PyTorch基础(五)循环神经网络
RNN简介
我们的大脑区别于机器的一个最大的特征就是我们有记忆,并且能够根据自己的记忆对未知事物进行推导,我们的思想拥有持久性的。但是本教程目前所介绍的神经网络结构各个元素之间是相互独立的,输入与输出是独立的。
RNN的起因
现实世界中,很多元素都是相互连接的,比如室外的温度是随着气候的变化而周期性的变化的、我们的语言也需要通过上下文的关系开确认所表达的含义。但是机器要做到这一步就相当困难了。因此,就有了现在的循环神经网络,他们的本质是:拥有记忆的能力,并且会根据这些记忆的内容来进行推断。因此,他的输出就依赖于当前的输入和记忆。
为什么需要RNN
RNN背后的想法是利用顺序的信息。在传统的神经网络中,我们假设所有输入(输出)彼此独立。如果你们想预测句子中的下一个单词,你就要知道它前面有哪些单词,甚至要看到后面的单词才能够给出正确的答案。
RNN之所以称为循环,就是因为它们对序列的每个元素都会执行相同的任务,所有的输出都取决于先前的计算。从另一个角度讲RNN,它是有“记忆”的,可以捕获到目前为止计算的信息。理论上,RNN可以在任意长的序列中使用信息,但是实际上它们仅限于回顾几个步骤。循环神经网络的提出便是基于记忆模型的想法,期望网络能够记住前面出现的特征。并依据特征推断后面的结果,而且整体的网络结构不断循环,因此叫循环神经网络。
RNN都能做什么
RNN在许多NLP任务中都取得了巨大的成功。下面是RNN在NLP中的一些示例:
- 语言建模与生成文本
通过给定的单词生成一段文本 - 机器翻译
- 语音识别
- 生成图像描述
RNN的网络结构及原理
RNN
RNN的结构很简单,就是将网络的输出保存在一个记忆单元中,然后这个记忆单元和下一次的输入一起进入到神经网络中,下面就是一个RNN的结构示意图:
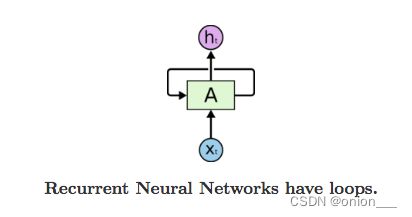
RNN可以被看做是同一神经网络的多次赋值,每个神经网络模块会把消息传递给下一个,下面将RNN结构图展开:
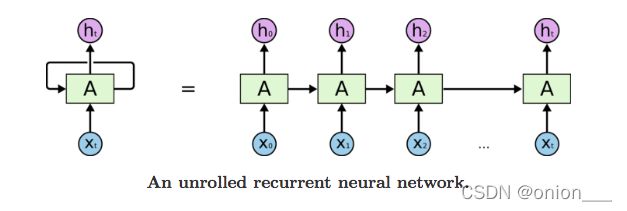
