Pytorch 入门 ----学习笔记
本文是在参加DataWhale开源组队学习《深入浅出Pytorch》过程中,整理的学习笔记。
Pytorch 基础知识
张量
张量的创建
张量,也叫做多维数组,常常我们对于一维张量也叫做标量,二位张量叫做矩阵。大部分时候,张量是三维及三维以上的多维变量
张量的创建可以通过如下命令:
- torch.rand() 构造一个随机初始化矩阵
- torch.zeros()构造一个全为零的矩阵
- torch.tensor() 直接使用数据构造
张量的操作
张量的操作种类繁多,包括数学运算、维度变换等等,详情可参考官方文档
- 加法操作
- 维度变换
对形状相同的张量进行数学运算时,我们按照“按位运算”来进行,即张量内部的每个元素都进行相同的操作。此外,还有向量点积和矩阵乘法等。对于形状不同的张量,则需要下面介绍的广播机制来处理。
广播机制
广播机制是在某些情况下,当我们的张量间形状不同,但还要进行按元素运算时所应用到的。其核心就是通过适当的复制元素来扩展其中的一个或两个数组,使两者形状相同,再进行按元素运算。
import torch
a = torch.arange(3).reshape((3, 1))
b = torch.arange(2).reshape((1, 2))
'''
a: tensor([[0],
[1],
[2]])
b: tensor([[0, 1]])
a + b : tensor([[0, 1],
[1, 2],
[2, 3]])
'''Pytorch主要组成模块
深度学习的任务往往比较复杂,虽然默认是在CPU上运行,但GPU是用来做深度学习任务更好的选择
常见的GPU设置方式有:
# 1.使用os.environ,这种情况如果使用GPU不需要设置
os.environ['CUDA_VISIBLE_DEVICES'] = '0,1'
# 2.使用“device”,后续对要使用GPU的变量用.to(device)即可
device = torch.device("cuda:1" if torch.cuda.is_available() else "cpu")数据读入
Pytorch 通过Dataset 和 DataLoader 来完成数据的读入,Dataset主要负责定义数据的格式,是否进行变换等。DataLoader可以按批次读取数据,在数据量很大的情况下,可以避免内存爆炸,还提供shuffle(打乱)等操作。
构建模型
PyTorch中神经网络构造一般是基于 Module 类的模型来完成的,它是 nn 模块里提供的一个模型构造类,是所有神经网络模块的基类。
import torch
from torch import nn
#继承Module类,构建MLP
class MLP(nn.Module):
# 声明带有模型参数的层,这里声明了两个全连接层
def __init__(self, **kwargs):
# 调用MLP父类Block的构造函数来进行必要的初始化。这样在构造实例时还可以指定其他函数
super(MLP, self).__init__(**kwargs)
self.hidden = nn.Linear(784, 256)
self.act = nn.ReLU()
self.output = nn.Linear(256,10)
# 定义模型的前向计算,即如何根据输入x计算返回所需要的模型输出
def forward(self, x):
o = self.act(self.hidden(x))
return self.output(o) 模型初始化
在Pytorch中,模型初始化主要通过 torch.nn.init 来实现,但对于不同的神经网络层来说,做的初始化操作并不一定相同,常见的操作有torch.nn.init.uniform_ ,torch.nn.init.normal_等,更多操作可以参考官方文档
# 分别对不同的层进行不同的初始化操作
# 对conv进行kaiming初始化
torch.nn.init.kaiming_normal_(conv.weight.data)
conv.weight.data
# 对linear进行常数初始化
torch.nn.init.constant_(linear.weight.data,0.3)
linear.weight.data损失函数
损失函数,通俗理解就是来评价我们前进的方向有没有问题。从控制的角度来理解损失函数就是反馈机制,可以告诉我们输出的预测结果和实际的真实值之间的差距。通过损失函数,我们才能进一步的来调整方向,愈加逼近真实值。
(常见的损失函数与其优缺点)
模型定义
模型定义的方式
模型的定义主要基于nn.Module 模块,通过如下三种方法,可以快速的构建我们自己的模型。
- Sequential
- ModuleList
- ModuleDict
Sequential
对应模块为nn.Sequential(),当模型的前向计算为简单的串联时,使用nn.Sequential() 非常的简洁易懂,它会按照写好的顺序逐一进行前向计算。不需要再写forward函数。
import torch.nn as nn
net = nn.Sequential(
nn.Linear(784, 256),
nn.ReLU(),
nn.Linear(256, 10),
)
print(net)ModuleList
对应模块为nn.ModuleList(),它用来存储一个模块列表,可以向其添加或删除层。但存储顺序并不是整个网络的forward计算顺序,需要在forward内部指定真实的计算顺序。
ModuleDict
