Python数据处理课程设计-房屋价格预测
注:可能有些图片未能成功上传,可在文档处进行下载
链接:Python数据处理课程设计-房屋价格预测-机器学习文档类资源-CSDN下载
课程设计报告
| 课程名称 |
Python数据处理课程设计 |
| 项目名称 |
房屋价格预测 |
目录
一. 题目背景.. 3
1.选题背景... 3
2.研究意义... 3
3.题目描述... 3
4.选题数据... 3
二. 现有研究状态... 4
三. 运用的技术手段和方法... 5
3.1 EDA(探索性数据分析)... 5
3.2 异常值的处理.. 5
3.3合并训练集和测试集... 6
3.4 删除多余的列.. 6
3.5 缺失值的处理.. 6
3.6 数据类型转换.. 6
3.7 数据对数化处理... 6
3.8 得到数据特征的重要性并做成DataFrame形式... 6
3.9 对数据特征重要性数值进行可视化.. 6
3.10 对数据进行合并... 7
3.11 取出处理后的测试集数据... 7
3.12 使用机器学习模型对数据进行预测.. 7
四. 数据分析.. 7
4.1 EDA(探索性数据分析)... 7
4.2异常值处理.. 7
4.3合并训练集和测试集... 11
4.4删除多余的列... 11
4.5缺失值处理.. 11
4.6数据类型转换... 14
4.7数据对数化处理.. 14
4.8 得到数据特征的重要性并做成DataFrame形式... 16
4.9 对数据特征重要性数值进行可视化.. 17
4.10 对数据进行合并... 18
4.11 取出处理后的测试集数据... 20
4.12使用机器学习模型对数据进行预测... 20
4.13 有意义的方面... 21
五. 项目总结.. 22
六. 参考文献.. 23
- 题目背景
1.选题背景
随着经济的持续发展,房地产行业已经成为了支柱产业,房屋价格不仅直接影响着居民的生活水平,也间接影响着国家经济的持续、健康、平稳发展,房屋价格已经成为关系民生的热点问题。房价是否合理,仅仅通过表面观察和凭空想象是不能回答这些问题的,要通过科学的研究方法才能得出合理的结论。房屋价格受到很多因素的制约和影响,比如:地理位置、建造房子所用的材料、住宅风格、住宅类型、有无地下室、有无车库、栅栏的质量、家庭的功能等,都会对房价产生影响。所以要选取的特征因素应当具有全面性、多样性,选择与房价密切相关的指标,对数据进行分析、处理,利用机器学习算法研究其对价格的影响程度,并构建出稳定性好、误差小的价格预测模型,较为准确地预测出房子的最终价格,从而为政府相关部门宏观调控、房地产开发商以及卖房或买房者提供科学的定价以及估价依据,更好地推进房屋市场的稳定发展。
2.研究意义
目前有人在对房屋价格的研究上已经取得了诸多成果,大多数人主要从政治、经济、政策、人口等宏观层面对房屋价格进行了分析,也有少数学者从房屋建筑硬件设施等微观因素展开了研究,也取得了较好的预测效果,但目前这方面还是相对较少。鉴于此,我将根据比赛的数据,构建特征变量集,选取有代表性的特征变量,在已有数据的基础上,对数据进行处理,使用机器学习算法分析房价问题,选择预测模型将其用于预测测试集的房屋价格。
此外,无论是对于监管者还是消费者,是房产中介机构还是房地产开发商,只有深入了解房地产交易市场,才能进行合理监管与规划;高效率推广房源,在能满足购房者需求的前提下科学定价,提高市场竞争优势;有效规避风险,降低不必要的损失等。所以预测房屋价格能为人们在住房购买方面提供更多选择,具有一定的参考作用。
3.题目描述
购房者描述了他们梦想中的房子,他们可能不会从地下室天花板的高度或东西向铁路的距离开始。但这些数据证明,影响价格谈判的因素远大于卧室数量或白色栅栏。题目给出的变量几乎描述了爱荷华州艾姆斯市住宅的各个方面。根据题目所给出的训练集和测试集的数据,分析题目所给的80个变量,预测出测试集中1460条样本的房价。