从RNN的结构中可以看出,它本身就是一个序列结构,所以在处理序列类型的数据上有着天然的优势。
RNN具有特别好的记忆特性,但是相对的,记忆最大的问题就是遗忘。
pytorch中使用nn.RNN类来搭建基于序列的循环神经网络,它的构造函数有以下几个参数:
- input_size:输入数据X的特征值的数目
- hidden_size: 隐藏层的神经元数量,也就是隐藏层的特征数量
- num_layers:循环神经网络的层数,默认值为1
- bias:默认为True,如果为false则表示神经元不使用bias偏移参数
- batch_first:如果设置为True,则输入数据的维度中第一个维度就是batch值,默认为False。默认情况下第一个维度是序列的长度,第二个维度才是batch,第三个维度是特征数目
- dropout:如果不为空,则表示最后一个跟一个dropout层抛弃部分数据,抛弃数据的比例由该参数指定。
RNN中最主要的参数是input_size和hidden_size,其他参数通常采用默认值。
import torch
rnn = torch.nn.RNN(20,50,2)
#nn.RNN(input_size, hidden_size, num_layers=1,
#nonlinearity=tanh, bias=True, batch_first=False,
#dropout=0, bidirectional=False)
input = torch.randn(100,32,20)
h_0 = torch.randn(2,32,50)
output, hn = rnn(input,h_0)
print(output.size(),hn.size())
再实现之前,我们先介绍一下RNN的工作机制,RNN其实也是一个普通的神经网络,只不过多了一个hidden_state来保存历史信息。这个hidden_state的作用就是保存之前的状态,我们常说RNN中保存的记忆状态信息,就是这个hidden_state。
对于RNN来说,我们只需要记住一个公式:
![]()
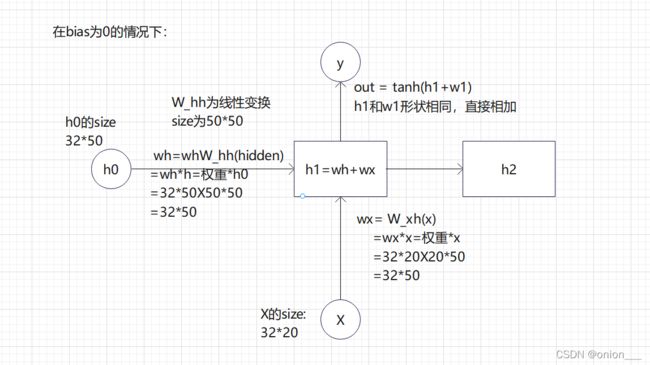
