【超硬核】一文打尽 Redis 核心技术
Redis 核心技术
- 前言
- 基础篇
-
- Redis 特性
- Redis 的数据结构以及数据类型
- Redis 键和值用什么结构组织?
- Redis 为什么不使用多线程?
- 单线程 Redis 为什么那么快?
- Redis 单线程处理 IO 请求性能瓶颈
- Redis 持久化机制
- Redis 高可用之主从模式
-
- 主从模式常见的问题
- 复制缓冲区(replication buffer) 和 复制积压缓冲区(repl_backlog_buffer) 的区别
- 为什么主从库间的复制不使用 AOF 呢?
- Redis 高可用之哨兵集群
- Redis 集群
-
- Redis 集群数据倾斜问题
- 实战篇
-
- Redis 的淘汰策略
- 四种缓存异常问题及解决方案
- Redis 中的原子操作
- Redis 是如何实现事务机制的?
- Redis 分布式锁的实现
- Redis 实现消息队列
- Redis 实现秒杀场景
- 删除了大量的缓存数据,为何内存使用依然很高?
- Redis 6.0 新特性
- 文末福利
前言
过年了,给大家伙整点福利。
缓存在我们工作中应用非常广泛,而 Redis 凭借着其优异的性能、丰富的生态、活跃的社区、以及低成本的开发门槛,在众多的缓存框架中,一枝独秀。
本文把 Redis 的核心技术点整理了个脑图,为大家总结下 Redis 相关的功能点以及常见问题。
脑图在文末可下载。
基础篇
Redis 特性
- 纯内存操作
- 单线程高性能
- 丰富的数据结构类型
Redis 的数据结构以及数据类型

Redis 键和值用什么结构组织?

Redis 为什么不使用多线程?
我们通常说的 Redis 是单线程,主要是指 Redis 的网络 IO 和键值对读写是由一个线程来完成的。
但 Redis 其他功能,比如持久化、异步删除、集群数据同步等,其实都是额外的线程执行的。
所以,严格来说,Redis并不是单线程,但是我们一般把Redis称为单线程高性能。
Redis为什么用单线程?
根本原因是避免多线程模式带来的开销问题。
系统中通常会存在被多线程同时访问的共享资源,比如一个共享的数据结构。 当有多个线程要修改这个共享资源时,为了保证共享资源的正确性,就需要有额外的机制进行保证,而这个额外的机制,就会带来额外的开销。
这就是多线程编程模式面临的共享资源的并发访问控制问题:
- 若没有额外机制保证情况下,不能保证共享资源的准确性;
- 添加额外机制可能带来额外的开销。
在Redis 6.0前,网络请求的解析和数据读写都是由主线程来完成的, 这也是我们称之为单线程的原因。 从Redis 6.0开始,网络请求的解析是由其他线程完成, 然后把解析后的请求交由主线程进行实际的内存读写。
单线程 Redis 为什么那么快?
- 内存数据库:操作都在内存上完成
- 底层高效的数据结构:简单动态字符串、双向链表(O(N))、压缩列表(O(N))、哈希表(O(1))、跳表(O(logN))和整数数组(O(N))
- 基于多路复用的高性能 I/O 模型
Redis 单线程处理 IO 请求性能瓶颈
- 操作 bigkey:写入或者删除一个 bigkey 在操作内存时需要消耗更多的时间
- 使用复杂度过高的命令
- 大量 key 集中过期
- 淘汰策略
- AOF刷盘开启
always机制 - 主从全量同步生成 RDB
- 并发量非常大时,单线程读写客户端 IO 数据存在性能瓶颈
Redis 持久化机制

