pandas学习笔记之DateFrame
pandas学习笔记之DateFrame
文章目录
- pandas学习笔记之DateFrame
-
-
- 1.DateFrame的创建
-
- 1)认识DataFrame对象
- 2)由二维列表创建(默认index和columns值)
- 指定索引ndex 和 columns值:
- 3)由元组tuple组成的列表
- 4)由字典dict组成的列表
- 5)由数组array组成的列表
- 6)由序列series组成的列表
-
- 第一种
- 第二种
- 2.DataFrame的数据查看
-
- 1)行索引查看数据
-
- ①使用.loc方法进行选取行
- ②使用.iloc方法进行选取行
- 2)列索引查看数据
-
- 通过名称直接选取列
- 3)数据表信息查看
- 3.DataFram数据表的处理
-
- 1)对行进行增添与删除
-
- ①添加数据行
- ②删除数据行
- 2)对列进行增添与删除
-
- 列索引添加数据列
-
- ①使用 columns 列索引表标签可以实现添加新的数据列
- ②使用 insert() 方法插入新的列
- 列索引删除数据列
- 3)对数据表中缺失值的处理
-
- ①检测
- ②删除
- ③填充
- 4)数据表的和并
- 5)DataFrame的分组求和
-
- ①groupby()进行分组
- ②agg()函数进行聚合运算
- 6)对DataFrame的某一列进行排序
-
- ①按索引排序df.sort_index()
- ②按数值排序df.sort_values()
- 4.读取文档文件
-
- 1、pandas读取xlsx、xls文件
- 2、pandas读取csv文件
- 2、pandas读取csv文件
-
1.DateFrame的创建
1)认识DataFrame对象
import pandas as pd
pd.DataFrame( data, index, columns, dtype, copy)
| 参数名称 | 说明 |
|---|---|
| data | 输入的数据,可以是 ndarray,series,list,dict,标量以及一个 DataFrame。 |
| index | 行标签,如果没有传递 index 值,则默认行标签是 np.arange(n),n 代表 data 的元素个数。 |
| columns | 列标签,如果没有传递 columns 值,则默认列标签是 np.arange(n)。 |
| dtype | dtype表示每一列的数据类型。 |
| copy | 默认为 False,表示复制数据 data。 |
2)由二维列表创建(默认index和columns值)
import pandas as pd
data = [['张三', 23, '男'], ['李四', 27, '女'], ['王二', 26, '女']]
df = pd.DataFrame(data)
print(df)
输出:
0 1 2
0 张三 23 男
1 李四 27 女
2 王二 26 女
指定索引ndex 和 columns值:
import pandas as pd
data = [['张三', 23, '男'], ['李四', 27, '女'], ['王二', 26, '女']]
df = pd.DataFrame(data, columns=['姓名', '年龄', '性别'], index=['a', 'b', 'c'])
print(df)
输出:
姓名 年龄 性别
a 张三 23 男
b 李四 27 女
c 王二 26 女
3)由元组tuple组成的列表
import pandas as pd
data = [('张三', 23, '男'), ('李四', 27, '女'), ('王二', 26, '女')]
df = pd.DataFrame(data, columns=['姓名', '年龄', '性别'], index=['a', 'b', 'c'])
print(df)
输出:
姓名 年龄 性别
a 张三 23 男
b 李四 27 女
c 王二 26 女
4)由字典dict组成的列表
import pandas as pd
data = [
{'姓名': '张三', '年龄': 23, '性别': '男'},
{'姓名': '李四', '年龄': 27, '性别': '男'},
{'姓名': '王二', '年龄': 26}
]
# 缺少的值自动添加NaN
df = pd.DataFrame(data)
print(df)
输出:
姓名 年龄 性别
0 张三 23 男
1 李四 27 男
2 王二 26 NaN
5)由数组array组成的列表
import pandas as pd
import numpy as np
data = [
np.array(('张三', 23, '男')),
np.array(('李四', 27, '女')),
np.array(('王二', 26, '女'))
]
df = pd.DataFrame(data, columns=['姓名', '年龄', '性别'])