这个公式里边的xt是我们当前状态的输入值,h(t-1)就是上面说的要传入的上一个状态的hidden_state,也就是记忆部分。整个网络要训练的部分就是Wih也就是当前状态输入值的权重,Whh就是上一个状态的权重,还有这两个输入偏置值。这四个值加起来使用tanh进行激活,pytorch默认是使用tanh激活,也可以设置成relu
实现:
#RNN实现
class RNN(object):
def __init__(self,input_size, hidden_size):
super().__init__()
self.W_xh = torch.nn.Linear(input_size, hidden_size)
self.W_hh = torch.nn.Linear(hidden_size, hidden_size)
def __call__(self, x, hidden):
return self.step(x,hidden)
def step(self, x, hidden):
wh = self.W_hh(hidden)
wx = self.W_xh(x)
y = torch.tanh(wh + wx)
hidden = self.W_hh.weight
return y, hidden
rnn = RNN(20,50)
x = torch.randn(32,20)
h0 = torch.randn(32,50)
seq_len = input.shape[0]
for i in range(seq_len):
y, hn = rnn(x[i,:],h0)
print(output.size(),h_0.size())
计算过程图:(仅为自己理解,如有错误欢迎指正)
LSTM
推荐台大李宏毅老师讲的LSTM视频
长的短时记忆网络。LSTM虽然只解决了短期依赖问题,并且它通过刻意的设计来避免长期依赖问题,这样的做法在实际应用中被证明是十分有效的。
