【今日CV 计算机视觉论文速览 第136期】Wed, 26 Jun 2019
今日CS.CV 计算机视觉论文速览
Wed, 26 Jun 2019
Totally 28 papers
?上期速览✈更多精彩请移步主页

Interesting:
?+++基于水面反射的三维重建方法, 研究人员提出了一种基于水面反射的立体重建方法,由于水面提供了额外的视角所以可以用于立体重建。还解决了一系列散射、环境放射和光照问题让反射图像和与真实图像进行有效匹配。另外,反射可以为相机提供一种自标定的方法(catadioptric反射折射),有效的确定了相机的参数(from 京都大学)
这一方法的流程图:
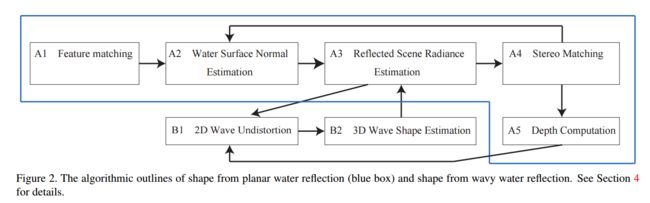
和对应的三维重建结果:

?基于激光雷达体素数据重建场景表面, 基于TSDF的体素实现了激光雷达数据的三维重建。(from 法国国家信息与自动化研究所 INRIA Paris, R&D Department of AKKA Technologies )

mesh重建方法和置信度估计:
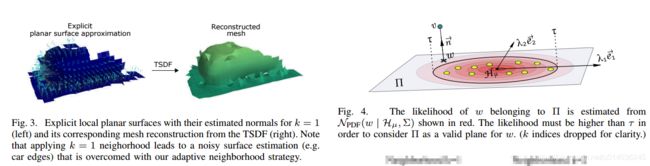
重建出的结果比较:
dataset:KITTI dataset 0018
?MSFNet,端到端的多尺度立体匹配算法, 针对内容语义信息和细节,研究人员提出了多尺度融合的匹配方法。首先利用多尺度特征融合将语义信息和细粒度细节进行编码,随后将信息进行衔接,并利用引导机制使得网络对于不确定的区域给予更多关注,最后基于连续性来作为误差图,来优化最终的视差图。(from 北京大学)
方法的架构图,将立体匹配的四个步骤融合到了单一的网络中去:
用于融合语言特征进行视差图优化,堆叠引导残差模块的结构(Stacked Guidance Residual Module SGRM):

一些结果:
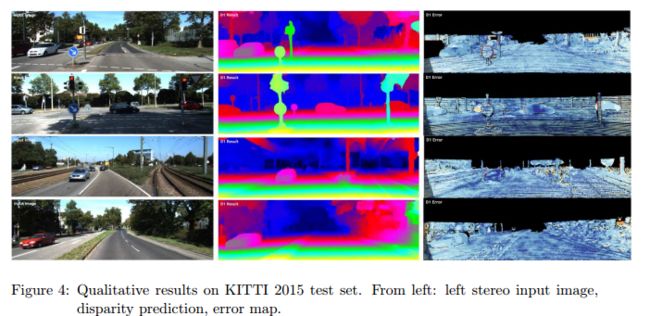
dataset:e Scene Flow dataset and the KITTI dataset
ref:
MVSNet:https://github.com/YoYo000/MVSNet
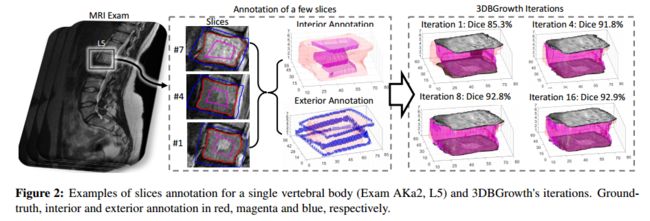
?3DBGrowth,核磁共振图像基于体素的脊柱分割和重建, 基于单层图像分割、堆叠,进行迭代融合重建。(from University of Sao Paulo)
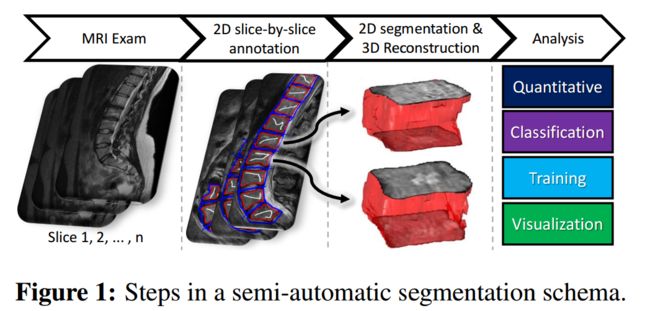
单个脊柱的重建过程:
Daily Computer Vision Papers
| Technical Report: Fast Robot Arm Inverse Kinematics and Path Planning Under Complex Obstacle Constraint Authors David W. Arathorn 这里描述的是一种简单,可靠的方法,用于在存在复杂障碍物的情况下快速计算机器人手臂反向运动学解决方案和运动路径计划。该方法基于MSC映射寻找电路算法的限制形式,被优化以利用实际臂配置的特性。 MSC表示自然地结合了臂和障碍物几何形状。现代硬件的后续性能适用于需要实时响应的应用。在高端GPGPU上,对于8 DOF臂的最终姿势和避免到该姿势的运动路径的平滑障碍物的硬件计算花费大约200毫秒。 |