print(df)
输出:
姓名 年龄 性别
0 张三 23 男
1 李四 27 女
2 王二 26 女
6)由序列series组成的列表
第一种
import pandas as pd
data = [
pd.Series(['张三', '李四', '王二'], index=['a', 'b', 'c']),
pd.Series([23, 27], index=['a', 'b']),
pd.Series(['男', '女', '女'], index=['a', 'b', 'c'])
]
# 序列里的index作为dataframe表的columns索引
# 缺少值自动添加NaN
df = pd.DataFrame(data, index=['姓名', '年龄', '性别'])
print(df)
输出:
a b c
姓名 张三 李四 王二
年龄 23.0 27.0 NaN
性别 男 女 女
第二种
import pandas as pd
data = {
'姓名': pd.Series(['张三', '李四', '王二'], index=['a', 'b', 'c']),
'年龄': pd.Series([23, 27], index=['a', 'b'])
}
# 序列里的index作为dataframe表的index索引
# 字典里的key作为dataframe表的columns索引
df = pd.DataFrame(data)
print(df)
输出:
姓名 年龄
a 张三 23.0
b 李四 27.0
c 王二 NaN
2.DataFrame的数据查看
1)行索引查看数据
①使用.loc方法进行选取行
- .loc[ 行索引, 列索引]方法使用的是对行名称进行选取
df = pd.DataFrame([[1, 2], [4, 5], [7, 8]],
index=['cobra', 'viper', 'sidewinder'],
columns=['max_speed', 'shield'])
print(df.loc['viper'])
输出:
max_speed 4
shield 5
Name: viper, dtype: int64
- 可以使用切片,切片包含末尾值
import pandas as pd
df = pd.DataFrame([[1, 2], [4, 5], [7, 8]],
index=['cobra', 'viper', 'sidewinder'],
columns=['max_speed', 'shield'])
print(df)
print(df.loc['viper':'sidewinder'])
输出:
max_speed shield
viper 4 5
sidewinder 7 8
- 可以使用boll值进行选取
import pandas as pd
df = pd.DataFrame([[1, 2], [4, 5], [7, 8]],
index=['cobra', 'viper', 'sidewinder'],
columns=['max_speed', 'shield'])
print(df)
print(df.loc[df['shield'] > 4])
输出:
max_speed shield
viper 4 5
sidewinder 7 8
②使用.iloc方法进行选取行
df.iloc[row_index位置, column_index位置]方法是对于位置进行选取
import pandas as pd
df = pd.DataFrame([[1, 2], [4, 5], [7, 8]],
index=['cobra', 'viper', 'sidewinder'],
columns=['max_speed', 'shield'])
print(df.iloc[[0,1]])
输出:
max_speed shield
cobra 1 2
viper 4 5
2)列索引查看数据
通过名称直接选取列
import pandas as pd
df = pd.DataFrame([[1, 2], [4, 5], [7, 8]],
index=['cobra', 'viper', 'sidewinder'],
columns=['max_speed', 'shield'])
print(df['max_speed'])
输出:
cobra 1
viper 4
sidewinder 7
Name: max_speed, dtype: int64
3)数据表信息查看
| 参数名称 | 说明 |
|---|---|
| df.shape | 维度查看 |
| df.info() | 数据表基本信息(维度、列名称、数据格式、所占空间等) |
| df.dtypes | 每一列数据的格式 |
| df[‘B’].dtype | 某一列格式 |
| df.isnull() | 空值 |
| df[‘B’].isnull() | 查看某一列空值 |
| df[‘B’].unique() | 查看某一列的唯一值 |
| df.values | 查看数据表的值 |
