从头开始实现YOLOV3
本讲义是关于从头开始构建YOLO v3检测器的简要说明,详细介绍了如何从配置文件创建网络架构,加载权重和设计输入/输出管道。
看懂后文说明的先决条件
对于后文的阅读,如果不熟悉一下概念的同学,请先复习:
- 你应该了解卷积神经网络是如何工作的。这还包括剩余块、跳过连接和上采样的知识。
- 什么是对象检测、边界框回归、IoU 和非最大抑制。
- 基本 PyTorch 用法。您应该能够轻松创建简单的神经网络。
对象检测概述
对象检测是一个从深度学习的最新发展中受益匪浅的领域。近年来,人们开发了许多用于对象检测的算法,其中一些包括YOLO,SSD,Mask RCNN和RetinaNet。
第一部分 了解YOLOV3的工作原理
YOLO代表你只看一次。它是一个对象检测器,它使用深度卷积神经网络学习的特征来检测对象。在我们用代码实现之前,我们必须了解YOLO是如何工作的。
完全卷积神经网络
YOLO仅使用卷积层,使其成为完全卷积网络(FCN)。它有75个卷积层,具有残差连接和上采样层。不使用任何形式的池化,并且使用步幅为 2 的卷积层对特征映射进行下采样。这有助于防止由于池化导致的低级特征丢失。
作为FCN,YOLO与输入图像的大小是不变的。如果我们想批量处理图像(批量图像可以由GPU并行处理,从而提高速度),我们需要所有图像具有固定高度和宽度。这是将多个图像连接成一个大批量所必需的(将许多PyTorch张量连接成一个batch)
网络通过称为网络步幅的因子对图像进行下采样。例如,如果网络的步幅为 32,则大小为 416 x 416 的输入图像将生成大小为 13 x 13(416/32=13) 的输出。通常,网络中任何图层的步幅都等于图层输出小于网络输入图像的因子。通常网络中任意一层的步长等于该层输出图像小于网络输入图像的因子。
解释输出
通常,(与所有对象检测器的情况一样)卷积层学习的特征被传递到分类器/回归量上,该分类器/回归量进行检测预测(边界框的坐标,类标签等)。
在YOLO中,预测是通过使用1 x 1卷积的卷积层来完成的。
现在,首先要注意的是,我们的输出是一个特征图。由于我们使用了 1 x 1 卷积,因此预测图的大小正好是之前特征图的大小。在YOLO v3(及其后代)中,解释此预测映射的方式是每个单元格可以预测固定数量的边界框。
虽然描述特征图中一个单元的技术上正确的术语是神经元,但称其为细胞使其在我们的上下文中更加直观。
在深度方面,我们在特征图中有 (B x (5 + C)) 个条目。这里的B 表示每个单元格可以预测的边界框数。根据论文,这些边界框中的每一个都可能专门用于检测某种物体。每个边界框都有 5 + C 个属性,这些属性描述每个边界框的中心坐标、尺寸、置信度和 每一类的概率。YOLO v3 为每个单元格预测 3 个边界框。
如果对象的中心落在某个单元格的范围内,则希望该特征图的每个单元格都通过该对象的边界框来预测该对象。(感受野是神经元可见的输入图像区域。不熟悉的同学,请看课件)。这与YOLO的训练方式有关,其中只有一个边界框负责检测任何给定对象。
首先,我们必须确定此边界框属于哪个单元格。为此,我们将输入图像划分为与最终特征图的尺寸相等的网格。让我们考虑下面一个例子,其中输入图像为416 x 416,网络的步幅为32。如前所述,特征图的尺寸将为 13 x 13。然后,我们将输入图像分成13 x 13个单元格。
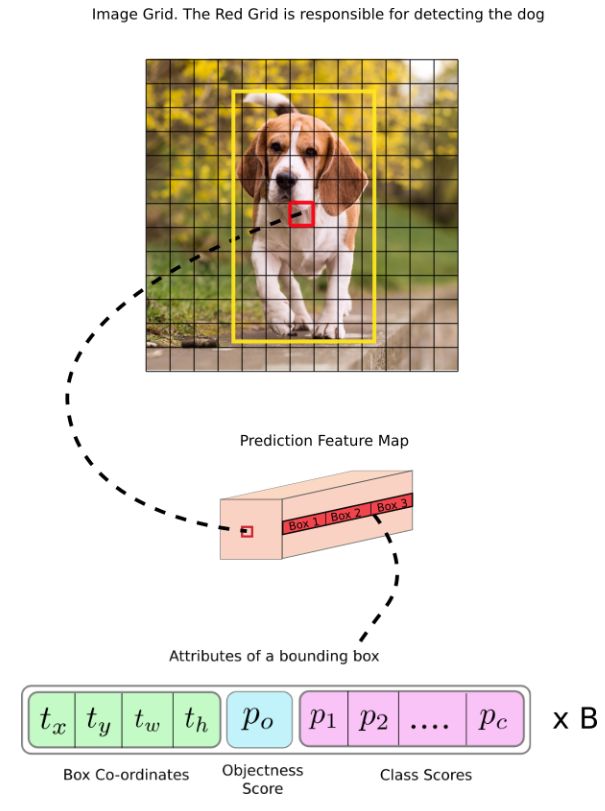
然后,选择包含目标的真实框(ground truth)中心(标记为红色)的单元格(在输入图像上)作为负责预测对象的单元格,其中包含ground truth框(标记为黄色)的中心。
现在,红色单元格是网格上第 7 行中的第 7 个单元格。现在,我们将特征图上第 7 行中的第 7 个单元格(特征图上的相应单元格)指定为负责检测狗的单元格。
请注意,我们在这里讨论的单元格是预测特征图上的单元格。我们将输入图像划分为网格,只是为了确定预测特征图的哪个单元格负责预测。
锚框(Anchor Boxes,也称先验框)
预测边界框的宽度和高度在实践中这会导致训练期间梯度不稳定。因此,大多数现代对象检测器是预测对数空间变换,或者只是预测到预定义的默认边界框(称为**anchor **)的偏移。
然后,将这些变换应用于锚框以获得预测。YOLO v3 有三个anchor ,可以用于预测每个单元格的三个边界框。
回到我们之前的问题,负责检测狗的边界框将是与真实框具有最高IoU的边界框。
进行预测
以下公式描述如何转换网络输出以获得边界框预测。
b x = σ ( t x ) + c x b y = σ ( t y ) + c y b w = p w e t w b h = p h e t h \begin{aligned} b_{x} &=\sigma\left(t_{x}\right)+c_{x} \\ b_{y} &=\sigma\left(t_{y}\right)+c_{y} \\ b_{w} &=p_{w} e^{t_{w}} \\ b_{h} &=p_{h} e^{t_{h}} \end{aligned} bxbybwbh=σ(tx)+cx=σ(ty)+cy=pwetw=pheth
b x b_x bx, b y b_y by, b w b_w bw, b h b_h bh是我们预测的 x x x, y y y中心坐标,宽度和高度。 t x t_x tx, t y t_y ty, t w t_w tw, t h t_h th 是网络输出的内容。 c x c_x cx 和 c y c_y cy 是网格的左上角坐标。 p w p_w pw 和 p h p_h ph 是Anchor box尺寸。
中心坐标
请注意,我们正在通过 Sigmoid 函数运行中心坐标预测。这将强制输出的值介于 0 和 1 之间。为什么会这样呢?
