【R语言上市公司财务数据描述性数据统计】
上市公司财务数据描述性数据统计
一、导入数据集:
1.先预览数据集基本格式:
数据集百度盘链接
https://pan.baidu.com/s/1vrlXYlgr2-rR_fJPOqi2Uw?pwd=Yoke
提取码:Yoke

根据图片样式我们可以知道本数据集只有列标签没有行标签,且包含头标签
data <- read.csv(file="E:\\RHome\\al6-2.csv",header=T)
报错:
Error in read.table(file = file, header = header, sep = sep, quote = quote, :
more columns than column names
原因是:
more columns than column names(列的数目比列的名字要多)
解决办法:
1. 先取消读取第一行为标题,把header属性设置为False
data <- read.csv(file="E:\\RHome\\al6-2.csv",header=F)

数据读取成功,得知此问题是乱码问题
2. 尝试解决问题
设置encoding:
data <- read.csv(file="E:\\RHome\\al6-2.csv",header=T,encoding="utf-8")
报错:
Error in read.table(file = file, header = header, sep = sep, quote = quote, :
more columns than column names
fileEncoding根据参数对整个文件的重新编码,encoding根据参数仅对文件中字符串类型的参数重新编码
设置fileEncoding:
data <- read.csv(file="E:\\RHome\\al6-2.csv",header=T,fileEncoding = "utf-8")
3.导入数据成功

二、列出250家公司的“总资产”的频数分布:
1.将数据以升序进行排序
dat=data[order(data[,2]),]#data[sort(data$总资产,index.return=TRUE)$ix,]也可以

2.计算数据的极差(最大值减去最小值)
利用psych
library(psych)
des <- describe(dat)#屏幕上查看所有连续变量的描述统计量。
可以得到非缺失值的数量250,平均数204.53196,标准差1158.61893,中位数37.895,截尾均值55.14285,绝对中位差36.657285,最小值0.58,最大值17299.29,值域17298.71,偏度13.104640,峰度187.2536494和平均值的标准误差73.277495

观察数据发现有六个异常值严重影响了我们的频数分布我们将其放置在单独类,去其对数据的影响
# 删除这些行
del <- which(dat$总资产>=dat[245,2])
dat_del <- dat[-del,]
des1 <- describe(dat_del)#屏幕上查看去掉异常值所有连续变量的描述统计量。
Jicha <- des1[2,9]-des1[2,8]
> Jicha
[1] 924.77
3.确定频率分布,得出包含的区间数K
我们发现,总资产为0.58~924.77。将0 ~1000区间进行分段,每100为一段,共分为10段。区间数K=10+1(异常值)
4.确定区间宽度(极差/K)=100
5.不断的在数据最小值上加上区间宽度来确定各个区间的端点,此过程在到达包含最大值的区间时停止
6.计算落入每个区间中观测的个数
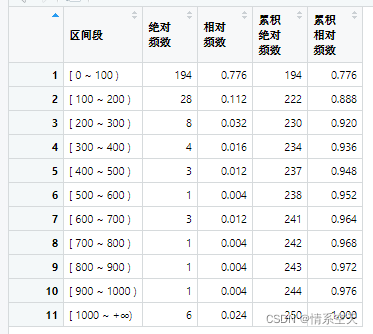
7.建立一个落入从小到大排列的每个区间中观测值数量的表格
#区间段
a = function(){
j = 1
n=c()
for(i in seq(0, 900, by=100)){
n[j]=paste('[',i,'~',i+100,')')
j = j+1
}
return (n)
}
qjd = a()
qjd[11]=paste('[',1000,'~ +∞)')
#累积绝对频数
b = function(){
n=c(0,0,0,0,0,0,0,0,0,0,250)
num=100
m=1
i=1
for (i in seq(1, 245, by=1)) {
if(dat[i,2]>num) {
n[m]=i-1
m=m+1
num=num+100
}
}
return(n)
}
ljjd = b()
#绝对频数
d=function(){
n=c()
n[1]=ljjd[1]
for(i in seq(1,10,by=1)){
n[i+1]=ljjd[i+1]-ljjd[i]
}
return(n)
}
jd=d()
#相对频数
xd = jd/250
#累积相对频数
ljxd = ljjd/250
#数据展示
区间段=qjd
绝对频数=jd
相对频数=xd
累积绝对频数=ljjd
累积相对频数=ljxd
data_last=data.frame(区间段,绝对频数,相对频数,累积绝对频数,累积相对频数)
主要思想是通过在升序的dataframe中寻找各组的临界单元值,然后通过返回行号进行处理最终得到所需数据。
8.数据可视化
#数据可视化
library(gcookbook)
library(ggplot2)
barplot(data_last$相对频数,names.arg = data_last$区间段,main="相对频数的柱状图",ylim = c(0,1))
ggplot(data_last, aes(x=区间段, y=相对频数))+labs(title="相对频数的折线图")+ geom_point(size=6, shape=20)+geom_line(aes(group=""), color="black",size=1)+
theme(plot.title = element_text(hjust = 0.5))