| df.columns | 查看列名称 |
| df.head() #默认前5行数据 | 查看前5行数据 |
| df.tail() #默认后5行数据 | 查看后5行数据 |
3.DataFram数据表的处理
1)对行进行增添与删除
①添加数据行
使用 append() 函数,可以将新的数据行添加到 DataFrame 中,该函数会在行末追加数据行。
import pandas as pd
df = pd.DataFrame([[1, 2], [3, 4]], columns = ['a','b'])
df2 = pd.DataFrame([[5, 6], [7, 8]], columns = ['a','b'])
#在行末追加新数据行
df = df.append(df2)
print(df)
输出:
a b
0 1 2
1 3 4
0 5 6
1 7 8
②删除数据行
可以使用行索引标签,从 DataFrame 中删除某一行数据。如果索引标签存在重复,那么它们将被一起删除。
import pandas as pd
df = pd.DataFrame([[1, 2], [3, 4]], columns = ['a','b'])
df2 = pd.DataFrame([[5, 6], [7, 8]], columns = ['a','b'])
df = df.append(df2)
print(df)
#注意此处调用了drop()方法
df = df.drop(0)
print (df)
输出:
执行drop(0)前:
a b
0 1 2
1 3 4
0 5 6
1 7 8
执行drop(0)后:
a b
1 3 4
1 7 8
2)对列进行增添与删除
列索引添加数据列
①使用 columns 列索引表标签可以实现添加新的数据列
import pandas as pd
d = {'one' : pd.Series([1, 2, 3], index=['a', 'b', 'c']),
'two' : pd.Series([1, 2, 3, 4], index=['a', 'b', 'c', 'd'])}
df = pd.DataFrame(d)
#使用df['列']=值,插入新的数据列
df['three']=pd.Series([10,20,30],index=['a','b','c'])
print(df)
#将已经存在的数据列做相加运算
df['four']=df['one']+df['three']
print(df)
输出:
使用列索引创建新数据列:
one two three
a 1.0 1 10.0
b 2.0 2 20.0
c 3.0 3 30.0
d NaN 4 NaN
已存在的数据列做算术运算:
one two three four
a 1.0 1 10.0 11.0
b 2.0 2 20.0 22.0
c 3.0 3 30.0 33.0
d NaN 4 NaN NaN
②使用 insert() 方法插入新的列
import pandas as pd
info=[['Jack',18],['Helen',19],['John',17]]
df=pd.DataFrame(info,columns=['name','age'])
print(df)
#注意是column参数
#数值1代表插入到columns列表的索引位置
df.insert(1,column='score',value=[91,90,75])
print(df)
输出:
添加前:
name age
0 Jack 18
1 Helen 19
2 John 17
添加后:
name score age
0 Jack 91 18
1 Helen 90 19
2 John 75 17
列索引删除数据列
通过 del 和 pop() 都能够删除 DataFrame 中的数据列
import pandas as pd
d = {'one' : pd.Series([1, 2, 3], index=['a', 'b', 'c']),
'two' : pd.Series([1, 2, 3, 4], index=['a', 'b', 'c', 'd']),
'three' : pd.Series([10,20,30], index=['a','b','c'])}
df = pd.DataFrame(d)
print ("Our dataframe is:")
print(df)
#使用del删除
del df['one']
print(df)
#使用pop方法删除
df.pop('two')
print (df)
输出:
原DataFrame:
one three two
a 1.0 10.0 1
b 2.0 20.0 2
c 3.0 30.0 3
d NaN NaN 4
使用del删除 first:
three two
a 10.0 1
b 20.0 2
c 30.0 3
d NaN 4
使用 pop()删除:
three
a 10.0
b 20.0
c 30.0
d NaN
3)对数据表中缺失值的处理
数据例子:
