gpt 语言模型
1.简介 (1. Introduction)
If you have been following the recent developments in the NLP space, then it would be almost impossible to avoid the GPT-3 hype in the last few months. It all started with researchers in OpenAl researchers publishing their paper “Language Models are few Shot Learners” which introduced the GPT-3 family of models.
如果您一直关注NLP领域的最新发展,那么在过去的几个月中避免GPT-3的炒作几乎是不可能的。 一切始于OpenAl研究人员的研究,他们发表了论文“语言模型是很少的镜头学习者”,其中介绍了GPT-3系列模型。
GPT-3’s size and language capabilities are breathtaking, it can create fiction, develop program code, compose thoughtful business memos, summarize text and much more. Its possible use cases are limited only by our imaginations. What makes it fascinating is that the same algorithm can perform a wide range of tasks. At the same time there is widespread misunderstanding about the nature and risks of GPT-3’s abilities.
GPT-3的大小和语言功能令人叹为观止,它可以创建小说,开发程序代码,撰写周到的业务备忘录,摘要文本等等。 它的可能用例仅受我们的想象力限制。 令人着迷的是,同一算法可以执行各种各样的任务。 同时,人们对GPT-3的性质和风险存在广泛的误解。
To better appreciate the powers and limitations of GPT-3, one needs some familiarity with pre-trained NLP models which came before it. Table below compares some of the prominent pre-trained models:
为了更好地了解GPT-3的功能和局限性,需要熟悉GPT-3之前的预训练NLP模型。 下表比较了一些著名的预训练模型:

Let’s look at some of the common characteristics of the pre-trained NLP models before GPT-3:
让我们看一下GPT-3之前的预训练NLP模型的一些共同特征:
i) NLP Pre-Trained models are based on Transformer Architecture
i) NLP预训练模型基于变压器架构
Most of the pre-trained models belong to the Transformer family that use Attention techniques;These models can be divided into four categories:
大部分经过预训练的模型都属于使用Attention技术的Transformer系列;这些模型可以分为四类:
ii)Different models for different tasks
ii)用于不同任务的不同模型
The focus has been on creating customized models for various NLP tasks. So we have different pre-trained model for separate NLP tasks like Sentiment Analysis, Question Answering, Entity Extraction etc.
重点一直放在为各种NLP任务创建定制模型。 因此,对于单独的NLP任务(例如情感分析,问题回答,实体提取等),我们有不同的预训练模型。
iii). Fine-tuning of pre-trained model for improved performance
iii)。 对预训练模型进行微调以提高性能
For each task the pre-trained model needs to be fine-tuned to customize it to the data at hand. Fine-tuning involves gradient updates for the respective pre-trained model and the updated weights were then stored for making predictions on respective NLP tasks
对于每个任务,都需要对预训练的模型进行微调,以针对手头的数据进行定制。 微调涉及各个预训练模型的梯度更新,然后存储更新的权重以对各个NLP任务进行预测
iv) Dependency of fine-tuning on large datasets
iv) 对大型数据集进行微调的依赖性
Fine-tuning models requires availability of large custom labeled data. This has been a bottleneck when it comes to extension of Pre-trained model to new domains where labeled data is limited.
微调模型需要使用大量自定义标签数据。 当将预训练模型扩展到标签数据受限的新域时,这是一个瓶颈。
v) Focus was more on architectural improvements rather than size
v) 重点更多是架构改进,而不是规模
While one saw the emergence of new pre-trained models in a short span, the larger focus has been on bringing architectural improvements or training on different datasets to widen the net of NLP applications.
尽管人们在短期内看到了新的预训练模型的出现,但更大的重点是对体系结构进行了改进或对不同数据集进行了训练,以扩大NLP应用的范围。
2. GPT-3-快速概述 (2. GPT-3 -Quick Overview)
Key facts about GPT-3:
有关GPT-3的主要事实:
- Models: GPT-3 has eight different models with sizes ranging from 125 million to 175 billion parameters. 型号:GPT-3有八种不同的型号,参数的大小从1.25亿到1,750亿不等。
- Model Size: The largest GPT-3 model has 175 billion parameter. This is 470 times bigger than the largest BERT model (375 million parameters) 型号大小:最大的GPT-3型号参数为1750亿。 这是最大的BERT模型(3.75亿个参数)的470倍
- Architecture: GPT-3 is an Autoregressive model and follows a decoder only architecture. It is trained using next word prediction objective 体系结构:GPT-3是一种自回归模型,遵循仅解码器的体系结构。 使用下一个单词预测目标进行训练
- Learning: GPT-3 learns through Few Shots and there is no Gradient updates while learning 学习:GPT-3通过少量射击学习,学习时没有渐变更新
- Training Data Needed: GPT-3 needs less training data. It can learn from very less data and this enables its application on domains having less data 所需的培训数据:GPT-3需要较少的培训数据。 它可以从很少的数据中学习,这使其可以在数据较少的域中应用
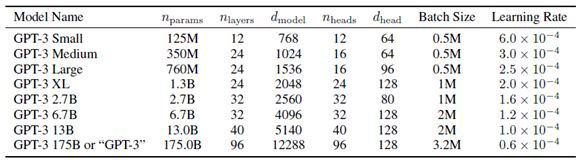
Sizes, architectures, and learning hyper-parameters of the GPT 3 models
GPT 3模型的大小,架构和学习超参数
Key design assumptions in GPT 3 model:
GPT 3模型中的关键设计假设:
(i) Increase in model size and training on larger data can lead to improvement in performance
(i)增加模型大小并接受大数据训练可提高性能
(ii) A single model can provide good performance on a host of NLP tasks.
