pandas处理异常数据(缺失值和重复值)
1. 缺失值**
a) 可以用None或者np.nan来表示缺失的值
import pandas as pd
import numpy as np
data=[['mark',55,'Italy',4.5,'Europe'],
['John',33,'China',3.8,'Asian'],
['mary',40,'Japan',2.3,'Asian']]
df=pd.DataFrame(data=data,columns=['name','age','country','score','continent'],
index=[1001,1002,1003])
df.loc[1001,'score'] = None
df.loc[1004,:]=None
print(df)
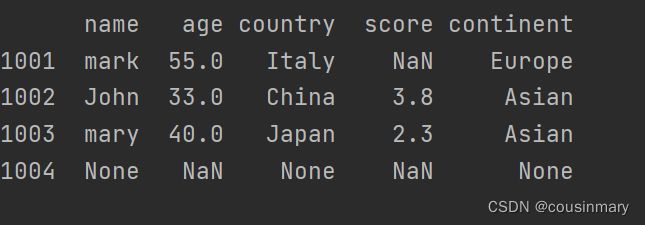
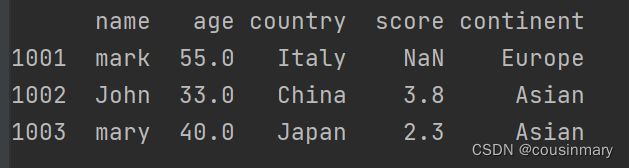
b) 移除所有包含缺失数据的行
df=df.dropna()

注:
pd.dropna()同样不能改动原Dataframe,需要重新赋值
c) 只移除所有数据却缺失的行
df=df.dropna(how='all')
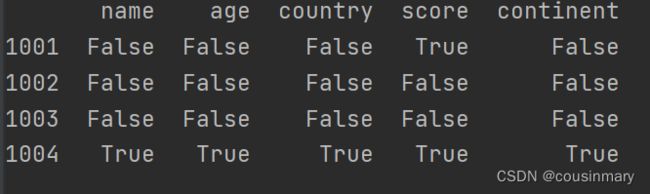
d) 判断对应位置上是否时NAN
df=df.isna()
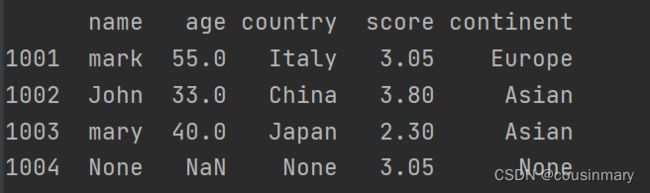
e) 使用fillna()对缺失值进行填补
df=df.fillna({'score':df['score'].mean()})
2. 对重复值进行处理
a) 使用drop_duplicates函数(第一次出现的数据会保留)
import pandas as pd
import numpy as np
data=[['mark',55,'Italy',4.5,'Europe'],
['John',33,'China',3.8,'Asian'],
['mary',40,'Japan',2.3,'Asian'],
['fiona',35,'China',5.6,'Asian']]
df=pd.DataFrame(data=data,columns=['name','age','country','score','continent'],
index=[1001,1002,1003,1004])
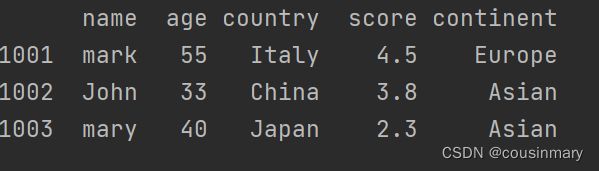
df=df.drop_duplicates(['country','continent'])
print(df)
b) is_unique确认是否存在重复值
unique获取去重之后的值
import pandas as pd
import numpy as np
data=[['mark',55,'Italy',4.5,'Europe'],
['John',33,'China',3.8,'Asian'],
['mary',40,'Japan',2.3,'Asian'],
['fiona',35,'China',5.6,'Asian']]
df=pd.DataFrame(data=data,columns=['name','age','country','score','continent'],
index=[1001,1002,1003,1004])
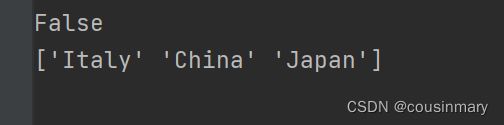
print(df['country'].is_unique)
df=df['country'].unique()
print(df)
c) 定位重复行—duplicated
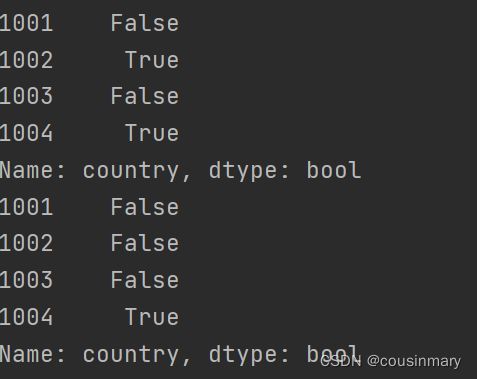
- keep参数为first时,保留第一次出现的数据,
keep参数为False时,所有重复数据都会被标记为True
import pandas as pd
import numpy as np
data=[['mark',55,'Italy',4.5,'Europe'],
['John',33,'China',3.8,'Asian'],
['mary',40,'Japan',2.3,'Asian'],
['fiona',35,'China',5.6,'Asian']]
df=pd.DataFrame(data=data,columns=['name','age','country','score','continent'],
index=[1001,1002,1003,1004])
print(df['country'].duplicated(keep=False))
print(df['country'].duplicated(keep='first'))
2. 定位重复行
import pandas as pd
import numpy as np
data=[['mark',55,'Italy',4.5,'Europe'],
['John',33,'China',3.8,'Asian'],
['mary',40,'Japan',2.3,'Asian'],
['fiona',35,'China',5.6,'Asian']]
df=pd.DataFrame(data=data,columns=['name','age','country','score','continent'],
index=[1001,1002,1003,1004])
df=df.loc[df['country'].duplicated(keep=False),:]
print(df)
