NNDL 作业12:第七章课后题
文章目录
前言
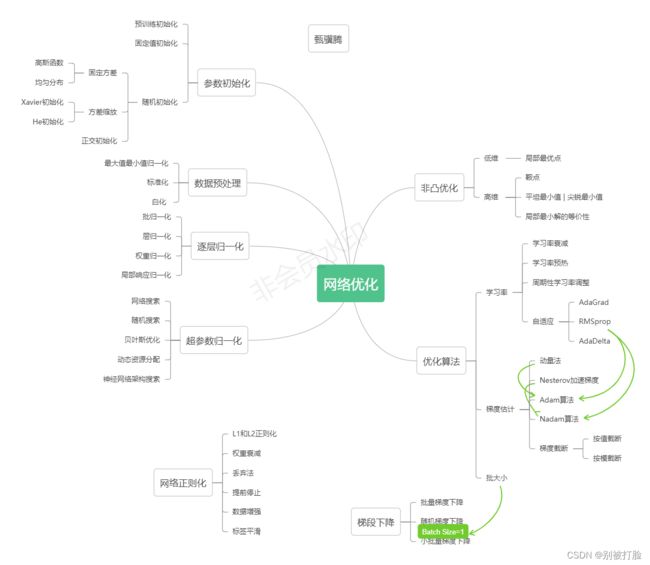
一、习题7-1在小批量梯度下降中,试分析为什么学习率要和批量大小成正比.
二、习题7-2 在Adam算法中,说明指数加权平均的偏差修正的合理性(即公式(7.27)和公式(7.28)).
三、习题7-9证明在标准的随机梯度下降中,权重衰减正则化和L2正则化的效果相同.并分析这一结论在动量法和Adam算法中是否依然成立.
L2正则化和权重衰减是一样的吗?
总结
前言
这次写的很细,但是真的有点累,因为哥们中招了,有点难受,但是还是要坚持写完,坚持是最重要的(哈哈哈)。
这次的流程图感觉真的画了一会,对照着老师的看着书,有点累,但是还是画出来了,这么多流程图,全是自己画的没有去网上随便粘一个,也是有点坚持的味道了(哈哈哈)。
最后,写的不太好,请老师和各位大佬多教教我。

一、习题7-1在小批量梯度下降中,试分析为什么学习率要和批量大小成正比.

由上边的式子推出,下边的这个式子,其实就是把式子一个一个带入就会得出,下边的式子。
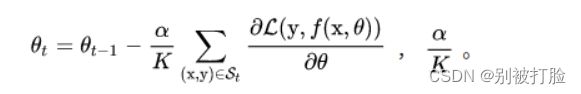
由上边这个式子,就可以看出,规律总结一下就是

其实,就是老师上课讲的,下边的这两张照片。

当梯度较小时,就是下边的照片。

二、习题7-2 在Adam算法中,说明指数加权平均的偏差修正的合理性(即公式(7.27)和公式(7.28)).
深度学习工程师微专业 - 一线人工智能大师吴恩达亲研-网易云课堂 - 网易云课堂

这个就是老师的意思,然后把数带进去咱们看一下例子。我圈的那个链接看了会很明白。
三、习题7-9证明在标准的随机梯度下降中,权重衰减正则化和L2正则化的效果相同.并分析这一结论在动量法和Adam算法中是否依然成立.
这个论文里有实验论证, https://arxiv.org/pdf/1711.05101.pdf
权重衰减和L2正则化是一个意思吗? - 知乎
权重衰减和L2正则化是一个意思吗?它们只是在某些条件下等价 - 知乎
L2正则化是在目标函数中直接加上一个正则项,直接修改了我们的优化目标。
权值衰减是在训练的每一步结束的时候,对网络中的参数值直接裁剪一定的比例,优化目标的式子是不变的。
在使用朴素的梯度下降法时二者是同一个东西,因为此时L2正则化的正则项对梯度的影响就是每次使得权值衰减一定的比例。
但是在使用一些其他优化方法的时候,就不一样了。比如说使用Adam方法时,每个参数的学习率会随着时间变化。这时如果使用L2正则化,正则项的效果也会随之变化;而如果使用权值衰减,那就与当前的学习率无关了,每次衰减的比例是固定的。
L2正则化和权重衰减是一样的吗?
L2正则化和权值衰减不是一回事,但可以通过基于学习率的权值衰减因子的重新参数化使SGD等效。困惑吗?让我给你详细解释一下。
权重衰变方程给出下面λ是衰减系数。

![]()
L2正则化可被证明为SGD情况下的权值衰减,证明如下:
让我们首先考虑下图9所示的L2正则化方程。我们的目标是重新参数化它,使其等价于图8中给出的权重衰减方程。
![]()
因此,我们得出结论,尽管权重衰减和L2正则化在某些条件下可能达到等价,但仍然是略有不同的概念,应该区别对待,否则会导致无法解释的性能下降或其他实际问题。

这个是我看着老师的ppt,弄的。
分析这一结论在动量法和Adam算法中是否成立?
L2正则化梯度更新的方向取决于最近一段时间内梯度的加权平均值。
当与自适应梯度相结合时(动量法和Adam算法),
L2正则化导致导致具有较大历史参数 (和/或) 梯度振幅的权重被正则化的程度小于使用权值衰减时的情况。
总结
首先,这次,写的很细,虽然有点累,但是还是一点一点的去写了,去弄明白了,感觉直接抄网上的答案,没什么意义。
其次,哥们这次写的确实有点挣扎,因为中招了,没办法,但还是要努力。
其次,希望疫情快点过去吧,因为确实中招了,之后有点难受。
其次,明白了,偏差、方差、噪声、泛化误差以及过拟合和欠拟合之间的关系,这次推的时候发现,理解还是不深入。
偏差、方差、噪声、泛化误差以及过拟合和欠拟合之间的关系_你吃过卤汁牛肉吗的博客-CSDN博客_误差、噪声、偏差、方差的区别与联系
最后,当然是谢谢老师,感谢老师在学习和生活上的关心(哈哈哈)。
这次说一下,每个流程图都是自己画的,没有去网上随便粘一个,虽然粘一个又好又省事,但是感觉就没啥意义了,感觉画了这么多,还是有点坚持的感觉(哈哈哈)。