(ii)单个模型可以在许多NLP任务上提供良好的性能。
(iii) Model can infer from new data without the need for fine-tuning
(iii)模型可以从新数据推断而无需进行微调
(iv) The model can solve problems on datasets it has never been trained upon.
(iv)该模型可以解决从未训练过的数据集上的问题。
3. GPT-3如何学习 (3. How GPT-3 learns)
Traditionally the pre-trained models have learnt using fine-tuning. Fine-tuning of models need lot of data for the problem we are solving and also required update to model weights. The existing fine-tuning approach is explained in below diagram.
传统上,预训练模型是使用微调学习的。 模型的微调需要大量数据来解决我们要解决的问题,并且还需要更新模型权重。 下图说明了现有的微调方法。
Learning Process for earlier Pre-Trained Language Models — Fine Tuning
早期预训练语言模型的学习过程-微调
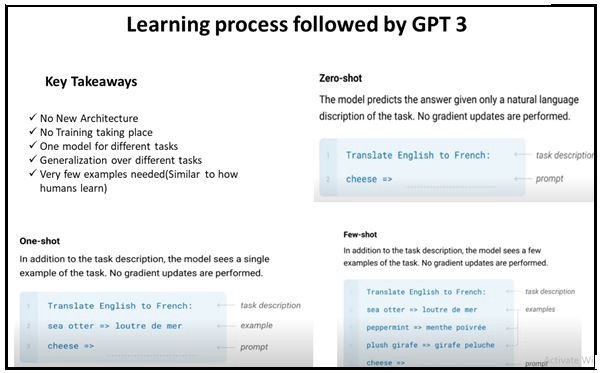
GPT-3 adopts a different learning approach. There is no need for large labeled data for inference on new problems. Instead, it can learn from no data (Zero Shot Learning), just one example (One Shot Learning) or few examples (Few Shot Learning).
GPT-3采用了不同的学习方法。 无需大量标记数据即可推断出新问题。 取而代之的是,它可以从没有数据的学习中(零镜头学习),仅一个示例(一次镜头学习)或少量示例(很少镜头学习)学习。
Below we have shown a representation of different learning approach followed by GPT-3.
下面我们展示了GPT-3所采用的不同学习方法。
4. GPT-3与BERT有何不同 (4. How is GPT-3 different from BERT)
BERT was among the earliest pre-trained model and is credited with setting the benchmarks for most NLP tasks. Below we compare GPT-3 with BERT on three dimensions:
BERT是最早的预训练模型之一,并为大多数NLP任务设定了基准。 下面我们在三个方面比较GPT-3和BERT:
Things which stand out from above representation are:
从上面的表示中脱颖而出的是:
- GPT-3 size is the stand out feature. It’s almost 470 times the size of largest BERT model GPT-3尺寸是突出的功能。 它几乎是最大的BERT型号的470倍
- On the Architecture dimension, BERT still holds the edge. It’ s trained-on challenges which are better able to capture the latent relationship between text in different problem contexts. 在体系结构维度上,BERT仍然占据优势。 它是经过培训的挑战,可以更好地捕获不同问题上下文中文本之间的潜在关系。
- GPT-3 learning approach is relatively simple and can applied on many problems where sufficient data does not exist. Thus GPT-3 should have a wider application when compared to BERT. GPT-3学习方法相对简单,可以应用于许多没有足够数据的问题。 因此,与BERT相比,GPT-3应该有更广泛的应用。
5. GPT-3真正成功的地方 (5. Where GPT-3 has really been successful)
Application of NLP techniques have evolved with the progress made in learning better representation of the underlying text corpus. Below chart gives a quick overview of some of the traditional NLP application areas.