对应模块为nn.ModuleDict(),它与MouduleList的功能几乎相同,但ModuleDict可以方便的定义神经网络层的名称。
#添加名称
net = nn.ModuleDict({
'linear': nn.Linear(784, 256),
'act': nn.ReLU(),
})
net['output'] = nn.Linear(256, 10) # 添加
print(net['linear']) # 访问
print(net.output)
print(net)
'''
Linear(in_features=784, out_features=256, bias=True)
Linear(in_features=256, out_features=10, bias=True)
ModuleDict(
(act): ReLU()
(linear): Linear(in_features=784, out_features=256, bias=True)
(output): Linear(in_features=256, out_features=10, bias=True)
)
'''综上,Sequential适用于快速验证结果,因为已经明确了要用哪些层,直接写一下就好了,不需要同时写__init__和forward;
ModuleList和ModuleDict在某个完全相同的层需要重复出现多次时,非常方便实现,可以”一行顶多行“;
当我们需要之前层的信息的时候,比如 ResNets 中的残差计算,当前层的结果需要和之前层中的结果进行融合,一般使用 ModuleList/ModuleDict 比较方便。
进阶技巧
自定义损失函数
虽然Pytorch的torch.nn模块已经给我们提供了较多常用的损失函数,如L1Loss、MSELoss等。但是这些损失函数可以应对通用模型,对于一些非通用模型,可能需要一些专门的损失函数。就好比Pytorch提供给我们了一堆常用的标准的零部件,但有时候我们可能需要一些个性化的零部件来满足特别的需求。这时候我们就需要自定义零部件了,也就是自定义我们的损失函数。
损失函数可以通过函数方法来定义
#用函数方法自定义loss函数
def my_loss(output, target):
loss = torch.mean((output - target)**2)
return loss也可以通过类的方式来定义
#通过类方式自定义损失函数
class DiceLoss(nn.Module):
def __init__(self,weight=None,size_average=True):
super(DiceLoss,self).__init__()
def forward(self,inputs,targets,smooth=1):
inputs = F.sigmoid(inputs)
inputs = inputs.view(-1)
targets = targets.view(-1)
intersection = (inputs * targets).sum()
dice = (2.*intersection + smooth)/(inputs.sum() + targets.sum() + smooth)
return 1 - dice
# 使用方法
criterion = DiceLoss()
loss = criterion(input,targets)其中,我们自己定义的损失函数类继承自nn.Module。
动态调整学习率
在过往的学习和实验经历中我们了解到,超参数的选择对模型的效果有较大的影响,同样的模型,超参数的不同甚至会有较大的差异。其中学习率的选择就是十分令人头疼的代表,过高的学习率会导致振荡,可能永远都无法找到最优解;过小的学习率则会使得收敛速度大大降低,整体的训练时间显著增加。
因此,有人提出是否可以动态调整学习率,一开始学习率可以设置较大,随着训练的进行,学习率逐渐降低,这样则可以避免振荡的发生。
设置一个学习率衰减策略这种方法在Pytorch中称为scheduler。
Pytorch中已经封装好了一些动态调整学习率的方法在torch.optim.lr_scheduler下。例如:
-
lr_scheduler.LambdaLR
-
lr_scheduler.MultiplicativeLR
-
lr_scheduler.StepLR
-
lr_scheduler.MultiStepLR
-
lr_scheduler.ExponentialLR
-
lr_scheduler.CosineAnnealingLR
-
lr_scheduler.ReduceLROnPlateau
-
lr_scheduler.CyclicLR
-
lr_scheduler.OneCycleLR
-
lr_scheduler.CosineAnnealingWarmRestarts
更多方法可以参考官方文档。
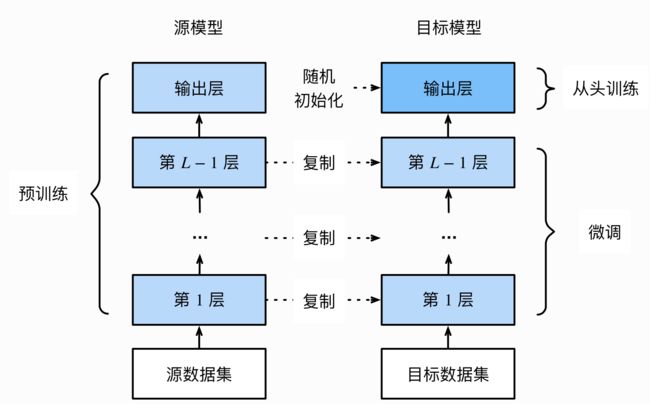
模型微调
模型微调是随着深度学习的发展而产生的一种训练形式,随着深度学习模型的复杂度越来越高,数据量越来越大,其参数甚至达到千万级别。而这些模型开源出来我们在使用时,因为我们可能数据量较小,从头开始训练很难有好的效果。
模型微调提供了使用这种超大模型的可能性。即将别人已经训练好的模型,我们拿来使用,虽然很可能这个模型和我们的目标不一定完全相同,但其中很多关于特征的提取等都是可以用得上的。
参考文献
《动手学深度学习》 — 动手学深度学习 2.0.0-beta0 documentation (d2l.ai)
《深入浅出Pytorch》