| Interpretable Image Recognition with Hierarchical Prototypes Authors Peter Hase, Chaofan Chen, Oscar Li, Cynthia Rudin 视觉模型在根据人们可以直接理解的特征对对象进行分类时是可解释的。最近,为此目的开发了依赖于视觉特征原型的方法。然而,与人类如何对物体进行分类相比,这些方法还没有使用任何类别标签的分类学组织。例如,通过这种方法,我们可以看到为什么黑猩猩被归类为黑猩猩,但不是为什么它被认为是灵长类动物甚至是动物。在这项工作中,我们引入了一个模型,该模型使用分层组织的原型来对预定义分类中的每个级别的对象进行分类。因此,我们可以找到对图像在分类法的每个级别接收的预测的不同解释。分层原型使模型能够执行另一个重要任务,可解释地将来自先前未见过的类的图像分类到它们正确关联的分类法的级别,例如,当训练数据中唯一的武器是步枪时,将手枪分类为武器。使用ImageNet的一个子集,我们针对两个任务的对应黑盒模型测试我们的模型1来自熟悉的类的数据分类,以及来自分类中适当级别的先前未见过的类的数据的2个分类。我们发现我们的模型与其对应的黑盒模型的表现大致相同,同时允许解释每个分类。 |
| 3D Surface Reconstruction from Voxel-based Lidar Data Authors Luis Rold o, Raoul de Charette, Anne Verroust Blondet 为了实现完全自主的导航,车辆需要计算其直接周围的精确模型。本文提出了一种基于异构密度三维数据的三维表面重建算法。所提出的方法基于基于TSDF体素的表示,其中引入了源自高斯置信度评估的自适应邻域核。这使得能够在重建网格的密度与其精度之间保持良好的折衷。与用于表面重建的现有技术方法相比,对合成CARLA和真实KITTI 3D数据进行的实验评估显示出良好的性能。 |
| Zero-Shot Image Classification Using Coupled Dictionary Embedding Authors Mohammad Rostami, Soheil Kolouri, Zak Murez, Yuri Owekcho, Eric Eaton, Kuyngnam Kim 零镜头学习ZSL是一种框架,用于根据关于这些看不见的类的语义信息对属于看不见的类的图像进行分类。在本文中,我们提出了一种使用耦合字典学习的新ZSL算法。核心思想是图像的视觉特征和语义属性可以在中间空间中共享相同的稀疏表示。我们使用来自已知类和来自看不见的类的语义属性的图像来学习两个可以稀疏地表示图像的视觉和语义特征向量的字典。在ZSL测试阶段并且在没有标记数据的情况下,通过仅使用可视数据查找联合稀疏表示,可以将来自未见类的图像映射到属性空间中。然后,在给定看不见的类的语义描述的情况下,将图像分类在属性空间中。我们还提供了一个属性感知公式来解决ZSL中的域转换和集线器问题。提供了大量实验来证明我们的方法在基准ZSL数据集上对最先进的ZSL算法的优越性能。 |
| ***Discrete Optimization of Ray Potentials for Semantic 3D Reconstruction Authors Nikolay Savinov, Lubor Ladicky, Christian Haene, Marc Pollefeys 密集语义3D重建通常被表述为体素网格中的标签分配上的离散或连续问题,其结合了马尔可夫随机场框架中的语义和深度可能性。深度和语义信息被合并为一元电位,由成对正则化器平滑。然而,将可能性建模为一元潜力并不能正确地模拟问题,从而导致各种不期望的可见性伪像。 |
| Learning Features with Differentiable Closed-Form Solver for Tracking Authors Linyu Zheng, Ming Tang, JinqiaoWang, Hanqing Lu 我们提出了一种新颖且易于实施的视觉跟踪培训框架。我们的方法主要侧重于以端到端的方式学习特征嵌入,这可以基于在线判别训练的岭回归模型很好地推广到跟踪器。通过利用以下两个重要理论有效地实现了这一目标。 1岭回归问题具有闭合形式解,并且在最优性条件下是隐式微分。因此,它的求解器可以作为一层嵌入,在训练深度卷积神经网络中具有有效的前向和后向过程。当采用高维特征嵌入时,可以利用Woodbury识别来确保岭回归问题的有效解决。此外,为了解决训练期间极端的前景背景类不平衡,我们修改原点收缩损失,然后将其用作有效和有效训练的损失函数。值得一提的是,我们提出的培训框架的上述核心部分很容易在当前流行的深度学习框架下用几行代码实现,因此我们的方法很容易被遵循。六个公共基准测试,即OTB2015,NFS,TrackingNet,GOT10k,VOT2018和VOT2019的大量实验表明,所提出的跟踪器在超过30 FPS的情况下实现了最先进的性能。代码将可用。 |
