Logistic回归之梯度上升优化算法(四)
Logistic回归之梯度上升优化算法(四)
从疝气病症状预测病马的死亡率
1、实战背景
我们使用Logistic回归来预测患疝气病的马的存活问题。原始数据集点击这里下载。数据中一个包含了368个样本和28个特征。这种病不一定源自马的肠胃问题,其他问题也可能引发疝气病。该数据集中包含了医院检测疝气病的一些指标,有的指标比较主观,有的指标难以测量。例如马的疼痛级别。另外需要说明的是,除了部分指标主观和难以测量外,该数据集有30%的值是缺失的。所以我们得预先对数据集进行处理,再利用Logistic回归和随机梯度上升算法来预测病马的死亡率。
2、准备数据
假设有100个样本和20个特征,这些数据都是机器手机回来的。若机器上的某个传感器损坏导致一个特征无效时该怎么办?此时是否要扔掉整个数据?这种情况下,另外19个特征怎么办?是否还可用?答案是肯定的。因为有的数据相当昂贵,扔掉和重新获取都是不可取的,下面给出了一些处理方法。
- 使用可用特征的均值来填补缺失值
- 使用特殊值来填补缺失值,如-1
- 忽略有缺失值的样本
- 使用相似样本的均值填补缺失值
- 使用另外的机器学习算法预测缺失值
现在我们要进行数据预处理。有两件事,一、所有的缺失值必须用一个实数值;唉替换,因为我们使用的Numpy数据类型不允许包含缺失值。这里选择实数0来替换所有缺失值。这样做的好处在于更新时不会影响回归系数的值,如果选择实数0来替换缺失值,那么dataMatrix的某特征对应值为0,那么该特征的系数将不做更新。所有以0代替缺失值在Logistic回归中可以满足这个要求。二、如果在测试数据集中发现一条数据的类别标签已经缺失,那么我们的简单做法是将该条数据丢弃,这是因为类别标签与特征不同,很难确定采用某个合适的值来替换。采用Logistic回归进行分析时这类做法是合理的。现在我没有一个干净可用的数据集和一个不错的优化算法,将二者结合,预测马的生死问题。
干净数据集下载地址:https://github.com/Jack-Cherish/Machine-Learning/tree/master/Logistic
3、使用Python构建Logistic回归分类器
使用训练集的每个特征用于最优化算法中得到回归系数。把测试集的特征乘以回归系数并求和放入Sigmoid函数中。如果返回值大于0.5,预测标签为1,否则为0.
import numpy as np
import random
'''
函数说明:sigmoid函数
Parameters:
inX - 数据
Retruns:
sigmoid函数
'''
def sigmoid(inX):
return (1.0/(1+np.exp(-inX)))
'''
函数说明:改进的随机梯度上升算法
Parameters:
dataMatrix - 数据数组
classLabels - 数据标签
numIter - 迭代次数
Returns:
weights - 求得的回归系数数组(最优参数)
'''
def stocGradAscent1(dataMatrix,classLabels,numIter=150):
m,n = np.shape(dataMatrix)#返回dataMatrix大小
weights = np.ones(n)#初始化回归系数
for j in range(numIter):
dataIndex = list(range(m))
for i in range(m):
alpha = 4/(1.0+j+i)+0.01 #降低alpha的大小,每次减小1/(j+i)
randIndex = int(random.uniform(0,len(dataIndex)))#随机选取样本
h = sigmoid(sum(dataMatrix[randIndex] * weights))
error = classLabels[randIndex] - h
weights = weights + alpha * error* dataMatrix[randIndex]
del(dataIndex[randIndex])
print(weights)
return weights
'''
函数说明:使用Python写得Logistic分类器做预测
Parameters:
None
Returns:
None
'''
def colicTest():
frTrain = open('horseColicTraining.txt')#打开训练集
frTest = open('horseColicTest.txt')#打开测试集
trainingSet = []
trainingLabels = []
for line in frTrain.readlines():
currLine = line.strip().split('\t')#strip()为空是,split以'\t'分割字符串
# print(currLine)
lineArr = []
for i in range(len(currLine) - 1):
lineArr.append(float(currLine[i]))
trainingSet.append(lineArr)#处理成一个二维列表
# print(trainingSet)
trainingLabels.append(float(currLine[-1])) #存放标签列表
trainweights = stocGradAscent1(np.array(trainingSet),trainingLabels,500)#使用改进的随机梯度上升算法
errorCount = 0
numTestVec = 0.0
for line in frTest.readlines():
numTestVec += 1.0
currLine = line.strip().split('\t')
lineArr = []
for i in range(len(currLine) - 1):
lineArr.append(float(currLine[i]))
if int(classifyVector(np.array(lineArr),trainweights)) != int(currLine[-1]):
errorCount +=1
errorRate = (float(errorCount)/numTestVec) * 100
print('测试集错误率为: %.2f%%' %errorRate)
'''
函数说明:分类函数
Parameters:
inX - 特征向量
weights - 回归系数
Returns:
分类结果
'''
def classifyVector(inX , weights):
prob = sigmoid(sum(inX * weights))
if prob > 0.5:
return 1.0
else:
return 0.0
if __name__ == '__main__':
np.set_printoptions(suppress=True) # 关闭科学技术法
colicTest()
运行结果如下:

结果中有个警告,意思是计算的数据结果益处。这个警告对我们的实验虽然没什么影响,如果要改的话可以用如下代码:
def sigmoid(inX):
if inX >= 0:
return 1.0 / (1 + np.exp(-inX))
else:
