Python 疫情数据可视化(爬虫+数据可视化)(Jupyter环境)
目录
1 项目背景
2 项目目标
3 项目分析
3.1数据获取
3.1.1分析网站
3.1.2找到数据所在url
3.1.3获取数据
3.1.4解析数据
3.1.5保存数据
3.2数据可视化
3.2.1读取数据
3.2.2各地区确诊人数与死亡人数情况条形图
3.2.3各地区现有确诊人数地图
3.2.4各地区现有确诊人数分布环形图
3.2.4各地区现有确诊人数分布折线图
项目源码:
1 项目背景
2019年底,肺炎(COVID-19)在全球爆发,后来被确认为新型冠状病毒(SARS-CoV-2)所引发的。
2 项目目标
我们在爬取到公开数据的条件下,开展了一些可视化工作希望能够帮助大家更好理解现在疫情的发展情况,更有信心一起战胜肆虐的病毒。
3 项目分析
3.1数据获取
3.1.1分析网站
先去先找到今天要爬取的目标数据:
https://news.qq.com/zt2020/page/feiyan.htm#/
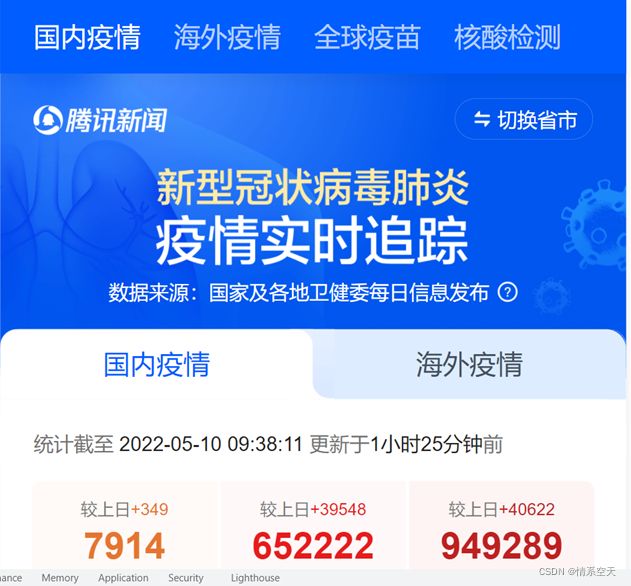
3.1.2找到数据所在url
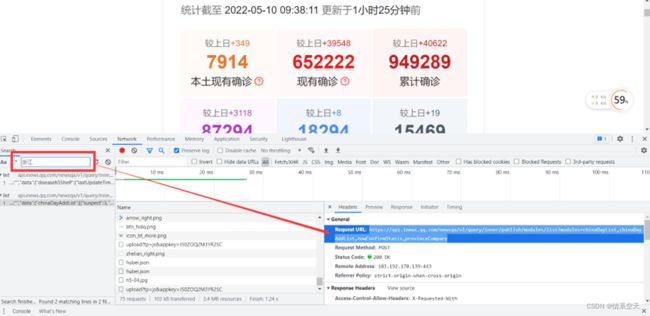
url点击跳转查看
url='https://api.inews.qq.com/newsqa/v1/query/inner/publish/modules/list?modules=statisGradeCityDetail,diseaseh5Shelf'3.1.3获取数据
通过爬虫获取它的json数据:
url='https://api.inews.qq.com/newsqa/v1/query/inner/publish/modules/list?modules=statisGradeCityDetail,diseaseh5Shelf'
response = requests.get(url, verify=False)
json_data = response.json()['data']
china_data = json_data['diseaseh5Shelf']['areaTree'][0]['children'] # 列表3.1.4解析数据
通过一个for循环对我们的列表进行取值然后再存入到我们的字典中
data_set = []
for i in china_data:
data_dict = {}
# 地区名称
data_dict['province'] = i['name']
# 新增确认
data_dict['nowConfirm'] = i['total']['nowConfirm']
# 死亡人数
data_dict['dead'] = i['total']['dead']
# 治愈人数
data_dict['heal'] = i['total']['heal']
data_set.append(data_dict)3.1.5保存数据
df = pd.DataFrame(data_set)
df.to_csv('yiqing_data.csv')

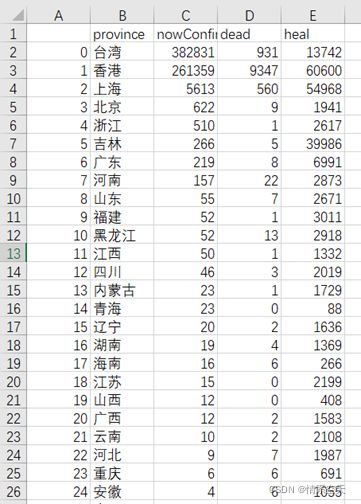
3.2数据可视化
3.2.1读取数据
df2 = df.sort_values(by=['nowConfirm'],ascending=False)[:9]
df2
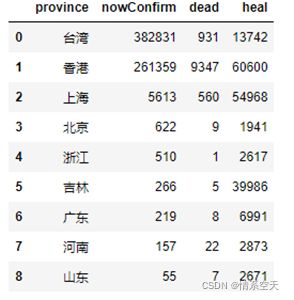
3.2.2各地区确诊人数与死亡人数情况条形图
bar = (
Bar()
.add_xaxis(list(df['province'].values)[:6])
.add_yaxis("死亡", df['dead'].values.tolist()[:6])
.add_yaxis("治愈", df['heal'].values.tolist()[:6])
.set_global_opts(
title_opts=opts.TitleOpts(title="各地区确诊人数与死亡人数情况"),