| **A CNN-Based Super-Resolution Technique for Active Fire Detection on Sentinel-2 Data Authors Massimiliano Gargiulo, Domenico Antonio Giuseppe Dell Aglio, Antonio Iodice, Daniele Riccio, Giuseppe Ruello 遥感应用可以受益于相对精细的空间分辨率多光谱MS图像和双卫星Sentinel 2确保的高重访频率。不幸的是,13个频段中只有4个以10米的最高分辨率提供,其他的则为20个。或60米。例如,在20米处提供的短波红外SWIR波段对于检测主动火灾非常有用。针对更详细的主动火灾探测AFD地图,我们提出了一种基于卷积神经网络CNN的超分辨率数据融合方法,以向SWIR频带的10 m空间分辨率方向发展。基于CNN的解决方案在某些准确度指标方面取得了比替代方法更好的结果。此外,我们通过经典指数监控主动火灾,从应用的角度测试超级解决的波段。我们提出的方法的优点和局限性在特立的维苏威火山地区得到了验证,那里靠近那不勒斯,在2017年夏天遭到大范围火灾的破坏。 |
| **Graph-Based Offline Signature Verification Authors Paul Maergner, Nicholas R. Howe, Kaspar Riesen, Rolf Ingold, Andreas Fischer 图形提供了强大的表示形式,可以为手写签名验证等任务带来好处。虽然签名验证的大多数现有技术方法依赖于固定大小的表示,但是图形在大小上是灵活的并且允许对局部特征以及手写的全局结构进行建模。在本文中,我们提出了两种最近基于图的离线签名验证关键点图方法,其中包含近似图形编辑距离和墨球模型。我们提供了方法的全面描述,提出了计算时间和准确性方面的改进,并报告了四个基准数据集的实验结果。所提出的方法实现了几个基准测试的最佳结果,突出了基于图形的签名验证的潜力。`GPDSsynthetic dataset` |
| Brain MR Image Segmentation in Small Dataset with Adversarial Defense and Task Reorganization Authors Xuhua Ren, Lichi Zhang, Qian Wang, Dinggang Shen 医学图像分割尤其在处理3D MR图像的小数据集时具有挑战性。编码来自个体受试者的大脑解剖结构的变化不能容易地实现,这仅由有限数量的良好标记的训练对象进一步挑战。在这项研究中,我们的目标是解决小型脑部MR图像分割的问题。首先,关于训练图像数量有限,我们采用adver sarial防御来增强训练数据,从而提高网络的鲁棒性。其次,受先前神经解剖学知识的启发,我们以不同的方式将不同区域的分割任务重新组织成若干组。第三,任务重组延伸到语义级别,因为我们结合了额外的对象级别分类任务以向像素级别分割任务贡献高阶视觉特征。在实验中,我们通过在挑战数据集上分割灰质,白质和几个主要区域来验证我们的方法。仅提供7个训练对象的方法可以在现场测试集中达到84.46的Dice得分。 |