return np.exp(inX) / (1 + np.exp(inX))
# return (1.0/(1+np.exp(-inX)))代码出处:https://blog.csdn.net/cckchina/article/details/79915181。文中也没有说明原因,如果有知道为什么的还请在评论中说一下,谢谢。回归正题,我们的算法错误率比较高。主要原因是我们的数据集本身就小,而且有很多的数据缺失。因此在面对数据量小的情况下我们可以试试梯度上升算法。
import numpy as np
import random
'''
函数说明:梯度上升法
Parameters:
dataMatIn - 数据集
classLabels - 数据标签
Returns:
weights.getA() - 求得的权重数组
'''
def gradAscent(dataMatIn, classLabels):
dataMatrix = np.mat(dataMatIn) # 转换成numpy的mat
labelMat = np.mat(classLabels).transpose() # 转换成numpy的mat,并进行转置
m, n = np.shape(dataMatrix) # 返回dataMatrix的大小。m为行数,n为列数。
alpha = 0.01 # 移动步长,也就是学习速率,控制更新的幅度。
maxCycles = 500 # 最大迭代次数
weights = np.ones((n, 1))
for k in range(maxCycles):
h = sigmoid(dataMatrix * weights) # 梯度上升矢量化公式
error = labelMat - h
weights = weights + alpha * dataMatrix.transpose() * error
return weights.getA() # 将矩阵转换为数组,并返回
'''
函数说明:sigmoid函数
Parameters:
inX - 数据
Retruns:
sigmoid函数
'''
def sigmoid(inX):
# if inX >= 0:
# return 1.0 / (1 + np.exp(-inX))
# else:
# return np.exp(inX) / (1 + np.exp(inX))
return 1.0/(1+np.exp(-inX))
'''
函数说明:改进的随机梯度上升算法
Parameters:
dataMatrix - 数据数组
classLabels - 数据标签
numIter - 迭代次数
Returns:
weights - 求得的回归系数数组(最优参数)
'''
def stocGradAscent1(dataMatrix,classLabels,numIter=150):
m,n = np.shape(dataMatrix)#返回dataMatrix大小
weights = np.ones(n)#初始化回归系数
for j in range(numIter):
dataIndex = list(range(m))
for i in range(m):
alpha = 4/(1.0+j+i)+0.01 #降低alpha的大小,每次减小1/(j+i)
randIndex = int(random.uniform(0,len(dataIndex)))#随机选取样本
h = sigmoid(sum(dataMatrix[randIndex] * weights))
error = classLabels[randIndex] - h
weights = weights + alpha * error* dataMatrix[randIndex]
del(dataIndex[randIndex])
# print(weights)
return weights
'''
函数说明:使用Python写得Logistic分类器做预测
Parameters:
None
Returns:
None
'''
def colicTest():
frTrain = open('horseColicTraining.txt')#打开训练集
frTest = open('horseColicTest.txt')#打开测试集
trainingSet = []
trainingLabels = []
for line in frTrain.readlines():
currLine = line.strip().split('\t')#strip()为空是,split以'\t'分割字符串
# print(currLine)
lineArr = []
for i in range(len(currLine) - 1):
lineArr.append(float(currLine[i]))
trainingSet.append(lineArr)#处理成一个二维列表
# print(trainingSet)
trainingLabels.append(float(currLine[-1])) #存放标签列表
trainweights = gradAscent(np.array(trainingSet),trainingLabels)#使用改进的随机梯度上升算法
errorCount = 0
numTestVec = 0.0
for line in frTest.readlines():
numTestVec += 1.0
currLine = line.strip().split('\t')
lineArr = []
for i in range(len(currLine) - 1):
lineArr.append(float(currLine[i]))
if int(classifyVector(np.array(lineArr),trainweights[:,0])) != int(currLine[-1]):
errorCount +=1
errorRate = (float(errorCount)/numTestVec) * 100
print('测试集错误率为: %.2f%%' %errorRate)
'''
函数说明:分类函数
Parameters:
inX - 特征向量
weights - 回归系数
Returns:
分类结果
'''
def classifyVector(inX , weights):
prob = sigmoid(sum(inX * weights))
if prob > 0.5:
return 1.0
else:
return 0.0
if __name__ == '__main__':
np.set_printoptions(suppress=True) # 关闭科学技术法
colicTest()
运行结果如下:
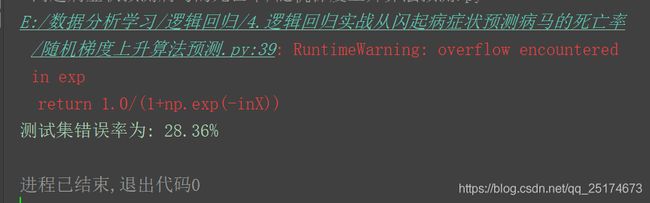
错误率有所降低。
- 数据集较大时,使用随机梯度上升发
- 数据集较小是,使用梯度上升算法
总结
Logistic回归的有点在于容易实现,好理解,计算代价不高,速度很快,存储资源低。缺点在于容易欠拟合,分类经度可能不高。
参考文献:
- 《机器学习实战》第五章内容
- Jack Cui博客:https://cuijiahua.com/blog/2017/11/ml_7_logistic_2.html