Potsdam 数据集预处理(切割)
Potsdam 数据集预处理(切割)
- 可视化结果展示
- 总结
Potsdam 数据集是一个优秀的城市语义分割数据集主要包含’background’,‘car’,‘tree’,‘low vegetation’,‘building’,'impervious surfaces’共六个类别。
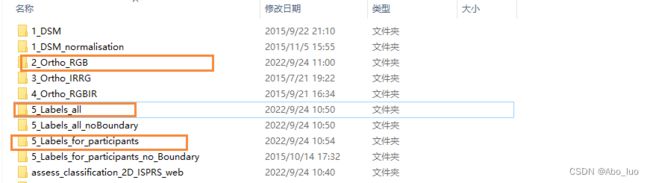
下载完数据集之后解压文件如下,主要使用图片中标注的文件。分别是原始RGB图像,全部标注,部分标注。 采用将部分标注作为训练集,其余图像作为测试集。(PS:2_Ortho_RGB文件夹下的文本文件不清楚是什么,直接删除了)
对程序中的文件路径需要切换,已使用多进程加速!
import cv2
import matplotlib.pyplot as plt
import os
import numpy as np
import multiprocessing
from PIL import Image
# CLASS = ['background','car','tree','low vegetation','building','impervious surfaces']
def crop(img,target,size,overlap,train):
img_name = img.split('//')[-1].split('.')[0]
image = cv2.imread(img)
target = cv2.imread(target)
target = cv2.cvtColor(target,cv2.COLOR_BGR2RGB)
assert image.shape[:2]==target.shape[:2]
number = 0
for i in range((image.shape[0]-size)//overlap+1):
for j in range((image.shape[1]-size)//overlap+1):
image_ = image[i*overlap:i*overlap+size,j*overlap:j*overlap+size,:]
target_ = target[i*overlap:i*overlap+size,j*overlap:j*overlap+size,:].reshape(-1,3)
target_[(target_==[255,0,0]).all(axis=1)] = np.array([0])
target_[(target_ == [255, 255, 0]).all(axis=1)] = np.array([1])
target_[(target_ == [0, 255, 0]).all(axis=1)] = np.array([2])
target_[(target_ == [0, 255, 255]).all(axis=1)] = np.array([3])
target_[(target_ == [0, 0, 255]).all(axis=1)] = np.array([4])
target_[(target_ == [255, 255, 255]).all(axis=1)] = np.array([5])
target_ = target_[:,0]
target_ = target_.reshape(image_.shape[0],image_.shape[1])
if train:
cv2.imwrite(r'F:\work\2022_9\Potsdam\dataset\jpg' + '//' + img_name + str(number) + '.jpg', image_)
cv2.imwrite(r'F:\work\2022_9\Potsdam\dataset\target' + '//' + img_name + str(number) + '.png', target_)
else:
cv2.imwrite(r'F:\work\2022_9\Potsdam\dataset\jpg_test' + '//' + img_name + str(number) + '.jpg', image_)
cv2.imwrite(r'F:\work\2022_9\Potsdam\dataset\target_test' + '//' + img_name + str(number) + '.png', target_)
# print(r'F:\work\2022_9\Potsdam\dataset\jpg'+'//'+img_name+str(number)+'.jpg')
number += 1
image_ = image[i*overlap:i*overlap+size,-size:,:]
target_ = target[i*overlap:i*overlap+size,-size:,:].reshape(-1, 3)
target_[(target_ == [255, 0, 0]).all(axis=1)] = np.array([0])
target_[(target_ == [255, 255, 0]).all(axis=1)] = np.array([1])
target_[(target_ == [0, 255, 0]).all(axis=1)] = np.array([2])
target_[(target_ == [0, 255, 255]).all(axis=1)] = np.array([3])
target_[(target_ == [0, 0, 255]).all(axis=1)] = np.array([4])
target_[(target_ == [255, 255, 255]).all(axis=1)] = np.array([5])
target_ = target_[:, 0]
target_ = target_.reshape(image_.shape[0], image_.shape[1])
if train:
cv2.imwrite(r'F:\work\2022_9\Potsdam\dataset\jpg' + '//' + img_name + str(number) + '.jpg', image_)
cv2.imwrite(r'F:\work\2022_9\Potsdam\dataset\target' + '//' + img_name + str(number) + '.png', target_)
else:
cv2.imwrite(r'F:\work\2022_9\Potsdam\dataset\jpg_test' + '//' + img_name + str(number) + '.jpg', image_)
cv2.imwrite(r'F:\work\2022_9\Potsdam\dataset\target_test' + '//' + img_name + str(number) + '.png', target_)