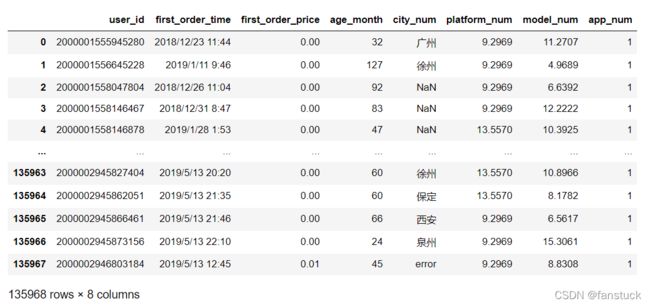
①检测
可以使用df.isnull()函数显示空值

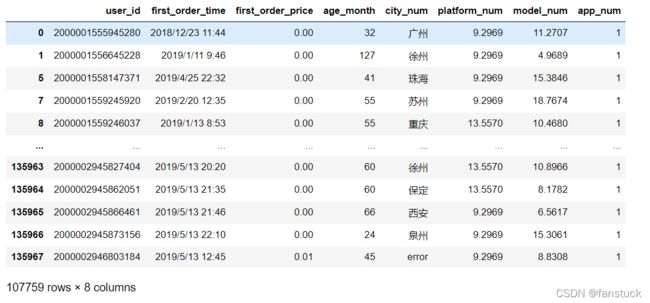
②删除
运用df.dropna()的方法
DataFrame.dropna(axis=0, how='any', thresh=None, subset=None, inplace=False)
参数说明:
axis:指定的轴,默认为0也就是参照对每行进行操作,1就为列。
how:可以为any也可以为all,对整体或者部分进行操作。
thresh:一行或一列中至少出现了多少个空值才删除。
subset:在某些列的子集中选择出现了缺失值的列删除,不在子集中的含有缺失值得列或行不会删除(有axis决定是行还是列)
inplace:是否替换原数据集。
实际操作:
df1.dropna(axis=0,how='any',inplace=False)
③填充
运用df.fillna()的方法
DataFrame.fillna(value=None, method=None, axis=None, inplace=False, limit=None, downcast=None)
参数说明:
value:将空值替换成任意设定的值
method:method参数的取值 : {‘pad’, ‘ffill’,‘backfill’, ‘bfill’, None}, default None
ffill:用缺失值前面的一个值代替缺失值,如果axis =1,那么就是横向的前面的值替换后面的缺失值,如果axis=0,那么则是上面的值替换下面的缺失值。backfill/bfill,缺失值后面的一个值代替前面的缺失值。注意这个参数不能与value同时出现。
向上填充method=‘ffill’、向下填充method=‘bfill’,
axis:指定改变的轴,默认为0也就是对每行操作。
inplace:是否替换原数据集。
limit参数:限制填充个数。
4)数据表的和并
pd.concat(objs, axis=0, join='outer', join_axes=None, ignore_index=False,
keys=None, levels=None, names=None, verify_integrity=False,
copy=True)
objs︰ 一个序列或系列、 综合或面板对象的映射。如果字典中传递,将作为键参数,使用排序的键,除非它传递,在这种情况下的值将会选择
(见下文)。任何没有任何反对将默默地被丢弃,除非他们都没有在这种情况下将引发 ValueError。
axis: {0,1,…},默认值为 0。要连接沿轴。
join: {‘内部’、 ‘外’},默认 ‘外’。如何处理其他 axis(es) 上的索引。联盟内、 外的交叉口。
ignore_index︰ 布尔值、 默认 False。如果为 True,则不要串联轴上使用的索引值。由此产生的轴将标记
0,…,n-1。这是有用的如果你串联串联轴没有有意义的索引信息的对象。请注意在联接中仍然受到尊重的其他轴上的索引值。
join_axes︰ 索引对象的列表。具体的指标,用于其他 n-1 轴而不是执行内部/外部设置逻辑。 keys︰
序列,默认为无。构建分层索引使用通过的键作为最外面的级别。如果多个级别获得通过,应包含元组。
levels︰ 列表的序列,默认为无。具体水平 (唯一值) 用于构建多重。否则,他们将推断钥匙。
names︰ 列表中,默认为无。由此产生的分层索引中的级的名称。
verify_integrity︰ 布尔值、 默认 False。检查是否新的串联的轴包含重复项。这可以是相对于实际数据串联非常昂贵。
例子:1.frames = [df1, df2, df3]
2.result = pd.concat(frames)
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-zL4f3Es6-1667044558536)(https://gitee.com/yuan6222/images/raw/master/20180611091426153)]
5)DataFrame的分组求和
①groupby()进行分组
给groupby()传入一个列表,列表中的元素为分类字段,从左到右分类级别增大。(一级分类、二级分类…)
import pandas as pd
data = [['a', 'A', 109], ['b', 'B', 112], ['c', 'A', 125], ['d', 'C', 120],
['e', 'C', 126], ['f', 'B', 133], ['g', 'A', 124], ['h', 'B', 134],
['i', 'C', 117], ['j', 'C', 128]]
index = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
columns = ['name', 'class', 'num']