| End-to-End Learning of Multi-scale Convolutional Neural Network for Stereo Matching Authors Li Zhang, Quanhong Wang, Haihua Lu, Yong Zhao 深度神经网络在立体匹配任务中表现出优异的性能。最近基于CNN的方法已经表明立体匹配可以被公式化为监督学习任务。然而,对语境语义信息和细节的融合关注较少。为了解决这个问题,我们提出了一个基于丰富的上下文细节和语义信息的差异估计网络,称为多尺度特征网络MSFNet。首先,我们设计了一种新结构,通过融合多尺度特征来编码丰富的语义信息和细粒度细节。并且我们结合了元素加法和连接的优点,这有利于将语义信息与细节合并。其次,引入了引导机制来引导网络自动更多地关注不可靠区域。第三,我们将一致性检查表示为错误图,由具有细粒度细节的低阶段特征获得。最后,我们采用左边特征和合成左边特征之间的一致性检查来细化初始视差。在Scene Flow和KITTI 2015基准测试中的实验表明,所提出的方法可以实现最先进的性能。 |
| COP: Customized Deep Model Compression via Regularized Correlation-Based Filter-Level Pruning Authors Wenxiao Wang, Cong Fu, Jishun Guo, Deng Cai, Xiaofei He 神经网络压缩使得有效且笨重的深度卷积神经网络CNN能够部署在资源受限的场景中。大多数现有技术方法根据滤波器的重要性在滤波器级别中修剪模型。尽管它们取得了成功,但我们注意到它们至少遭受以下两个问题:1不考虑过滤器之间的冗余,因为重要性是独立评估的。 2跨层过滤器比较是无法实现的,因为重要性是在每个层内本地定义的。因此,我们必须手动指定分层修剪比率。 3它们易于产生次优解,因为它们忽略了减少参数和降低计算成本之间的不等式。减少网络中不同位置的相同数量的参数可以降低不同的计算成本。为了解决上述问题,我们开发了一种新的算法,称为基于COP相关的修剪,可以有效地检测冗余滤波器。我们通过全局规范化启用跨层过滤器比较。我们将参数数量和计算成本正则化项添加到重要性中,这使得用户能够根据他们的偏好更小或更快地定制压缩。大量实验表明COP显着优于其他COP。代码发布于 |
| **低功耗目标检测SkyNet: A Champion Model for DAC-SDC on Low Power Object Detection Authors Xiaofan Zhang, Yuhong Li, Cong Hao, Kyle Rupnow, Jinjun Xiong, Wen mei Hwu, Deming Chen 在边缘开发人工智能AI总是具有挑战性,因为边缘设备具有有限的计算能力和存储器资源,但需要满足苛刻的要求,例如实时处理,高吞吐量性能和高推理精度。为了克服这些挑战,我们提出了SkyNet,这是一种极轻量级的DNN,具有12个卷积Conv层,并且采用自下而上的DNN设计方法,仅有1.82兆字节MB的参数。 SkyNet在第56届IEEE ACM设计自动化会议系统设计竞赛DAC SDC中进行了演示,这是无人机无人机拍摄的图像中的低功率物体探测挑战。 SkyNet赢得了GPU和FPGA赛道的第一名,我们在TX2 GPU上提供0.731 Intersection over Union IoU和67.33帧每秒FPS,并在Ultra96 FPGA上提供0.716 IoU和25.05 FPS。 |
| EKFPnP: Extended Kalman Filter for Camera Pose Estimation in a Sequence of Images Authors Mohammad Amin Mehralian, Mohsen Soryani 在现实世界的应用中,Perspective n Point PnP问题通常应该应用于一系列图像中,随着时间的推移跟踪一组漂移倾向特征。在本文中,我们考虑相机姿态的时间依赖性和连续相机姿态估计的特征的不确定性。使用扩展卡尔曼滤波器EKF,从相机运动模型计算相机姿态的先验估计,然后通过最小化参考点的重投影误差来校正。使用模拟和真实数据的实验结果表明,与现有技术相比,所提出的方法在存在噪声的情况下改善了相机姿态估计的鲁棒性。 |
