ros自己写避障算法_迷雾学术篇|视觉感知的无人机动态避障(下篇)
PartI : 开篇语
继九九度过一个为期两天的假日(宅宿舍)之后,终得时间来补一下视觉感知的无人机动态避障的下篇。本篇将在上篇机器视觉技术概念的基础上对无人机的动态避障问题描述和具体的技术流程进行展开,最后进行总结和展望。
PartII : 动态避障问题描述
无人机动态避障的主要目的在于让无人机实时感知周围障碍物的位置和速度(世界位置和速度),且障碍物速度不为零。相比静态避障的核心区别在于,无人机需要实时对障碍物位置进行预测,提前产生控制量,从而躲避障碍物。
静态障碍物
障碍物位置和形状无法改变;
障碍物易于被探测。
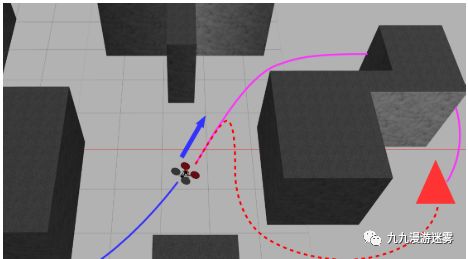
动态障碍物
位置和特性处于变化之中;
难以在较短时间做出反应。

那么无人机动态避障的的问题描述就是
U = Optimal(@(U) cost(U,x,U_p,Env,vehicle),U_ini,[],[],[],[],LB,UB, @(U) con(U,x,Env,vehicle),options)% min cost(U,x,U_p,Env,vehicle)% st. con(U,x,Env,vehicle)即,在满足约束条件和避障条件下,使得以时间和能量为变量的代价函数最小。
PartIII : 技术流程

事件相机和障碍物检测
根据相机事件信息检测到周围移动障碍物的存在。主要的算法就是相机事件生成,即计算不同帧像素强度差异,然后根据时间戳计算滑动窗口内的差异平均值,进行滤波,根据强度差异的正负值生成正事件和负事件,最后得到正事件所表征的移动障碍物。
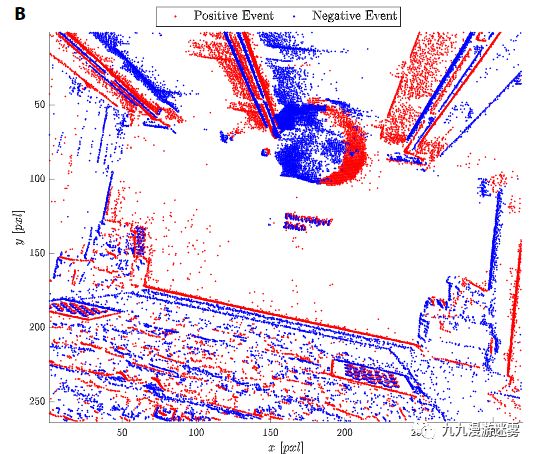
基于IMU的运动补偿
基于惯性测量组件(IMU)进行运动补偿,即根据特征点在图像的投影位置和IMU的积分信息估计无人机自身位置。自我运动估计和补偿是视觉定位(Visual Odometry)的核心问题,也是机器视觉研究的一个热点。
VO也叫序列SFM(Structure From Motion),VO用于增量式计算相机的运动轨迹,由于相机固定在无人机或载体上,相机的运动状态即载体的运动状态。
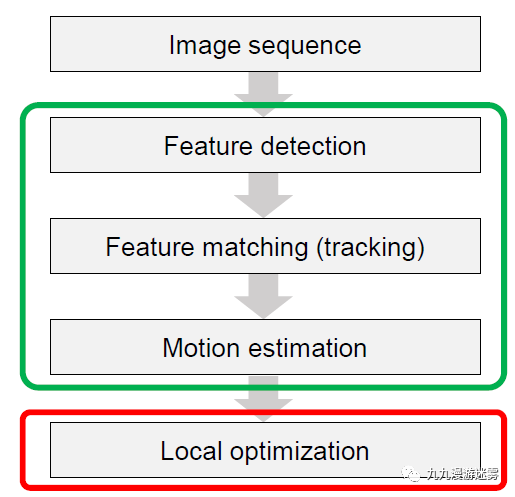
首先获取图像序列,然后进行特征点检测。特征点一般是转角或者圆形边界,需要对变形、旋转、移动、照明具有不变性。最常用的特征点检测有SIFT(Scale-invariant feature transform),即从一组参考图像中提取对象的SIFT关键点,并将其存储在数据库中。特征点检测完成之后需要对不同图像序列的特征点进行匹配,一般采用相似算法找到最为匹配的点,相似算法主要最小或最大不同像素之间的NCC,SSD,SAD,Census Transform 和 Hamming distance等相似测量。