df = pd.DataFrame(data=data, index=index, columns=columns)
print(df)
print("=================================================")
df1 = df.groupby('class').sum() # 分组统计求和
print(df1)
输出:
name class num
0 a A 109
1 b B 112
2 c A 125
3 d C 120
4 e C 126
5 f B 133
6 g A 124
7 h B 134
8 i C 117
9 j C 128
=================================================
num
class
A 358
B 379
C 491
②agg()函数进行聚合运算
使用groupby()函数和agg()函数 实现 分组聚合操作运算
import pandas as pd
data = [['a', 'A', '1等', 109, 144], ['b', 'C', '1等', 112, 132], ['c', 'A', '1等', 125, 137], ['d', 'B', '2等', 120, 121],
['e', 'B', '1等', 126, 136], ['f', 'B', '2等', 133, 127], ['g', 'C', '2等', 124, 126], ['h', 'A', '1等', 134, 125],
['i', 'C', '2等', 117, 125], ['j', 'A', '2等', 128, 133], ['h', 'B', '1等', 130, 122], ['i', 'C', '2等', 122, 111]]
index = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11]
columns = ['name', 'class_1', 'class_2', 'num1', 'num2']
df = pd.DataFrame(data=data, index=index, columns=columns)
print(df)
print("===============================")
df1 = df[['class_1', 'class_2', 'num1', 'num2']]
print(df1.groupby(['class_1', 'class_2']).agg(['mean', 'sum']))
输出:
num1 num2
mean sum mean sum
class_1 class_2
A 1等 122.666667 368 135.333333 406
2等 128.000000 128 133.000000 133
B 1等 128.000000 256 129.000000 258
2等 126.500000 253 124.000000 248
C 1等 112.000000 112 132.000000 132
2等 121.000000 363 120.666667 362
对不同列使用不同聚合函数:给agg()方法传入一个字典
import pandas as pd
data = [['a', 'A', '1等', 109, 144], ['b', 'C', '1等', 112, 132], ['c', 'A', '1等', 125, 137], ['d', 'B', '2等', 120, 121],
['e', 'B', '1等', 126, 136], ['f', 'B', '2等', 133, 127], ['g', 'C', '2等', 124, 126], ['h', 'A', '1等', 134, 125],
['i', 'C', '2等', 117, 125], ['j', 'A', '2等', 128, 133], ['h', 'B', '1等', 130, 122], ['i', 'C', '2等', 122, 111]]
index = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11]
columns = ['name', 'class_1', 'class_2', 'num1', 'num2']
df = pd.DataFrame(data=data, index=index, columns=columns)
print(df)
print("===============================")
df1 = df[['class_1', 'num1', 'num2']]
print(df1.groupby('class_1').agg({'num1': ['mean', 'sum'], 'num2': ['sum']}))
输出:
num1 num2
mean sum sum
class_1
A 124.00 496 539
B 127.25 509 506
C 118.75 475 494
