广告深度学习计算:多媒体AI推理服务加速利器high_service
本文作者:雨行、列宁、阿洛、腾冥、枭骑、无蹄、逍城、少奇、持信、云芑
本文是上一篇内容《广告深度学习计算:阿里妈妈智能创意服务优化》工作的进一步延伸,欢迎阅读交流。
概述
随着视频、文案、图文等多媒体模型在阿里妈妈智能创意、内容风控等业务场景的广泛落地,在提升业务效果的同时,也为在线部署带来了诸多新的挑战。本文聚焦于多媒体AI服务场景下,提升GPU利用率以及避免GPU资源浪费这一核心问题,分析了用Python上线多媒体AI推理服务GPU利用率低的原因,以及在线流量波动造成的资源分配困难,并给出了我们的解决方案 high_service。
一、多媒体AI服务特点及挑战
1. 多媒体业务场景简介
多媒体AI服务涉及到了智能视频制作、图文创意、智能文案、违规内容检测等众多场景,如:
微视频,通过多模态检索技术从长视频中裁剪出3-10秒最吸引用户眼球的主要内容,或者使用剧本自动生成视频,投放到搜索、推荐等场景,留住用户并促成点击。
智能抠图,从商品主图中选取出主体商品或者模特,作为其他智能创意服务的素材。

智能文案,根据不同载体(图片、视频、信息流卡片等)以及不同媒体的风格,为商品生成最恰当的文案。下表展示了我们为淘宝和头条自动生成的不同风格的文案。

违规内容检测,对违规词以及违规图片进行筛查过滤,规避风险。
2. 多媒体AI服务部署挑战
2.1 “成也Python,败也Python”
对于Python的态度,可以说是“又爱又恨”。在模型训练方面,Python因其动态语言特性,以及丰富的数据处理库(如Numpy/Pandas等),成为算法同学的首选。尤其是随着越来越多的顶会文章采用PyTorch,使得Python+PyTorch组合几乎成为多媒体模型训练的标配。
但是作为线上推理服务,Python由于全局解释器锁(下文简称GIL锁),导致单进程服务模式无法充分利用多核CPU的处理能力,GPU Kernel Launch线程频繁被其它线程中断,使得Cuda Cores得不到足够的任务而空闲,GPU利用率相应的也就很低。
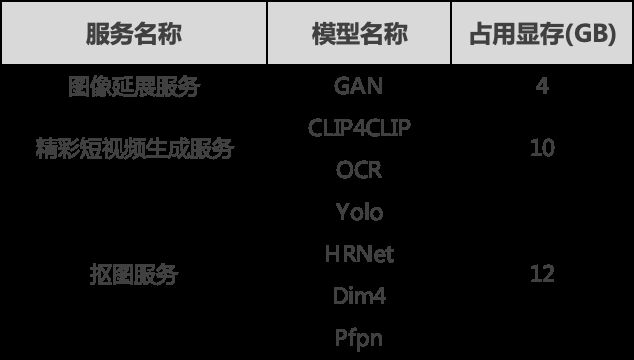
既然单进程的方式不行,那么Python多进程可以吗?答案是部分可以,因为多进程部署需要为每个进程加载一份GPU模型,而这无疑会受到GPU显存的约束。我们知道,随着多媒体模型在图片分类、目标检测、图像分割等领域的表现越来越亮眼,其代价便是模型的复杂度与模型参数的几何级增加。除了模型参数占显存外,中间运算结果以及Cuda Context内容(约占用几百MB显存)均需要占用显存资源。此外,一个服务会往需要多个模型共同协作,这使得每个进程加载一份模型的方式不可行。下表显示了我们部分多媒体服务,在单进程模式下对于显存的需求。
但是多媒体场景下,Python转C++困难很大。原因有几项:
视频处理逻辑处理复杂。视频数据需要经过抽帧采样、尺寸变化、通道转换、归一化等复杂的预处理,模型输出的图片还要合成视频、FFmpeg转码等后处理。
C++图片处理库不如Python完善,很多Numpy和Python的函数需要手写C++实现,效率低下,开发周期长。
C++与Python结果一致性很难保证,调试困难。
正是因为上述Python转C++的困难,使得“Python训练+Python线上推理”的模式,成为特别迫切的需求。这种模式不仅方便算法同学自助上线,更加快了算法迭代更新的速度,保证了最新的研究成果能够及时落地。
2.2 流量不均匀
除了Python带来的问题外,流量不均匀也为多媒体AI落地带来了诸多挑战,包括但不限于
