知识图谱和图神经网络
知识图谱
- 理论知识
- 知识图谱嵌入模型
-
- TransE
- DistMult
- 知识图谱的抽取与构建
-
- 知识图谱工程
- 知识抽取——实体识别与分类
- 知识抽取——实体关系抽取与属性补全
- 知识图谱的推理
-
- 常见知识图谱推理方法分类
- 图表示学习
-
- 随机游走
-
- 同构图算法
- 异构图算法
- 图神经网络系列
-
- 监督学习或半监督学习模型
-
- GCN,图卷积神经网络([视频](https://aistudio.baidu.com/aistudio/education/lessonvideo/3720952))
- VGAE,图变分自编码器
- GAT,图注意力网络([视频](https://aistudio.baidu.com/aistudio/education/lessonvideo/864813))
- GraphSAGE & PinSAGE([视频](https://aistudio.baidu.com/aistudio/education/lessonvideo/868946))
- GTN,Graph Transformer Network
- ERNIESage(Text Graph + Sage) + UniMP
- 层次化模型
- 预训练GNN模型
-
- GPT-GNN
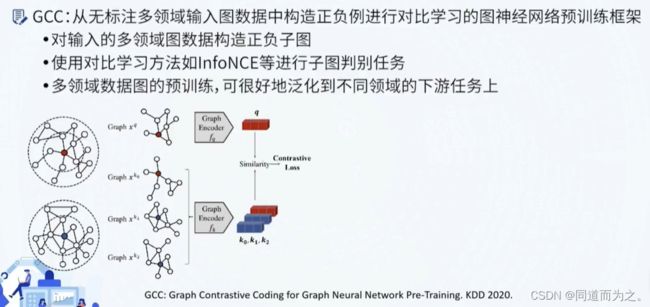
- GCC,对比学习模型
相关课程见:https://www.bilibili.com/video/BV1AG411G7nB?p=9&spm_id_from=pageDriver&vd_source=8837f9e77e9560aed14eb1cdf850f72f
理论知识
知识(图谱)的表示学习是符号表示与神经网络相结合比较自然且有前景的方向。知识的向量表示有利于刻画那些隐含不明确的知识,同时基于神经网络和表示学习实现的推理一定程度上可以解决传统符号推理所面临的鲁棒性不高不容易扩展等众多问题。

知识图谱嵌入模型
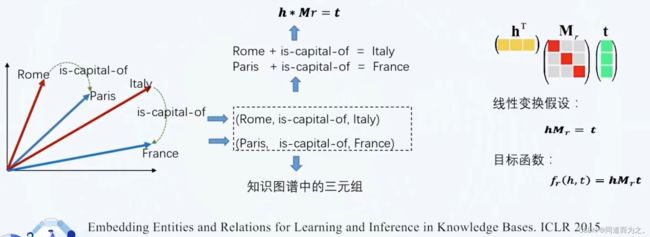
利用句子中词的上下文贡献来学习词的向量表示一样(Skip-gram和Cbow模型),同样也可以用三元组(主谓宾,Rome is-capital-of Italy)结构来学习知识图谱中实体和关系的向量表示。
TransE
假设三元组之间的关系存在"加法"等式,代表模型TransE

其中, h h h是主语, r r r是关系谓语, t t t是宾语。目标函数的含义:让真实存在的三元组的score尽可能高,让不存在的三元组的score尽可能低。可以采用简单的梯度下降方法,随机初始化所有实体和关系的向量表示,然后迭代优化这些向量的参数,如果优化目标能够收敛,最后学习到满足 h + r = t h+r=t h+r=t的关系假设。关键点:负样本(不存在的三元组)有很多方法可以构建,其中一种方法是随机替换真实三元组中的 h h h或 t t t。
DistMult
假设三元组之间的关系存在"乘法"等式,基于线性变换的学习模型。使用了一个矩阵而不是向量表示关系,如果一个三元组 ( h , r , t ) (h, r, t) (h,r,t)存在,那么 h ∗ M r = t h * M_r = t h∗Mr=t 也一定存在,损失函数与TransE模型一致。
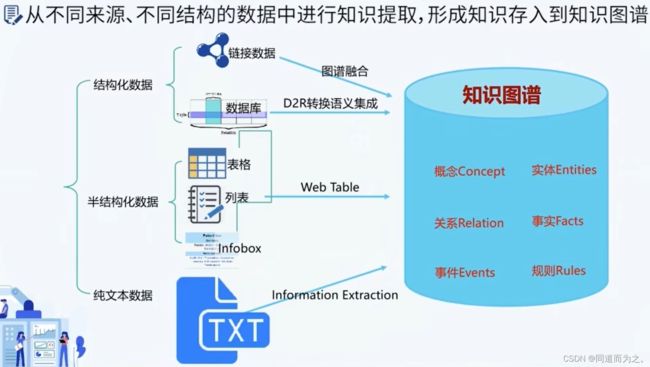
知识图谱的抽取与构建
知识图谱工程