datazoom_opts=[opts.DataZoomOpts()],
)
)
bar.render_notebook()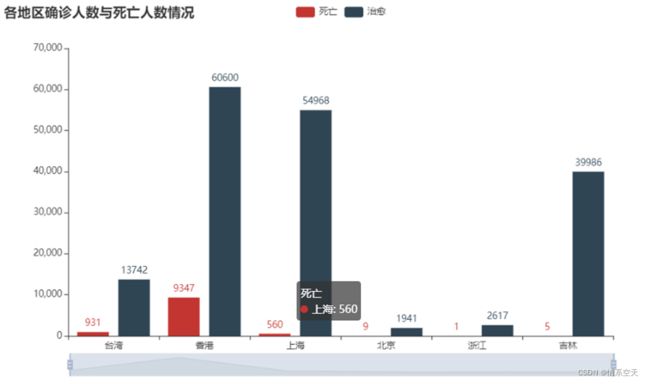
3.2.3各地区现有确诊人数地图
china_map = (
Map()
.add("现有确诊", [list(i) for i in zip(df['province'].values.tolist(),df['nowConfirm'].values.tolist())], "china")
.set_global_opts(
title_opts=opts.TitleOpts(title="各地区确诊人数"),
visualmap_opts=opts.VisualMapOpts(max_=600, is_piecewise=True),
)
)
china_map.render_notebook()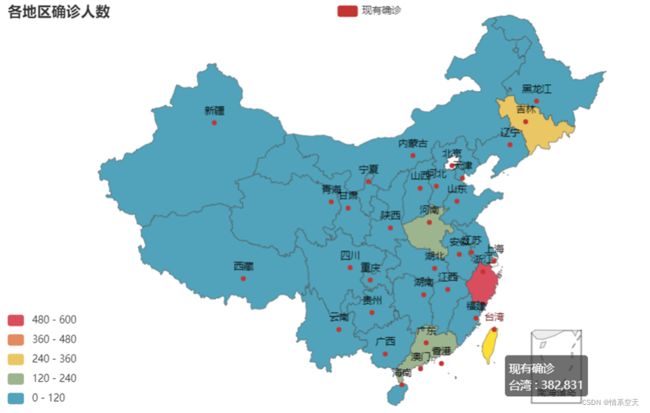
3.2.4各地区现有确诊人数分布环形图
pie = (
Pie()
.add(
"",
[list(i) for i in zip(df2['province'].values.tolist(),df2['nowConfirm'].values.tolist())],
radius = ["10%","30%"]
)
.set_global_opts(
legend_opts=opts.LegendOpts(orient="vertical", pos_top="70%", pos_left="70%"),
)
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}"))
)
pie.render_notebook()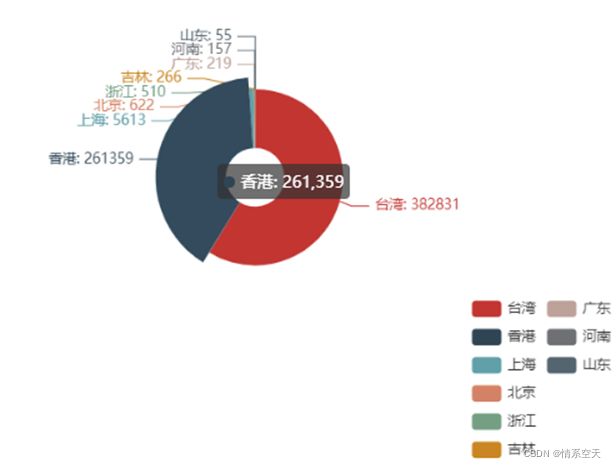
3.2.4各地区现有确诊人数分布折线图
line = (
Line()
.add_xaxis(list(df['province'].values))
.add_yaxis("治愈", df['heal'].values.tolist())
.add_yaxis("死亡", df['dead'].values.tolist())
.set_global_opts(
title_opts=opts.TitleOpts(title="死亡与治愈"),
)
)
line.render_notebook()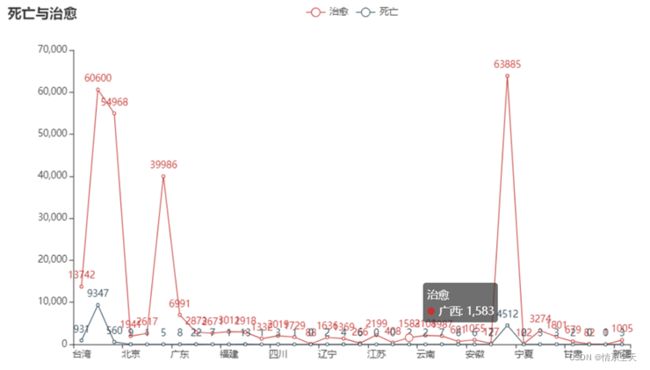
项目源码:
import requests # 发送网络请求模块
import json
import pprint # 格式化输出模块
import pandas as pd # 数据分析当中一个非常重要的模块
from pyecharts import options as opts
from pyecharts.charts import Bar,Line,Pie,Map,Grid
import urllib3
from pyecharts.globals import CurrentConfig, NotebookType
# 配置对应的环境类型
CurrentConfig.NOTEBOOK_TYPE = NotebookType.JUPYTER_NOTEBOOK
CurrentConfig.ONLINE_HOST='https://assets.pyecharts.org/assets/'
urllib3.disable_warnings()#解决InsecureRequestWarning: Unverified HTTPS request is being made to host 'api.inews.qq.com'. 问题
url = 'https://api.inews.qq.com/newsqa/v1/query/inner/publish/modules/list?modules=statisGradeCityDetail,diseaseh5Shelf'