通常,YOLO 不会预测边界框中心的绝对坐标。它预测的偏移量为:
- 相对于预测对象的网格单元格的左上角。
- 通过特征图中单元的尺寸进行归一化,即 1。
例如,考虑我们的上图检测狗的情况。如果中心的预测值为 (0.4, 0.7),则意味着中心位于 13 x 13 特征图上的 (6.4, 6.7)。(由于红色单元格的左上角坐标是(6,6))。
但是如果预测的 x,y 坐标大于 1,比如 (1.2, 0.7),会发生什么情况。这意味着中心位于 (7.2, 6.7)。请注意,根据上面的值,狗应该位于第7行的第8个单元格中。这打破了YOLO之前的要求,因为如果我们假设红盒子负责预测狗,狗的中心必须位于红色格子中,而不是在它旁边的格子中。
因此,为了解决这个问题,输出通过一个sigmoid函数传递,该函数在0到1的范围内挤压输出,有效地将中心保持在预测的网格中。
边界框的尺寸
通过将对数空间变换应用于输出,然后乘以特征图尺寸来预测边界框的尺寸。
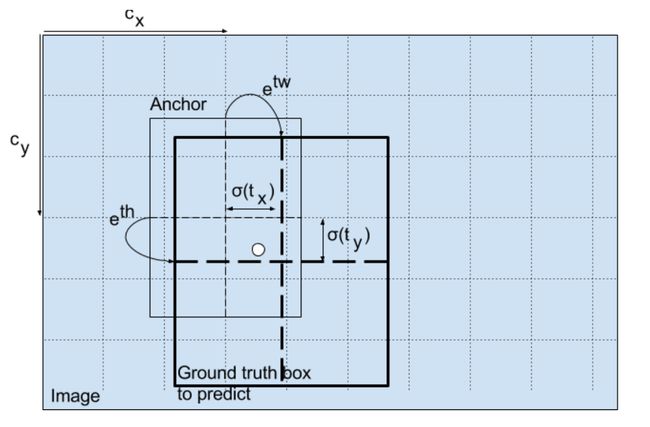
如何转换检测器输出以提供最终预测。图片来源。http://christopher5106.github.io/
生成的预测 b w b_w bw 和 b h b_h bh 通过图像的高度和宽度进行归一化。因此,如果包含狗的框的预测 b x b_x bx 和 b y b_y by 是 (0.3, 0.8),则 13 x 13 特征图上的实际宽度和高度为 (13 x 0.3, 13 x 0.8)。
目标置信度
目标置信度表示对象包含在边界框内的概率(背景或前景)。对于红色和相邻网格,它应该接近 1,而对于角处的网格,它应该接近 0。
目标置信度也通过sigmoid传递,因为它将被解释为概率。
类别概率
类别概率表示检测到的对象属于特定类(狗、猫、香蕉、汽车等)的概率。在 v3 之前,YOLO 用于软化类分数。
但是,该设计选择在v3中已被删除,作者选择使用sigmoid代替。原因是Softmaxing类分数假设这些类是相互排斥的。简单来说,如果一个对象属于一个类,那么它保证它不能属于另一个类。对于简单的COCO数据集来说,情况确实如此。
然而,当我们有像女性和人这样的多分类问题时,这种假设可能并不成立。这就是作者避免使用Softmax激活的原因。
多尺度预测
YOLO v3在3个不同的尺度上进行预测。检测层用于对三种不同尺寸的特征图进行检测,步幅分别为32、16、8。这意味着,在输入为 416 x 416 的情况下,我们在 13 x 13、26 x 26 和 52 x 52 的刻度上进行检测。
网络对输入图像进行缩减采样,直到进入第一个检测层,其中使用步幅为 32 的图层的特征图进行检测。此外,图层按系数 2 进行上采样,并与具有相同特征图大小的先前图层的进行通道维度的连接。现在在步幅为 16 的图层上进行另一次检测。重复相同的上采样过程,并在步幅8的层进行最终检测。
在每个比例下,每个单元格使用 3 个锚点预测 3 个边界框,使得使用的锚点总数为 9 个。(不同尺度的锚点不同)

YOLO作者在论文中说,这种方式有助于YOLO v3更好地检测小物体,这是早期版本的YOLO中存在的问题。上采样可以帮助网络学习细粒度特征,这些特征有助于检测小物体。
输出处理
对于大小为 416 x 416 的图像,YOLO 预测 ((52 x 52) + (26 x 26) + 13 x 13)) x 3 = 10647 个边界框。但是,就我们的目标而言,只有一只狗。如何将检测值从 10647 减少到 1?
按对象置信度设置阈值
首先,我们根据框的objectness score来过滤它们。通常,分数低于阈值的框将被忽略。
非极大值抑制(NMS)
NMS旨在解决同一图像的多次检测问题。例如,红色网格单元格的所有 3 个边界框都可以检测到一个框,或者相邻单元格可以检测到相同的对象。

实现
YOLO只能检测属于用于训练网络的数据集中存在的类的对象。我们将使用官方提供的预训练权重文件作对网络进行初始化。这些权重是通过在COCO数据集上训练网络而获得的,因此我们可以检测到80个对象类别。
这就是第一部分。通过第一部分,你应该对YOLO工作原理有了一个基本了解。但是,如果您想深入了解YOLO的工作原理,它是如何训练的以及它与其他检测器之间的性能比较,你可以阅读原始论文,我在下面提供了链接。
第二部分 创建网络结构中的层
开始
首先创建项目代码所在的目录。
darknet.py : 网络基本架构
``util.py `: 一些辅助函数
配置文件
官方代码(用C编写)使用配置文件来构建网络。cfg 文件逐块描述网络的布局,这有点类似于caffe框架。我们使用官方的cfg配置文件,这里老师会提供给你。
如果打开配置文件,将看到类似下面的内容。
[convolutional]
batch_normalize=1
filters=64
size=3
stride=2
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=32
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=64
size=3
stride=1
pad=1
activation=leaky
[shortcut]
from=-3
activation=linear
...省略...
我们在上面看到4个blocks。其中,3个描述了卷积层,然后是shortcut层。shortcut层是skip连接,类似于 ResNet 中使用的残差连接。YOLO中使用了5种类型的层:
卷 积
[convolutional]
batch_normalize=1
filters=64
size=3
stride=1
pad=1
activation=leaky
shortcut
[shortcut]
from=-3
activation=linear
shortcut层是skip连接,类似于 ResNet 中使用的残差连接。from -3,意味着shortcut层的输出是通过从shortcut层向后添加上一层和第三层的特征映射来获得的。
上采样
[upsample]
stride=2
通过使用双线性上采样,stride=2 对上一层中的特征图进行上采样。
Route
[route]
layers = -4
[route]
layers = -1, 61
路由层值得一些解释。它有一个属性layers,可以有一个或两个值。
当layers属性只有一个值时,它输出按该值索引的层的特征图。在我们的例子中,它是-4,所以这层将输出从改层向后数四层的feature map。
当层有两个值时,它返回按其值索引的层的连接特征映射。在我们的例子中,它是- 1,61,该层将输出前一层(-1)和第61层的特征图,并沿着通道维度进行连接。
注意区别:Route层是实现通道维度的合并,代码中使用Concat,shortcut层类似残差连接,直接进行数据相加。
YOLO
[yolo]
mask = 0,1,2
anchors = 10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
classes=80
num=9
jitter=.3
ignore_thresh = .5
truth_thresh = 1
YOLO层对应于第1部分中描述的检测层。描述了 9 个锚框,但仅使用按标记mask属性索引的锚框。此处,值为 0,1,2,这意味着使用第一个、第二个和第三个锚点。,因为检测层的每个单元格预测3个框。总的来说,我们有3个尺度的检测层,总共组成了9个不同大小的锚框。
Net
[net]
# Testing
batch=1
subdivisions=1
# Training
# batch=64
# subdivisions=16
width= 320
height = 320
channels=3
momentum=0.9
decay=0.0005
angle=0
saturation = 1.5
exposure = 1.5
hue=.1
在 cfg 中调用了另一种成为 n e t net net的块,但我不会将其称为层,因为它仅描述有关网络输入和训练参数的信息,它不用于YOLO的正向传播。但是,它确实为我们提供了诸如网络输入大小之类的信息,我们用它来调整正向传播中的锚点。
解析配置文件
在开始之前,请在darknet.py文件顶部添加必要的导入。
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
我们定义一个名为parse_cfg 的函数,它将配置文件的路径作为输入。
def parse_cfg(cfgfile):
"""
读取配置文件作为输入
返回一个块列表
每个blocks描述一个神经网络中待搭建的block
block表示为列表中的字典
"""
这里的想法是解析cfg,并将每个块存储为字典。块的属性及其值作为键值对存储在字典中。当我们通过cfg进行解析时,我们不断将这些字典(由代码中的变量表示)附加到列表中。我们的函数将返回此块。
我们首先将 cfg 文件的内容保存在字符串列表中。下面的代码对此列表执行一些预处理。
file = open(cfgfile, 'r')
lines = file.read().split('\n') # 将每一行存在列表中
lines = [x for x in lines if len(x) > 0] # 去除空行
lines = [x for x in lines if x[0] != '#'] # 去除注释行
lines = [x.rstrip().lstrip() for x in lines] # 去除每一行左右的空格
然后,我们循环访问生成的列表以获取块。
block = {}
blocks = []
for line in lines:
if line[0] == "[": # [ 说明开始了一个新的block
if len(block) != 0: # 如果一个 block不为空,则说明在存储上一个block的值
blocks.append(block) # 添加到blocks list
block = {} # 重新初始化一个新的block
block["type"] = line[1:-1].rstrip()
else:
key,value = line.split("=")
block[key.rstrip()] = value.lstrip()
blocks.append(block)
return blocks
构建模块
现在,我们将使用上面parse_cfg返回的列表构造PyTorch模块。
我们在列表中有5种类型的层(如上所述)。PyTorch 已经提供了一些pre-built layers,如:卷积和上采样等。我们需要扩展nn.Module来实现我们自己的模块。
create_modules函数接受parse_cfg函数返回的blocks列表作为输入。
def create_modules(blocks):
net_info = blocks[0] #捕获关于输入和预处理的信息
module_list = nn.ModuleList()
prev_filters = 3
output_filters = []
在循环访问块列表之前,我们定义一个变量net_info来存储有关网络的信息。
nn.ModuleList
我们的函数将返回nn.Module 。此类类似于包含对象的普通列表。但是,当我们添加nn.ModuleList为nn.Module对象的成员时(即当我们将模块添加到我们的网络时),在nn.ModuleList内的所有nn.Module对象的参数也都被添加为nn.Module对象的参数。
当我们定义一个新的卷积层时,我们必须定义它的kernel维度。虽然kernel高度和宽度由 cfg 文件提供,但kernel的深度恰好是前一层中filter的数量(或特征图的通道数)。这意味着我们需要跟踪卷积层的的filter数量。我们使用变量prev_filter来执行此操作。我们将其初始化为 3,因为图像具有 3 个RGB 通道的filter。
route层将带来(可能concatenated)先前层的特征图的映射。如果在route层前有一个卷积层,则卷积kernel将应用于先前层的特征映射。因此,我们不仅需要跟踪前一层中的filter数量,还需要跟踪前面每一层中的filter数量。在迭代时,我们将每个块的输出追加到列表output_filters中。
现在,迭代block lists,并为每个块创建一个PyTorch模块。
for index, x in enumerate(blocks[1:]):
module = nn.Sequential()
# 检查block类型
# 为block创建新胡module
# append到module_list
nn.Sequential类用于按顺序执行多个nn.Module对象。如果你看一下cfg,你会意识到一个块可能包含多个层。例如,convolutional块还包含有BatchNorm层、leaky ReLU激活层。我们使用nn.Sequential将这些层串联在一起,这就是add_module函数。
if x["type"] == "convolutional":
# 获得layer的激活数据
activation = x["activation"]
try:
batch_normalize = int(x["batch_normalize"])
bias = False
except:
batch_normalize = 0
bias = True
filters = int(x["filters"])
padding = int(x["pad"])
kernel_size = int(x["size"])
stride = int(x["stride"])
if padding:
pad = (kernel_size - 1) // 2
else:
pad = 0
# 添加convolutional layer
conv = nn.Conv2d(prev_filters, filters, kernel_size, stride, pad, bias=bias)
module.add_module("conv_{0}".format(index), conv)
# 添加 Batch Norm Layer
if batch_normalize:
bn = nn.BatchNorm2d(filters)
module.add_module("batch_norm_{0}".format(index), bn)
