基于python+opencv+mediapipe实现手势识别详细讲解
目录
运行环境:
一、opencv
二、meidapipe配置
三、实现手部的识别并标注
1、参数分析
1.multi_hand_landmarks
2.multi_hand_world_landmarks
3.multi_handedness
2.绘制信息点和连线
运行环境:
python3.9.7 opencv-python4.6.0.66 mediapipe0.8.11
运行之前先要安装opencv-python、opencv-contrib-python、mediapipe
pip install opencv-python
pip install opencv-contrib-python
pip install mediapipe项目可能对版本的要求较为严格,安装不上的可以按我版本
这篇文章只介绍mediapipe的简单实现,拖拽和放大效果后续更新
一、opencv
OpenCV是一个基于Apache2.0许可(开源)发行的跨平台计算机视觉和机器学习软件库,它轻量级而且高效——由一系列 C 函数和少量 C++ 类构成,提供了Python的接口,实现了图像处理和计算机视觉方面的很多通用算法。
这里用opencv实现调用摄像头,绘制图像等操作。
opencv的简单使用
通过while循环,每次循环读取每一帧的图片,并对每一帧的图片进行处理,并设置一个1毫秒的延迟,再进入下一次循环,实现摄像头的调用和读取
import cv2
# 调用摄像头 0为默认摄像头
cap = cv2.VideoCapture(0)
# 通过循环将每一帧的图片读出来
while True:
# read方法返回两个参数
# success 判断摄像头是否打开成功,img 为读取的每一帧的图像对象
success, img = cap.read()
if not success:
print('摄像头打开失败')
break
# 0为开启上下镜像 1为开启左右镜像 -1为左右并上下镜像
img = cv2.flip(img,1)
# imshow方法展示窗口,第一个参数为窗口的名字,第二个参数为帧数
cv2.imshow("frame", img);
# 延迟一毫秒
cv2.waitKey(1)二、meidapipe配置
首先要在while循环之前对mediapipe进行配置
hand_drawing_utils:为手部特征点和连线的绘制工具
mp_hands:因为mediapipe中有很多的识别,包括手部,面部,姿态等,mp_hands获取到的是手部识别的api
my_hands:通过api获取到手部识别的类
# 配置mediapipe
hand_drawing_utils = mp.solutions.drawing_utils # 绘图工具
mp_hands = mp.solutions.hands # 手部识别api
my_hands = mp_hands.Hands() # 获取手部识别类Hands类中可以填入参数,也可以使用默认参数,在pycharm中按住ctrl,点击函数名查看此函数的介绍

static_image_mode=True适用于静态图片的手势识别,Flase适用于视频等动态识别,比较明显的区别是,若识别的手的数量超过了最大值,True时识别的手会在多个手之间不停闪烁,而False时,超出的手不会识别,系统会自动跟踪之前已经识别过的手。默认值为False。
max_num_hands 用于指定识别手的最大数量。默认值为2。
model_complexity 表示手部模型的复杂程度,手部模型越复杂,需要的响应时间就越长。默认值为1。
min_detection_confidence 表示最小检测信度,取值为[0.0,1.0]这个值约小越容易识别出手,用时越短,但是识别的准确度就越差。越大识别的越精准,但是响应的时间也会增加。默认值为0.5。
min_tracking_confience 表示最小的追踪可信度,越大手部追踪的越准确,相应的响应时间也就越长。默认值为0.5。
若不填任何参数,那么将会使用默认参数。
import mediapipe as mp
import cv2
# 配置meidapipe
hand_drawing_utils = mp.solutions.drawing_utils # 绘图工具
mp_hands = mp.solutions.hands # 手部识别api
my_hands = mp_hands.Hands() # 获取手部识别类
# 调用摄像头 0为默认摄像头
cap = cv2.VideoCapture(0)
# 通过循环将每一帧的图片读出来
while True:
# read方法返回两个参数
# success 判断摄像头是否打开成功,img 为读取的每一帧的图像对象
success, img = cap.read()
if not success:
print('摄像头打开失败')
break
# 0为开启上下镜像 1为开启左右镜像 -1为左右并上下镜像
img = cv2.flip(img, 1)
# imshow方法展示窗口,第一个参数为窗口的名字,第二个参数为帧数
cv2.imshow("frame", img);
# 延迟一毫秒
cv2.waitKey(1)
三、实现手部的识别并标注
1、参数分析
完成mediapipe手部识别的基本配置后,此时还不能识别出手势,接下来要在while循环中的每一帧图像中,进行手部的识别
process()是手势识别最核心的方法,通过调用这个方法,将窗口对象作为参数,mediapipe就会将手势识别的信息存入到res对象中。
# 将BGR转换为RGB
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
# 识别图像中的手势,并返回结果
results = my_hands.process(img)
# 再将RGB转回BGR
img = cv2.cvtColor(img, cv2.COLOR_RGB2BGR)因为在opencv中使用的色彩格式为BGR,而mediapipe能识别的为RGB,所以要先用