| 3DBGrowth: volumetric vertebrae segmentation and reconstruction in magnetic resonance imaging Authors Jonathan S. Ramos, Mirela T. Cazzolato, Bruno S. Fai al, Marcello H. Nogueira Barbosa, Caetano Traina Jr., Agma J. M. Traina 医学图像的分割对于使分析和分类的多个过程更可靠是至关重要的。随着越来越多的人出现背部疼痛和相关问题,椎体的半自动分割和3D重建对于支持决策变得更加重要。 3D重建允许对每个椎骨状况进行快速且客观的分析,这可能在手术计划和合适治疗的评估中起主要作用。在本文中,我们提出了3DBGrowth,它开发了一种有效的二维图像平衡增长方法的三维重建。我们还利用注释时间中的斜率系数来减少注释切片的总数,从而减少了手动注释所花费的时间。我们在17个MRI检查的代表性数据集上显示实验结果,证明我们的方法明显优于竞争对手,平均而言,只有37个具有椎体内容的切片必须注释而不会失去性能准确性。与现有技术方法相比,我们已经获得了超过5的骰子得分增益,并具有可比较的处理时间。此外,3DBGrowth适用于不精确的种子点,这减少了专家手动注释所花费的时间。 |
| Shape from Water Reflection Authors Ryo Kawahara, Shohei Nobuhara, Ko Nishino 本文介绍了水反射摄影的单幅图像三维场景重建,即采集直接和水反射现实世界场景的图像。水反射为直接视线提供了额外的视角,共同形成立体声对。然而,水反射场景除了场景辐射之外还包括内部散射和反射的环境照明,这排除了直接立体匹配。我们推导出一种原理迭代方法,该方法解开了这个场景辐射测量和几何,以重建三维场景结构及其高动态范围外观。在存在波浪的情况下,我们同时恢复波浪几何形状,作为水面的表面正常扰动。最重要的是,我们表明水反射可以校准相机。换句话说,我们表明在一次曝光中捕获直接和水反射的场景形成了自校准反射折射立体相机。我们在野外拍摄的许多图像上展示了我们的方法。结果证明了利用这种意外折反射相机的新方法。 |
| **字体分析Serif or Sans: Visual Font Analytics on Book Covers and Online Advertisements Authors Yuto Shinahara, Takuro Karamatsu, Daisuke Harada, Kota Yamaguchi, Seiichi Uchida 在本文中,我们对书籍封面和在线广告中的字体统计进行了大规模的研究。通过统计研究,我们试图了解图形设计师如何关联字体和内容类型,并确定字体样式,颜色和类型之间的关系。我们提出了一种自动方法,通过对图形设计应用一系列字符检测,样式分类和聚类技术,从图形设计中提取字体信息。提取的字体信息与诸如浪漫或商业之类的类型信息一起累积,以进行进一步的趋势分析。通过我们独特的实证研究,我们表明收集的字体统计数据揭示了排版设计如何代表内容类型的印象和氛围的有趣趋势。 |
| Efficient Multi-Domain Network Learning by Covariance Normalization Authors Yunsheng Li, Nuno Vasconcelos 考虑了深度网络的多域学习问题。每个目标域诱导自适应层,并且提出了一种新的过程,表示协方差归一化CovNorm,以减少其参数。 CovNorm是一种相当简单实现的数据驱动方法,需要两个主成分分析PCA和微调适应层的微调。然而,在理论上和实验上,它都显示出优于先前方法的若干优点,例如批量归一化或几何矩阵近似。此外,当目标数据集可以顺序或同时可用时,可以部署CovNorm。实验表明,在两种情况下,它都具有与完全微调网络相当的性能,每个目标域使用少至0.13个相应参数。 |