NLP技术的应用随着学习基础文本语料库的更好表示所取得的进步而发展。 下图快速概述了一些传统的NLP应用领域。
Traditional NLP built on Bag of Words approach was limited to tasks like parsing text, sentiment analysis, topic models etc. With the emergence of Word vectors and Neural Language models, new applications like Machine Translation, entity recognition, information retrieval came into prominence.
基于词袋方法的传统NLP仅限于解析文本,情感分析,主题模型等任务。随着词向量和神经语言模型的出现,机器翻译,实体识别,信息检索等新应用程序应运而生。
In last couple of years, the emergence of Pre-trained models like BERT, Roberta etc. and supporting frameworks like Hugging Face, Spacy Transformers have made NLP tasks like Reading Comprehension, Text Summarization etc. possible and state of the art benchmarks were created by these NLP models.
在最近几年中,像BERT,Roberta等这样的预训练模型的出现以及诸如Hugging Face,Spacy Transformers之类的支持框架的出现,使诸如阅读理解,文本摘要等NLP任务成为可能,并且最先进的基准测试是由这些NLP模型。
The frontiers where pre-trained NLP models struggled were tasks like Natural Language Generation, Natural Language Inference, Common Sense Reasoning tasks. Also, there was question mark of application of NLP in these areas where limited data is available. So the question is how much impact is GPT-3 able to make on some of these tasks.
训练有素的NLP模型遇到的难题是诸如自然语言生成,自然语言推理,常识推理任务之类的任务。 同样,在数据有限的这些领域中,NLP的应用存在问号。 因此,问题是GPT-3能够对其中某些任务产生多大的影响。
GPT-3 has been able to make substantive progress on i. Text Generation tasks and ii. Extend NLP’s application into domains where there is lack of enough training data.
GPT-3已在i方面取得实质性进展。 文本生成任务和ii。 将NLP的应用程序扩展到缺少足够培训数据的领域。
Text Generation Capabilities: GPT-3 is very powerful when it comes to generating text. Based on the human surveys done, it has been observed that very little separates the text generated by GPT-3 compared to one developed by humans. This is great development for building solutions in the space of generating creative fictions, stories, resumes, narratives, chatbots, text summarization etc. At the same time the world is taking cognizance of the fact that this power can be used by unscrupulous elements to create and plant fake data on social platforms.
文本生成功能: GPT-3在生成文本方面非常强大。 根据所做的人类调查,已经观察到,与人类开发的文本相比,GPT-3生成的文本几乎没有分隔。 这是在生成创意小说,故事,简历,叙事,聊天机器人,文本摘要等空间中构建解决方案的巨大发展。与此同时,世界正在意识到这样的事实,即这种力量可以被不道德的元素用来创造并将假数据植入社交平台。
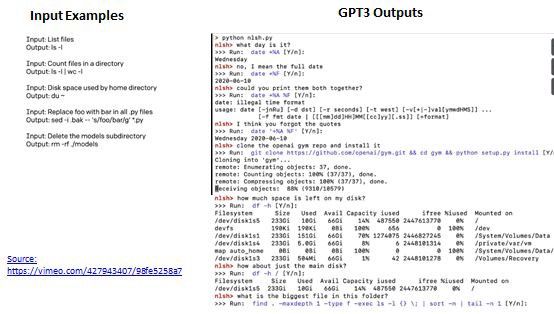
Build NLP solutions with limited data: The other area where GPT-3 models have left a mark are domains where limited data is available. We have seen the open source community use GPT-3 API’s for tasks like generation of UNIX Shell commands, SQL queries, Machine Learning code etc. All that users need to provide is a task description in plain English and some examples of input/output. This can have huge potential for organizations to automate routine tasks, speeding up processes and focus their talent on higher value tasks
使用有限的数据构建NLP解决方案: GPT-3模型留下深刻印象的其他领域是可获得有限数据的领域。 我们已经看到开放源代码社区使用GPT-3 API来执行诸如UNIX Shell命令生成,SQL查询,机器学习代码等任务。用户所需提供的只是用简单的英语描述的任务以及一些输入/输出示例。 这对于组织自动执行日常任务,加速流程并将其才能集中于高价值任务具有巨大的潜力
6. GPT-3在哪里挣扎 (6. Where GPT-3 struggles)
We have seen GPT-3 being able to make substantive progress on Text Generation tasks and also extend NLP’s applications to domains that have limited data available. However how does it fare on the traditional NLP tasks like Machine Translation, Reading Comprehension, and Natural Language Inference tasks. It’s a mixed bag and this is clearly documented in the original research paper.
我们已经看到GPT-3可以在“文本生成”任务上取得实质性进展,并且还可以将NLP的应用程序扩展到可用数据有限的域。 但是,它如何处理传统的NLP任务,例如机器翻译,阅读理解和自然语言推理任务。 它是一个混合袋,并且在原始研究论文中有明确记录。
Language Modeling — GPT-3 beat all the benchmarks on pure Language Modeling tasks.
