IJCAI'22 | 感知图像内容的创意布局自动生成方法
本文分享阿里妈妈创意&视频平台团队在图文广告创意方向上关于元素自动布局的探索与实践,在多个核心广告场景中应用并取得线上收益,具体应用可参考往期文章 《实现"模板自由"?阿里妈妈全自动无模板图文创意生成》。基于该项工作总结的论文已被 IJCAI 2022 AI & Arts Track录用,欢迎阅读交流~
论文:Composition-aware Graphic Layout GAN for Visual-textual Presentation Designs
下载:https://arxiv.org/abs/2205.00303
▐ 背景
在广告投放过程中,需根据不同的商品制作创意以吸引用户。从历史实验上看,点击效果与创意视觉美观度呈正相关关系。目前,业界广泛应用的自动化创意制作方法,都是基于固定模板(布局)的元素替换或属性更改,即如下图所示,logo、文字、衬底、装饰元素等图形元素的位置不随商品图像变化而更改,常出现遮挡图像主体、视觉融合度不佳等问题,且千篇一律,容易产生视觉疲劳。在学术研究上,有一些自动生成布局的方法,但这些方法主要关注于布局的图形元素内部间的关系建模,未充分利用图像内容信息,无法解决上述问题。
因此,为解决这一业务痛点,我们提出了一种感知图像内容的创意布局自动生成方法,并基于该方法,可为商品图定制化地生成合理布局(如下图所示),保证商品主体的有效展示,提升创意美观度。
 不同创意示意图
不同创意示意图
▐ 相关工作
在学术研究上,自动布局生成(Automatic Layout Generation)是一个被广泛关注的经典问题。早期的方法主要依赖于模板或者启发式方法,往往需要一定的专业知识,且经常受限于手工规则而无法实现灵活、多样化的布局。
随着深度学习的发展,LayoutGAN [1]、LayoutVAE [2]、VTN [3] 可通过数据驱动的方式自动生成布局,同时涌现了一些条件布局生成方法(如指定元素数量或类别、元素相对位置关系等)。但以上这些方法都仅仅专注于学习图形元素间的内部关系,没有考虑图像内容对布局的影响。
ContentGAN [4] 是第一个使用图像的视觉语义信息来生成布局的方法,它可以产出高质量的杂志页面布局。但在对图像内容的处理上,它仅使用了由预训练网络提取出的一维向量,缺乏空间信息和细节特征,在广告创意布局上仍无法避免主体被遮挡等问题。由此,我们提出了一种能更好地感知图像具体内容与位置的布局生成方法,能产出与图像适配度更强的高质量创意布局。
▐ 方法设计
首先,布局可定义为不定长的图形元素集合 ,每个元素包括其类别和位置信息。如上图所示,我们将元素类别设定为logo、文字、衬底、装饰元素这四类,位置信息则由每个元素的中心坐标和宽高表示。
在根据图像内容生成创意布局的过程中,需解决两个核心问题:1)图像和人工创意布局的成对数据获取;2)如何在生成布局过程中充分利用图像内容信息。
对于问题1),最直接的方式是由设计师根据无文字等元素的干净商品图像设计布局,得到相应数据,但这样成本很高,且数据易因设计师少而陷入固有模式。因此我们创新地提出了一个域对齐(Domain Alignment Module, DAM)模块,只需获取广告主创意图,并类似于图像检测任务标出其上的元素类别和位置,测试时可直接使用干净的商品图像进行预测。基于此,我们也制作了首个针对广告创意布局的大型数据集,包含约6w张人工标注好布局信息的创意图像(训练集),和1k张干净的商品图像(测试集)。
对于问题2),我们则将Multi-scale CNN和Transformer相结合,提出了一个图像内容感知的布局生成GAN网络。该网络充分利用两者的优点,不仅可以有效学习地学习元素间的对齐、交叠等关系,而且还能建模元素与图像内容位置、背景颜色纹理分布间的关系。此外,该网络还支持添加用户约束,可对用户布局进行合理补全,满足实际应用中部分场景有固定设计规则的需求。
整体流程如下图所示,具体的步骤和模块如下:
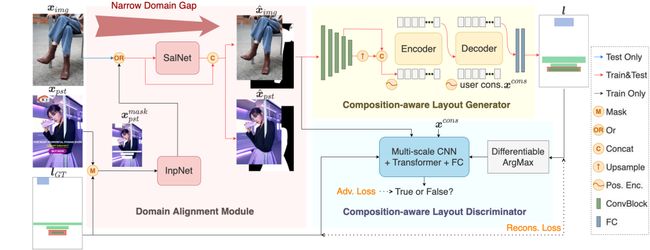 整体流程和模型结构图
整体流程和模型结构图
1)域对齐模块
该模块由两个预先训练好的子网络构成:inpainting网络(LAMA[5])InpNet、显著性检测网络[6] SalNet。训练时,对于每张创意图,由标注得到的ps元素布局信息制作mask ,InpNet根据该mask和创意图生成修复后图像,再通过SalNet得到其主体区域,将修复后图像与显著性检测结果concat后作为该模块的输出。测试时,对于干净商品图,则直接将其与对应显著性结果concat得到输出。显然,相比于直接使用创意图和干净商品图,经过inpainting和显著性处理后的和间域差异更小。
2)基于内容感知的布局生成
为了更好地建模图像和布局元素之间的关系,布局生成器由三部分组成:提取图像特征的Multi-scale CNN 主干网络、隐式学习布局生成规则的Transformer,以及用于转换输出为分类和位置回归的全连接层。
图像数据从域对齐模块输出后,被送入 CNN中提取图像特征。由于影响布局的图像内容不仅意味着主体位置之类的高级语义,还包括区域复杂度等低级特征,因此我们在最后两个卷积块上加入了多尺度策略。多尺度特征通过一个线性层转化为Transformer 编码器的输入,并通过编码器进一步细化图像特征。解码器则采用初始布局(噪声或约束)作为输入,并利用交叉注意力机制来学习图像与布局之间的关系。此外,图形元素之间的内部关系则是通过解码器中的自注意力机制建立的。
最后,将每个元素的解码器特征送入全连接层中,分别预测对应的类和坐标。将各元素结果综合,则得到预测的一个完整布局。
3) 损失函数与模型优化