| A Deep Regression Model for Seed Identification in Prostate Brachytherapy Authors Yading Yuan, Ren Dih Sheu, Luke Fu, Yeh Chi Lo 植入后剂量测定PID是前列腺近距离放射治疗的必要步骤,其利用CT对前列腺成像并允许放射性种子的位置和剂量分布与实际前列腺直接相关。然而,当多个种子聚集在一起时,由于严重的金属伪影和高重叠外观而在CT图像中识别这些种子是非常具有挑战性的任务。在本文中,我们提出了一种基于3D深度完全卷积网络的自动高效算法,用于识别CT图像中的植入种子。我们的方法将种子定位任务建模为监督回归问题,其将输入CT图像投影到地图,其中每个元素表示相应输入体素属于种子的概率。这种深度回归模型显着抑制了图像伪影,使后期处理更容易,更易控制。所提出的方法在大型临床数据库中得到验证,该数据库在100名患者中具有7820个种子,其中来自70个患者的5534个种子用于模型训练和验证。我们的方法在30个测试患者中正确检测到2150个2286个94.1种子,与广泛使用的商业种子取景器软件VariSeed,Varian,Palo Alto,CA相比,产生了16个改进。 |
| RUBi: Reducing Unimodal Biases in Visual Question Answering Authors Remi Cadene, Corentin Dancette, Hedi Ben younes, Matthieu Cord, Devi Parikh 视觉问题回答VQA是回答图像问题的任务。一些VQA模型经常利用单峰偏差来提供正确的答案而不使用图像信息。因此,当对其训练集分布之外的数据进行评估时,他们的性能会大幅下降。这个关键问题使它们不适合现实世界的设置。 |
| ***医学图像重建综述A Review on Deep Learning in Medical Image Reconstruction Authors Haimiao Zhang, Bin Dong 医学成像在现代诊所中至关重要,可指导疾病的诊断和治疗。医学图像重建是医学成像中最基本和最重要的组成部分之一,其主要目的是以最小的成本和对患者的风险获得用于临床使用的高质量医学图像。医学图像重建中的数学模型,或者更一般地,计算机视觉中的图像恢复,已经发挥了重要作用。早期的数学模型大多是通过人类知识或假设来重建的,我们称这些模型为手工模型。后来,手工制作和数据驱动建模开始出现,这仍然主要依赖于人类设计,而模型的一部分是从观察到的数据中学习的。最近,随着更多数据和计算资源的可用,基于深度学习的模型或深度模型将数据驱动建模推向极端,其中模型主要基于最小人类设计的学习。手工制作和数据驱动建模都有各自的优缺点。医学成像的主要研究趋势之一是将手工建模与深度建模相结合,以便我们可以从两种方法中获益。本文的主要部分是从展开动力学角度对近期深度建模的一些作品进行概念性回顾。这一观点激发了神经网络架构的新设计,其灵感来自优化算法和数值微分方程。鉴于深度建模的普及,该领域仍然存在巨大的挑战,以及我们将在本文末尾讨论的机会。 |
| Naver at ActivityNet Challenge 2019 -- Task B Active Speaker Detection (AVA) Authors Joon Son Chung 本报告描述了我们在CVPR 2019上提交的ActivityNet挑战。我们使用基于CNN的3D卷积神经网络前端以及时间卷积和LSTM分类器的集合来预测可见人是否在说话。我们的结果显示AVA ActiveSpeaker数据集的基线有显着改进。 |