有了相机移动造成的特征点在图像上的移动,就可以根据投影方程计算相机的外部参数(external parameters),即位移和旋转(R,T)。
单目视觉

双目视觉
最后进行局部优化,使得所有利用物体在图像上的投影反向计算的位置和实际位置距离方差和最小,即得到相机的运动轨迹。

- 障碍物分割
在对上一个时间窗口中触发的事件执行自我运动补偿后,我们获得了一个场景,其中包含属于场景动态部分的事件的位置,在此步骤中仅提取其中动态部分,对静态部分不做处理。
- 基于光流速度估计
图像点的密度及其在图像平面中的距离取决于对象的速度,到传感器的距离及其整体大小。由于仅具有自我运动补偿产生的平均时间戳信息和图像位置无法有效地聚类来自不同视觉传感器具有与动态物体不同的速度和距离的物体的图像点,因此需要采用光流传感器来估计运动物体的速度,从而对运动进行估计,这个速度也是之后排除力函数的一个重要参数。
组合聚类算法
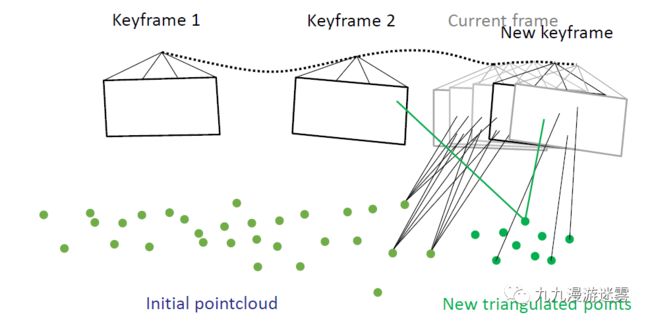
聚类是为了让具备同样运动特征的图像点形成一个物体,例如运动的足球。为了最大化聚类的准确性,我们使用所有可用的数据信息,文中所用的聚类算法是Density-based spatial clustering of applications with noise(DBSCAN) algorithm,通过利用运动估计得到的位置,事件时间戳和光流传感器得到的速度信息来对像素点进行聚类,从而得到运动物体。
3D位置估计
图像到世界坐标变换
障碍物速度估计
势能场函数和推力
势能场函数包括排斥力和吸引力函数。排斥力势能场主要根据无人机位置和实时捕获的障碍物位置之间的距离生成一个势能场函数,而吸引力势能场则是根据目标点和无人机位置之间的距离生成。根据势能场的导数即可生成相应的推力和速度。通过这样的方法,无人机就可以保证在避障的同时到达期望的目标位置。


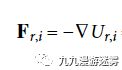
实验结果
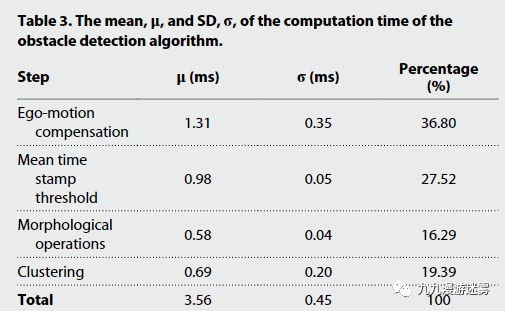
处理时间
成功率

PartIV: 软硬件配置

文中所使用的硬件主要包括:
- 主机架是6′′Lumenier QAV-RXL
- 6′′三叶螺旋桨
- Cobra CM2208-2000无刷电动机
- 两台机载计算机:(i)Qualcomm Snapdragon Flight,用于使用提供的Machine Vision SDK进行基于视觉的单眼状态估计;(ii)NVIDIA Jetson TX2,以及AUVIDEA J90载板,可运行所有其他软件堆栈。
- Lumenier F4 AIO飞行控制器
- DYS Aria 35a电机控制器代码基于ROS开发和运行。
PartV: 总结
本篇主要对基于事件相机的视觉感知动态避障的主要 技术实现 进行了描述,基于事件相机的动态避障相比标准相机具备 低时延 和 快速响应 能力,但在处理重叠事件时仍存在较大问题,特别是密度环境中的避障。同时文中并未涉及较为复杂的全局路径生成而是以局部势能场函数的导数来计算推力大小和方向,在减少计算量的同时也存在一定局限性 。 总之,本文给动态避障提供了一种快速安全鲁棒的方法,从目标检测到指令生成都是有相当大的创新性和实用性,也期待在视觉感知的无人机动态避障的研究领域出现更多实用性方法和框架。 敬请关注。点击