r语言多重对应分析_R语言实战 多元统计分析Day3聚类分析(一)
R语言实战 多元统计分析
— —聚类分析(一)
聚类分析是一类将数据所对应研究对象进行分类的统计方法。聚类分析根据分类对象不同分为Q型聚类分析和R型聚类分析。Q型聚类分析是指对样本进行聚类,R型聚类分析是指对变量进行聚类分析.
1 认识聚类分析相关函数:1.dist()函数:
距离函数,计算各样本之间的距离
使用格式:
dist(x,method="euclidean",diag=FALSE,upper=FALSE,p=2)
#函数说明:
method 为定义距离的方法
diag 是否输出对角线上的距离
upper 是否输出上三角矩阵的值
p为Minkowski距离的参数q
2.scale()函数:
数据中心化或标准化处理
使用格式:
scale(x,center=TRUE,scale=TRUE)
#函数说明:
x 数据矩阵
center 是否对数据作中心变换
scale是否对数据作标准化变换
3.hclust()函数:
提供系统聚类的计算
使用格式:
hclust(d,method="complete",members=NULL)
#函数说明:
d为dist()函数生成的对象,即距离。
method 系统聚类的方法
4.plclust()函数:
画出系统聚类的树形图
使用格式:
plclust(tree,hang=0.1,unit=FALSE,level=FALSE,hmin=0,square=TRUE,labels=NULL,plot.=TRUE,axes=TRUE,...)
#函数说明:
tree为hclust()函数生成的对象
unit:TRUE为分叉画在等空间高度
hmin:数值
hang 谱系图中各类所在的位置,取负值表示谱系图中的类从底部画起
5.cutree()函数:
根据谱系图确定最终的聚类
使用格式:
cutree(tree,k=NULL,h=NULL)
#函数说明:
tree为hcluct()函数生成的对象
k 表示类的个数
h 表示谱系图中的阈值
6.rect.hclust()函数:
根据谱系图确定最终的聚类
使用格式:
rect.hclust(tree,k=NULL,border=2,..)
#函数说明:
tree为hcluct()函数生成的对象
border 矩形框的颜色
2实例分析
为了更深入地了解我国人口的文化程度状况,现利用1990年全国人中普查数据对全国30个省、直辖市、自治区进行聚类分析。数据如下图。分析选用三个指标:(1)大学以上文化程度的人口占全部人口的比例(DXBZ)(2)初中文化程度的人口占全部人口的比例(CZBZ)(3)文盲半文盲占全部人口的比例。分别用来反映较高、中等、较低文化程度人口的状况。
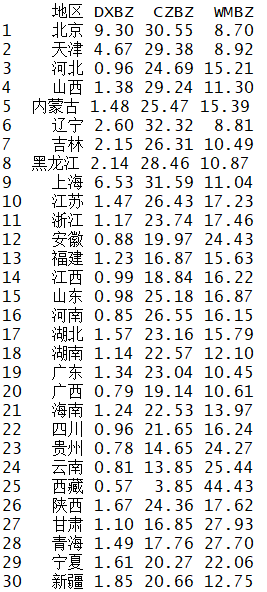
[数据来源:R语言实用教程 薛毅 陈立萍编著]
此时我们用以上介绍的相关函数对数据进行聚类分析。