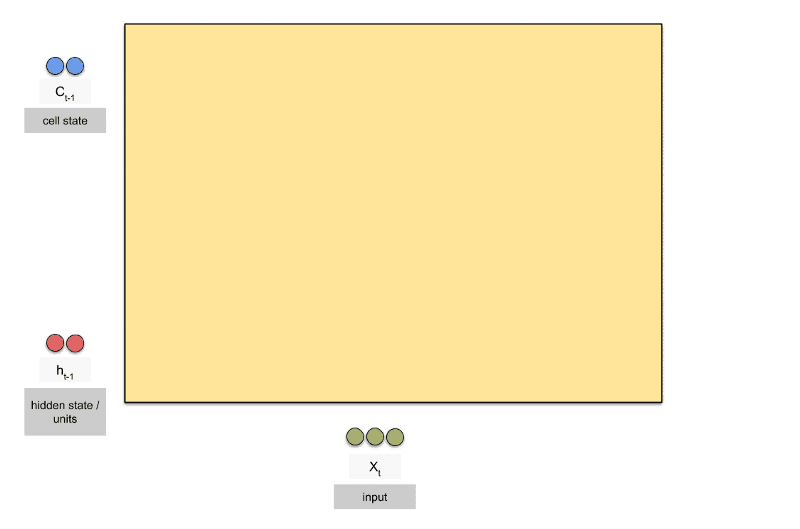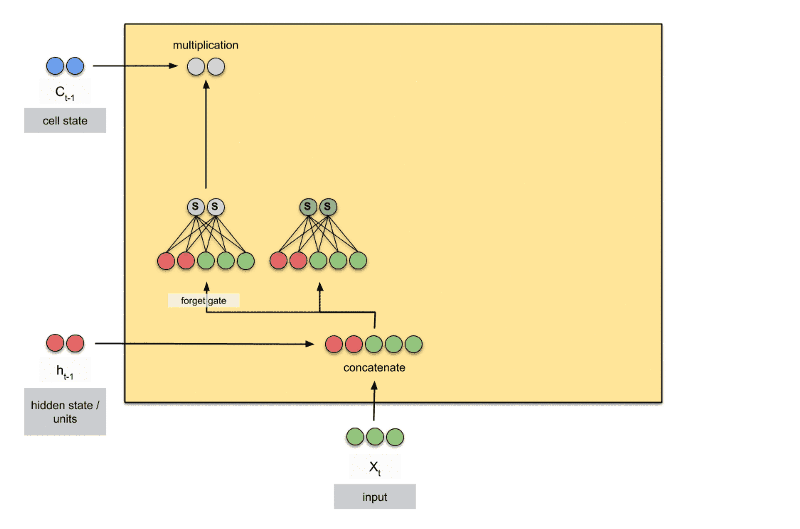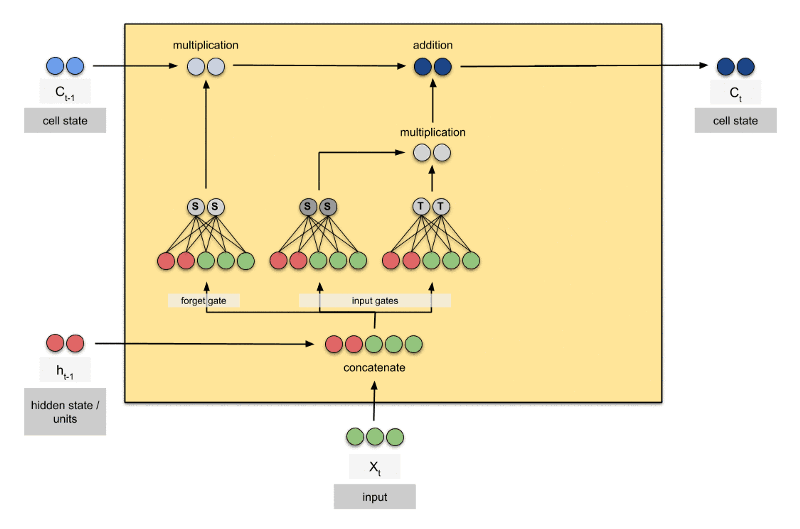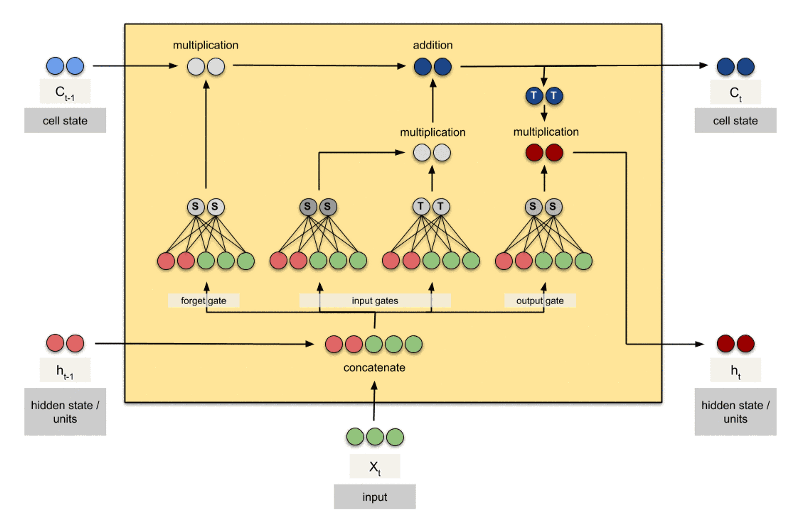
标准的循环神经网络内部只有一个简单的层结构,而LSTM内部有4个层结构:
- 第一层是忘记层:来决定状态中丢弃什么信息
- 第二层tanh层用来产生更新值的候选项,说明状态在某些维度上需要加强,在某些维度上需要减弱
- 第三层sigmoid层,它的输出值要乘到tanh层的输出上,起到一个缩放的作用,极端情况下sigmoid输出0说明相应维度上的状态不需要更新
- 最后一层决定输出什么,输出值跟状态有关。候选项中的哪部分最终会被输出由一个sigmoid层来决定。
lstm = torch.nn.LSTM(10,20,2)
input = torch.randn(5,3,10)
h0 = torch.randn(2,3,20)
c0 = torch.randn(2,3,20)
output, hn = lstm(input, (h0,c0))
print(output.size(), hn[0].size(), hn[1].size())
GRU
GRU是gated recurrent units的缩写。GRU和LSTM最大的不同在于GRU将遗忘门和输入门合成了一个“更新门”,同时网络不再额外给出记忆状态,而是将输出结果作为记忆状态不断向后循环传递,网络的输入和输出都变得特别简单。
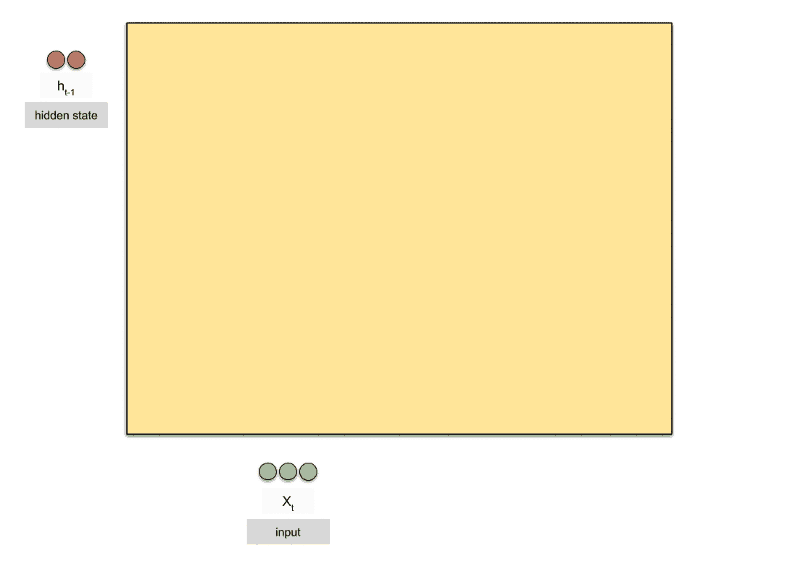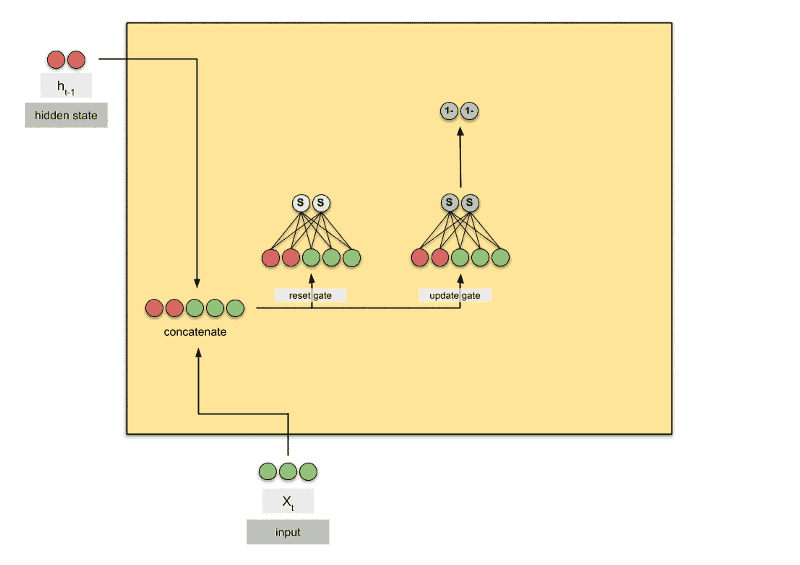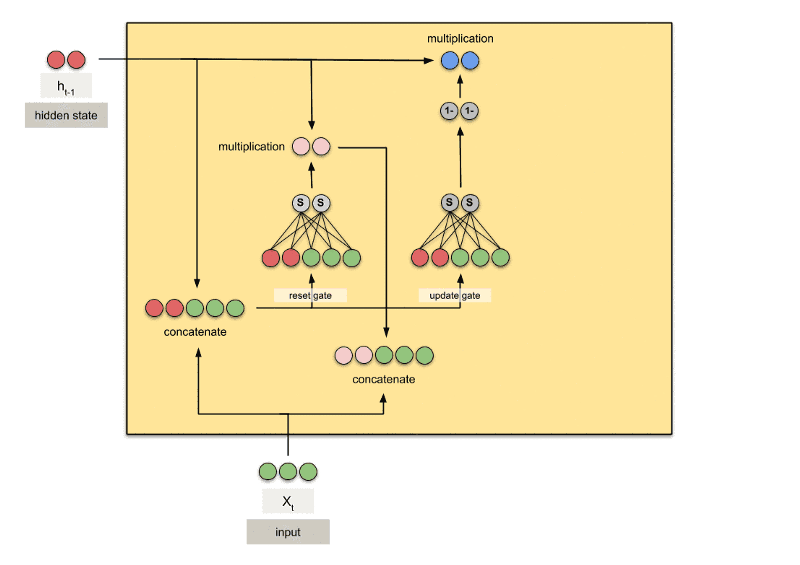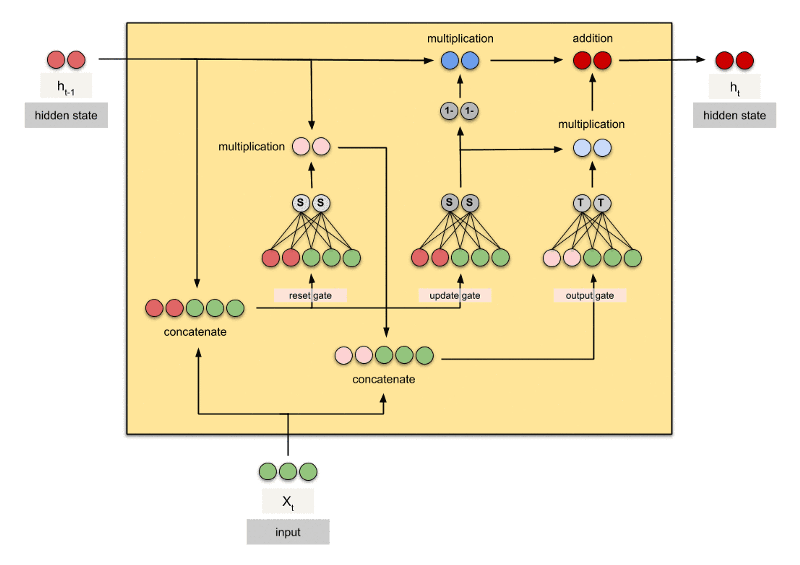
gru = torch.nn.GRU(10,20,2)
input = torch.randn(5,3,10)
h_0 = torch.randn(2,3,20)
output, hn = gru(input, h0)