# 检查激活函数.
# 对于YOLO可能是Linear或者 Leaky ReLU
if activation == "leaky":
activn = nn.LeakyReLU(0.1, inplace=True)
module.add_module("leaky_{0}".format(index), activn)
# upsampling layer
# 使用Pytorch内的双线性插值上采样模块
elif x["type"] == "upsample":
stride = int(x["stride"])
upsample = nn.Upsample(scale_factor=2, mode="bilinear")
module.add_module("upsample_{}".format(index), upsample)
Route Layer / Shortcut Layers
接下来,我们编写用于创建Route和Shortcut层的代码。
# route layer
elif x["type"] == "route":
x["layers"] = x["layers"].split(',')
# route的开始层
start = int(x["layers"][0])
# route的结束层,如果route参数中有第二个数字.
try:
end = int(x["layers"][1])
except:
end = 0
# Positive anotation
if start > 0:
start = start - index
if end > 0:
end = end - index
route = EmptyLayer()
module.add_module("route_{0}".format(index), route)
if end < 0:
filters = output_filters[index + start] + output_filters[index + end]
else:
filters = output_filters[index + start]
# shortcut
elif x["type"] == "shortcut":
shortcut = EmptyLayer()
module.add_module("shortcut_{}".format(index), shortcut)
上面的代码值得一提。首先,我们提取属性的值,将其转换为整数并将其存储在列表中。然后我们定义了一个新层EmptyLayer,顾名思义,它只是一个空层,只是为了保证代码的一致性,用于占位。
route = EmptyLayer()
EmptyLayer定义如下:
class EmptyLayer(nn.Module):
def __init__(self):
super().__init__()
为什么这里设置一个空层,看代码什么都没做?
Route层,就像任何其他层一样执行操作(接受来自上一层的输入进行前向传播)。在PyTorch中,当我们定义一个新层时,我们继承nn.Module并在forward方法中定义需要执行的操作。
为了设计Route块的层,我们必须构建一个nn.Module对象,该对象使用属性值作为其成员进行初始化。然后,我们可以编写代码来连接(concatenate)forward中的特征图。最后,我们在网络的forward方法中执行此层。
但是,鉴于concatenate代码相当短且简单(只需要调用torch.cat完成特征图的拼接),如上所述设计层将导致不必要的抽象,这只会增加代码。相反,我们可以做的是放置一个虚拟层来代替建议的Route层,然后直接在nn.Module对象的forward方法中执行串联。
在Route前面的卷积层将它的Kernel应用于(可能是连接的)前一层的特征图。下面的代码更新过filter变量,以保存Route输出的filter数量。
if end < 0:
#If we are concatenating maps
filters = output_filters[index + start] + output_filters[index + end]
else:
filters= output_filters[index + start]
Shortcut 层也利用了空层,因为它还执行非常简单的操作(加法)。无需更新更新变量,因为它只是将上一层的特征图加到后面层的特征图中。
YOLO层
最后,我们编写用于创建YOLO层的代码。
# Yolo是检测层
elif x["type"] == "yolo":
mask = x["mask"].split(",")
mask = [int(x) for x in mask]
anchors = x["anchors"].split(",")
anchors = [int(a) for a in anchors]
anchors = [(anchors[i], anchors[i+1]) for i in range(0, len(anchors),2)]
anchors = [anchors[i] for i in mask]
detection = DetectionLayer(anchors)
module.add_module("Detection_{}".format(index), detection)
在循环结束时,我们进行记录。
module_list.append(module)
prev_filters = filters
output_filters.append(filters)
循环的主体到此结束。在create_modules函数的末尾,我们返回一个包含net_info和module_list 的元组。
return (net_info, module_list)
在上面的代码中,我们定义看了一个新层我们定义了一个新层DetectionLayer,用于保存用于检测边界框的锚点。
检测层定义为:
class DetectionLayer(nn.Module):
def __init__(self, anchors):
super(self).__init__()
self.anchors = anchors
测试一下
可以通过在darknet.py文件的末尾键入以下代码并运行该文件来测试代码。
if __name__ == '__main__':
blocks = parse_cfg("config/yolov3.cfg")
print(create_modules(blocks))
你将看到一个长列表(正好包含106个项目),其元素将如下所示
.
.
(9): Sequential(
(conv_9): Conv2d (128, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(batch_norm_9): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True)
(leaky_9): LeakyReLU(0.1, inplace)
)
(10): Sequential(
(conv_10): Conv2d (64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(batch_norm_10): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True)
(leaky_10): LeakyReLU(0.1, inplace)
)
(11): Sequential(
(shortcut_11): EmptyLayer(
)
)
.
.
.
下一部分,我们将这些blocks进行组装,从输入图像产生输出。
第三部分 构建网络的前向传播过程
在这一部分中,我们将在PyTorch中实现YOLO的网络架构,以便我们可以在给定图像的情况下生成输出。
我们的目标是设计网络的前向传播过程。
定义网络
正如我之前指出的,我们使用nn.Module类在PyTorch中构建自定义架构。让我们为检测器定义一个网络。在darknet.py文件中,我们添加以下类。
class Darknet(nn.Module):
def __init__(self, cfgfile):
super(Darknet, self).__init__()
self.blocks = parse_cfg(cfgfile)
self.net_info, self.module_list = create_modules(self.blocks)
在这里,我们已将继承nn.Module类,并将我们的类命名为Darknet 。我们使用blocks、和net_info、module_list 初始化网络。
实现网络前向传播
网络的前向传播是通过重写nn.Module类的forward方法实现的。
forward有两个目的:首先,计算输出;其次,以更易于处理的方式转换输出的检测特征图(例如,转换它们,以便可以拼接多个不同比例的特征图,否则由于它们具有不同的维度,不能进行拼接)。
def forward(self, x, CUDA):
modules = self.blocks[1:]
outputs = {} #保存每一层的输出到列表,因为route层需要使用
forward有三个输入参数 ,self输入 x和 CUDA, CUDA如果为 true,将使用 GPU 来加速前向传播。
在这里,我们从 self.blocks[1:]迭代而不是self.blocks,因为 self.blocks的第一个元素是一个net block,它不是前向传播的一部分。
由于ROUTE和shortcut层需要先前层的输出特征图,因此我们将每个层的输出特征图存在字典outputs中。键是层的索引,值是特征图。
与create_modules函数的情况一样,我们现在迭代module_list包含的模块。这里要注意的是,模块的追加顺序与它们在配置文件中存在的顺序相同。这意味着,我们可以简单地通过输入每个模块运行以获得输出。
write = 0 # 稍后解释
for i, module in enumerate(modules):
module_type = (module["type"])
卷积层和上采样层
如果模块是卷积或上采样模块,则前向传播如下进行。
if module_type == "convolutional" or module_type == "upsample":
x = self.module_list[i](x)
Route Layer / Shortcut Layer
如果您查看Route层的代码会发现,我们必须考虑两种情况(如第 2 部分所述)。对于拼接两个特征图的情况,我们使用torch.cat,第二个参数为 1 。这是因为我们希望沿通道维度拼接特征图。(在PyTorch中,卷积层的输入和输出的格式为B X C X H X W。深度对应于通道维度)。
elif module_type == "route":
layers = module["layers"]
layers = [int(a) for a in layers]
if (layers[0]) > 0:
layers[0] = layers[0] - i
if len(layers) == 1:
x = outputs[i + (layers[0])]
else:
if (layers[1]) > 0:
layers[1] = layers[1] - i
map1 = outputs[i + layers[0]]
map2 = outputs[i + layers[1]]
x = torch.cat((map1, map2), 1)
elif module_type == "shortcut":
from_ = int(module["from"])
x = outputs[i-1] + outputs[i+from_]
YOLO(检测层)
YOLO 的输出是一个卷积特征图,其中包含沿特征图深度维度的边界框属性。这些由每个格子预测的边界框属性彼此逐个堆叠。因此,如果获取(5,6)处单元格的第二个边界,则必须按 m a p [ 5 , 6 , ( 5 + C ) : 2 ∗ ( 5 + C ) ] map[5,6, (5+C): 2*(5+C)] map[5,6,(5+C):2∗(5+C)]索引它。这种形式对于输出处理非常不方便,例如通过对象置信度进行阈值,向中心添加网格偏移,应用锚点等。