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB) 将BGR转换为RGB,为了保证窗口显示正常,还要在识别完成后,将RGB再转回BGR
接下来就是对results中保存的信息进行处理
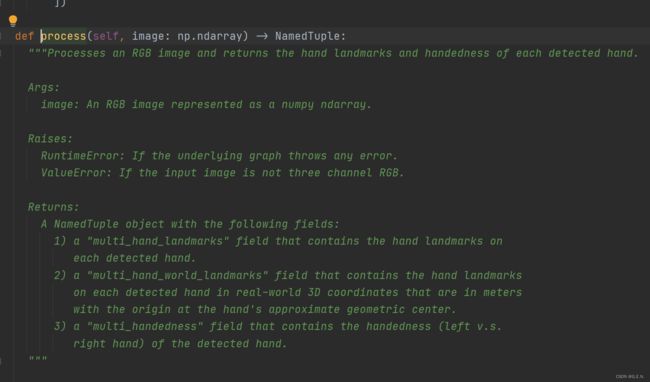
在pycharm中按住ctrl点击process就可以看到这个方法的相关介绍和返回值的信息,在下方的Returns中,返回的对象中含有以下三个字段:1.multi_hand_landmarks 2.multi_hand_world_landmarks 3.multi_handedness
1.multi_hand_landmarks
包括识别出的所有手的手部的所有信息点,可以将这个参数打印出来观察一下
print(results.multi_hand_landmarks)
简单来说,参数的形式为 [手1所有信息点,手2所有信息点,……],识别出来手的个数取决于画面中手的个数以及设置的手部最大识别个数。若画面中没有手,那么这个参数值为None。
landmark表示每个信息点中有三个参数 x y z。要注意的是x,y是小数,是相对整个屏幕到左侧和上侧的距离,若识别出的信息点的x为0.5,那么在x方向上信息点在屏幕中心位置,若为0,那么手指在屏幕左侧边缘,若为1,那么信息点在屏幕右侧边缘。y方向同理。z为相对与手掌根处的距离。
2.multi_hand_world_landmarks
这个参数跟multi_hand_landmarks 的形式一致,但是坐标的组织方式不同,根据官方说明,检测到跟踪的手的集合,其中每只手都表示为世界坐标中 21 个手地标的列表。每个地标由x、y和z组成,以米为单位的真实世界 3D 坐标,原点位于手部的近似几何中心。
3.multi_handedness

这个参数记录了识别出的每只手的描述。包括手的索引值,是惯用手的概率,和左手还是右手。
2.绘制信息点和连线
在搞懂具体的参数后,就开始绘制手部的信息点和连线。
# results.multi_hand_landmarks为None时进行for循环会报错,所以要先判断
if results.multi_hand_landmarks:
for hand_landmark in results.multi_hand_landmarks:
hand_drawing_utils.draw_landmarks(img, hand_landmark)通过for循环遍历出每只手的全部信息点,然后就可以对信息点进行绘制。
这里要在for循环之前用if进行判断,因为在未识别到手势时,multi_hand_landmarks的值为None,此时进行for循环就会报错。
通过在前面定义的绘图工具,绘制手部信息点,第一个参数传入要绘制的图片,也就是当前的帧,第二个参数要填入信息点的集合。现在就可以绘制出信息点了
但是此时只有信息点,信息点中没有连线,接下来我们可以在
draw_landmarks()方法中继续传入参数
hand_drawing_utils.draw_landmarks(img, hand_landmark, mp_hands.HAND_CONNECTIONS)此时的连线就出现了
hand_drawing_utils.draw_landmarks(img,
hand_landmark,
mp_hands.HAND_CONNECTIONS,
mp.solutions.drawing_styles.get_default_hand_landmarks_style(),
mp.solutions.drawing_styles.get_default_hand_connections_style())向方法中传入样式的参数,便会显示出更丰富的样式
所有代码
import mediapipe as mp
import cv2
# 配置meidapipe
hand_drawing_utils = mp.solutions.drawing_utils # 绘图工具
mp_hands = mp.solutions.hands # 手部识别api
my_hands = mp_hands.Hands() # 获取手部识别类
# 调用摄像头 0为默认摄像头
cap = cv2.VideoCapture(0)
# 通过循环将每一帧的图片读出来
while True:
# read方法返回两个参数
# success 判断摄像头是否打开成功,img 为读取的每一帧的图像对象
success, img = cap.read()
if not success:
print('摄像头打开失败')
break
# 将BGR转换为RGB
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
# 识别图像中的手势,并返回结果
results = my_hands.process(img)
# 再将RGB转回BGR
img = cv2.cvtColor(img, cv2.COLOR_RGB2BGR)
# results.multi_hand_landmarks为None时进行for循环会报错,所以要先判断
if results.multi_hand_landmarks:
for hand_landmark in results.multi_hand_landmarks:
hand_drawing_utils.draw_landmarks(img,
hand_landmark,
mp_hands.HAND_CONNECTIONS,
mp.solutions.drawing_styles.get_default_hand_landmarks_style(),
mp.solutions.drawing_styles.get_default_hand_connections_style())
# 0为开启上下镜像 1为开启左右镜像 -1为左右并上下镜像
img = cv2.flip(img, 1)
# imshow方法展示窗口,第一个参数为窗口的名字,第二个参数为帧数
cv2.imshow("frame", img)
# 延迟一毫秒
cv2.waitKey(1)