绝大部分知识图谱工程项目,通过已有的结构化数据完成冷启动,再进一步利用文本、图片等数据来补全知识图谱。


知识抽取——实体识别与分类

粗粒度和细粒度识别实体

该方法不常用,更为常用的做法是基于机器学习算法的实体识别。实体识别任务可以定义为一个序列标注问题,即给定一个句子,我们需要通过一个分类器给每个词打一个标签,例如B-ORG标签代表该词是机构ORG的起始词、I-PERSON标签代表该词是一个人名的中间词等等,这样我们就能够通过机器学习训练一个分类算法来完成整个句子的序列标注。
跟大多数机器学习模型一样,我们需要设计各种类型的特征来训练分类器,例如我们可以利用词本身的特征、前后缀特征、字本身的特征,等等。

首先要确定实体识别的序列标签体系:

IOB是粗粒度的标注体系,B-ORG:起始词,I-ORG:中间词,O:其它词
根据特定领域的需要,定义更加细粒度的标签,标签体系越复杂,所需要的语料标注成本越高。
常见序列标注模型:隐马尔科夫模型HMM,基于深度学习的实体识别(BiLstm+CRF),基于预训练语言模型的实体识别、实体识别解码策略

实体识别面临着标签分布不平衡,实体嵌套等问题,制约了现实应用;中文的实体识别面临一些特有的问题,例如:中文没有自然分词、用字变化多、简化表达现象严重等等;实体识别是语义理解和构建知识图谱的重要一环,也是进一步抽取三元组和关系分类的前提基础。
知识抽取——实体关系抽取与属性补全
实体关系抽取任务定义:从文本中抽取出两个或者多个实体之间的语义关系;从文本获取知识图谱三元组的主要技术手段,通常被用于知识图谱的补全。例如:给定文本信息<美丽的西湖坐落于浙江省的省会城市杭州的西南面>,可以抽取出(西湖,位于,杭州),(浙江省,省会,杭州)。
实体关系抽取方法概览:

常见方法:
(1)基于模板的方法:基于触发词匹配的关系抽取
(2)基于模板的方法:基于依存句法匹配的关系抽取
(3)基于监督学习的关系抽取:At-least-one Hypothesis
(4)基于深度学习的关系抽取:RNN、CNN、Piece-wise CNN Model、Attention + BiLstm等等。
(5)基于图神经网络的关系抽取:GCN
(6)基于预训练语言模型的关系抽取:bert
(7)基于胶囊神经网络的多标签关系抽取
(8)多元关系抽取:Graph Lstm
(9)基于远程监督的关系抽取:半监督学习(Bootstrapping)
属性补全的任务定义:对实体拥有的属性及属性值进行补全。一个事物若干属性的取值来对这个事物进行多维度的描述。
属性补全的方法:抽取式和生成式
一个基于深度学习的开源中文关系抽取框架 https://github.com/zjunlp/deepke
OpenConcept, 中文概念知识图谱: http://openconcept.openkg.cn/
基于神经网络的事件抽取模型:DMCNN
知识图谱的推理
常见知识图谱推理方法分类