另一个问题是,由于检测发生在三个不同尺度上,因此预测图的尺寸将有所不同。尽管三个特征映射的尺寸不同,但要对它们执行的输出处理操作是相似的。最好在单个张量上执行这些操作,而不是在三个单独的张量上执行这些操作。
为了解决这些问题,引入了函数predict_transform
对输出进行变换
我们将该predict_transform函数保存在util.py于文件中,当我们在Darknet类的forward中使用它时,我们将导入该函数。
将导入添加到util.py顶部
from __future__ import division
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
import cv2
predict_transform接受5个参数:预测(我们的输出)、inp_dim(输入图像尺寸)、锚点、num_classes和可选的 CUDA 标志
def predict_transform(prediction, inp_dim, anchors, num_classes, CUDA = True):
predict_transform函数获取检测特征图并将其转换为二维张量,其中张量的每一行都按以下顺序对应于边界框的属性。

下面是执行上述转换的代码。
# 对一个特征层的特征进行变换操作(先验框调整)
# prediction的维度是:[batch_size, bbox_attrs*num_anchors, grid_size, grid_size]
# # -----------------------anchors:-----------------------------#
# # 13x13的特征层对应的anchor是[116,90],[156,198],[373,326]
# # 26x26的特征层对应的anchor是[30,61],[62,45],[59,119]
# # 52x52的特征层对应的anchor是[10,13],[16,30],[33,23]
# # -----------------------------------------------------------#
batch_size = prediction.size(0)
stride = inp_dim // prediction.size(2) # 步距:三个YOLO层分别为8(416/52),16(416/26),32(416/13)
grid_size = inp_dim // stride # 网格尺寸:
bbox_attrs = 5 + num_classes # COCO:5+80 =85 VOC:5+20=25
num_anchors = len(anchors) # 3
# [batch_size, bbox_attrs*num_anchors, grid_size, grid_size]
# -> [batch_size, bbox_attrs * num_anchors, grid_size * grid_size]
prediction = prediction.view(batch_size, bbox_attrs * num_anchors, grid_size * grid_size)
锚点的尺寸与 net block的height 和 width属性一致。这些属性描述输入图像的尺寸,该尺寸比检测地图大(按步幅系数计算)。因此,我们必须将锚点除以检测特征图的步幅。
# -----------------------------------------------------------#
# 13x13的特征层对应的anchor是[116,90],[156,198],[373,326]
# 26x26的特征层对应的anchor是[30,61],[62,45],[59,119]
# 52x52的特征层对应的anchor是[10,13],[16,30],[33,23]
#
# 以13x13的特征层为例,anchor经过变换后的值为:
# [(3.625, 2.8125), (4.875, 6.1875), (11.65625, 10.1875)]
# -----------------------------------------------------------#
anchors = [(a[0] / stride, a[1] / stride) for a in anchors]
现在,我们需要根据我们在第 1 部分中讨论的数学公式转换我们的输出。
对中心坐标x,y和目标置信度求sigmoid
#Sigmoid the centre_X, centre_Y. and object confidencce
prediction[:,:,0] = torch.sigmoid(prediction[:,:,0])
prediction[:,:,1] = torch.sigmoid(prediction[:,:,1])
prediction[:,:,4] = torch.sigmoid(prediction[:,:,4])
将网格偏移预测量加到网格中心中标。
# Add the center offsets
grid = np.arange(grid_size)
# 生成网格,a,b分别 对应x坐标和y坐标组成的列表
# a和b的维度均为[grid_size,grid_size]
a, b = np.meshgrid(grid, grid)
# 将坐标列表转换为列向量
# 以13x13的网格为例,x_offset和y_offset的shape均为:[169,1] [grid_size*grid_size,1]
x_offset = torch.FloatTensor(a).view(-1, 1)
y_offset = torch.FloatTensor(b).view(-1, 1)
if CUDA:
x_offset = x_offset.cuda()
y_offset = y_offset.cuda()
# cat->[169,2] [grid_size*grid_size,2]
# repeat->[169, 6] [grid_size*grid_size,6]
# view-> [507, 2] [grid_size*grid_size*3,2]
# unsqueeze -> [1,507, 2] [1,grid_size*grid_size*3,2] 增加batch维
x_y_offset = torch.cat((x_offset, y_offset), 1).repeat(1, num_anchors).view(-1, 2).unsqueeze(0)
# prediction:[batch_size,grid_size * grid_size* num_anchors ,bbox_attrs ]
prediction[:, :, :2] += x_y_offset
将锚点应用于定界框的尺寸。
# 对数空间变换height和width
anchors = torch.FloatTensor(anchors) # ->shape:[3,2]
if CUDA:
anchors = anchors.cuda()
#->shape:[1,grid_size*grid_size,2]
anchors = anchors.repeat(grid_size*grid_size, 1).unsqueeze(0)
prediction[:,:,2:4] = torch.exp(prediction[:,:,2:4])*anchors
将Sigmoid激活函数应用到类别分数上
prediction[:,:,5: 5 + num_classes] = torch.sigmoid((prediction[:,:, 5 : 5 + num_classes]))
最后要做的是将检测映射特征图的大小调整为输入图像的大小。此处的边界框属性的取决于特征映射(例如,13 x 13)。如果输入图像为 416 x 416,我们将属性乘以 32 或步幅变量。
prediction[:, :, :4] *= stride
循环体到此结束。函数最后返回预测predictions
return prediction
重新回顾检测层
现在我们已经转换了输出张量,现在可以将三个不同尺度的检测图拼接成一个大张量。请注意,在我们转换之前,这是不可能的,因为无法连接具有不同空间维度的特征图。但是从现在开始,我们的输出张量只是一个带有边界框的表,拼接是非常可能的。
我们继续往下的一个障碍是,我们不能初始化一个空的张量,然后将一个非空的(形状不同)的张量连接到它。因此,我们延迟(保存检测的张量)的初始化,直到我们获得第一个检测映射,然后在获得后续检测时进行特诊图拼接。
请注意函数 中有一行之前没有解释的write = 0。该标志用于指示我们是否遇到第一次检测。如果为 0,则表示尚未初始化收集器。如果它是 1,则表示收集器已初始化,我们可以将检测的特征图拼接到它。
现在,我们完成了predict_transform函数编写,接下来在forward过程中使用它进行处理检测特征图。
在darknet.py文件顶部,添加以下导入。
from utils import *
然后,在Darknet类的函数中forward中:
elif module_type == 'yolo':
anchors = self.module_list[i][0].anchors
# 获取输入图像尺寸
inp_dim = int (self.net_info["height"])
# 获取类别数信息
num_classes = int (module["classes"])
# 变换
x = x.data
x = predict_transform(x, inp_dim, anchors, num_classes, CUDA)
if not write: #if no collector has been intialised.
detections = x
write = 1
else:
detections = torch.cat((detections, x), 1)
outputs[i] = x
现在,只需返回检测结果即可。
return detections
测试前向传播
下面是一个创建模拟输入的函数。在编写此函数之前,请将此测试图像保存到工作目录 。
现在,在darknet.py文件顶部定义函数,如下所示:
import cv2
def get_test_input():
img = cv2.imread("dog-cycle-car.png")
img = cv2.resize(img, (416,416)) # 将图片resize到网络要求的输入尺寸
img_ = img[:,:,::-1].transpose((2,0,1)) # BGR -> RGB | H X W C -> C X H X W
img_ = img_[np.newaxis,:,:,:]/255.0 #在维度0增加一维(for batch_size) | Normalise
img_ = torch.from_numpy(img_).float() #转换为浮点型
return img_
然后,我们键入以下代码:
if __name__ == '__main__':
# blocks = parse_cfg("config/yolov3.cfg")
# print(create_modules(blocks))
print("use GPU" if torch.cuda.is_available() else "use CPU")
model = Darknet("config/yolov3.cfg")
inp = get_test_input()
pred = model(inp, False)
print(pred)
将看到类似这样的输出:
( 0 ,.,.) =
16.0962 17.0541 91.5104 ... 0.4336 0.4692 0.5279
15.1363 15.2568 166.0840 ... 0.5561 0.5414 0.5318
14.4763 18.5405 409.4371 ... 0.5908 0.5353 0.4979
⋱ ...