4.选题数据
赛题数据由以下两部分构成:
训练集包含1460条样本,81个属性:

测试集包含1460条样本,80个属性:
- 现有研究状态
一直以来,房价问题是社会各界讨论较多的话题,已有诸多学者从不同视角探索了影响房价的因素,并取得了一定研究成果。同时也在尝试探索如何构建更精确的模型去预测房价。
近年来,国内外大多学者以宏观或微观角度为切入点,展开对房价影响因素的研究。如:
- 周学君等[1]采用了影响房价的6个主要因素输入到人工神经网络中进行房价预测;
- 申瑞娜等[2]收集了影响房价的8个因素,结合主要影响因素和支持向量机对房屋价格进行预测;
- 王景行[3]将LASSO回归和XGBoost机器学习算法集成并融合stacking模型来对比用单一方法预测房价的效果,得到用集成模型来预测房价比用单一模型预测效果更加显著的结论;
- 赵泰等[4]将灰色GM(1,1)模型来对商品房销售的价格进行预测,得到了该模型在房价中的应用价值;
- 王瑾等[5]通过多元逐步回归方法建立房价预测模型对北京市房屋价格进行统计分析;
- 陈世鹏等[6]根据襄阳房贷数据建立随机森林模型对测试样本进行房价预测,取得了较好的效果。
在研究方法上大部分学者都使用了 Lasso回归、随机森林回归、支持向量回归、XGBoost 回归、多元线性回归等单一模型,使用的模型较为广泛,也有部分研究所选取的特征维数有限,并不能全面反映影响房屋价格的制约因素,能够分析处理的特征维数较少,并不能全面挖掘特征因素与房价之间的影响关系。
所以本文在对房屋价格的研究过程中,以Kaggle平台的房屋价格作为数据库,建立影响房屋价格的多维因素与房屋价格之间的联系,我选取了较多的变量组合对同一预测指标进行对比分析和模型评价,将多种算法融合使用并构建组合模型去预测房屋的价格,通过模型评价指标,选择最优的预测模型,以为政府部门、中介机构和购房者等提供合理的对策建议。
- 运用的技术手段和方法
3.1 EDA(探索性数据分析)
这是一个功能强大的库,使用这个库只需要一行代码便可以得到数据EDA报告,生成的报告可以有效帮助我们熟悉数据集、了解数据集。报告中会有缺失值信息、重复值信息、每个变量的信息等内容,这些信息以便更好对数据进行的分析、处理。
3.2 异常值的处理
看到数据后,我首先考虑的是数据中异常值信息,对数据中异常值进行处理。在处理数据异常值这里,我根据变量的相关矩阵图选取了三个变量:建造年份、房屋的面积和地下室面积,构建了三个图像:YearBuilt与SalePrice之间的箱型图、GrLivArea与SalePrice之间的散点图、TotalBsmSF与SalePrice之间的散点图,通过得到的图对异常的数据进行分析处理。
3.3合并训练集和测试集
接下来便是把训练集和测试集数据进行合并,以便后面方便对数据进行分析、处理。
3.4 删除多余的列
把数据进行合并后,我发现Id列和索引值都是以1为间隔,升序排列的数值,所以我把Id列给删除了,删除Id列后,方便后面对数据的处理。
3.5 缺失值的处理
在开始的时候,有考虑过要不要把有缺失的数据给删除,但缺失值的数量还是挺多的,如果把缺失的数据都删除的话,信息丢失会很大,所以还是选择保留。
在对缺失数据进行填充时,我对部分字符类型的变量使用众数进行填充,部分字符类型的变量用“None”进行填充,对数值类型的变量使用0进行填充。
3.6 数据类型转换
从变量的数据类型信息图中可以看到,有很多变量是字符串类型的,但计算机对字符串的特征是无能为力的,所以需要将字符串特征映射成数值类型。
3.7 数据对数化处理