首先将文件名为RKPC的数据导入,并将文件转化为数据框形式进行分析。

生成距离结构,进行系统聚类。

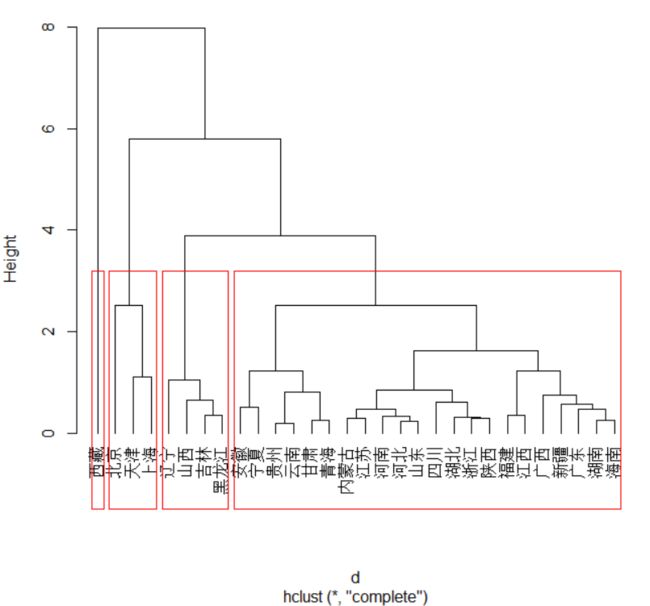
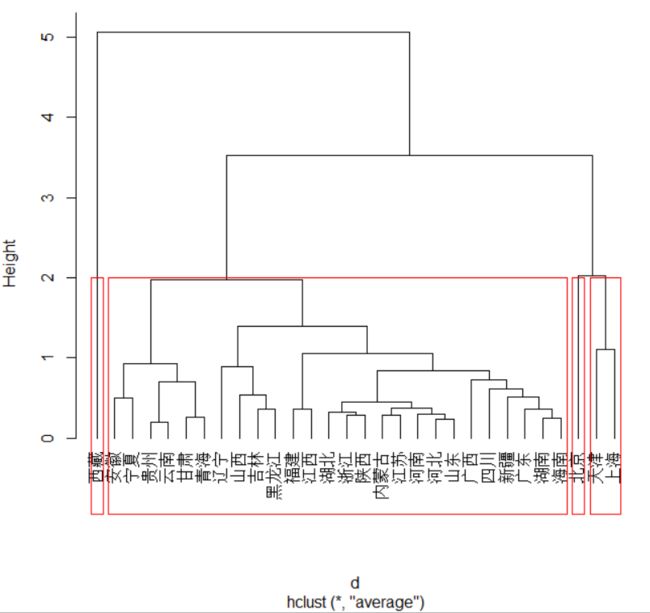
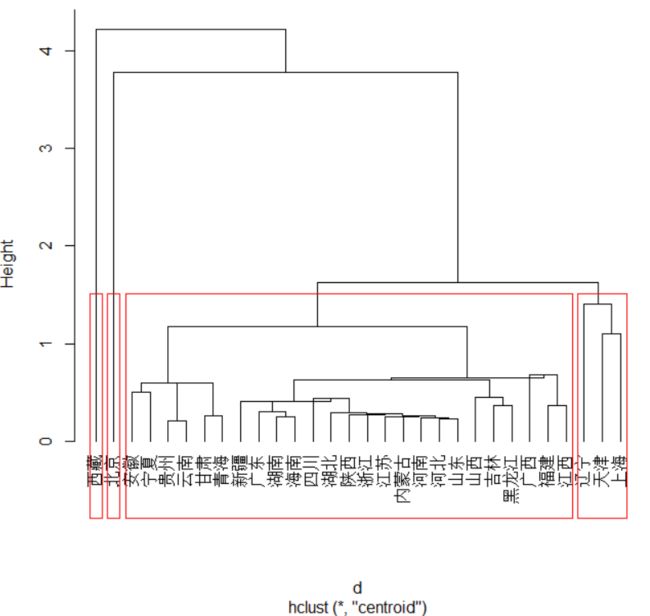
显示用最长距离法,均值法、重心法、ward法聚类,计算出的结果。

最长距离法:4类
第一类:北京、天津、上海
第二类:河北、内蒙古、江苏、浙江、安徽、福建、江西、山东、河南、湖北、湖南、广东、广西、海南、四川、贵州、云南、陕西、甘肃、青海、宁夏、新疆
第三类:山西、辽宁、吉林、黑龙江
第四类:西藏

均值法:4类
第一类:北京
第二类:天津、上海
第三类:河北、山西、内蒙古、辽宁、吉林、黑龙江、江苏、浙江、安徽、福建、江西、山东、河南、湖北、湖南、广东、广西、海南、四川、贵州、云南、陕西、甘肃、青海、宁夏、新疆
第四类:西藏

重心法:4类
第一类:北京
第二类:天津、辽宁、上海
第三类:河北、山西、内蒙古、吉林、黑龙江、江苏、浙江、安徽、福建、江西、山东、河南、湖北、湖南、广东、广西、海南、四川、贵州、云南、陕西、甘肃、青海、宁夏、新疆
第四类:西藏

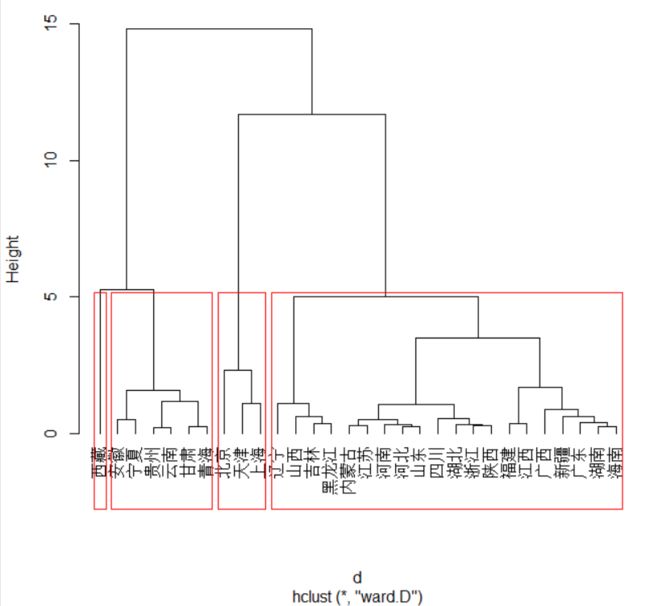
离差平方和法(ward)
第一类:北京、天津、上海
第二类:河北、山西、内蒙古、辽宁、吉林、黑龙江、江苏、浙江、福建、江西、山东、河南、湖北、湖南、广东、广西、海南、四川、陕西、新疆、
第三类:安徽、贵州、云南、甘肃、青海、宁夏
第四类:西藏
THE END
对于四种聚类方法,结果有相同的也有不相同的。今天就到这里,明天我们根据具体数据与背景再进行进一步确定哪种聚类较为合理。