图表示学习
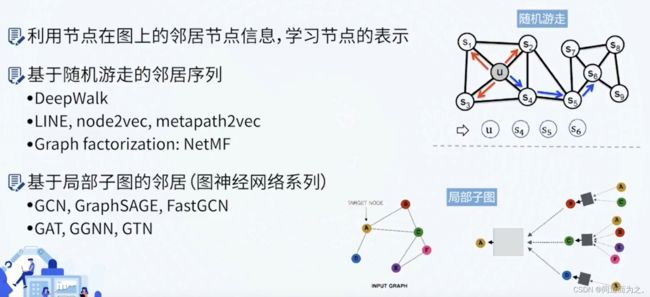
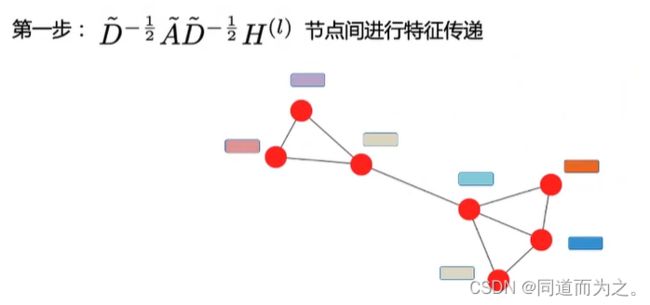
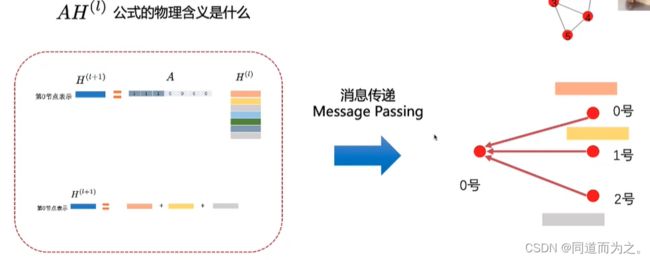
GNN主要通过聚合节点周围的局部子图来定义节点的邻居信息,进而更新当前节点的表示,比如右下角节点A,其邻居节点包括B、C、D,对它们进行聚合操作。
随机游走
同构图算法
- DeepWalk
- Node2Vec
- Line
- NetMF
异构图算法
- Metapath2Vec
图神经网络系列
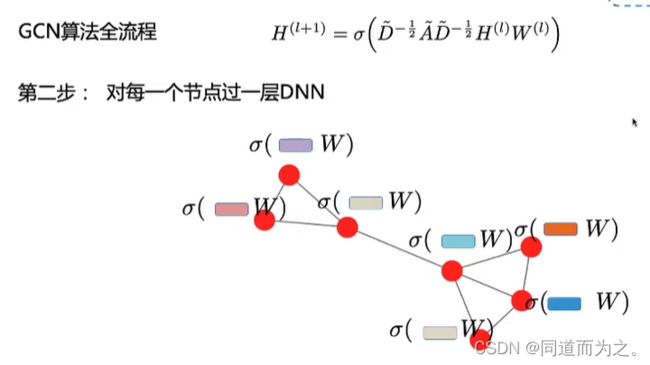
信息传播模块:聚合周围邻居节点的信息,在节点间进行信息传播并以此更新节点的隐藏层状态。
聚合器:使用神经网络模块聚合周围节点信息/特征。
迭代器:基于当前节点的表示和周围节点的特征更新周围节点的表示输出模块:基于学习到的节点表示,根据任务定义目标函数。
模型通常以半监督方式进行训练。
GNN的分类如下:

监督学习或半监督学习模型
GCN,图卷积神经网络(视频)