由于一些变量不符合正态分布,对数据进行对数化处理可以使那些不完全具有正态分布的特征更符合正态分布,特征的正态性对回归模型的拟合效果起到非常重要的作用。所以对数据进行对数转换,不仅可以使特征正态化,而且也可以减少异常值对变量的影响。
3.8 得到数据特征的重要性并做成DataFrame形式
特征的选择是非常关键的一步,好的特征选择能够提升模型的性能,更能帮助我们理解数据的特点、底层结构,这对进一步改善模型、算法都有着重要作用。特征没有选择好,对比赛结果也会产生不小的影响。这里我选择使用Lasoo回归来得到数据特征的重要性数值,并将变量名和特征的重要性作为DataFrame的形式,方便后面进行可视化处理。
3.9 对数据特征重要性数值进行可视化
得到了变量特征的重要性后,由于得到的是一些数值,数字太抽象,图表会更直观、可以突出数据中的关注点,所以这里对上面得到的数据进行可视化处理。
3.10 对数据进行合并
根据上面得到的数据特征重要性图,对数据特征进行选择与重做,对题目所给的变量,根据特征重要性值对特征进行加减乘除等运算,对部分数据进行合并。
3.11 取出处理后的测试集数据
将数据进行处理后,把测试集的数据取出,以便后面使用机器学习相关模型对数据进行预测。
3.12 使用机器学习模型对数据进行预测
对数据处理完成后,使用机器学习算法对的处理后的测试集进行预测,得到测试结果。
- 数据分析
4.1 EDA(探索性数据分析)
首先我根据题目所给的数据,使用了pandas_profiling库,生成了数据的EDA(探索性数据分析)报告:
从Overview部分可以看到,数据中没有重复数据,不需要处理重复数据;但空值占比还是不小的,有5.9%,需要对空值进行处理。
4.2异常值处理
根据EDA报告中得到的变量相关矩阵图:

从这个相关矩阵图的最后一列数据可以看出,SalePrice与其他变量的关系,从图中可以看出房屋的面积(GrLivArea)、地下室面积(GrLivArea)、建造年份(YearBuilt)等变量与SalePrice的颜色较深,也有其他一些颜色较深的变量。颜色越深说明其相关性越大。我认为房屋的面积(GrLivArea)、地下室面积(TotalBsmSF)、建造年份(YearBuilt)与房屋的价格(SalePrice)关系还是挺大的,一般来讲,面积越大房子的价格会越贵,房龄越久房子的价格也会较便宜。所以我构建了三个图像:YearBuilt与SalePrice之间的箱型图、GrLivArea与SalePrice之间的散点图、TotalBsmSF与SalePrice之间的散点图。
- YearBuilt与SalePrice的箱型图:

从这个箱型图可以看出:房屋建造年份和销售价格并没有很强的趋势关系, 但根据我平时的常识来说,我觉得他们两者之间还是有一定的关系,所以在后面处理时我还是将它重点考虑了。
- GrLivArea与SalePrice的散点图:

根据得到的散点图,可以看出房屋面积和房屋的价格存在着一定的线性关系,但也有少量的数据偏离线性关系,由于数据只有两个,所以这里我把太偏离线性的那两个数据使用drop()函数删除掉了,删除后得到的散点图如下:
- TotalBsmSF与SalePrice的散点图:
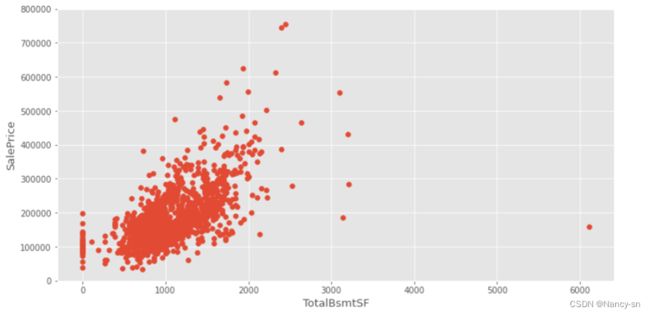
根据得到的散点图,可以看出地下室面积和房屋的价格存在着一定的线性关系,但也有数据偏离线性关系,所以这里我把右边太偏离线性的那个数据使用drop()函数删除掉了,删除后得到的散点图如下:
4.3合并训练集和测试集
处理好了训练集的异常值后,我把训练集和测试集数据使用concat()函数进行合并,以便后面方便对数据进行分析处理。
4.4删除多余的列