流量潮汐现象严重,波动很大,无法按峰值流量准备机器
在线服务与离线训练任务的一个很大不同,就是流量波动非常大。离线训练由于是算法同学主动发起的,因此通过合理的任务调度,可以保证GPU时刻都有任务运行。但是对于在线服务来说,其流量来源于用户的操作。因此流量波动很大,主要体现在两个方面:一是白天工作时间的流量远远大于夜间;二是大促前后的流量明显高于日常。
对于大促增加的流量,可以通过临时增加机器来解决,但是对于日常流量的波动,如果每个服务都按照峰值流量准备机器,资源是不够的,但是不按峰值流量准备,则会造成高峰时段的请求超时,影响用户体验和广告投放效果。
部分服务流量低,资源浪费严重
在流量分配方面,“二八定律”也非常明显,80%的流量集中的头部20%的服务上,其他服务的流量则很低,尤其是由于历史遗留和服务特点等原因,约40%的服务流量极其低。面对这样情况,即使每个服务使用资源缩到最低,也会占用几十块GPU。而且随着业务的发展,这种服务会越来越多,如果处理这些低流量的服务,成为一个难题。
二、high_service如何解决上述问题
1. high_service介绍
high_service是阿里妈妈AI-Serving异构计算团队,为多媒体在线预估服务量身打造的高性能推理框架。其核心理念是,在尽量少侵入业务代码的前提下,将Python 多媒体AI推理服务的性能做到极致。high_service从集群服务调度、服务架构优化、模型推理加速等多个维度,构建了一整套解决方案,解决了前文分析的问题,提高了服务的吞吐(QPS)和GPU利用率。
high_service简单易用,目前支持PyTorch、TensorFlow等深度学习框架,并通过ONNX、Torch-TensorRT等工具自动将模型转换为TensorRT格式进行加速,较原始模型数倍的性能提升。
high_service自2021年在阿里妈妈智能创意业务上线以来,已经覆盖了妈妈智能创意90%以上的服务,满足了高速发展的业务对于GPU资源的需求。2022年又拓展到了阿里妈妈内容风控业务,支持了人脸识别、OCR等多个场景。
2. 主要功能简介
high_service的系统架构如下图所示,其中浅绿色虚线框内为high_service的架构。
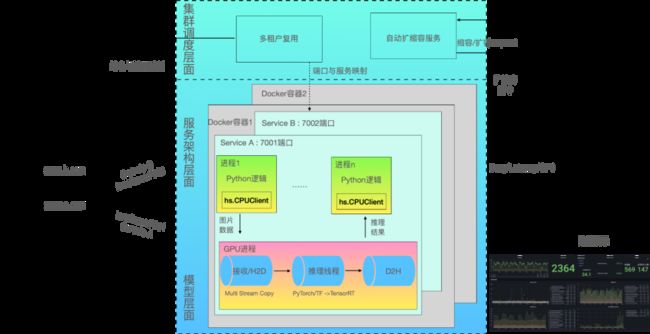
从上图可以看出,high_service通过Nginx,将业务处理逻辑封装成HTTP接口,对外提供服务。使用者仅需编写接收request后的处理逻辑,而无需关心多进程部署、流量监控报警、自动扩缩容等复杂的处理。从单个服务的内部来看,处理流程类似于“生产者-消费者”模式,多个CPU进程并行接收图片/视频数据,经过预处理后,将数据发送给GPU进程。GPU服务通常只有一个进程,接收CPU进程发送的数据,执行模型推理,再将推理输出返回给CPU进程。
high_service从功能层面主要分为三部分:
1) 集群服务层面
基于业务优先级的自动扩缩容:解决流量波动问题。通过获取当前服务的“Busy状态”,动态调整服务的容器数,在保证请求不超时的前提下,最大限度的提高GPU利用率。
多租户复用:解决服务流量低的问题。在满足CPU内存和GPU显存约束条件下,将多个低流量的服务部署到同一个容器中,通过多个服务共用GPU的方式节省资源。
2) 服务架构层面
CPU/GPU任务分离的多进程架构:解决Python GIL锁造成的单进程GPU利用率低的问题。通过将GPU任务抽离成单个进程的方式,降低CPU任务对Kernel Launch线程的干扰,从而提高GPU利用率。
3) 模型优化层面