response = requests.get(url, verify=False)
json_data = response.json()['data']
china_data = json_data['diseaseh5Shelf']['areaTree'][0]['children'] # 列表
data_set = []
for i in china_data:
data_dict = {}
# 地区名称
data_dict['province'] = i['name']
# 新增确认
data_dict['nowConfirm'] = i['total']['nowConfirm']
# 死亡人数
data_dict['dead'] = i['total']['dead']
# 治愈人数
data_dict['heal'] = i['total']['heal']
data_set.append(data_dict)
df = pd.DataFrame(data_set)
df.to_csv('yiqing_data.csv')
df2 = df.sort_values(by=['nowConfirm'],ascending=False)[:9]
df2
# bar = (
# Bar()
# .add_xaxis(list(df['province'].values)[:6])
# .add_yaxis("死亡", df['dead'].values.tolist()[:6])
# .add_yaxis("治愈", df['heal'].values.tolist()[:6])
# .set_global_opts(
# title_opts=opts.TitleOpts(title="各地区确诊人数与死亡人数情况"),
# datazoom_opts=[opts.DataZoomOpts()],
# )
# )
# bar.render_notebook()
# china_map = (
# Map()
# .add("现有确诊", [list(i) for i in zip(df['province'].values.tolist(),df['nowConfirm'].values.tolist())], "china")
# .set_global_opts(
# title_opts=opts.TitleOpts(title="各地区确诊人数"),
# visualmap_opts=opts.VisualMapOpts(max_=600, is_piecewise=True),
# )
# )
# china_map.render_notebook()
# pie = (
# Pie()
# .add(
# "",
# [list(i) for i in zip(df2['province'].values.tolist(),df2['nowConfirm'].values.tolist())],
# radius = ["10%","30%"]
# )
# .set_global_opts(
# legend_opts=opts.LegendOpts(orient="vertical", pos_top="70%", pos_left="70%"),
# )
# .set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}"))
# )
# pie.render_notebook()
line = (
Line()
.add_xaxis(list(df['province'].values))
.add_yaxis("治愈", df['heal'].values.tolist())
.add_yaxis("死亡", df['dead'].values.tolist())
.set_global_opts(
title_opts=opts.TitleOpts(title="死亡与治愈"),
)
)
line.render_notebook()