轻量级实时语义分割:ICNet & BiSeNet
轻量级实时语义分割:ICNet & BiSeNet
- ICNet
-
- 贡献
- Image Cascade Network
- Cascade Label Guidance
- Structure Comparision and Analysis
- 结果
- BiSeNet
-
- Introduction
- Bilateral Segmentation Network
- NetWork architecture
- 结果
- 总结
介绍两篇论文,都是2018年ECCV提出来的,一篇是ICNet,一篇是BiSeNet,都是实时轻量化语义分割。
ICNet
贡献
- 提出一个新颖且独特的图像级联网络用于实时语义分割,利用了低分辨率语义信息和高分辨率图像的细节。
- 提出的级联特征融合单元和级联标签引导能够以较低的计算成本逐步恢复和细化分割预测。
- ICNet速度快,内存占用小。
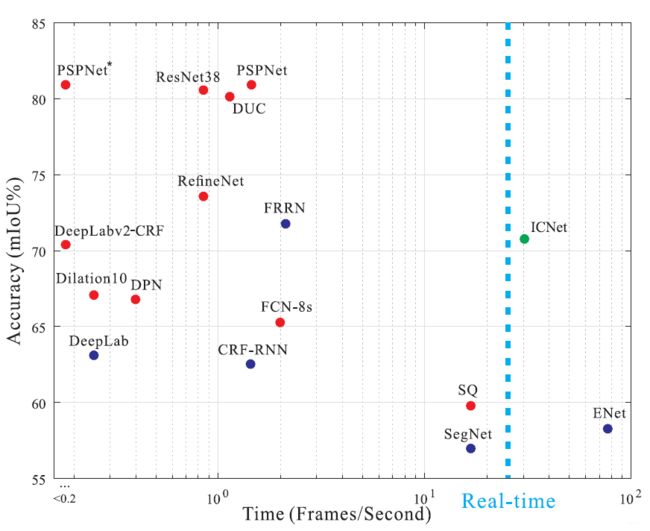
Image Cascade Network
Speed Analysis
输入feature map: V ∈ R c × h × w V \in \mathbb{R}^{c \times h \times w} V∈Rc×h×w
输出feature map: U ∈ R c ′ × h ′ × w ′ U \in \mathbb{R}^{c^{\prime} \times h^{\prime} \times w^{\prime}} U∈Rc′×h′×w′
V → U V \rightarrow U V→U的转移是通过 c ′ c^{\prime} c′个 k × k × c k\times k \times c k×k×c大小卷积核运算得到的。
且输出的 h ′ h^{\prime} h′和 w ′ w^{\prime} w′是根据stride步长s决定的。有 h ′ = h / s , w ′ = w / s h^{\prime}=h/s,w^{\prime}=w/s h′=h/s,w′=w/s
所以整个操作的参数为: c ′ c k 2 h w / s 2 c^{\prime} c k^{2} hw/s^2 c′ck2hw/s2
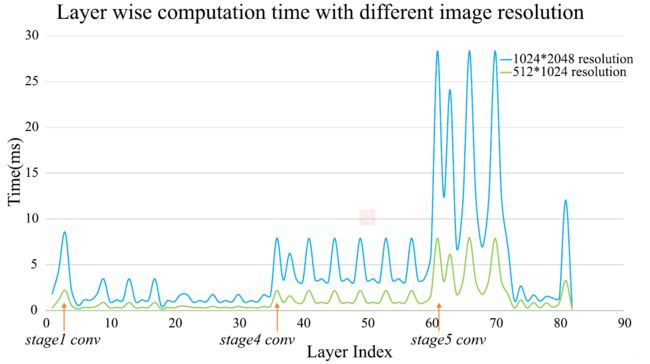
计算的复杂度和feature map分辨率、卷积核数量和网络宽度有关。
下图显示了PSPNet50在不同分辨率的运行时间情况。
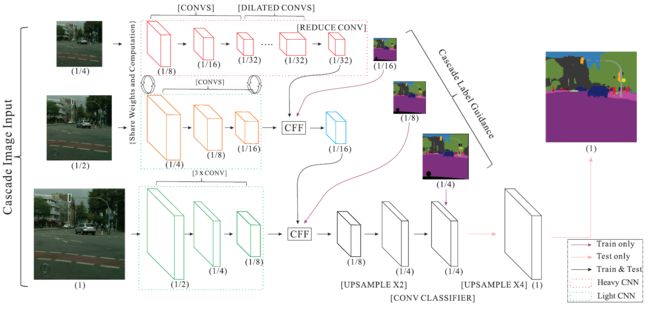
Network Archirtecture
作者首先采用了常规的加速策略:downsampling input,shrinking feature maps 和 conducting model compression,实验结果显示没办法平衡精度和速度。
于是作者提出了image cascade network(ICNet)。输入多个分辨率的图像(下采样二倍和四倍),对于小分辨率的图像采用PSPNet的网络,称之为heavy CNN(层数多),而对于大分辨率的图像则采用Light CNN(层数少)。