总损失函数分为重建与对抗损失两部分。对于重建损失,则是和DETR [7]一样,用预测布局与真实布局间通过交叉熵等计算分类、回归损失。对于对抗损失,则是构建了一个与生成器相似的判别器。且在应用判别器时,为了消除真实布局和预测布局之间的数值差异,对预测布局应用可微分的argmax,并将预测的非对象的框坐标重置为0。
▐ 指标设计与实验效果
为了更全面地评估方法效果,除了使用布局质量评估常用的重叠、对齐等与图像内容无关的指标外,我们还使用了人工测评指标,并根据设计原则创新地提出了三项和图像内容相关的布局评价指标。由下表可见(三大类指标从左至右分别为:人工测评、与图像相关的评价指标、与图像内容无关关注元素关系的指标),与SOTA方法相比,我们的方法在各项指标上均表现良好,特别是人工测评、内容相关的指标上远超其他方法。
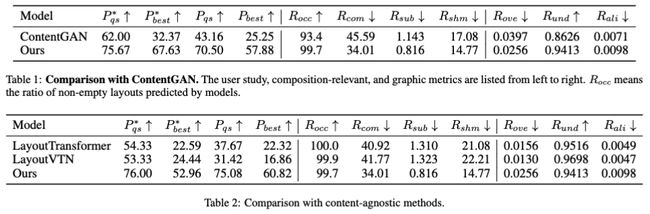 与SOTA方法的定量对比
与SOTA方法的定量对比
与SOTA方法在不同输入图像上的可视化对比效果如下:
与SOTA方法的定性对比为验证创意布局和图像内容间的相关性,我们还对图像进行了随机裁剪/缩放,结果如下图所示,网络能相应地产生不同的布局。
 图像裁剪/缩放后的创意布局变化
图像裁剪/缩放后的创意布局变化
此外,当使用随机选择的部分布局进行训练时,从下图可见,模型可根据输入的布局情况进行合理完整布局输出,方便添加用户输入约束。
 用户约束下的布局生成(用户约束布局如第一行所示)
用户约束下的布局生成(用户约束布局如第一行所示)
▐ 关于我们
我们是阿里妈妈创意&视频平台,专注于图片、视频、文案等各种形式创意的智能制作与投放,以及短视频广告多渠道投放,产品覆盖阿里妈妈内外多条业务线,欢迎各业务方关注与业务合作。同时,真诚欢迎具备CV、NLP和推荐系统相关背景同学加入!
投递简历邮箱:[email protected]
Reference
[1] Jianan Li, Jimei Yang, Aaron Hertzmann, Jianming Zhang, and Tingfa Xu. Layoutgan: Generating graphic layouts with wireframe discriminators. In 7th International Conference on Learning Representations, ICLR 2019, New Orleans, LA, USA, May 6-9, 2019. OpenReview.net, 2019.901.06767, 2019.
[2] Akash Abdu Jyothi, Thibaut Durand, Jiawei He, Leonid Sigal, and Greg Mori. Layoutvae: Stochastic scene layout generation from a label set. pages 9894–9903. ICCV, 2019.
[3] Diego Mart ́ın Arroyo, Janis Postels, and Federico Tombari. Variational transformer networks for layout generation. In CVPR, pages 13642–13652, 2021.
[4] Xinru Zheng, Xiaotian Qiao, Ying Cao, and Rynson W. H. Lau. Content-aware generative modeling of graphic design layouts. ACM Trans. Graph., 38(4):133:1–133:15, 2019.
[5] Roman Suvorov, Elizaveta Logacheva, Anton Mashikhin, Anastasia Remizova, Arsenii Ashukha, Aleksei Silvestrov, NaejinKong, Harshith Goka, Kiwoong Park, and Victor Lempitsky. Resolution-robust large mask inpainting with fourier convolutions. In IEEE/CVF Winter Conference on Applications of Computer Vision, WACV 2022, Waikoloa, HI, USA, January 3-8, 2022, pages 3172–3182. IEEE, 2022.
[6] Bo Wang, Quan Chen, Min Zhou, Zhiqiang Zhang, Xiaogang Jin, and Kun Gai. Progressive feature polishing network for salient object detection. AAAI2020: 12128-12135.
[7] Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, and Sergey Zagoruyko. End-to-end object detection with transformers. In ECCV, pages 213–229, 2020.
END

也许你还想看
丨实现"模板自由"?阿里妈妈全自动无模板图文创意生成
丨ACM MM'22 & ECCV'22 | 6篇论文带你了解广告创意的“黑科技”
丨CVPR'22 | 基于像素差异学习的视频高光检测算法及在视频广告中的应用
丨CVPR'22 | 基于可形变关键点模型的图像驱动技术
丨告别拼接模板 —— 阿里妈妈动态描述广告创意
丨如何快速选对创意 —— 阿里妈妈广告创意优选


喜欢要“分享”,好看要“点赞”哦ღ~
↓欢迎留言参与讨论↓
丨ACM MM'22 & ECCV'22 | 6篇论文带你了解广告创意的“黑科技”