Pandas之 DateFrame
DataFrame是一个表格型的数据结构,它包含一组有序的列,每列可以是不同的值的类型。
DataFrame 有行索引也有列索引,它可以被看作由Series组成的字典
import pandas as pd
data = {
import pandas as pd
data = {
'name':['张三','李四','王五','小明'],
'sex':['female','female','male','male'],
'year':[2001,2001,2003,2002],
'city':['北京','上海','广州','北京']
}
df1 =pd.DataFrame(data, columns=['name','year','sex','city'])
display(df1)运行结果

构建DataFrame的方式有很多,最常用的是直接传入一个由等长列表或NumPy数组组成的字典来构建DataFrame。
DataFrame会自动加上索引和Series一样,并且全部列会被有序排列,如果指定了列序列,DateFrame的列会按照指定顺序进行排列。 跟Series一样,如果传入的列在数据中找不到,就会产生NaN值
重建索引时填充缺失值。
对于顺序数据,比如时间序列,重新索引时可能需要进行插值或填值处理,利用参数method选项可以设置:
Ø method = ‘ffill’或‘pad’,表示前向值填充
Ø method = ‘bfill’或‘backfill’,表示后向值填充
import pandas as pd
obj = pd.Series([7.2,-3,3.5,3.6],index = ['b','a','d','c'])
obj.reindex(['a','b','c','d','e'],fill_value= 0)
重建索引:
import pandas as pd
obj = pd.Series([7.2,-3,3.5,3.6],index = ['b','a','d','c'])
obj.reindex(['a','b','c','d','e'])结果:
df3 = df1.set_index('city') display(df3)

缺失值的向前填充
import numpy as np
obj1 = pd.Series(['blue','red','blak'],index=[0,2,4])
obj1.reindex(np.arange(6),method='ffill')结果: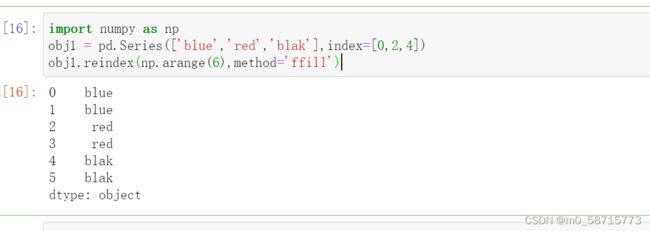
DataFrame数据
df2 = pd.DataFrame(np.arange(9).reshape(3,3),
index =['a','c','d'],columns = ['one','two','four'])
display(df2)
df2.reindex(index = ['a','b','c','d'],columns = ['one','two','three','four']) 结果: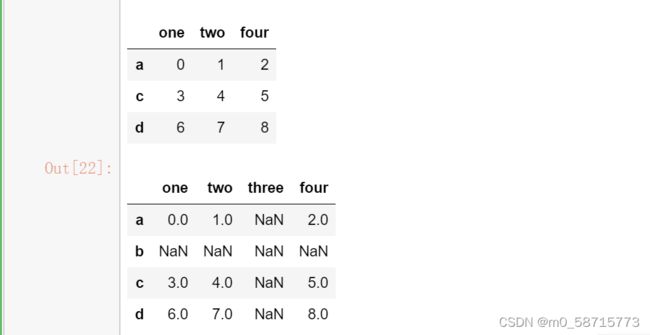
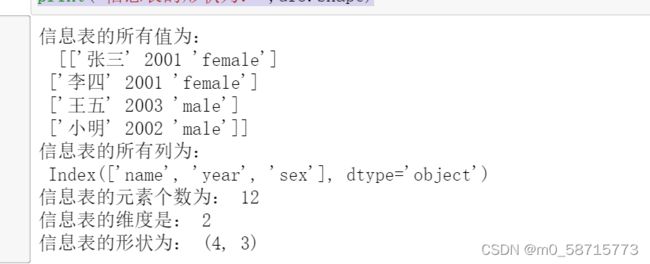
print('信息表的所有值为:\n ',df3.values)
print('信息表的所有列为:\n',df3.columns)
print('信息表的元素个数为:',df3.size)
print('信息表的维度是:',df3.ndim)
print('信息表的形状为:',df3.shape)