VGAE,图变分自编码器

其中X为节点特征矩阵,A为邻接矩阵,其它过程与VAE基本类似。
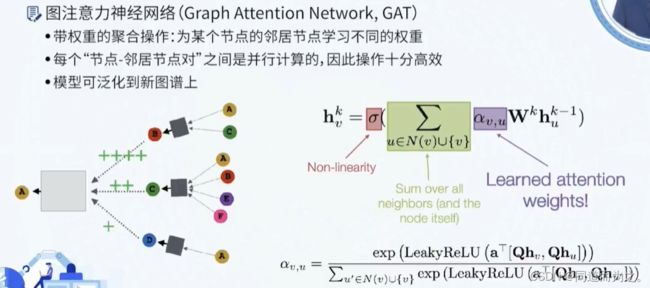
GAT,图注意力网络(视频)
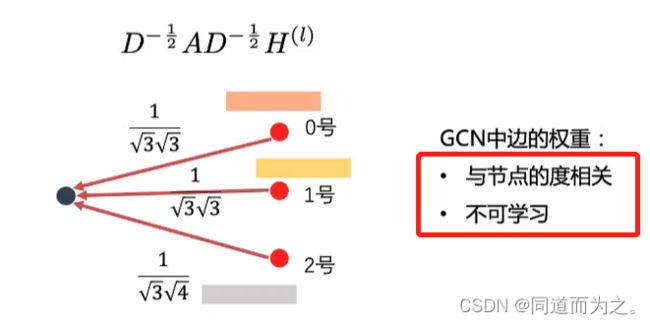
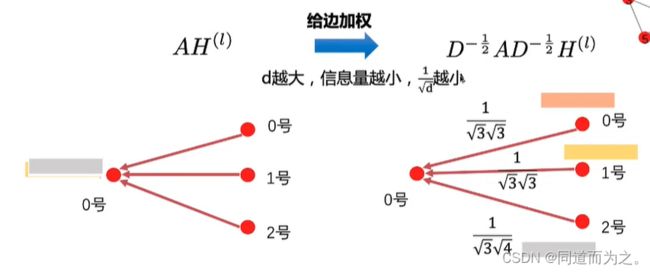
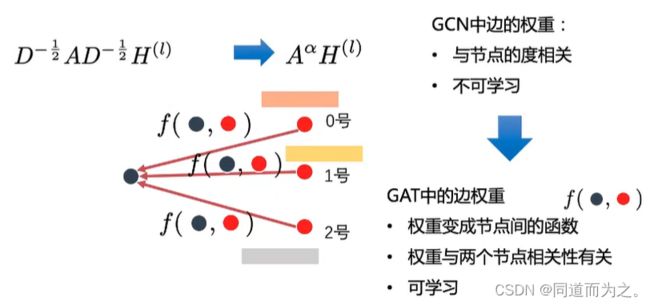
GCN中边的权重与节点的度相关,度越大,权重越小,同时该权重是不可学习的。 针对这个问题,提出了GAT,使得权重变成节点间的函数,两个节点相关性越强,权重越大,同时该权重是通过学习得到的。如下图所示:


GraphSAGE & PinSAGE(视频)
为什么要图采样?因为图规模庞大时,无法一次性全图送入计算资源,需要借鉴深度学习中的miniBatch,对图进行分批训练,但分批训练又存在节点之间相互依赖、涉及计算的节点随层数增加呈指数增长的问题。
不同于GCN等模型中利用图谱的邻接矩阵时,需要固定每个节点的周围邻居节点,GraphSAGE(SAmple & aggreGatE)考虑了对邻居节点进行随机采样,使得GNN模型可以应用到大规模图谱上。
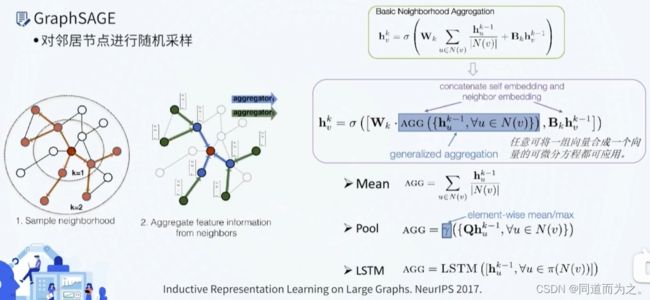

在模型推断时,一个邻居节点不在训练阶段出现过,它仍然可以参与到这个节点的计算过程,因为GraphSAGE模型在训练过程中一个节点的邻居节点数目是随机采样得到的,并不是某些固定的邻居节点决定的。
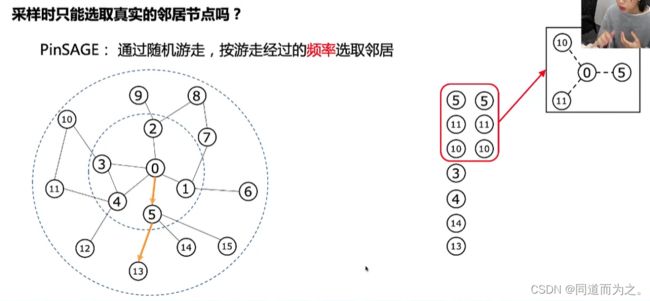
采样时只能选取真实的邻居节点吗?不是的,PinSAGE先进行随机游走,然后选取游走经过频率高的节点作为邻居节点,这些节点包含直连和非直连的节点,这样可以快速地聚合到远距离节点(二阶、三阶、…等)的信息。
为什么要选取游走经过频率高的节点作为邻居节点?因为这些节点相对于随机游走的起始节点更加重要。
GTN,Graph Transformer Network