Redis 高可用之主从模式

主从模式常见的问题

复制缓冲区(replication buffer) 和 复制积压缓冲区(repl_backlog_buffer) 的区别
replication buffer 作用:
主节点开始和一个从节点进行全量同步时,会为从节点创建一个输出缓冲区,这个缓冲区就是复制缓冲区。
当主节点向从节点发送 RDB 文件时,如果又接收到了写命令操作,就会把它们暂存在复制缓冲区中。 等 RDB 文件传输完成,并且在从节点加载完成后,主节点再把复制缓冲区中的写命令发给从节点,进行同步。
对主从同步的影响:如果主库传输 RDB 文件以及从库加载 RDB 文件耗时长, 同时主库接收的写命令操作较多,就会导致复制缓冲区被写满而溢出。 一旦溢出,主库就会关闭和从库的网络连接,重新开始全量同步。 所以,我们可以通过调整 client-output-buffer-limit slave 这个配置项,来增加复制缓冲区的大小,以免复制缓冲区溢出。
repl_backlog_buffer 作用:
主节点和从节点进行常规同步时,会把写命令也暂存在复制积压缓冲区中。 如果从节点和主节点间发生了网络断连,等从节点再次连接后,可以从复制积压缓冲区中同步尚未复制的命令操作。
对主从同步的影响:如果从节点和主节点间的网络断连时间过长,复制积压缓冲区可能被新写入的命令覆盖。 此时,从节点就没有办法和主节点进行增量复制了,而是只能进行全量复制。 针对这个问题,应对的方法是调大复制积压缓冲区的大小 repl_backlog_size。
总的来说,replication buffer 是主从库在进行全量复制时,主库上用于和从库连接的客户端的 buffer。
而 repl_backlog_buffer 是为了支持从库增量复制,主库上用于持续保存写操作的一块专用 buffer。
replication buffer 不是共享的,而是每个从库都有一个对应的客户端。
repl_backlog_buffer 是一块专用 buffer,在 Redis 服务器启动后,开始一直接收写操作命令,这是所有从库共享的。
为什么主从库间的复制不使用 AOF 呢?
- RDB 文件内容是经过压缩的二进制数据,文件很小。无论是要把 RDB 写入磁盘,还是要通过网络传输 RDB, IO 效率都比记录和传输 AOF 的高。
- 在从库端进行恢复时,用 RDB 的恢复效率要高于用 AOF。
- 假设要使用 AOF 做全量同步,意味着必须打开AOF功能,打开 AOF 就要选择文件刷盘的策略,选择不当会严重影响 Redis 性能。 而 RDB 只有在需要定时备份和主从全量同步数据时才会触发生成一次快照。而在很多丢失数据不敏感的业务场景,其实是不需要开启 AOF 的。
Redis 高可用之哨兵集群

Redis 集群

Redis 集群数据倾斜问题

实战篇
Redis 的淘汰策略

四种缓存异常问题及解决方案

Redis 中的原子操作

Redis 是如何实现事务机制的?

