Python爬取网页数据并进行基础数据整理和分析
这是我用python做的第一个project,也通过这个project感受到了python的强大,我随机找了两个包含很多数据的网页,都是关于太阳耀斑(solar flares)。我将把两个网页的数据爬取到一起进行分析和整理
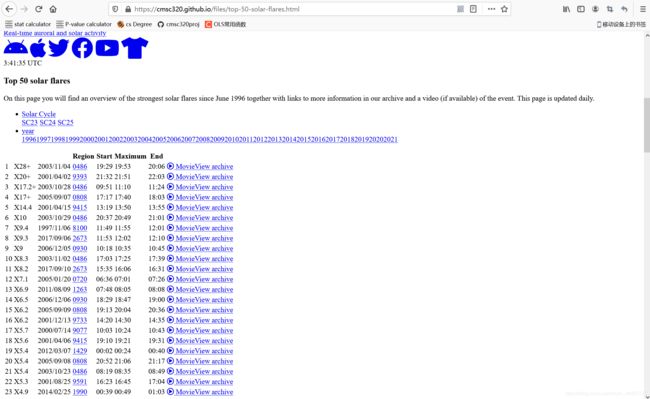
该网页的网址是:https://cmsc320.github.io/files/top-50-solar-flares.html
另一个网页的网址是:http://cdaw.gsfc.nasa.gov/CME_list/radio/waves_type2.html
下面是大概这个网页的样子,可以看到他显示出来了top50 solar flares的表,我将在下面用python 爬取改网页的数据表并进行分析。
另一个网页的样子
这个project我实用google colab写的,之所以没有选择用vscode或者docker来完成是因为觉得colab更方便和强大,代码报错会有快捷键直接跳转stackoverflow进行查询报错的原因,colab是一个很强大的在线编译器,强烈推荐用来写jupyter book!
下面是第一部分爬取数据的代码。
import requests
import pandas
import bs4
import numpy as np
import json
import copy
# step 1
# srcaping data from the website
response = requests.get('https://cmsc320.github.io/files/top-50-solar-flares.html')
soup = bs4.BeautifulSoup(response.text, features="html.parser")
soup.prettify()
# creating table
solar_table = soup.find('table').find('tbody')
data_table = pandas.DataFrame(columns=['rank', 'x_class', 'date', 'region', 'start_time', 'max_time', 'end_time', 'movie'], index = range(1,len(solar_table)+1))
# set data into table format
i = 0
for row in solar_table:
k = 0
columns = row.find_all('td')
for col in columns:
data_table.iat[i,k]=col.get_text()
k += 1
i += 1
data_table运行效果,实际出来的50行,也就是前50的top flares的table,我们可以看到,和网页上的数据以及对应的数据类型是一样的。

下一步我开始做数据分析,我将移除已经生成table的最后一列,并且将日期和上面的3列数据关于开始时间的列分别合并,这样我的表会变得简洁,后面进行数据分析更方便。
data_table = data_table.drop('movie', 1)
# Combine the date
start = pandas.to_datetime(data_table['date'] + ' ' + data_table['start_time'])
max = pandas.to_datetime(data_table['date'] + ' ' + data_table['max_time'])
end = pandas.to_datetime(data_table['date'] + ' ' + data_table['end_time'])
# Update values
data_table['start_datetime'] = start
data_table['max_datetime'] = max
data_table['end_datetime'] = end
data_table = data_table.drop('start_time', 1)
data_table = data_table.drop('max_time', 1)
data_table = data_table.drop('end_time', 1)
data_table = data_table.drop('date', 1)
# Set - as NaN
data_table = data_table.replace('-', 'NaN')
data_table = data_table[['rank', 'x_class', 'start_datetime', 'max_datetime', 'end_datetime', 'region']]
data_table
调整后的表格如下

第三步我将爬取上面提到的另一个网页的数据然后把他存到一个新的table里面
response2 = requests.get('https://cdaw.gsfc.nasa.gov/CME_list/radio/waves_type2.html')
soup2 = bs4.BeautifulSoup(response2.text, features="html.parser")
soup2.prettify()
# Creating data table
table2 = soup2.find('pre').get_text().splitlines()
del table2[0:12]
del table2[-1:]
data_table2 = pandas.DataFrame(columns = ['starting_date', 'starting_time', 'ending_date', 'ending_time', 'starting_frequency', 'ending_frequency',
'solar_source', 'active_region', 'x-ray', 'date_of_CME', 'time_of_CME', 'position_angle', 'CME_width',
'CME_speed', 'plots'], index = range(1,len(table2)+1))
# Set data into the table
i = 0
for row in table2:
table2[i] = (row.split('PHTX')[0] + 'PHTX').split()
k = 0
for col in table2[i]:
data_table2.iat[i, k] = col
k += 1
i +=1
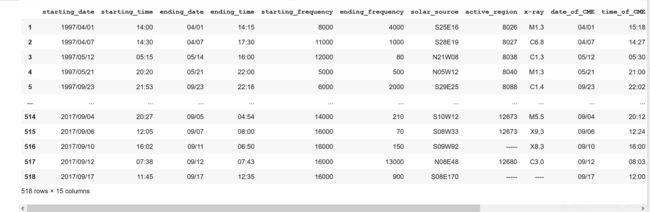
data_table2运行效果如下