TensorRT加速:解决PyTorch动态图、未充分Kernel Fusion带来的执行效率低问题。借助TensorRT极致的推理优化,提高模型的执行效率。
模型优化:通过优化冗余的计算逻辑,简化模型结构,提升模型的执行效率。
接下来的部分将对上述功能进行详细介绍。
3. 功能详细介绍
3.1 集群服务调度
集群层面的功能,着眼于全局角度进行资源的调配,以达到整体资源利用率最高的目的。主要包含两个方面的工作:基于业务优先级的自动扩缩容( Priority-Based Service Auto Scaling )和多租户复用( Multi-Tenant )。
3.1.1 基于业务优先级的自动扩缩容
很多管控系统都提供自动扩缩容功能,比如根据CPU利用率自动扩缩容,通过简单配置即可开启,但是却无法满足我们的使用需求,主要体现在两个方面:1)单靠CPU使用率无法判断当前服务是否已达到极限,如运行于GPU上的计算密集型的模型,即使大量请求已经超时,CPU的使用率仍然很低。因此除了CPU使用率外,还需要根据当前容器的QPS(Query Per Second)和Latency等其他指标;2)单条流量的价值不相同,当高价值服务需要扩容但资源不足时,就需要低价值的服务释放资源,以保证高价值服务不受影响,这些业务规则信息显然平台是无法获取的。
针对上述实际需求,high_servcie 提供了基于业务优先级的自动扩缩容解决方案。该方案追求全局收益的最大化,寻找最优的资源配置。第一版调控的依据比较简单,由用户设置每个服务的优先级和QPS,通过调控服务的数量来保证单机QPS不超过上限。在资源充足的情况下,按需分配各个服务的资源。资源不足的时候,自动释放优先级低的服务资源以保障高优的业务。
通过这种方式,既能保证流量高峰来的时候,服务能够及时扩容资源,又能保证流量低的时候释放资源,提高了GPU的利用率,节约了资源,很好的应对了流量波动的场景。对于流量波动比较大的某个线上服务,动态扩缩容的效果如下图所示。
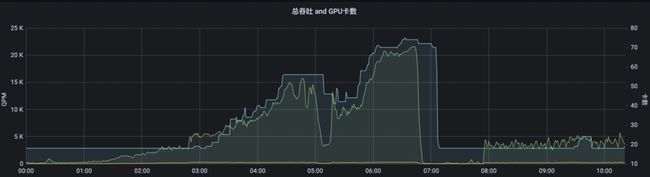
从上图可以看出,该服务使用GPU卡数(容器数)随着流量变化而增减的效果图。可以很明显的看到,从3:00开始,流量(绿色曲线)逐步增加,随之GPU卡数(蓝色曲线)也开始增加,在6:40左右达到峰值,使用了约75张卡。之后流量迅速减少,系统随之缩容至20左右。如果没有自动扩缩容功能,该服务需要长期占用75张卡,但是每天仅有4个小时的流量高峰,显然这种使用方式会造成严重的资源浪费。
✅ 有没有比QPS更好的调控指标:
如何选择合适的服务指标,判断当前服务的满载状态,是动态扩缩容的关键。第一版我们采用了QPS作为扩缩容的依据。但是也存在一些问题:1) 需要用户手工设置上限QPS,比较繁琐;2) 单机上限QPS会随着机器规格、流量batch大小等动态变化,不能准确反映出当前服务的满载状态。
因此我们新定义“服务忙碌状态(Busy)”替换QPS,来判断当前服务的状态。Busy指标通过统计单位时间(一般为10秒)内各个CPU进程的工作时间占比,来判断当前服务器是否达到性能上限,如下图所示。
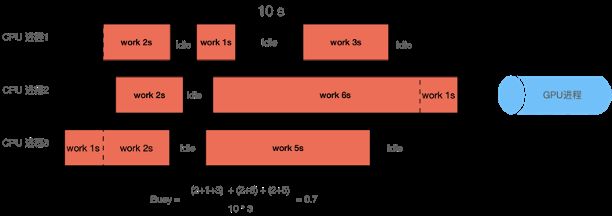
通过调整服务机器数,使得Busy值稳定在0.6~0.8之间,取得了比较好的线上效果,在保证请求不超时的前提下,有效的提高了GPU利用率。
后续还要从两个方面继续完善该功能:1.扩缩容的依据由单机QPS以及Busy状态外,还应加入P99 Latency变化、GPU Util等多个维度的指标,保证扩缩容更加精细和准确;2.当重要任务扩容资源不足时,是完全缩最低优先级的服务,还是不同优先级服务各缩容一部分,才能满足各个服务owner的诉求,需要更精细化的计算。
