):
plt.text(x+0.2, y+30, '%s' % y, ha='center', va='top')
for x, y in enumerate(xin3):
plt.text(x+0.4, y+30, '%s' % y, ha='center', va='top')
for x, y in enumerate(xin4):
plt.text(x + 0.6, y+30, '%s' % y, ha='center', va='top')
plt.xticks(np.arange(len(x_data))+bar_width/2, x_data)
# 设置标题
plt.title("薪酬分段对应工作经验要求数据")
# 为两条坐标轴设置名称
plt.xlabel("工作经验")
plt.ylabel("数量")
# 显示图例
plt.legend()
plt.show()
plt.show()