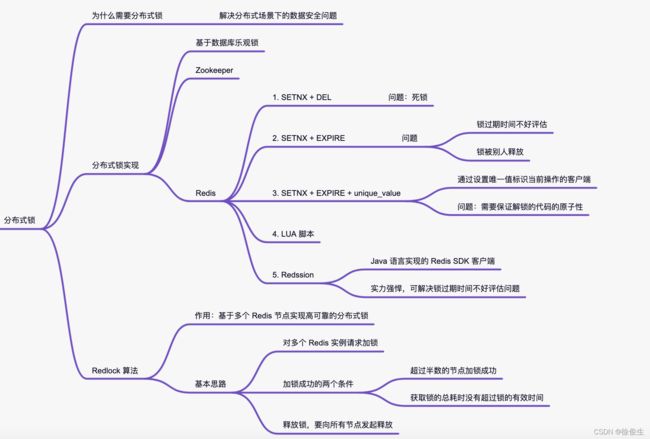
Redis 分布式锁的实现
Redis 实现消息队列

Redis 实现秒杀场景

删除了大量的缓存数据,为何内存使用依然很高?
根本原因是由于存在内存碎片。
操作系统的剩余内存空间总量足够,但是,应用申请的是一块连续地址空间的 N 字节, 但在剩余的内存空间中,没有大小为 N 字节的连续空间了,那么,这些剩余空间就是内存碎片。
内存碎片是如何形成的?
内存碎片的形成有内因和外因两个层面的原因。
- 内因:操作系统的内存分配机制。
- 外因:Redis 的负载特征。
内因:操作系统的内存分配机制
内存分配器的分配策略就决定了操作系统无法做到「按需分配」。 这是因为,内存分配器一般是按固定大小来分配内存,而不是完全按照应用程序申请的内存空间大小给程序分配。
Redis 可以使用 libc、jemalloc、tcmalloc 多种内存分配器来分配内存,默认使用 jemalloc。
拿 jemalloc 来说 , jemalloc 的分配策略之一,是按照一系列固定的大小划分内存空间,例如 8 字节、16 字节、32 字节、48 字节,…, 2KB、4KB、8KB 等。 当程序申请的内存最接近某个固定值时, jemalloc 会给它分配相应大小的空间。
这样的分配方式是为了减少分配次数。
例如,Redis 申请一个 20 字节的空间保存数据,jemalloc 就会分配 32 字节,此时,如果应用还要写入 10 字节的数据, Redis 就不用再向操作系统申请空间了,因为刚才分配的 32 字节已经够用了,这就避免了一次分配操作。
外因:大小不一的键值对和键值对修改删除带来的内存空间变化。
比如,一些键值对被删除了,此时,就会把空间释放出来,形成空闲空间,这些空间是碎片空间,并不是连续的。导致大量的内存碎片生成。
如何判断是否有内存碎片?
查询命令:
INFO memory
有一个 mem_fragmentation_ratio 的指标,它表示的就是 Redis 当前的内存碎片率。
如何清理内存碎片?
- 简单粗暴的方式是重启 Redis 实例,但是可能会造成数据丢失
- 4.0-RC3 版本以后,Redis 提供了内存碎片自动清理的方法
自动清理的原理:简单来说就是,一块连续的内存空间分割成好几块不连续的空间时,操作系统就会把数据拷贝到别处。此时,数据拷贝需要能把这些数据原来占用的空间都空出来,把原本不连续的内存空间变成连续的空间。
代价:操作系统需要把多份数据拷贝到新位置,把原有空间释放出来,这会带来时间开销。 因为 Redis 是单线程,在数据拷贝时,Redis 只能等着,这就导致 Redis 无法及时处理请求,性能就会降低。
启用自动内存碎片清理:
config set activedefrag yes
两个参数:
- active-defrag-ignore-bytes 100mb:表示内存碎片的字节数达到 100MB 时,开始清理;
- active-defrag-threshold-lower 10:表示内存碎片空间占操作系统分配给 Redis 的总空间比例达到 10% 时,开始清理。
控制清理操作占用的 CPU 时间比例的上、下限:
- active-defrag-cycle-min 25: 表示自动清理过程所用 CPU 时间的比例不低于 25%,保证清理能正常开展;
- active-defrag-cycle-max 75:表示自动清理过程所用 CPU 时间的比例不高于 75%,一旦超过,就停止清理, 从而避免在清理时,大量的内存拷贝阻塞 Redis,导致响应延迟升高。
Redis 6.0 新特性

文末福利
脑图下载地址
提取码:8uah
关于 Redis,之前也总结了一些文章,这里一并做了汇总,希望大家加深对 Redis 的全面理解,工作使用中也能更加的得心应手。
文章列表:
1、Redis分布式锁的正确打开方式
2、关于缓存异常:缓存雪崩、击穿、穿透的解决方案
3、一文读懂Redis持久化机制
4、面试官:Redis 事务完全保证 ACID 么?
5、解决缓存和数据库双写数据一致性问题
6、Redis 的内存淘汰机制,看这篇就够了。
7、Redis 集群之主从模式
8、Redis 高可用之哨兵机制
9、Redis 高可用之哨兵集群
10、Redis 高可用之切片集群
如果你喜欢我的文章,欢迎关注我的公众号【ShawnBlog】。