语言建模 — GPT-3在纯语言建模任务上击败了所有基准测试。
Machine Translation — The model is able to beat the benchmark performance for translation tasks that require conversion of documents to English language. But the opposite is not true and GPT-3 performance struggles if the language translation needs to be done from English to a Non-English Language.
机器翻译 -对于需要将文档转换为英语的翻译任务,该模型可以超越基准性能。 但是事实并非如此,如果需要将语言从英语翻译成非英语,则GPT-3的性能会很困难。
Reading Comprehension — GPT 3 models performance fall well short of the State of the Art here.
阅读理解 -GPT 3模型的性能远远低于此处的最新水平。
Natural Language Inference — Natural Language Inference (NLI) concerns the ability to understand the relationship between two sentences. GPT 3 models performance fall well short on NLI tasks
自然语言推论 —自然语言推论(NLI)与理解两个句子之间的关系有关。 GPT 3模型的性能远远低于NLI任务
Common Sense Reasoning — Common Sense Reasoning datasets test performance on physical or scientific reasoning skills. GPT 3 models performance fall well short on these tasks
常识推理 -常识推理数据集可测试物理或科学推理技能的性能。 GPT 3模型的性能远远不能满足这些任务
7.未来之路 (7. Road Ahead)
Integration Challenges: At the moment GPT-3 has been made available to selected users using Open AI’s api and the user community is happy to build toy applications using GPT-3. Many firms especially in the Financial world have regulations that prohibit transfer of data outside acceptable the firm. Given GPT-3 size, if the model needs to be integrated into mainstream applications, it will be a herculean effort to develop the necessary infrastructure to ingest the data and model.
集成挑战:目前,已使用Open AI的api将GPT-3提供给选定的用户,并且用户社区很高兴使用GPT-3构建玩具应用程序。 许多公司,特别是在金融界,都有规定禁止在公司可接受的范围之外传输数据。 在GPT-3大小的情况下,如果需要将模型集成到主流应用程序中,则将大力开发必要的基础结构以提取数据和模型。
Single versus Hybrid Model Debate: The dream of having a single model for all tasks, which does not need to be trained and can learn without much data, is a cherished one. GPT-3 has made the first steps towards achieving it, but there is a journey that still needs to be made. In its present form, GPT-3 is a mixed bag. Organizations will have to choose horses for courses approach. One possible approach is to use GPT-3 for tasks like Text Generation, Machine Translation and areas where limited data exists. However, the existing pre-trained customized models (BERT/Roberta/Reformer….) will continue to hold ground on traditional tasks like Entity Recognition, Sentiment Analysis, Question Answering.
单一模型与混合模型的争论:梦dream以求的是,无需为任何任务训练就可以拥有单个模型,并且无需大量数据就可以学习。 GPT-3已朝着实现这一目标迈出了第一步,但仍有一段路要走。 以目前的形式,GPT-3是一个混合袋。 组织将不得不为课程选择马。 一种可能的方法是将GPT-3用于诸如文本生成,机器翻译和数据有限的区域之类的任务。 但是,现有的经过预先训练的定制模型(BERT / Roberta / Reformer…。)将继续在传统任务(例如实体识别,情感分析,问题回答)上站稳脚跟。
Concerns over Model Bias and Explainability: Given the sheer size of GPT-3 it will be very difficult for firms to explain the decisions made by the algorithm. There is no way for firms to regulate the data that was used to train the algorithm. How do we know if the training data has in built bias or the algorithm is making its decisions based on false data that has been put in public domain? This is further complicated by the ambiguity over how the actual decision is made just by observing a few examples in few shot learning
对模型偏差和可解释性的担忧:鉴于GPT-3的庞大规模,公司很难解释该算法做出的决策。 公司无法调节用于训练算法的数据。 我们如何知道训练数据是否存在固有偏差或算法是否基于已放入公共领域的错误数据做出决策? 仅通过观察少量射击学习中的一些示例就对如何做出实际决策的模棱两可进一步使情况变得更加复杂
Need for regulations to prevent misuse: There are some very valid concerns being raised about misuse of GPT-3 powers if not properly regulated. How the AI community is able to come up with regulation that prohibits the misuse will govern to a large extent how the model gets accepted in the organizations where there is increased awareness on Responsible AI.
需要制定法规以防止滥用:如果监管不当,人们会非常关注GPT-3的滥用。 AI社区如何提出禁止滥用的法规,将在很大程度上决定该模型如何在人们对负责任AI意识增强的组织中被接受。
翻译自: https://medium.com/swlh/understanding-gpt-3-openais-latest-language-model-a3ef89cffac2
gpt 语言模型