把数据进行合并后,我发现Id列和索引值都是以1 为间隔升序的数值:
所以我把Id列给删除,删除Id列后,方便后面对数据的处理,删除后:
4.5缺失值处理
在得到的EDA报告中可以看出训练集中缺失值占比不少:
从图中可以看出,空白部分代表的是缺失值,部分变量缺失值占比很大。
把数据合并后,我使用了isnull()和sum()函数来统计数据中缺失值的个数,并使用sort_values()函数对缺失数据从低到高进行排序:
由于存在空值的变量较多,我使用了info()方法查看80个变量的信息:
从得到的信息可以看出,有些缺失数据时字符串类型的,有些是数值类型的,所以在使用fillna()函数对缺失值进行填充时,我先对字符串类型的变量进行分析,决定对这些变量:MSZoning (一般分区分类)、BsmtFullBath (地下室全浴室)、BsmtHalfBath (地下室半浴室)、KitchenQual (厨房质量)、SaleType (销售类型)、Exterior1st (房屋外墙)、Exterior2nd (房屋的外部覆盖物)、Utilities(公用设施)、Functional(家庭功能评级)、Electrical(电气设备)使用众数进行填充;对数值类型的变量用0进行填充;对剩下的字符型变量使用“None”进行填充:
填充完成后,查看是否有还有未填充的数据:
发现只有房屋价格一列存在缺失,故把目前把空值填充完成。
4.6数据类型转换
从上面得到数据类型信息图中可以看到,有很多变量是字符串类型的,但计算机对字符串的特征是无能为力的,所以需要将字符串特征映射成数值类型。我使用了fit_transform()函数对数据进行转换,fit_transform()是fit()和transform()的组合,这个函数先对部分数据进行拟合fit,然后根据具体转换的目的,对该数据进行转换,从而实现数据的标准化:
可以看到转换后字符类型的值转换为数值类型的值。
4.7数据对数化处理
由于一些变量不符合正态分布,对数据进行对数化处理可以使那些不完全具有正态分布的特征更符合正态分布,特征的正态性对回归模型的拟合效果会起到非常重要的作用。所以我对部分数据进行对数转换:
SalePrice(房屋价格):
|
|
由于变量数较多,所以我筛选了部分变量,选择了skew(偏差)大于0.75的变量,共有12个,对这12个变量进行了转换,下面是前后对比图:
4.8 得到数据特征的重要性并做成DataFrame形式
特征的选择是非常关键的一步,好的特征选择能够提升模型的性能,更能帮助我们理解数据的特点、底层结构,这对进一步改善模型、算法都有着重要作用。特征没有选择好,对比赛结果也会产生不小的影响。在得到数据特征的重要性时,我考虑到了Lasso回归和Ridge回归,但由于Lasso回归中求得的值会有更少的非零分量,所以这里我选择使用Lasoo回归来得到数据特征的重要性数值:
得到后,将变量名和特征的重要性作为DataFrame的形式,方便后面进行可视化处理:
4.9 对数据特征重要性数值进行可视化
得到了变量特征的重要性后,由于得到的是一些数值,数字太抽象,图表会更直观、可以突出数据中的关注点,所以这里对上面得到的数据进行可视化处理:
4.10 对数据进行合并
根据上面得到的数据特征重要性图,对数据特征进行选择与重做,对题目所给的变量,根据特征重要性值对特征进行加减乘除等运算,对部分数据进行合并,我构造了一个转换函数transform():
下面是我构建这个转换函数的想法:
- 地下室面积、一楼的面积、二楼的面积这三者进行组合为整个房子
- 地下室面积、一楼的面积、二楼的面积、车库面积这四者进行组合为整个房子的总面积
- 把总体材料和加工质量、整个房子进行组合为一个新的特征变量
- 把生活区面积、总体材料和加工质量进行组合为一个新的特征变量