3.1.2 多租户复用
多祖户复用,指的是在满足容器内存和GPU显存约束的前提下,将多个服务同时部署到单个容器内,以达到节省GPU资源,提高GPU利用率的目的。除了流量低需要多服务复用GPU外,GPU运算能力越来越强大也是我们考虑复用的一个原因之一。目前最新的A100的计算能力已经达到了624 TFLOPS(FP16 Tensor Core),2,039 GB/s 的带宽,后续还会出现越来越多的单机八卡服务器,因此探索多服务混布技术越来越重要。GPU的复用主要有两种方式:时序复用/空间复用,如下图所示。

1)时序复用:
每个时刻仅处理一个模型的请求,该请求独占GPU计算资源和PCIe带宽等资源。这种模式适用于两种场景:
场景1:模型占用计算资源过多,两个模型同时运行时抢占计算资源和带宽资源,导致同时运行的总Latency比两个模型单独运行的Latency之和更多。通过时序复用的方式,模型A占用计算资源的时候,模型B占用带宽资源传输数据,下一个周期A和B互换,达到整体资源利用率最高。
场景2:模型占用显存资源过多,多个模型无同时load至GPU显存的情况。每次request到来之时,从显存中unload其他模型,再load当前模型。在当前的技术条件下,reload模型的耗时在秒级别,无法应对毫秒级别的request,适用场景有限。如果该技术得以应用,必须将reload模型的时间控制在ms级别。
2)空间复用:
多个模型同时加载,同时对外提供服务,共享GPU算力、显存以及PCIe带宽等资源。这种模式适用于单个模型无法占满GPU资源的情况,使用场景较广。每个进程通过一个单独的Cuda Context使用部分GPU资源,再配合Tesla 及Volta系列新增加的multi-process services 技术(MPS),使得GPU资源被充分利用。其原理大致如下图所示,多个服务同时 launch kernels至MPS server,后者根据GPU的规格,将Kernels打包一次性发送至GPU执行,提高GPU的利用率。下图来源于《Nvidia Mps Document》(https://docs.nvidia.com/deploy/mps/index.html)。
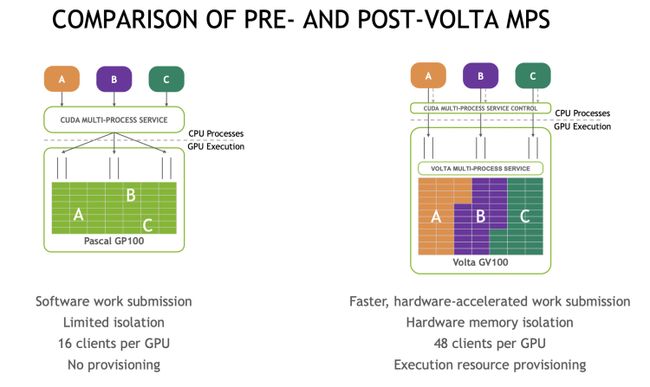
随着A100推出了multi-instance GPU(MIG),使得进程之间的GPU资源隔离(显存隔离、Cuda Cores隔离)越来越好,复用的价值越来越大,进程之间的相互影响也会越来越小。
high_service 目前采用的是空间复用的模式,但是空间复用存在一个绕不过去的问题:如果上图中A服务的请求占用太多的GPU计算资源,会造成B和C服务的request超时。对于这个问题,我们通过 CUDA_MPS_ACTIVE_THREAD_PERCENTAGE 环境变量,来限制A服务的Cuda Cores比例上限,避免A服务抢占全部的GPU资源。在CUDA 11.2之后的版本,可以为每个服务设置不同的使用比例。
3.2 服务架构优化
详细说明请参见上一篇文章《广告深度学习计算:阿里妈妈智能创意服务优化》,此处仅简要介绍。
服务架构层面的优化,着眼于解决单个服务性能不高,GPU利用率很低的问题。针对上文提到的Python GIL锁导致的GPU利用率低的问题,我们创新性的提出了CPU/GPU分离的多进程架构,在只加载一份模型的前提下,达到了多进程的效果。
3.2.1 CPU/GPU任务分离的多进程架构