print(output.size(), hn.size())
循环网络的向后传播(BPTT)
BPTT(back-propagation through time)算法是常用的训练RNN的方法,其实本质还是BP算法,只不过RNN处理时间序列数据,所以要基于时间反向传播,故叫随时间反向传播。
词嵌入(word embedding)
在PyTorch中,我们用nn.Embedding层来做嵌入词袋模型,Embedding层第一个输入表示我们有多少个词,第二个输入表示每一个词使用多少维度的向量表示
# an Embedding module containing 10 tensors of size 3
embedding = torch.nn.Embedding(10, 3)
# a batch of 2 samples of 4 indices each
input = torch.LongTensor([[1, 2, 4, 5], [4, 3, 2, 9]])
output = embedding(input)
print(output.size())
其他重要概念
Beam search(集束搜索)
Beam Search(集束搜索)是一种启发式图搜索算法,通常用在图的解空间比较大的情况下,为了减少搜索所占用的空间和时间,在每一步深度扩展的时候,剪掉一些质量比较差的结点,保留下一些质量较高的结点。虽然Beam Search算法是不完全的,但是用于了解空间较大的系统中,可以减少空间占用和时间。
Beam search可以看做是做了约束优化的广度优先搜索,首先使用广度优先策略建立搜索树,树的每层,按照启发代价对节点进行排序,然后仅留下预先确定的个数(Beam width-集束宽度)的节点,仅这些节点在下一层次继续扩展,其他节点被剪切掉。
- 将初始节点插入到list中
- 将给节点出堆,如果该节点是目标节点,则算法结束;
- 否则扩展该节点,取集束宽度的节点入堆。然后到第二步继续循环。
- 算法结束的条件是找到最优解或者堆为空。
在使用上,集束宽度可以是预先约定的,也可以是变化的,具体可以根据实际场景调整设定。
LSTM待完善。。。。