三、比较summary(),Hmisc(),pastecs(),psych()四种描述性统计量函数的区别
summary函数
使用summary函数时,会显示每个维度的最小值(min),四分位数,中位数(median),均值(mean),最大值(max).
summary函数它只能显示数据的集中程度,而无法展现数据的离散趋势
tips:summary只能对因子和逻辑型向量进行频数计算如下图,其初始评级,借款类型等数据类型为vector型(向量型),所以无法统计其频数,我们需要将其数据类型进行转化,
Hmisc函数
Hmisc包中的describe()函数可返回变量和观测的数量、缺失值和唯一值的数目、平均值、分位数,以及五个最大的值和五个最小的值。
pastecs函数
通过pastecs包中的stat.desc()函数计算描述性统计量
格式:
stat.desc(x,basic=TRUE,desc=TRUE,norm=FALSE,p=0.95)
| 属性 | 含义 |
|---|---|
| X | 是一个数据框或时间序列 |
| basic=TRUE | 计算其中所有值、空值、缺失值的数量以及最小值 、最大值、值域还有总和 |
| desc=TRUE | 计算中位数、平均数、平均数的标准误,平均数置信度为95%的置信区间、方差、标准差以及变异系数 |
| norm=TRUE | 返回正态统计量,包括信度和峰度(以及它们的统计显著程度)及Shapiro-Wilk正态检验结果 |
| p | 当p-value<0.01说明变量之间存在某种关系,当p-value>0.05,不存在关系(即独立) |
psych函数
可以得到非缺失值的数量,平均数,标准差,中位数,截尾均值,绝对中位差,最小值,最大值,值域,偏度,峰度和平均值的标准误差.
除了上述的描述性统计之外,还有类似于pastecs包中有一个名为stat.desc()函数,但是这个函数只能计算观测值个数小于5000的数据集,我这里不推荐使用.
上述三个描述统计方式可以一起使用效果更好,psych得到的如同一个图表一样的图,非常的简洁明了,一目了然,但是其对于分类型变量的统计是有问题的,而summary函数又无法完成对于数据离散程度的比较,而Hmisc包可以得到一些其他的统计量,如基尼均差,基尼均差对于非正态型数据的适用性更好.
四、项目源码
data <- read.csv(file="E:\\RHome\\al6-2.csv",header=T,fileEncoding = "utf-8")
dat <- data[order(data[,2]),]#data[sort(data$总资产,index.return=TRUE)$ix,]也可以
library(psych)
des <- describe(dat)#屏幕上查看所有连续变量的描述统计量。
# 删除这些行
del <- which(dat$总资产>=dat[245,2])
dat_del <- dat[-del,]
des1 <- describe(dat_del)#屏幕上查看去掉异常值所有连续变量的描述统计量。
Jicha <- des1[2,9]-des1[2,8]
#区间段
a = function(){
j = 1
n=c()
for(i in seq(0, 900, by=100)){
n[j]=paste('[',i,'~',i+100,')')
j = j+1
}
return (n)
}
qjd = a()
qjd[11]=paste('[',1000,'~ +∞)')
#累积绝对频数
b = function(){
n=c(0,0,0,0,0,0,0,0,0,0,250)
num=100
m=1
i=1
for (i in seq(1, 245, by=1)) {
if(dat[i,2]>num) {
n[m]=i-1
m=m+1
num=num+100
}
}
return(n)
}
ljjd = b()
#绝对频数
d=function(){
n=c()
n[1]=ljjd[1]
for(i in seq(1,10,by=1)){
n[i+1]=ljjd[i+1]-ljjd[i]
}
return(n)
}
jd=d()
#相对频数
xd = jd/250
#累积相对频数
ljxd = ljjd/250
#数据展示
区间段=qjd
绝对频数=jd
相对频数=xd
累积绝对频数=ljjd
累积相对频数=ljxd
data_last=data.frame(区间段,绝对频数,相对频数,累积绝对频数,累积相对频数)
#数据可视化
library(gcookbook)
library(ggplot2)
barplot(data_last$相对频数,names.arg = data_last$区间段,main="相对频数的柱状图",ylim = c(0,1))
ggplot(data_last, aes(x=区间段, y=相对频数))+labs(title="相对频数的折线图")+ geom_point(size=6, shape=20)+geom_line(aes(group=""), color="black",size=1)+
theme(plot.title = element_text(hjust = 0.5))