- 把一般分区分类、整个房子进行组合为一个新的特征变量
- 把一般分区分类、总体材料和加工质量进行组合为一个新的特征变量
- 把一般分区分类、建造年份进行组合为一个新的特征变量
- 把邻里、整个房子进行组合为一个新的特征变量
- 把邻里、总体材料和加工质量进行组合为一个新的特征变量
- 把邻里、建造年份进行组合为一个新的特征变量
- 把地下室的高度、总体材料和加工质量进行组合为一个新的特征变量
- 把家庭功能评级、整个房子进行组合为一个新的特征变量
- 把家庭功能评级、总体材料和加工质量进行组合为一个新的特征变量
- 把地块面积、总体材料和加工质量进行组合为一个新的特征变量
- 把整个房子、地块面积进行组合为一个新的特征变量
- 把类型 1成品、类型 2成品、地下室进行组合为一个新的特征变量
- 把浴室、房间数进行组合为一个新的特征变量
- 把开放门廊面积、 封闭的门廊面积、三季门廊面积、屏幕门廊面积进行组合为一个新的特征变量
- 把地下室总面积、一楼的面积、二楼的面积、车库面积、开放门廊面积、 封闭的门廊面积、三季门廊面积、屏幕门廊面积进行组合为一个新的特征变量
以上19条便是我根据数据特征重要性图和自己的想法来对数据进行特征的选择和重做。
4.11 取出处理后的测试集数据
将数据进行处理后,把测试集的数据取出,以便后面使用机器学习相关模型对数据进行预测:
4.12使用机器学习模型对数据进行预测
对数据处理完成后,使用机器学习算法对的处理后的测试集进行预测,得到测试结果:
①首先构建了模型评估方法:我选择使用交叉验证法。使用交叉验证法,每个样例都会刚好在测试集中出现一次,对数据的使用更加高效,更多的数据可以得到更为精确的模型。
②接下来使用网格搜索:网格搜索是一种调参手段,可以实现自动调参并返回最佳的参数组合。
③接下来就是对模型的选择:我使用了6个模型,这些模型之间有一些相同的点,但各个模型都有各自的优点所在:
Lasso回归:该方法是以缩小变量集(降阶)为思想的压缩估计方法。
岭回归:在不抛弃任何一个变量的情况下,缩小了回归系数,使得模型相对而言会比较稳定。
支持向量回归:这是一种“宽容的回归模型”,在线性函数两侧制造了一个“间隔带”,对于所有落入到间隔带内的样本,都不计算损失。
核岭回归:这个回归会产生近似形式的解,在中度规模的数据时效率高。
弹性网络:弹性网络它永远可以产生有效解,它不会产生交叉的路径。
贝叶斯回归:贝叶斯回归易于训练,可以用于在预估阶段的参数正则化,通过手动调节数据值来实现。
④最优参数的选取:使用上面所定义的模型评估方法对选择的模型进行评估,得出每个模型的最优参数如下:
⑤模型的集成:得到了选取模型的最优参数后,对模型进行集成,我使用了两个方法对模型进行集成:
加权平均法:使用上面所选取的最优参数,对每个模型分配不同比例的权重,求出交叉验证的均值:
模型的堆叠:定义了模型堆叠函数(先把数据进行了5折划分,把数据集分成了5份,然后使用模型进行拟合),后面便可以根据这个函数对数据进行预测。
⑥模型训练、预测结果:把处理后得到的测试集数据放到堆叠的模型中进行计算,得到结果,并将结果保存到csv文件中:
4.13 有意义的方面
我认为数据处理的有意义方面有:
- 对空值的填充:在对空值进行填充时,我选择对房屋销售类型、一般分区分类、地下室全浴室、地下室半浴室、厨房质量、销售类型、房屋外墙、房屋的外部覆盖物、公用设施、家庭功能评级、电气设备这些变量使用众数进行填充,我认为这些变量可以用数据的一般水平来代替。
- 对异常数据的删除:通过分析得到了房屋的面积、地下室面积、建造年份这三个变量与房屋价格之间的关系,得到了他们与房屋价格之间的图像,通过图像分析,对异常的值进行删除。