411.2625 412.0660 9.0127 ... 0.5054 0.4662 0.5043
412.1762 412.4936 16.0449 ... 0.4815 0.4979 0.4582
412.1629 411.4338 34.9027 ... 0.4306 0.5462 0.4138
[torch.FloatTensor of size 1x10647x85]
此张量的形状为 1 x 10647 x 85:第一个维度是batch_size,这里值是1,因为我们测试只使用了单张图像。对于批处理中的每个图像,得到一个 10647 x 85 维的表。此表中每个表的行表示一个边界框((52 x 52) + (26 x 26) + 13 x 13)) x 3 = 10647 个边界框。(4对于COCO数据集:4 个 bbox 属性、1 个执行度和 80 个类的概率值;对于VOC数据集:4 个 bbox 属性、1 个执行度和 20个类的概率值)
此时,我们的网络具有随机权重,并且不会产生正确的输出。我们需要在我们的网络中加载一个权重文件。这里我们使用官方提供的在COCO数据集上预训练的权重。
下载预训练权重
下载链接,上课时候老师会提前提供给大家。
认识权重文件
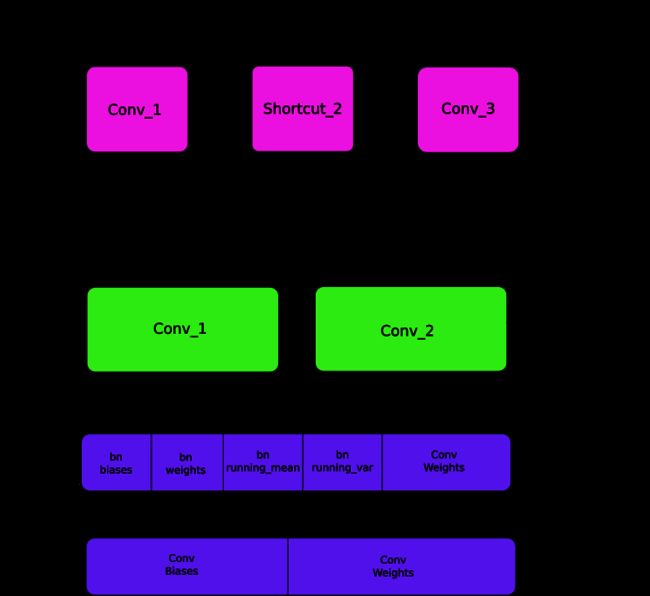
官方权重文件是包含以串行方式存储的权重的二进制文件。
必须了解清楚权重参数的存储方式,以便正确加载权重。权重在文件中以浮点型存储,文件中并无信息高速我们权重参数是属于那一层的,因此如果不熟悉文件组织方式,你可能将BatchNorm的权重错误的加载到了卷积模块。
首先,权重参数只对应两种类型的网络模块:batch norm和卷积。
这些层的权重的存储顺序与它们在配置文件中显示的顺序完全相同。因此,如果一个卷积块后面跟着一个shortcut块,shortcut块后面又是一个卷积块,则权重也是按顺序体现这两个卷积块。
当batch norm在卷积块中出现时,没有biase参数。而如果卷积块中没有batch norm,会有biase权重。
下图总结了权重如何存储:
加载权重
让我们编写一个加载权重函数。它将是Darknet类的成员函数。它除了参数self,只有一个权重文件的路径参数。
def load_weights(self, weightfile):
权重文件的前 160 个字节存储 5 个int32值,这些值构成文件头。
# 打开权重文件
fp = open(weightfile, "rb")
# 前五个值是文件头信息
# 1. 主版本号
# 2. 次版本号
# 3. 子版本号(修订号)
# 4,5. 网络看到的图片 (训练过程)
header = np.fromfile(fp, dtype=np.int32, count=5)
self.header = torch.from_numpy(header)
self.seen = self.header[3]
其余位现在按上述顺序表示权重。权重存储为float32或 32 位浮点数,可以将这些参数用np.ndarray进行加载:
# 加载剩余的权重参数
weights = np.fromfile(fp, dtype=np.float32)
现在,我们迭代权重文件,并将权重加载到我们网络的模块中。
ptr = 0
for i in range(len(self.module_list)):
module_type = self.blocks[i + 1]["type"]
# 如果 module_type 是 convolutional 就加载权重
# 否则忽略.
进入循环,我们首先检查convolutional块的batch_normalise标志是否为 True。在此基础上,我们加载权重。
if module_type == "convolutional":
model = self.module_list[i]
try:
batch_normalize = int(self.blocks[i + 1]["batch_normalize"])
except:
batch_normalize = 0
conv = model[0]
我们保留一个名为ptr的变量来跟踪我们在权重数组中的位置。现在,如果 batch_normalize为 True,我们将按如下方式加载权重:
if batch_normalize:
bn = model[1]
# 获取Batch Norm Layer的权重参数数目
num_bn_biases = bn.bias.numel()
# 加载权重
bn_biases = torch.from_numpy(weights[ptr:ptr + num_bn_biases])
ptr += num_bn_biases
bn_weights = torch.from_numpy(weights[ptr: ptr + num_bn_biases])
ptr += num_bn_biases
bn_running_mean = torch.from_numpy(weights[ptr: ptr + num_bn_biases])
ptr += num_bn_biases
bn_running_var = torch.from_numpy(weights[ptr: ptr + num_bn_biases])
ptr += num_bn_biases
# 将加载的权重转换为模型权重的维度
bn_biases = bn_biases.view_as(bn.bias.data)
bn_weights = bn_weights.view_as(bn.weight.data)
bn_running_mean = bn_running_mean.view_as(bn.running_mean)
bn_running_var = bn_running_var.view_as(bn.running_var)
# 将数据复制到模型
bn.bias.data.copy_(bn_biases)
bn.weight.data.copy_(bn_weights)
bn.running_mean.copy_(bn_running_mean)
bn.running_var.copy_(bn_running_var)
如果batch_norm为False,只需加载卷积层的bias即可。
else: # 如果batch_norm为False,只需加载卷积层的bias即可。
# biases数量
num_biases = conv.bias.numel()
# 加载群中
conv_biases = torch.from_numpy(weights[ptr: ptr + num_biases])
ptr = ptr + num_biases
# 将加载的权重转换为模型权重的维度
conv_biases = conv_biases.view_as(conv.bias.data)
# 将数据复制到模型
conv.bias.data.copy_(conv_biases)
最后,我们加载卷积层的权重。
# 加载卷积层的权重
num_weights = conv.weight.numel()
# 同上面
conv_weights = torch.from_numpy(weights[ptr:ptr + num_weights])
ptr = ptr + num_weights
conv_weights = conv_weights.view_as(conv.weight.data)
conv.weight.data.copy_(conv_weights)
我们已经完成了这个函数,你现在可以通过调用Darknet对象上的load_weights函数来加载对象中的权重。
if __name__ == '__main__':
# blocks = parse_cfg("config/yolov3.cfg")
# print(create_modules(blocks))
print("use GPU" if torch.cuda.is_available() else "use CPU")
model = Darknet("config/yolov3.cfg")
model.load_weights("config/yolov3.weights") # 新增代码
inp = get_test_input()
pred = model(inp, False)
print(pred)
这就是这部分的全部内容,随着我们的模型的构建和权重的加载,我们终于可以开始检测对象了。在下一部分,我们将介绍如何使用目标置信度阈值和非极大值抑制来生成最终的检测结果集合。
第四部分 置信度阈值和非极大值抑制
在前面的部分中,我们已经构建了模型,该模型在给定输入图像的情况下输出多个对象检测结果。确切地说,我们的输出是B x 10647 x 85形状的张量。B 是批处理中的图像数,10647 是每个图像预测的边界框数,85 是边界框属性数(中心点X坐标,中心点Y坐标,先验框调整宽度,先验框调整高度,目标执行度,80个分类的概率)。
这里再次回顾一下:10647=(13x13+26x26+52x52)x3 ,三种大小的特征图网格,每个网格三个锚框。85=4个边界框调整值(x,y,w,h)+1(目标置信度)+80个类别的概率(COCO数据集有80个类别)
但是,如第 1 部分 所述,我们必须将输出置于置信度阈值和非极大值抑制之下,以获得我将在本文的其余部分所说的真正的检测。为此,我们在util.py中将创建一个函数write_results:
def write_results(prediction, confidence, num_classes, nms_conf = 0.4):
# prediction:网络输出结果 Batch_size x 10647 x 85
# confidence:(目标置信度阈值)
# num_classes:分类数,COCO数据集为80,VOC为20
# nms_conf:NMS IoU阈值
该函数输入prediction、confidence (目标置信度阈值)、num_classes(分类数,在本例中为 80)和 nms_conf(NMS IoU 阈值)