中低分辨率图像分支之间参数共享,又降低了执行时间。
Cascade Feature Fusion
不同cascade feature使用论文提出的 Cascade Feature Fusion Unit(CFF)进行融合。F1其中上采样使用双线性插值法。然后使用空洞卷积继续上采样,相比于deconvolution,这种方法只需要少量的卷积核就能获得相同的感受野。而F2则进行了一个projection conv的操作。
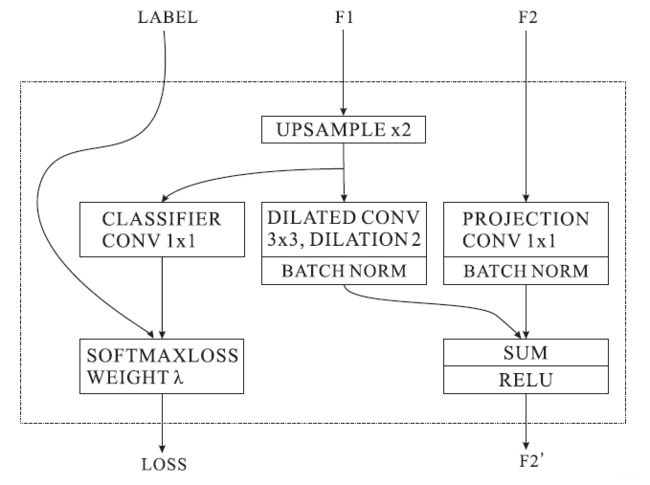
Cascade Label Guidance
为了提高F1、F2的学习能力,作者在F1、F2这里使用了cascade label guidance。使用不同尺寸的Groud-Truth去引导低、中、高分辨率学习。论文采用了加权softmax交叉熵损失。最小化损失函数:
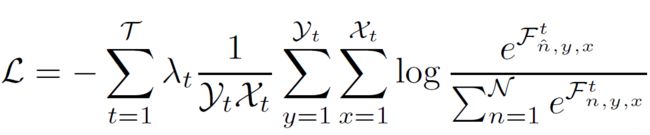
T \mathcal{T} T为branch的个数,本文为3。
branch t的feature map大小为 Y t × X t \mathcal{Y}_{t} \times \mathcal{X}_{t} Yt×Xt。
位置 ( n , y , x ) (n,y,x) (n,y,x)的值为 F n , y , x t \mathcal{F}_{n, y, x}^{t} Fn,y,xt
相关的ground truth label为 n ^ \hat{n} n^。
每个branch的损失权重为 λ t \lambda_{t} λt
测试阶段,低分辨率和中分辨率操作被舍弃,只留下高分辨率。这个策略使得梯度优化更平滑容易训练。
Structure Comparision and Analysis
以下abc是常有的框架。
a:Intermediate skip connection,如:FCN和Hypercolumns方法使用了。
b:Encoder-decoder structure,如:SegNet,DeconvNet,UNet,ENet
c:Multi-scale prediction,如:DeepLab-MSC,PSPNet-MSC
其中d是作者提出的框架,为ICNet的一部分。在这个框架上,仅有低分辨率输入使用Heavy CNN进行提取,大量减少了的计算且得到了粗糙的语义预测。更高的分辨率输入用于逐步恢复和细化模糊边界和缺失细节的预测,使用的是Light-weighted CNNs。新引入的cascade-feature fusion unit 和 guidance label 策略也为更加精准提供了帮助。
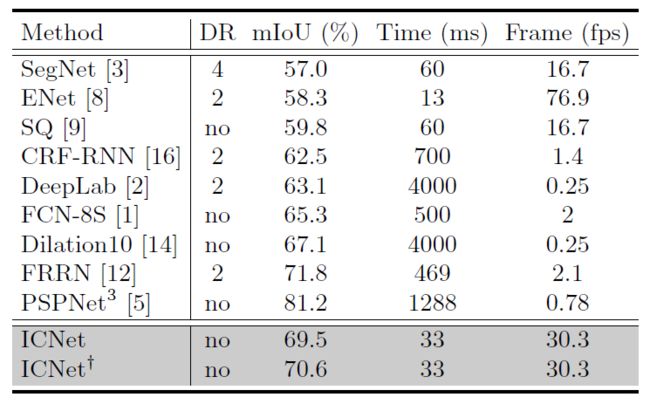
结果
BiSeNet
Introduction

一、之前的工作中,实时语义分割加速模型的方法主要有三种。
- [34,39]尝试通过裁剪或调整大小来限制输入大小,降低计算复杂度。虽然方法简单且有效,尤其是边界附近的预测会受到影响,导致度量和可视化的精度下降。