| Knowledge Amalgamation from Heterogeneous Networks by Common Feature Learning Authors Sihui Luo, Xinchao Wang, Gongfan Fang, Yao Hu, Dapeng Tao, Mingli Song 研究人员和开发人员已经在线发布了越来越多训练有素的深度网络,使社区能够以即插即用的方式重用它们,而无需访问培训注释。然而,由于大量网络变体,这种公共可用的训练模型通常具有不同的体系结构,每个体系结构都针对特定任务或数据集而定制。在本文中,我们研究了一个深度模型重用任务,我们作为输入预先训练的异构体系结构网络,专门研究不同的任务,作为教师模型。我们的目标是学习一个多才多艺,轻量级的学生模型,能够掌握所有这些异构结构教师的综合知识,同时不需要访问任何人类注释。为此,我们提出了一个共同的特征学习方案,其中所有教师的特征被转化为一个共同的空间,学生被强制模仿他们所有,以便合并完整的知识。我们在一系列基准测试中测试所提出的方法,并证明所学的学生能够取得非常有前途的表现,优于他们专业任务中的教师。 |
| Age and gender bias in pedestrian detection algorithms Authors Martim Brandao 行人检测算法是移动机器人的重要组成部分,例如与人类安全直接相关的自动驾驶车辆。这些算法中的性能差异可能会导致有偏见的事故结果形式的不同影响。为了评估这些问题的必要性,我们在最先进的行人检测算法的表现中描述了年龄和性别偏差。我们的分析基于INRIA人数据集,包括儿童,成人,男性和女性标签。我们表明,加州理工学院行人检测基准的所有24种表现最佳的方法都有较高的儿童失误率。差异很大,我们分析它如何随着方法使用的分类器,功能和训练数据而变化。算法平均也存在性别偏差,但性能差异不显着。我们讨论偏见的来源,道德含义,可能的技术解决方案和障碍。 |
| MFP-Unet: A Novel Deep Learning Based Approach for Left Ventricle Segmentation in Echocardiography Authors Shakiba Moradi, Azin Alizadehasl, Jan Dhooge, Isaac Shiri, Niki Oveisi, Mehrdad Oveisi, Majid Maleki, Mostafa Ghelich Oghli 左心室LV的分割是定量测量的关键步骤,例如面积,体积和射血分数。然而,2D超声心动图图像中的自动LV分割是由于边界不清楚而且具有不充分的再现性而具有挑战性的任务。 U net是医学图像分割中的公知架构,通过编码器解码器路径解决了该问题。尽管整体表现出色,但U net忽略了分割过程中所有语义优势的贡献。在本研究中,我们提出了一种新颖的架构来解决这个缺点。 U net的解码器路径的所有级别中的特征映射被连接,它们的深度被均衡,并且被上采样到固定维度。这组特征图将是语义分割层的输入。当使用相同的数据集与U net,扩张的U net和deeplabv3的结果进行比较时,所提出的网络产生了最先进的结果。实现了平均Dice Metric DM为0.945,Hausdorff距离HD为1.62,Jaccard系数JC为0.97,平均绝对距离MAD为1.32。相关图,bland altman分析和箱形图显示了自动和手动计算的体积,面积和长度之间的一致性。 |
| Deep Learning of Compressed Sensing Operators with Structural Similarity Loss Authors Yochai Zur, Amir Adler 压缩感测CS是用于有效地重建来自通过信号的线性投影获得的少量测量的信号的信号处理框架。在本文中,我们提出了一种针对CS的端到端深度学习方法,其中完全连接的网络执行线性感知和非线性重建阶段。在训练阶段期间,使用结构相似性指数SSIM作为损失而不是标准均方误差MSE损失来联合优化感测矩阵和非线性重建算子。我们将所提出的方法与现有技术在两种损失下的重建质量(即SSIM得分和MSE得分)进行比较。 |