目标置信度阈值
我们的预测张量包含有关B x 10647个边界框的信息。对于每个边界框,如果其置信度低于阈值,我们将它的每个属性(该边界框数据的整行)的值设置为零。
# 我们的预测张量包含Bx10647个边界框的信息。对于每个边界框,如果其置信度低于阈值,
# 我们将它的每个属性(该边界框数据的整行)的值设置为零。
# prediction[:,:,4] > confidence:shape:Batch_size x 10647
# .float() 上面的结果是True、False,转换为1. 0.
# .unsqueeze(2):shape还原为Batch_size x 10647 x1 方便后面相乘
conf_mask = (prediction[:,:,4] > confidence).float().unsqueeze(2)
# prediction中每一行的confidence字段低于阈值的话,改行所有值被设置为零
prediction = prediction*conf_mask
非极大值抑制
继续后面的内容,你应该已经了解什么是 IoU(交并比),以及什么是非极大值抑制,如果不了解的同学,请查看之前的课件。
我们现在拥有的边界框属性由中心坐标以及边界框的高度和宽度来描述。但是,使用每个框的一对对角的坐标来计算两个框的 IoU 会更容易。因此,我们将框的**(中心 x、中心 y、高度、宽度)属性转换为(左上角 x、左上角 y、右下角 x、右下角 y)。**
# 将框的(中心x、中心y、高度、宽度)坐标转换为
# (左上角x、左上角y、右下角x、右下角y)
box_corner = prediction.new(prediction.shape)
box_corner[:,:,0] = (prediction[:,:,0] - prediction[:,:,2]/2)
box_corner[:,:,1] = (prediction[:,:,1] - prediction[:,:,3]/2)
box_corner[:,:,2] = (prediction[:,:,0] + prediction[:,:,2]/2)
box_corner[:,:,3] = (prediction[:,:,1] + prediction[:,:,3]/2)
prediction[:,:,:4] = box_corner[:,:,:4]
每张图像的真实检测结果可能不同,比如:一个batch的大小是3,但其中的第1、2、3张图像分别有5、2、4个真实的检测目标。因此,置信度 阈值和NMS必须对同一张图像设置。这意味着,我们无法对所涉及的操作进行向量化,并且必须遍历prediction的第一维(batch维)。
# 遍历batch内的每一张图片,逐一进行处理
batch_size = prediction.size(0)
write = False
for ind in range(batch_size):
image_pred = prediction[ind] #image Tensor
#confidence阈值
#NMS
如前所述,write标志用于指示我们尚未初始化output ,我们将使用一个张量在整个batch中收集真正的检测结果。
进入循环后,我们稍微清理一下。请注意,每个边界框行都有 85 个属性,其中 80 个是80个分类的概率。此时,我们只关心具有最大概率的类。因此,我们从每行中删除 80 个类概率,添加具有最大值的类别的索引,以及该分类的概率值。
#confidence阈值
# max_conf:最大值,shape:[10647,]
# max_conf_score:最大值的索引shape:[10647,]
max_conf, max_conf_score = torch.max(image_pred[:,5:5+ num_classes], 1)
# shape:[10647,]->shape:[10647,1]
max_conf = max_conf.float().unsqueeze(1)
# shape:[10647,]->shape:[10647,1]
max_conf_score = max_conf_score.float().unsqueeze(1)
seq = (image_pred[:,:5], max_conf, max_conf_score)
# image_pred shape:[10647,6] ,
# 其中前0-4列是边界框属性,最后两列分别是最大概率和最大概率的索引
image_pred = torch.cat(seq, 1)
还记得我们已将目标置信度小于阈值的边界框行设置为零吗?去除它们。
# 获得目标置信度非零的索引,返回数据维度为z x n的二维张量,z为非零元素个数,n为输入张量维度
# image_pred[:, 4] shape:torch.Size([10647])
# torch.nonzero(image_pred[:, 4]) shape:[非零的索引,1]
non_zero_ind = (torch.nonzero(image_pred[:, 4]))
try:
# non_zero_ind.squeeze()->shape:[非零的索引]
# 通过这行代码将置信度非零的行保留下来
image_pred_ = image_pred[non_zero_ind.squeeze(), :].view(-1, 7)
except:
continue
# 为了兼容 PyTorch 0.4 版本
# 因为当没有检测到物体时,上面的代码不会抛出异常
# 因为在PyTorch 0.4中,标量是支持的
if image_pred_.shape[0] == 0:
# 如果没有任何物体检测到,继续处理下一张图片
continue
try-except部分是为处理图像中没有任何物体被检测到的情况。如果出现这种情况,使用continue继续下一轮循环,处理下一张图片。
现在,让我们获取在图像中检测到的类。
# 获取图像中检测到的类
# -1:image_pred_的最后一维是类索引,见上面
# unique:独立不重复元素,默认按升序输出
img_classes = torch.unique(image_pred_[:,-1])
由于同一类可以有多个真正的检测,因此我们使用一个unique函数来获取任何给定图像中存在的类。
def unique(tensor):
tensor_np = tensor.cpu().numpy()
unique_np = np.unique(tensor_np)
unique_tensor = torch.from_numpy(unique_np)
tensor_res = tensor.new(unique_tensor.shape)
tensor_res.copy_(unique_tensor)
return tensor_res
然后,我们按类执行 NMS。
for cls in img_classes:
# 按类别执行NMS
一旦我们进入循环,要做的第一件事就是提取特定类的检测(用变量cls表示)。
注意:下面的代码在原始代码文件中缩进了三个块。在这里为展示逐步实现过程,看不出来。
# image_pred_:torch.Size([非零的索引,7])
# cls_mask:筛选出类别是cls的行
cls_mask = image_pred_ * (image_pred_[:, -1] == cls).float().unsqueeze(1)
# class_mask_ind:概率
class_mask_ind = torch.nonzero(cls_mask[:, -2]).squeeze()
image_pred_class = image_pred_[class_mask_ind].view(-1, 7)
# 对detections排序,最高置信度的目标排在最前面
# torch.sort返回排序结果和排序对应原输入的索引,这里只要索引
conf_sort_index = torch.sort(image_pred_class[:, 4], descending=True)[1]
image_pred_class = image_pred_class[conf_sort_index]
# detections的数量
idx = image_pred_class.size(0) # Number of detections
现在,我们执行 NMS。
# NMS
for i in range(idx):
# 在循环中获取所有先验框与当前处理的先验框的IOU
# Get the IOUs of all boxes that come after the one we are looking at
# in the loop
try:
# unsqueeze(0)增加第一维,批量维度,因为后面要和其他所有的进行比较
ious = bbox_iou(image_pred_class[i].unsqueeze(0), image_pred_class[i + 1:])
except ValueError:
break
except IndexError:
break
在这里,我们使用一个函数bbox_iou 。该函数第一个输入是由循环中的变量i索引的边界框的行。第二个输入是多行边界框的张量。函数输出是一个张量,其中包含第一个参数做代表的边界框与第二参数的一组边界框中的每一个的 IoU。
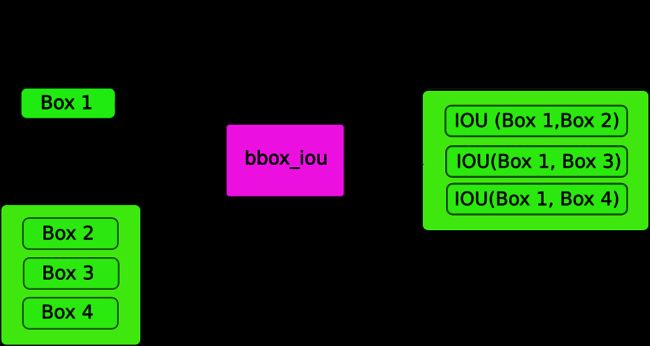
如果我们有两个同一类的边界框,其 IoU 大于阈值,则消除具有较低类置信度的边界框。我们已经排序了边界框,其中具有较高置信度的框位于顶部。
在循环的主体中,下面的代码给出了框的 IoU,索引i的边界框与所以索引大于i的边界框进行比较。
ious = bbox_iou(image_pred_class[i].unsqueeze(0), image_pred_class[i+1:])
每次迭代,如果有任何索引大于i边界框的IoU大于阈值nms_thresh,则该特定框将被消除。
# 将所有detections中IoU > treshhold的清除
iou_mask = (ious < nms_conf).float().unsqueeze(1)
# 小于阈值的保留原值,大于阈值的被置零
image_pred_class[i + 1:] *= iou_mask
# 保留值非零的行
non_zero_ind = torch.nonzero(image_pred_class[:, 4]).squeeze()
image_pred_class = image_pred_class[non_zero_ind].view(-1, 7)
另请注意,我们将计算ious的代码行放在 try-catch 块中计算 。这是因为循环根据idx(image_pred_class中的行)迭代。但是,当我们运行循环时,可能会有很多边界框从image_pred_class中删除。这意味着,如果从image_pred_class中删除了一个值,就不能正确迭代,因为可能会尝试索引一个超出范围的值(IndexError),或者image_pred_class[i+1:]切片可能会返回一个空张量,触发ValueError异常。如果发生这样的情况,我们可以确定NMS不能进一步的删除边界框,退出循环体。``
计算IOU
在bbox_iou函数中完成计算
def bbox_iou(box1, box2):
"""
返回两个bounding boxes的IoU
"""
# 获取bounding boxes的坐标
b1_x1, b1_y1, b1_x2, b1_y2 = box1[:, 0], box1[:, 1], box1[:, 2], box1[:, 3]
b2_x1, b2_y1, b2_x2, b2_y2 = box2[:, 0], box2[:, 1], box2[:, 2], box2[:, 3]
# 获取两个bounding boxes交集构成的矩形的坐标
inter_rect_x1 = torch.max(b1_x1, b2_x1)
inter_rect_y1 = torch.max(b1_y1, b2_y1)
inter_rect_x2 = torch.min(b1_x2, b2_x2)
inter_rect_y2 = torch.min(b1_y2, b2_y2)
# 计算交集面积
# clamp将输入的值控制在两个参数给定的区间
inter_area = torch.clamp(inter_rect_x2 - inter_rect_x1 + 1, min=0) * torch.clamp(inter_rect_y2 - inter_rect_y1 + 1,
min=0)
# 计算并集的面积
b1_area = (b1_x2 - b1_x1 + 1) * (b1_y2 - b1_y1 + 1)
b2_area = (b2_x2 - b2_x1 + 1) * (b2_y2 - b2_y1 + 1)
iou = inter_area / (b1_area + b2_area - inter_area)
return iou
编写预测方法
函数write_results输出形状为 D x 8 的张量。这里的D是所有图像中的真实检测,每个图像由一行表示。每个检测都有 8 个属性,即检测所属批次中图像的索引、4 个角坐标、目标置信度、具有最大置信度的类的概率以及该类的索引。
和之前一样,我们不会初始化输出张量,除非我们有一个检测结果来分配给它。一旦初始化以后,我们将后续检测与它拼接起来。我们使用write标志来指示该张量是否已初始化。在循环最后遍历完所有的类别后,我们将结果检测添加到output张量 。
batch_ind = image_pred_class.new(image_pred_class.size(0), 1).fill_(ind)
# 重复batch_id,重复次数与一张图像中cls类别的检测到的次数相同
seq = batch_ind, image_pred_class
if not write:
output = torch.cat(seq,1)
write = True
else:
out = torch.cat(seq,1)
output = torch.cat((output,out))
在函数结束时,我们检查output是否已初始化。如果尚未初始化,则意味着在该batch的任何图像中都没有检测到目标。在这种情况下,我们返回 0。
try:
return output
except:
return 0