✅ 为什么Python作为AI推理服务GPU利用率低?(技术大牛可绕行):
早期CPython为了避免多线程并发执行机器码造成bug,引入了互斥锁Global Interpreter Lock(GIL) ,只有获得了GIL锁的线程才能在执行。因此Python无法像C++那样充分利用现代CPU的多核处理能力,虽然开启了多线程,但是多线程并不能完全并行的跑在多个CPU Cores上,各个线程之间相互中断。
然而GPU作为一款协处理器,虽然其计算单元(Cuda Cores)远远多于CPU Cores,计算能力强大,但是GPU并不能主动执行计算任务,而是需要CPU将模型计算拆分成一个个独立的算子(称为Kernel),然后通过Cuda Stream串行发送给GPU去执行,这个过程是需要一个单独的CPU线程来完成的,我们称之为Kernel Launch线程。
但是多媒体AI服务天然是重CPU运算的,其视频/图片的读取、通道变换、尺寸压缩等等,通常会占用大量的CPU资源。这些线程会与Kernel Launch线程抢占CPU,导致Kernel Launch线程被频繁挂起,从而使得GPU无法及时接收到计算任务而闲置,导致了GPU利用率很低。GPU并没有到性能瓶颈,只是kernel执行的更加“稀疏”了。
✅ 如何解决?
为了避免CPU线程同Kernel Launch线程争抢GIL锁,我们将运行在GPU上的模型推理代码,剥离成为独立的进程。CPU进程执行视频/图片等输入的预处理,预处理后的Tensor写入共享内存,再将Tensor shape等信息通过进程间消息队列传递给GPU进程。由于读写共享内存与读写进程私有内存的效率几乎相同,因此这种使用模式并没有带来太多额外的开销,仅仅是多了一次内存读写,在整个pipeline中的耗时可以忽略。
同时由于CPU进程与Cuda操作无关,不占用显存,因此可以根据CPU core数目开启尽量多的进程,充分利用多核处理器的优势。多个CPU进程给一个GPU进程“喂”数据,可以使得GPU进程可以时刻保持满载运行状态,GPU利用率理论上可以达到100%。整体流程如下图所示。
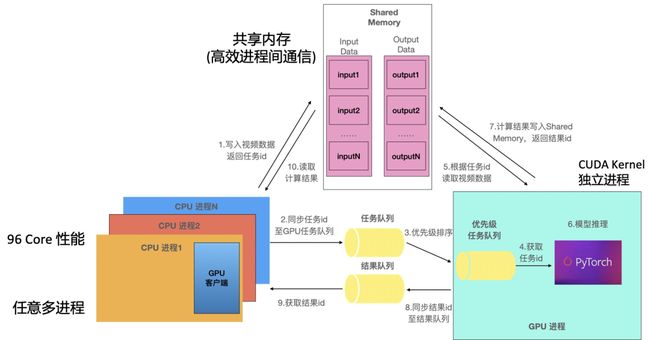
除了架构的改进,我们发现原生PyToch的计算和数据拷贝使用的是同一个Cuda Stream,二者在时序上是串行的,而GPU的计算资源和带宽资源实际上是可以同时并行的。因此high_service将二者调度到不同的Cuda Stream上并行起来,进一步提高了GPU利用率。
3.3 模型推理加速
3.3.1.支持PyTorch和TensorFlow模型优化
high_service目前支持PyTorch和TensorFlow两种深度学习模型。
1) PyTorch模型
针对PyTorch模型,high_service使用TensorRT进行优化加速。TensorRT是NVIDIA推出的一个高性能的深度学习推理框架,可以让深度学习模型在NVIDIA GPU上实现低延迟,高吞吐量的部署。

high_service引入TensorRT的同时,进行了高度的封装,简化了用户的使用成本。用户仅需在PyTorch模型定义阶段,添加如input shape等简单的配置,即可自动将PyTorch模型转换为TensorRT模型推理,真正做到了TensorRT使用的透明无感,大大方便了用户的使用。
对于生成的TensorRT serized engine文件,自动上传到内部oss存储系统,当后续服务启动时,系统根据当前GPU的型号、Cuda版本、TensorRT版本号等信息下载相应的TensorRT serized engine文件,避免了每个容器在重启时重复编译的情况,加快了服务的启动速度,平均一次编译可节省3-5分钟。该功能对于自动扩缩容场景尤为重要,能够大大加速流量高峰到来时,新容器的启动速度。