ERNIESage(Text Graph + Sage) + UniMP
百度推出的图语义理解模型,学习视频:视频1 + 视频2(关键)

bert / ernie 类似,bert随机对语句中部分token随机掩盖,训练模型预测这些token,它是token级别的mask机制,不需要理解整个句子的意思就可以比较轻松的预测出对应的正确答案,这种方式不太利于模型对知识语义的理解;ernie通过改变语句的mask的方式,对词、实体、短语进行mask,比如把例句中的哈尔滨mask掉,让模型预测被mask的地方是哈尔滨,此时模型需要了解整个句子的语义,这就是ernie模型1.0版本的核心思想“知识增强”。

持续学习的含义:持续地对模型进行多种预训练任务的训练,不遗忘先前的训练结果的前提下,不断增加新的预训练任务。

UniMP模型:

提出背景:传统的结构化数据不同样本之间缺乏关联关系,而图数据不同节点(对象)之间存在关联关系。
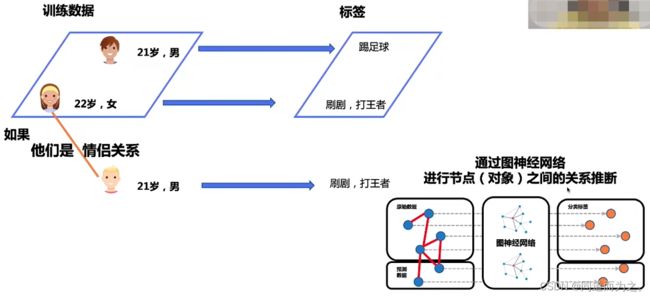
实际情况下,预测过程中,训练标签是不可见的,如何利用训练集的标签做预测推断呢?UniMP提出的解决方法是让训练标签也作为特征参与模型的训练,之后就可以利用模型直接进行推断,这个过程就是标签传播的过程。

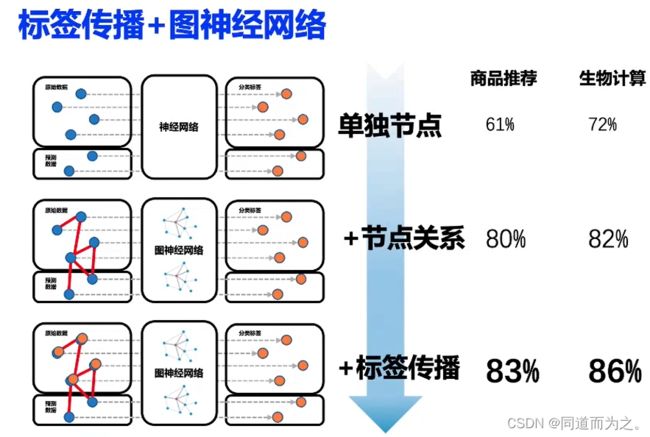
但是存在一个问题,直接将训练标签作为训练特征会导致标签泄露,导致训练后的模型具有非常严重的过拟合现象。针对这个问题,UniMP提出了“Masked Label Prediction”的策略,把训练集中部分节点标签Mask掉,利用其它没有被mask的节点信息(特征+标签)以及图网络结构来预测被mask掉标签的节点对应的标签,借鉴了Masked Language Model(MLM)中随机对输入语句的部分词进行mask并预测这部分词作为训练模型的方式的核心思想。如下图所示,节点2和节点3之间存在情侣关系,加上节点2的标签(喜好)是刷剧和打王者这个关键因素,可以比较容易地预测节点3标签(喜好)也是刷剧和打王者。

UniMP的模型结构:

训练集的标签信息是如何作为特征传进去的?
第一步,设定标签mask比例,并按照该比例划分训练集( V V V),得到一部分含标签的节点( U U U)和一部分不含标签的节点( V − U V-U V−U);
第二步,把含有标签的节点对应的标签信息通过Label Embedding的方式映射为与节点特征维度相同的维度,并把节点的特征和标签的特征直接相加,并作为节点新的初始特征;
第三步,将新的节点特征作为Graph Transformer的输入,参与传播过程,其中模型的目标函数是让被mask掉标签的节点预测标签与真实标签( Y ~ \tilde{Y} Y~)尽可能地一致,如下:

第四步,模型推断过程中,需要使用全部的训练集(原始训练集)节点信息(特征+标签)进行节点预测。注:模型训练过程中,把原始训练集划分成了mask节点集(被预测)和not mask节点集(真正参与模型训练)。
层次化模型

预训练GNN模型

GPT-GNN


GCC,对比学习模型