以上就是第四部分的内容。在这部分结尾,我们终于有了一个张量形式的预测,它将每个预测结果保存在一行。现在剩下的唯一事情是创建一个输入管道,从磁盘读取图像,计算预测,在图像上绘制边界框,然后显示/写入这些图像。这就是我们将在第四部分要执行的操作。
第五部分 设计输入和输出pipeline
在之前的部分,我们只是暴力的将输入的图像Resize为Darknet要求的416x416大小,这样会导致图像失真。在YOLOV3的原始实现中,作者采用的是调整图像大小,保持纵横比不变,并填充留出的部分。例如,如果我们要将 1900 x 1280 的图像大小调整为 416 x 415,则调整后的图像将如下所示:

准备输入时的这种差异导致前面我们的实现的性能略低于原始实现。在这一部分中,我们将构建检测器的输入和输出管道。这涉及从磁盘读取图像,进行预测,使用预测在图像上绘制边界框,然后将其保存到磁盘。我们还将介绍如何让探测器在摄像头或视频上实时工作。将介绍一些命令行标志,以允许对网络的各种超参数进行一些实验。
注意,后续内容需要安装OpenCV
创建一个文件detector.py,在其顶部添加必需的导入。
from __future__ import division
import time
import torch
import torch.nn as nn
from torch.autograd import Variable
import numpy as np
import cv2
from utils import *
import argparse
import os
import os.path as osp
from darknet import Darknet
import pickle as pkl
import pandas as pd
import random
创建命令行参数
由于detector.py是运行检测器执行的文件,因此最好有可以传递给它的命令行参数。可以使用python的ArgParse模块来做到这一点。关于ArgParse是使用不是本文重点,可以参考博客。
def arg_parse():
"""
解析传入检测器的命令行参数
"""
parser = argparse.ArgumentParser(description='YOLO v3 Detection Module')
# type是要传入的参数的数据类型 help是该参数的提示信息
# 输入的检测图片
parser.add_argument("--images", dest='images', help="Image / Directory containing images to perform detection upon",
default="imgs", type=str)
# 检测结果保存的位置
parser.add_argument("--det", dest='det', help="Image / Directory to store detections to",
default="det", type=str)
# batch_size
parser.add_argument("--bs", dest="bs", help="Batch size", default=1)
# 目标置信度
parser.add_argument("--confidence", dest="confidence", help="Object Confidence to filter predictions", default=0.5)
# nms阈值
parser.add_argument("--nms_thresh", dest="nms_thresh", help="NMS Threshhold", default=0.4)
# 网络结构配置文件路径
parser.add_argument("--cfg", dest='cfgfile', help="Config file",
default="config/yolov3.cfg", type=str)
# 预训练权重参数路径
parser.add_argument("--weights", dest='weightsfile', help="weightsfile",
default="config/yolov3.weights", type=str)
# 输入图像的分辨率
parser.add_argument("--reso", dest='reso', help= "Input resolution of the network. Increase to increase accuracy. Decrease to increase speed",
default="416", type=str)
return parser.parse_args()
args = arg_parse()
images = args.images
batch_size = int(args.bs)
confidence = float(args.confidence)
nms_thesh = float(args.nms_thresh)
start = 0
CUDA = torch.cuda.is_available()
其中,重要的标志是images(用于指定输入图像或图像目录),det(保存检测的目录),reso(输入图像的分辨率,可用于速度 - 准确性权衡),cfg(网络结构配置文件)和weightfile(预训练权重参数文件)。
加载网络
从此处下载文件coco.names(我会提供),该文件包含 COCO 数据集中对象的名称。在项目目录中创建一个data文件夹。
num_classes = 80
classes = load_classes("data/coco.names")
load_classes是一个函数,它返回一个字典,该字典将每个类的索引映射到其名称的字符串。
在util.py中补充该函数
# 加载coco.names或voc.names
def load_classes(namesfile):
fp = open(namesfile, "r")
names = fp.read().split("\n")[:-1]
return names
初始化网络和权重。
# 初始化网络和权重参数
print("Loading network.....")
model = Darknet(args.cfgfile)
model.load_weights(args.weightsfile)
print("Network successfully loaded")
model.net_info["height"] = args.reso
inp_dim = int(model.net_info["height"])
# 输入分辨率必须能被32整除
assert inp_dim % 32 == 0
# 输入分辨率必须大于32
assert inp_dim > 32
#如果GPU可用,将模型放在GPU上
if CUDA:
model.cuda()
# 将模型模式设置为evaluation mode,不进行梯度更新
model.eval()
读取输入图像
从磁盘读取图像,或从目录中读取图像。图像的路径存储在名为imlist的列表中。
# 用于记录运行时间
read_dir = time.time()
# 检测阶段
try:
imlist = [osp.join(osp.realpath('.'), images, img) for img in os.listdir(images)]
except NotADirectoryError:
imlist = []
imlist.append(osp.join(osp.realpath('.'), images))
except FileNotFoundError:
print ("No file or directory with the name {}".format(images))
exit()
read_dir是用于测量时间的checkpoint。(我们将设置几个)
如果用于保存检测结果的目录(由det标志定义)不存在,则创建它。
if not os.path.exists(args.det):
os.makedirs(args.det)
使用OpenCV来加载图像
load_batch = time.time()
loaded_ims = [cv2.imread(x) for x in imlist]
load_batch又是一个checkpoint。
OpenCV将图像加载为numpy数组,颜色通道的顺序是BGR。PyTorch要求的图像输入格式是(batchx通道x高度x宽度),通道顺序为RGB。因此,我们在 util.py中编写函数prep_image将numpy数组转换为PyTorch的输入格式。
在编写此函数之前,我们必须编写一个函数letterbox_image来调整图像大小,保持宽高比一致,并用颜色(128,128,128)填充左侧区域。
def letterbox_image(img, inp_dim):
'''使用填充,在保持图像宽高比的前提下对图像进行缩放'''
img_w, img_h = img.shape[1], img.shape[0]
w, h = inp_dim
new_w = int(img_w * min(w / img_w, h / img_h))
new_h = int(img_h * min(w / img_w, h / img_h))
resized_image = cv2.resize(img, (new_w, new_h), interpolation=cv2.INTER_CUBIC)
canvas = np.full((inp_dim[1], inp_dim[0], 3), 128)
canvas[(h - new_h) // 2:(h - new_h) // 2 + new_h, (w - new_w) // 2:(w - new_w) // 2 + new_w, :] = resized_image
return canvas
现在,我们编写一个函数,该函数获取OpenCV图像并将其转换为我们网络的输入。
def prep_image(img, inp_dim):
"""
将openCV读取的BGR numpy图像转换为
神经网络需要的RGB Tensor.
"""
img = cv2.resize(img, (inp_dim, inp_dim))
img = img[:, :, ::-1].transpose((2, 0, 1)).copy()
# 值除于255,将各通道的值缩放为0~1之间的浮点数
img = torch.from_numpy(img).float().div(255.0).unsqueeze(0)
# img是pytorch tensor
return img
除了转换后的图像外,我们还维护原始图像的列表im_dim_list,以及包含原始图像尺寸的列表。
# 包含原始图像尺寸的列表
im_dim_list = [(x.shape[1], x.shape[0]) for x in loaded_ims]
im_dim_list = torch.FloatTensor(im_dim_list).repeat(1,2)
if CUDA:
im_dim_list = im_dim_list.cuda()
创建batch
# 创建Batch
leftover = 0
if len(im_dim_list) % batch_size:
leftover = 1
if batch_size != 1:
num_batches = len(imlist) // batch_size + leftover
im_batches = [torch.cat((im_batches[i * batch_size: min((i + 1) * batch_size,
len(im_batches))])) for i in range(num_batches)]
The Detection Loop
我们迭代batch,生成所有图像上的预测结果张量,并连接预测结果张量(形状,D x 8,write_results函数的输出)
对于每个batch,我们将检测所需的时间度量,该时间记录了从输入到write_results函数输出的时间。在 write_prediction函数返回的输出中,其中一个属性是batch中图像的索引。我们将该属性进行转换,让它表示图像在imlist列表中的索引,该列表包含了所有图像的地址。
之后,我们打印每次检测所需的时间以及每张图像中检测到的目标。
如果write_results函数的输出为 int(0),表示没有检测到目标,则我们用于跳过剩下的循环。
write = 0
# 记录开始检测的时间
start_det_loop = time.time()
for i, batch in enumerate(im_batches):
# 加载图像
start = time.time()
if CUDA:
batch = batch.cuda()
prediction = model(batch, CUDA)
prediction = write_results(prediction, confidence, num_classes, nms_conf = nms_thesh)
end = time.time()
if type(prediction) == int:
for im_num, image in enumerate(imlist[i*batch_size: min((i + 1)*batch_size, len(imlist))]):
im_id = i*batch_size + im_num
print("{0:20s} predicted in {1:6.3f} seconds".format(image.split("/")[-1], (end - start)/batch_size))
print("{0:20s} {1:s}".format("Objects Detected:", ""))
print("----------------------------------------------------------")
continue
# 将在batch中的索引转换为在imlist中的索引
prediction[:,0] += i*batch_size
# 如果没有初始化output,即尚未检测到目标
if not write:
output = prediction
write = 1
else:
output = torch.cat((output,prediction))