number += 1
for i in range((image.shape[1]-size)//overlap+1):
image_ = image[-size:,i*overlap:i*overlap+size,:]
target_ = target[-size:,i*overlap:i*overlap+size,:].reshape(-1, 3)
target_[(target_ == [255, 0, 0]).all(axis=1)] = np.array([0])
target_[(target_ == [255, 255, 0]).all(axis=1)] = np.array([1])
target_[(target_ == [0, 255, 0]).all(axis=1)] = np.array([2])
target_[(target_ == [0, 255, 255]).all(axis=1)] = np.array([3])
target_[(target_ == [0, 0, 255]).all(axis=1)] = np.array([4])
target_[(target_ == [255, 255, 255]).all(axis=1)] = np.array([5])
target_ = target_[:, 0]
target_ = target_.reshape(image_.shape[0], image_.shape[1])
if train:
cv2.imwrite(r'F:\work\2022_9\Potsdam\dataset\jpg' + '//' + img_name + str(number) + '.jpg', image_)
cv2.imwrite(r'F:\work\2022_9\Potsdam\dataset\target' + '//' + img_name + str(number) + '.png', target_)
else:
cv2.imwrite(r'F:\work\2022_9\Potsdam\dataset\jpg_test' + '//' + img_name + str(number) + '.jpg', image_)
cv2.imwrite(r'F:\work\2022_9\Potsdam\dataset\target_test' + '//' + img_name + str(number) + '.png', target_)
number += 1
image_ = image[-size:,-size:,:]
target_ = target[-size:,-size:,:].reshape(-1, 3)
target_[(target_ == [255, 0, 0]).all(axis=1)] = np.array([0])
target_[(target_ == [255, 255, 0]).all(axis=1)] = np.array([1])
target_[(target_ == [0, 255, 0]).all(axis=1)] = np.array([2])
target_[(target_ == [0, 255, 255]).all(axis=1)] = np.array([3])
target_[(target_ == [0, 0, 255]).all(axis=1)] = np.array([4])
target_[(target_ == [255, 255, 255]).all(axis=1)] = np.array([5])
target_ = target_[:, 0]
target_ = target_.reshape(image_.shape[0], image_.shape[1])
if train:
cv2.imwrite(r'F:\work\2022_9\Potsdam\dataset\jpg' + '//' + img_name + str(number) + '.jpg', image_)
cv2.imwrite(r'F:\work\2022_9\Potsdam\dataset\target' + '//' + img_name + str(number) + '.png', target_)
else:
cv2.imwrite(r'F:\work\2022_9\Potsdam\dataset\jpg_test' + '//' + img_name + str(number) + '.jpg', image_)
cv2.imwrite(r'F:\work\2022_9\Potsdam\dataset\target_test' + '//' + img_name + str(number) + '.png', target_)
number += 1
# img = img_file+'//'+'top_potsdam_2_10_RGB.tif'
# target = target_file+'//'+'top_potsdam_2_10_label.tif'
# crop(img,target,640,320)
if __name__ == '__main__':
print('开始运行主线程')
img_file = r'F:\work\2022_9\Potsdam\2_Ortho_RGB'
train_target_file = r'F:\work\2022_9\Potsdam\5_Labels_for_participants'
target_file = r'F:\work\2022_9\Potsdam\5_Labels_all'
train_list = os.listdir(train_target_file)
all_list = os.listdir(target_file)
test_list = [i for i in all_list if i not in train_list]
multiprocessing.freeze_support()
multiprocessing.Process()
pool = multiprocessing.Pool(multiprocessing.cpu_count())
SIZE = 640
OVERLAP = 320
for file in all_list:
if file in train_list:
TRAIN = True
else:
TRAIN = False
IMG = img_file+'//'+file.replace('label','RGB')
TARGET = target_file + '//' + file
pool.apply_async(func=crop, args=[IMG,TARGET,SIZE,OVERLAP,TRAIN ])
pool.close()
pool.join()
print('主线程运行结束')
可视化结果展示
总结
可以设置SIZE控制切割后图像的大小,以及OVERLAP控制重叠区域的长度。