- 有些工作通过对网络信道进行修剪来提高推理速度[1,8, 25],特别是在基线模型的早期。但这也会削弱空间容量。
- 最后一种情况,ENet提议放弃模型的最后阶段,以追求一个非常紧密的框架。但是由于ENet在最后一个阶段丢弃了下采样操作,模型的感受也不足以cover大的物体。
这三种情况如上图a所示。
二、为了弥补上述空间损失,研究者更多地使用了U-shape 结构。通过backbone网络融合分层特征,逐渐提升空间分辨率和填补一些丢失的细节。但这种方法有有个缺点:
1.u形结构由于在高分辨率feature map上引入了额外的计算,降低了模型的速度。
2.大部分在pruning或cropping过程中丢失的空间信息都不能通过涉及浅层特征来轻松恢复。
其结构如上图b所示。
三、作者提出了Bilateral Segmentation Network(BiSeNet),包括两部分:Spatial Path 和 Context Path。这两部分分别是为了应对空间信息的丢失和感受野的收缩而设计的。Spatial Path经过三层卷积,得到1/8大小的feature maps,保留了丰富的空间细节,Context Path则是在Xpection尾部增加了全局平均池化层,因为这里是backbone network感受野最大的层。
结构如上图c所示。
作者还提出Feature Fusion Module (FFM) 和 Attention Refinement Module (ARM)。
贡献:
1.提出BiSeNet;
2.设计特征融合模块和注意力细化模块(FFM 和 ARM)。
Bilateral Segmentation Network
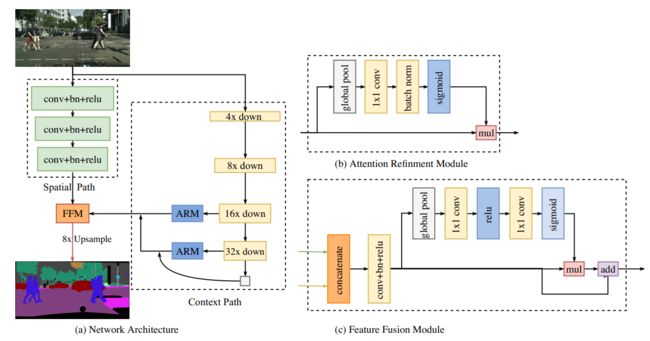
作者提出的BiSeNet包含两个Path,分别是Spatial Path 和 Context Path。
Spatial Path:一些现有的方法保持输入图像的分辨率使用空洞卷积进行编码,一些方法采用金字塔池化模型,空间金字塔池化或“更大的核”来获取足够的感受野。
这些方法表明,空间信息和感受野是获得高精度的关键。然而,很难同时满足这两种需求。
在实时语义分割任务中,一般采用小图像输入或轻量级模型来加速。小尺寸的输入会损失主要的空间信息,使用通道剪支的轻量级模型会破坏空间结构。基于观察,作者提出了Spatial Path去保留原始输入图像的空间信息,并且编码丰富的空间信息。Spatial Path包含三层,每一层包括stride为2的卷积,紧跟着是BN层和ReLU层。该路径提取出原始图像1/8的输出特征图。由于特征图的空间尺寸很大,因此可以编码丰富的空间信息。
Context Path:Spatial Path 编码丰富的空间信息。Context Path 主要用于获得更大的感受野。一些方法使用金字塔池化模型,空间金字塔池化等方法,但需要大量计算和内存。于是提出Context Path使用轻量级模型和全局平均池化(global average pooling )。这里使用了U-shape结构融合了分辨率不同的feature map。