for im_num, image in enumerate(imlist[i*batch_size: min((i + 1)*batch_size, len(imlist))]):
im_id = i*batch_size + im_num
objs = [classes[int(x[-1])] for x in output if int(x[0]) == im_id]
print("{0:20s} predicted in {1:6.3f} seconds".format(image.split("/")[-1], (end - start)/batch_size))
print("{0:20s} {1:s}".format("Objects Detected:", " ".join(objs)))
print("----------------------------------------------------------")
if CUDA:
# 在pytorch里面,程序的执行都是异步的,
# 等待当前设备上所有流中的所有核心完成。
torch.cuda.synchronize()
torch.cuda.synchronize确保 CUDA 内核与 CPU 同步。否则,CUDA 内核会在GPU任务进入队列后立刻将控制权返回CPU,而这时可能GPU上的任务还未完成(异步调用)。当GPU 任务未完成而end = time.time()代码已经被执行时,可能会导致打印出来的运行时间是错误的。
现在,我们在张量输出中包含了所有图像的检测结果。让我们在图像上绘制边界框。
在图像上绘制边界框
我们使用 try-catch 块来检查是否进行了单次检测。如果不是这种情况,则退出程序。
try:
output
except NameError:
print ("No detections were made")
exit()
在绘制边界框之前,输出张量中包含的预测符合的是网络的输入大小,而不是图像的原始大小。因此,在我们绘制边界框之前,需要将每个边界框的角属性转换为图像的原始尺寸。
在绘制边界框之前,输出张量中包含的预测是对填充图像的预测,而不是原始图像。所以仅仅将它们重新缩放到输入图像的尺寸在这里是行不通的。我们需要将要测量的bbox的坐标与包含原始图像的填充图像上的区域边界进行转换。
# 将要测量的bbox的坐标与包含原始图像的填充图像上的区域边界进行转换。
im_dim_list = torch.index_select(im_dim_list, 0, output[:,0].long())
scaling_factor = torch.min(inp_dim/im_dim_list,1)[0].view(-1,1)
output[:,[1,3]] -= (inp_dim - scaling_factor*im_dim_list[:,0].view(-1,1))/2
output[:,[2,4]] -= (inp_dim - scaling_factor*im_dim_list[:,1].view(-1,1))/2
现在,我们的坐标符合填充区域上图像的尺寸。但是,在letterbox_image函数中,我们通过比例因子调整了图像的两个尺寸的大小(两个维度都用一个公共因子相除以保持宽高比)。现在,我们撤消此缩放,以获取原始图像上边界框的坐标。
output[:,1:5] /= scaling_factor
现在,让我们将任何可能在图像外部具有边界的边界框剪辑到图像的边缘。
# 将任何可能在图像外部具有边界的边界框剪辑到图像的边缘
for i in range(output.shape[0]):
output[i, [1,3]] = torch.clamp(output[i, [1,3]], 0.0, im_dim_list[i,0])
output[i, [2,4]] = torch.clamp(output[i, [2,4]], 0.0, im_dim_list[i,1])
如果图像中有太多的边界框,那么将它们全部绘制成一种颜色会比较杂乱,区分区较低。我们制作了一个pickle文件,其中包含许多颜色可以随机选择。
# 为不同的类别边框赋予不同的随机颜色
class_load = time.time()
colors = pkl.load(open("pallete", "rb"))
现在让我们编写一个函数来绘制边界框。
def write(x, results):
c1 = tuple(x[1:3].int())
c2 = tuple(x[3:5].int())
img = results[int(x[0])]
cls = int(x[-1])
color = random.choice(colors)
label = "{0}".format(classes[cls])
cv2.rectangle(img, c1, c2,color, 1)
t_size = cv2.getTextSize(label, cv2.FONT_HERSHEY_PLAIN, 1 , 1)[0]
c2 = c1[0] + t_size[0] + 3, c1[1] + t_size[1] + 4
cv2.rectangle(img, c1, c2,color, -1)
cv2.putText(img, label, (c1[0], c1[1] + t_size[1] + 4), cv2.FONT_HERSHEY_PLAIN, 1, [225,255,255], 1);
return img
上面的函数绘制一个矩形,其颜色为从colors中随机选择。它还在边界框的左上角创建一个填充矩形,并写入检测到的目标的类。cv2.rectangle中的-1 参数用于创建填充矩形。
我们在本地定义函数,以便它可以访问列表。我们也可以将colors作为一个参数,但这样是允许我们在每个图像只使用一种颜色,这违背了我们的目的。``
定义此函数后,现在让我们在图像上绘制边界框。
list(map(lambda x: write(x, loaded_ims), output))
上面的代码段修改了就地loaded_ims内的图像。
每个图像都是通过在图像名称前面添加前缀“det_”来保存的。我们创建一个地址列表,将检测图像保存到该地址。
# 将检测图像名加上前缀/det_ 保存
det_names = pd.Series(imlist).apply(lambda x: "{}/det_{}".format(args.det, x.split("/")[-1]))
最后,将带有检测结果的图像写det_names中的地址。
# 检测图像写入地址
list(map(cv2.imwrite, det_names, loaded_ims))
end = time.time()
打印Time Summary
在检测器结束时,我们将打印一个摘要,其中包含执行代码的哪一部分需要多长时间。这样可以用来比较不同的超参数如何影响检测器的效率,这很有用。在命令行上执行detection.py脚本时,可以设置超参数,例如batchSize,目标置信度和NMS阈值(分别用bs,confidence,nms_thresh标志一起传递)。
# 打印Time Summary
print("SUMMARY")
print("----------------------------------------------------------")
print("{:25s}: {}".format("Task", "Time Taken (in seconds)"))
print()
print("{:25s}: {:2.3f}".format("Reading addresses", load_batch - read_dir))
print("{:25s}: {:2.3f}".format("Loading batch", start_det_loop - load_batch))
print("{:25s}: {:2.3f}".format("Detection (" + str(len(imlist)) + " images)", output_recast - start_det_loop))
print("{:25s}: {:2.3f}".format("Output Processing", class_load - output_recast))
print("{:25s}: {:2.3f}".format("Drawing Boxes", end - draw))
print("{:25s}: {:2.3f}".format("Average time_per_img", (end - load_batch)/len(imlist)))
print("----------------------------------------------------------")
测试检测器
可以在终端运行命令:
python detect.py --images dog-cycle-car.png --det det
下面是在CPU上运行的结果
Loading network.....
Network successfully loaded
dog-cycle-car.png predicted in 2.456 seconds
Objects Detected: bicycle truck dog
----------------------------------------------------------
SUMMARY
----------------------------------------------------------
Task : Time Taken (in seconds)
Reading addresses : 0.002
Loading batch : 0.120
Detection (1 images) : 2.457
Output Processing : 0.002
Drawing Boxes : 0.076
Average time_per_img : 2.657
----------------------------------------------------------
下面是在2080TI GPU 上运行的结果

在视频或摄像头上运行检测器
代码与之前的基本保持一致,除了一点不同,就是我们不是在batch上去遍历图像,而是对视频中的每一帧进行遍历。
首先,在OpenCV中打开视频/摄像机源。
videofile = "video.avi" #or path to the video file.
cap = cv2.VideoCapture(videofile)
#cap = cv2.VideoCapture(0) for webcam
assert cap.isOpened(), 'Cannot capture source'
frames = 0
我们以类似于我们迭代图像的方式迭代帧。
许多地方都简化了代码,因为我们不再需要处理batch,而是一次只处理一个图像。这是因为一次只能有一帧。这包括使用元组代替im_dim_list张量和write函数中微小更改。
每次迭代,我们都会跟踪在名为frames的变量中捕获的帧数。然后,我们将此数字除以视频FPS以打印第一帧以来经过的时间。
为了使用cv2.imwrite将检测图像写入磁盘,我们用cv2.imshow显示带有绘制边界框的帧。如果用户按下Q按钮,则会导致代码中断循环,并且视频结束。
frames = 0
start = time.time()
while cap.isOpened():
ret, frame = cap.read()
if ret:
img = prep_image(frame, inp_dim)
# cv2.imshow("a", frame)
im_dim = frame.shape[1], frame.shape[0]
im_dim = torch.FloatTensor(im_dim).repeat(1,2)
if CUDA:
im_dim = im_dim.cuda()
img = img.cuda()
output = model(Variable(img, volatile = True), CUDA)
output = write_results(output, confidence, num_classes, nms_conf = nms_thesh)
if type(output) == int:
frames += 1
print("FPS of the video is {:5.4f}".format( frames / (time.time() - start)))
cv2.imshow("frame", frame)
key = cv2.waitKey(1)
if key & 0xFF == ord('q'):
break
continue
output[:,1:5] = torch.clamp(output[:,1:5], 0.0, float(inp_dim))
im_dim = im_dim.repeat(output.size(0), 1)/inp_dim
output[:,1:5] *= im_dim
classes = load_classes('data/coco.names')
colors = pkl.load(open("pallete", "rb"))
list(map(lambda x: write(x, frame), output))
cv2.imshow("frame", frame)
key = cv2.waitKey(1)
if key & 0xFF == ord('q'):
break
frames += 1
print(time.time() - start)
print("FPS of the video is {:5.2f}".format( frames / (time.time() - start)))
else:
break
结论
在本讲义中,我们从头开始实现了YOLO3。我仍然认为编写高效的代码是深度学习从业者可以拥有的最被低估的技能之一。无论你的想法多么具有革命性,除非你能编码测试,否则它都没有用。为此,您需要具备强大的编码技能。
另外,了解深度学习中任何主题的最佳方法是实现代码。它迫使你了解一篇论文细微而基本的微妙之处,当你阅读一篇论文时,你可能会错过这些微妙之处。我希望你能跟随本讲义,一步一步的体验这个过程。
参考文献
How to implement a YOLO (v3) object detector from scratch in PyTorch