接下来我将整理这个新的table,我称他为NASA table, 里面缺失的position degree列里的信息会被我填上NaN, 然后日期会和上面一样和时间分别合并。我还创建了一个新的列来判断width是否是lower bound
data_table2.replace(['----', '-----', '------', '--/--', '--:--', 'FILA', '????' 'LASCO DATA GAP', 'DSF'], 'NaN', inplace = True)
# Copy
data_table2['is_halo'] = data_table2['position_angle'].map(lambda x: x == 'Halo')
data_table2['position_angle'] = data_table2['position_angle'].replace('Halo', 'NA')
data_table2['lower_bound'] = data_table2['CME_width'].map(lambda x: x[0] == '>')
data_table2['CME_width'] = data_table2['CME_width'].replace('>', '')
# Set data in data_table2
for i, row in data_table2.iterrows():
x = row['starting_date'][:5]
data_table2.loc[i, 'starting_date'] = pandas.to_datetime(row['starting_date'] + ' ' + row['starting_time'])
if row['ending_date'] != 'NaN' and row['ending_time'] !='NaN':
if row['ending_time'] == '24:00':
row['ending_time'] = '23:55'
data_table2.loc[i, 'ending_date'] = pandas.to_datetime(x + row['ending_date'] + ' ' + row['ending_time'])
if row['date_of_CME'] != 'NaN' and row['time_of_CME'] != 'NaN':
data_table2.loc[i, 'date_of_CME'] = pandas.to_datetime(x + row['date_of_CME'] + ' ' + row['time_of_CME'])
data_table2 = data_table2.drop(['starting_time'], 1)
data_table2 = data_table2.drop(['ending_time'], 1)
data_table2 = data_table2.drop(['time_of_CME'], 1)
data_table2.rename(columns = {'starting_date':'starting_date_time', 'ending_date':'ending_date_time', 'date_of_CME':'cme_date_time'}, inplace=True)
data_table2整理完后的table是这样的
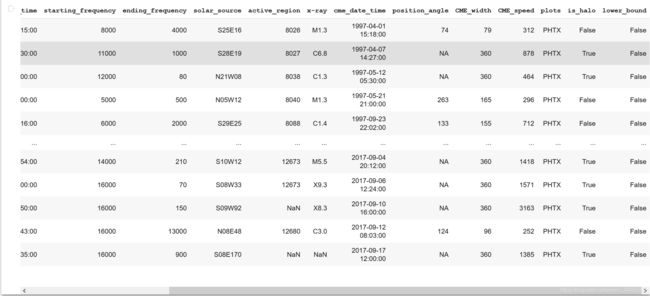
接下来辅助前50行从NASA table里面然后建成一个新的table
temp = data_table2.copy()
# Classifying only X leading
top_lines = temp.loc[temp['x-ray'].astype(str).str.contains('X')].copy()
top_lines['x-ray'] = top_lines['x-ray'].str.replace("X", '')
top_lines['x-ray'] = top_lines['x-ray'].astype(float)
top_lines = top_lines.sort_values('x-ray', ascending = False)
top_lines['x-ray'] = top_lines['x-ray'].astype(str)
top_lines['x-ray'] = 'X' + top_lines['x-ray']
top_lines = top_lines[0:50]
top_lines运行结果,没有截图全,但是可以大概看到NASA table的top50已经被复出出来
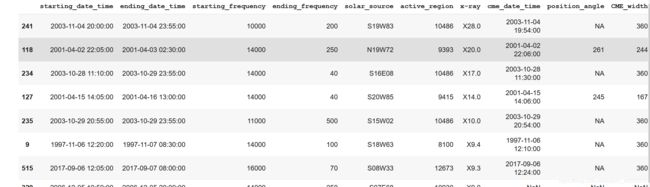
对于第一个网页的数据中排名前50的太阳耀斑,从这个新表的数据中找到最匹配的一行。
top_lines['ranking'] = 'NA'
for i, i1 in data_table.iterrows():
for j, j2 in top_lines.iterrows():
if i1['region'] == j2['active_region'] and i1['start_datetime'].date() == j2['starting_date_time'].date():
top_lines.loc[j, 'ranking'] = i
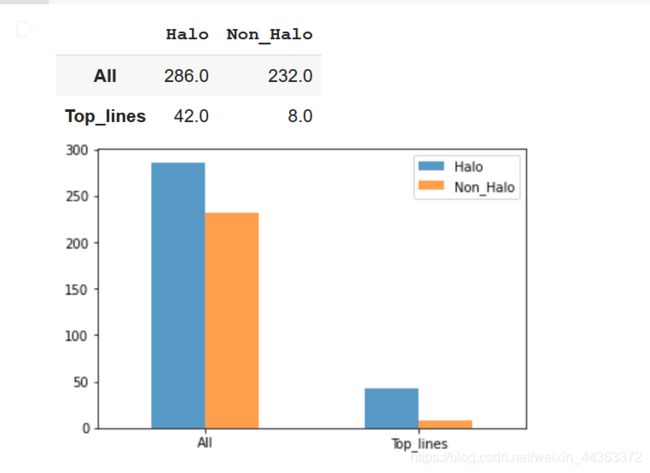
top_lines最后我将进行数据分析,NASA表数据集中的大量属性(开始或结束频率,耀斑高度或宽度)随时间的变化,我将画出一张柱状图来显示分析结果。
halo_CME_top_lines = top_lines.is_halo.value_counts('True')[1] * len(top_lines.index)
non_halo_top_lines = len(top_lines.index) - halo_CME_top_lines
halo_nasa = data_table2.is_halo.value_counts('True')[1] * len(data_table2.index)
non_halo_nasa = len(data_table2.index) - halo_nasa
# Draw the graph
plot_graph = pandas.DataFrame({'Halo': [halo_nasa, halo_CME_top_lines], 'Non_Halo':[non_halo_nasa, non_halo_top_lines]}, index=['All', 'Top_lines'])
plot_graph.plot(kind = 'bar', alpha = 0.75, rot = 0)
plot_graph运行结果