作者还在这个Path增加了一个特别的注意力细化模块,使用了全局平均池化去捕获全局信息,并计算注意力向量来引导特征学习。
NetWork architecture
作者Spatial Path 采用三层卷积层构成,Context使用了预训练过的Xception模型作为backbone。具体如上图所示,已经很清楚了。
Feature fusion module
针对spatial path表示的low-level特征和context path表示的high-level特征,作者首先将两者concat起来,然后使用BN来平衡特征尺度,然后使用池化、1x1卷积等计算出feature map的权重,再乘以concat的feature map,该权重向量可以对特征赋予权重。
Loss function
作者以BiSeNet最后输出来作为主要loss function,并使用了辅助loss function,分别在Context Path的两次output上进行预测分类,loss function均为Softmax loss。
los s = 1 N ∑ i L i = 1 N ∑ i − log ( e p i ∑ j e p j ) \operatorname{los} s=\frac{1}{N} \sum_{i} L_{i}=\frac{1}{N} \sum_{i}-\log \left(\frac{e^{p_{i}}}{\sum_{j} e^{p_{j}}}\right) loss=N1i∑Li=N1i∑−log(∑jepjepi)
L ( X ; W ) = l p ( X ; W ) + α ∑ i = 2 K l i ( X i ; W ) L(X ; W)=l_{p}(X ; W)+\alpha \sum_{i=2}^{K} l_{i}\left(X_{i} ; W\right) L(X;W)=lp(X;W)+αi=2∑Kli(Xi;W)
其中 l p l_p lp是主要concat后的主要loss。 l i l_i li是Context Path两个阶段output的预测loss。 α \alpha α是辅助loss的权重。
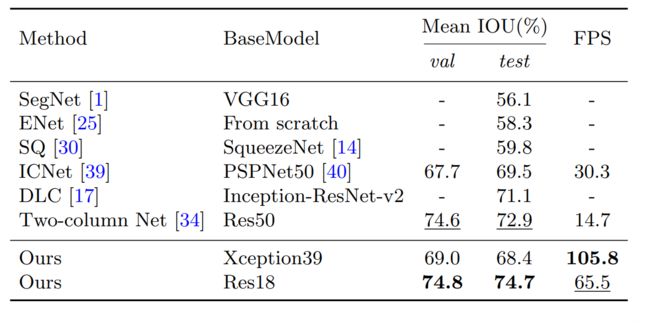
结果
总结
让我们重新回顾一下两个算法的特点。
ICNet:采用多尺度输入,在大分辨率采用较少的卷积核与层,在小分辨率使用较深网络,最后进行融合,并且在三个尺度提取出来的feature map进行预测分类来辅助整个loss function,上采样部分采用空洞卷积和双线性采样。
BiSeNet:采用单尺度原图输入,两个分支,Sptial Path使用三层卷积来避免破坏边缘信息且降低计算,Context Path使用深层网络获得更好的context信息,使得感受野更大,并在Context Path增加了注意力机制和预测分类来辅助loss function,最后进行融合。
两算法都没有采用常见的U型结构,而是使用了多路分支,既要提取分辨率大时的信息,又要提取分辨率小时的信息。且在分辨率大的feature map 采用浅层网络,在分辨率小的feature map使用深层网络,BiSeNet相较于ICNet的提升较大。