6)对DataFrame的某一列进行排序
若要降序排序则应该添加参数 ascending=False
①按索引排序df.sort_index()
原始数据:
import pandas as pd
data = {
'brand': ['C', 'PHP', 'c++', 'Python', 'Java'],
'B': [4, 6, 8, 12, 10],
'A': [10, 2, 5, 20, 16],
'D': [6, 18, 14, 6, 12],
'years': [4, 1, 1, 30, 30],
'C': [8, 12, 18, 8, 2],
}
index = [9, 3, 4, 5, 2]
df = pd.DataFrame(data=data, index=index)
print(df)
输出:
brand B A D years C
9 C 4 10 6 4 8
3 PHP 6 2 18 1 12
4 c++ 8 5 14 1 18
5 Python 12 20 6 30 8
2 Java 10 16 12 30 2
进行排序:
df.sort_index()
输出:
brand B A D years C
2 Java 10 16 12 30 2
3 PHP 6 2 18 1 12
4 c++ 8 5 14 1 18
5 Python 12 20 6 30 8
9 C 4 10 6 4 8
②按数值排序df.sort_values()
df.sort_values('B')
输出:
brand B A D years C
9 C 4 10 6 4 8
3 PHP 6 2 18 1 12
4 c++ 8 5 14 1 18
2 Java 10 16 12 30 2
5 Python 12 20 6 30 8
可同时进行多列进行排序,当第一个列中的参数相等时则根据第二个列进行排序
df.sort_values(['years','B'])
输出:
brand B A D years C
3 PHP 6 2 18 1 12
4 c++ 8 5 14 1 18
9 C 4 10 6 4 8
2 Java 10 16 12 30 2
5 Python 12 20 6 30 8
4.读取文档文件
1、pandas读取xlsx、xls文件
import pandas as pd
data=pd.read_excel('path',sheetname='sheet1',header=0,names=['第一列','第二列','第三列'])
path:要读取的文件的绝对路径
sheetname:指定读取excel中的哪一个工作表,默认sheetname=0,即默认读取excel中的第一个工作表
若sheetname = ‘sheet1’,即读取excel中的sheet1工作表;
header:用作列名的行号,默认为header=0
若header=None,则表明数据中没有列名行
若header=0,则表明第一行为列名
2、pandas读取csv文件
import pandas as pd
data=pd.read_csv('path',sep=',',header=0,names=["第一列","第二列","第三列"],encoding='utf-8')
path: 要读取的文件的绝对路径
sep:指定列和列的间隔符,默认sep=’,’
若sep=’’\t",即列与列之间用制表符\t分割,相当于tab——四个空格
header:列名行,默认为0
names:列名命名或重命名
encoding:指定用于unicode文本编码格式
4 8
2 Java 10 16 12 30 2
5 Python 12 20 6 30 8
### 4.读取文档文件
#### 1、pandas读取xlsx、xls文件
```python
import pandas as pd
data=pd.read_excel('path',sheetname='sheet1',header=0,names=['第一列','第二列','第三列'])
path:要读取的文件的绝对路径
sheetname:指定读取excel中的哪一个工作表,默认sheetname=0,即默认读取excel中的第一个工作表
若sheetname = ‘sheet1’,即读取excel中的sheet1工作表;
header:用作列名的行号,默认为header=0
若header=None,则表明数据中没有列名行
若header=0,则表明第一行为列名
2、pandas读取csv文件
import pandas as pd
data=pd.read_csv('path',sep=',',header=0,names=["第一列","第二列","第三列"],encoding='utf-8')
path: 要读取的文件的绝对路径
sep:指定列和列的间隔符,默认sep=’,’
若sep=’’\t",即列与列之间用制表符\t分割,相当于tab——四个空格
header:列名行,默认为0
names:列名命名或重命名
encoding:指定用于unicode文本编码格式