| Semi-Supervised Learning with Self-Supervised Networks Authors Phi Vu Tran 半监督学习的最新进展已经显示出巨大的潜力,克服了现代机器学习算法成功访问大量人类标记的训练数据的主要障碍。基于自我集成学习和虚拟对抗训练的算法可以利用丰富的未标记数据在许多半监督基准测试中产生令人印象深刻的现有技术结果,仅使用一小部分可用标记数据接近强监督基线的性能。然而,这些方法通常需要仔细调整许多超参数,并且通常在实践中不容易实现。在这项工作中,我们提出了一种基于自我监督学习的概念上简单但有效的半监督算法,以组合来自未标记数据的语义特征表示。我们的模型经过有效的端到端训练,可以在一个阶段中对标记和未标记数据进行联合,多任务学习。为了简单和实用,我们的方法不需要额外的超参数来调整超出训练卷积神经网络的标准集的最佳性能。我们对SVHN,CIFAR 10和CIFAR 100的半监督图像分类模型进行了全面的实证评估,并证明了结果与先前技术水平竞争,并且在某些情况下超过了先前的技术水平。参考代码和数据可在 |
| Learning a sparse database for patch-based medical image segmentation Authors Moti Freiman, Hannes Nickisch, Holger Schmitt, Pal Maurovich Horvat, Patrick Donnelly, Mani Vembar, Liran Goshen 我们介绍了一种功能,用于学习基于贴片的图像分割的最佳数据库,并应用于冠状动脉计算机断层扫描血管造影CCTA数据的冠状动脉腔分割。所提出的功能包括保真度,稀疏性和对小变量项及其相关权重的鲁棒性。现有工作通过原型选择来解决数据库优化,旨在通过根据一组预定义规则添加或移除原型来优化数据库。相反,我们将数据库优化任务表示为能量最小化问题,可以使用标准数值工具来解决。我们将建议的数据库优化功能应用于优化数据库以进行基于块的冠状动脉腔分割的任务。我们使用公开的MICCAI 2012冠状动脉腔分割挑战数据的实验表明,使用所提出的方法优化数据库将数据库大小减少了96,同时保持相同的流明分割精度水平。此外,我们表明,优化的数据库产生了基于CCTA的所有病变的分数流量储备0.73和0.7的改善的特异性,阻塞性病变的0.68对0.65,使用132 76阻塞性冠状动脉病变的训练集,以侵入性测量的FFR作为参考。 |
| Planning Robot Motion using Deep Visual Prediction Authors Meenakshi Sarkar, Prabhu Pradhan, Debasish Ghose 在本文中,我们介绍了一个新的框架,可以学习从原始视频帧对机器人代理的运动进行视觉预测。我们提出的运动预测网络PROM Net可以完全无监督的方式学习,并有效预测未来最多10帧。此外,与任何其他运动预测模型不同,它是轻量级的,并且一旦经过训练,它就可以在具有非常有限的计算能力的移动平台上轻松实现。我们创建了一个新的机器人数据集,包括LEGO Mindstorms在不同光照条件下在三种不同环境中沿着各种轨迹移动,用于测试和训练网络。最后,我们引入了一个框架,该框架将使用来自网络的预测帧作为模型预测控制器的输入,用于具有移动障碍的未知动态环境中的运动规划。 |
| Chinese Abs From Machine Translation |
Papers from arxiv.org
更多精彩请移步主页

pic from pexels.com