2)TensorFlow模型
由于我们部门在推荐和搜索广告场景,积累了大量TensorFlow模型的优化经验,因此high_service直接集成了高度优化过的TensorFlow v1.15安装包,最大程度提升TensorFlow模型的推理效率。详细的优化内容参见《广告深度学习计算:异构硬件加速实践》
除了支持原生TensorFlow模型以外,我们也集成了TensorFlow转Onnx再转TensorRT的工具。
3.3.2 模型优化
模型训练代码,与线上推理代码相比,部分逻辑是多余的,如果不进行处理直接上线,会引入额外的计算,造成计算资源的浪费。因此high_service集成了常见的模型改写Pass,以使得模型性能达到最优。
一个典型的例子是去除Spectral Normalization(谱归一化)。Spectral Normalization在GAN网络中被广泛使用,通过一种更优雅的方式使得判别器 D 满足Lipschitz连续性,限制了函数变化的剧烈程度,从而使模型更稳定。spectral_norm仅在训练阶段有意义,对于推理阶段固定权重W的情况下,该操作无任何意义。因此通过high_service的remove_all_spectral_norm pass,自动删除spectral_norm算子,提升服务性能且对算法同学完全透明。
随着遇到case的增加,high_service支持的优化pass会越来越多,这些优化会更好的复用到其他场景中。
三、未来规划
high_service目前已在妈妈智能创意以及内容风控两个业务领域落地并取得了不错的业务效果,提升了单机的服务能力,节省了大量的GPU资源。但是在使用过程中,还是发现有很多不足的地方,接下来我们将从以下几个方面继续完善:
自动定位服务瓶颈。目前的服务性能优化还是以经验为主,通过分析系统状态来定位瓶颈点。后续high_service将根据CPU/GPU利用率、内部消息队列长度等多维度指标,并集成NSight Systems/Perf等分析工具,自动生成系统性能分析报告,为系统优化提供更准确的信息。
CPU算力优化。对于视频、图文等服务,图片的预处理、视频的编解码消耗了大量的CPU资源。通过试验发现,不少服务仅通过增加容器的CPU核数,吞吐就可以提升10%~50%。因此接下来将引入更多的GPU图像处理库,将CPU运算迁移至算力更强大的GPU上,降低CPU使用率。
GPU计算优化。虽然TensorRT等后端执行引擎已经做了高度的优化,但是对于特定模型、特定场景还是有很大的优化空间。随着系统层面的持续优化,性能瓶颈点会转移至GPU Kernel运算。因此Kernel优化以及图执行调度优化等GPU计算优化将成为未来优化的主战场。
引用
[1] 广告深度学习计算:阿里妈妈智能创意服务优化
[2] 告别拼接模板 —— 阿里妈妈动态描述广告创意
[3] 营销文案的“瑞士军刀”:阿里妈妈智能文案多模态、多场景探索
[4] Nvidia Mps Document , https://docs.nvidia.com/deploy/mps/index.html
END

也许你还想看
丨广告深度学习计算:阿里妈妈智能创意服务优化
丨广告深度学习计算:异构硬件加速实践
丨广告深度学习计算:召回算法和工程协同优化的若干经验
丨新时期的阿里妈妈广告引擎
关注「阿里妈妈技术」,了解更多~

喜欢要“分享”,好看要“点赞”ღ~
↓欢迎留言参与讨论↓