- 数据的对数化处理:一些变量不符合正态分布,对数据进行对数化处理可以使那些不完全具有正态分布的特征更符合正态分布,这样对回归模型的拟合效果会起到非常重要的作用。
将特征进行合并:
- 将室内房屋的面积(地下室面积、一楼的面积、二楼的面积、车库面积)进行合并处理,构建出一个新的变量,并对这个新的变量进行分析处理。
- 把室内、室外房屋的面积(地下室总面积、一楼的面积、二楼的面积、车库面积、开放门廊面积、 封闭的门廊面积、三季门廊面积、屏幕门廊面积)进行合并,构建出一个新的变量,表示整个房子的室内、室外总面积。
- 把房屋的面积和房屋的加工材料这两个变量进行乘法运算,得到一个新的变量,后面再对这个新的变量进行分析。
- 把浴室、房间数相加组合为一个新的特征变量,这个变量可以用来表示整个房子的总房间个数。
- 把邻里、建造年份相加,组合为一个新的特征变量,我认为邻里可以反应出房子所在位置所在地段是否繁华,而建造年份可以反应出房子从开始建造到购买房子的时间。
- 把家庭功能评级、总体材料和加工质量相加,组合为一个新的特征变量,家庭功能评级和房子所用的材料都可以反应出这个房子的好坏,评级越高、加工材料越好,肯定房子也是越好的。
- 把(开放门廊面积、 封闭的门廊面积、三季门廊面积、屏幕门廊面积)相加,进行组合为一个新的特征变量门廊的总面积,后面便可以对门廊总面积进行分析了。
等等。。。
以上便是我列举的10个较有意义的数据处理。
- 项目总结
房价预测这个题目看似简单,只需要得到1460个样本数据的房价即可。但实质上也有难度,它的属性有80个,缺失值也很多,在数据预处理这里我也更改了多次。
特别是在对数据特征进行选择和重做时,我也是有点不知道该怎样处理,最后我决定构建出数据的特征重要性图,根据数据特征重要性图中的数据对参数进行选择,再把属性进行合并、分拆等操作。
在选择模型的时候,先是对模型的选择,再对模型进行集成、堆叠,通过更改每个模型的权重,最后得到了一个较好的结果。
通过这次的课程设计有学到很多,收获很大,对缺失值的处理、数据的合并、数据可视化处理、对数据特征的选择等。我也明白了数据处理的重要性,对数据的分析也很重要,使用不同的方法得出的结果可能会有很大的差别。这次实验,我对Python有了更好的了解,它拥有着巨大且活跃的科学计算社区,它有着pandas、sklearn等功能强大的库和工具,这次的课程设计让我深刻体会到了一些库和工具的强大。
但我觉得我在数据预处理部分还是处理的不够好,在填充空值时,只使用了均值、众数等进行填充,我认为这里还可以使用标准偏差值进行填充,在这一块,我还得继续学习;在变量特征的选取及合并方面,我认为还可以考虑更综合、更全面,构建出不一样的新特征,进一步加强预测精度,不断改进,最后拿到更好的成绩。
竞赛结果:
- 参考文献
- 周学君,陈文秀.基于人工神经网络BP算法的黄冈市房价预测[J].黄冈师范学院学报,2014.
- 申瑞娜,曹昶,樊重俊.基于主成分分析的支持向量机模型对上海房价的预测研究[J].数学的实践与认识,2013.
- 王景行.基于回归的房价预测模型研究[J].全国流通经济,2020.
- 赵泰,迟建英.基于灰色GM(1,1)模型在商品房销售价格预测中的应用[J].价值工程,2019.
- 王瑾,崔玉杰,李仝.统计模型在北京市商品房价格预测上的应用[J].劳动保障世界,2018.
- 陈世鹏,金升平.基于随机森林模型的房价预测[J].科技创新与应用,2016.
- 纪昀瑛.北京房价的思考研究与总结[J].全国流通经济,2017.
- 罗乐.中国房地产周期波动的统计研究成都 四川大学,2007.
- 姜玉砚,段燕临.影响房地产价格的四大因素[J].房地产市场,2009.
- 王明涛.多指标综合评价中权数确定的一种综合分析方法[J].系统工程,1999.