多变量特征衍生
1.多项式特征衍生
import pandas as pd
pd.set_option('display.max_columns',None)#显示所有列
data=pd.read_csv(r"C:\Users\15187\Desktop\games1.csv")
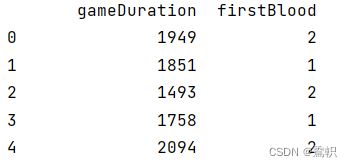
input=data[["gameDuration","firstBlood"]]#这里要嵌套两个列表
下图是使用的数据结构
1.1使用sklearn中PolynomialFeatures方法进行特征衍生
from sklearn.preprocessing import PolynomialFeatures
poly=PolynomialFeatures(degree=2,include_bias=False)
result=poly.fit_transform(input)
input_ploly_df = pd.DataFrame(result, columns=poly.get_feature_names())
print(input_ploly_df)
PolynomialFeatures主要关注两个参数
interaction_only:默认为False,如果选择True,表示只创建交叉项
include_bias,默认为True,即考虑计算特征的0次方,除了需要人工捕捉截距,否则建议修改为False。因为全是1的列没有包含任何有效信息。
运行结果: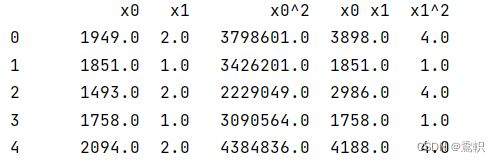
2.交叉特征衍生(两个离散变量常用情景)
下面给出普通代码(包含两个过程:1.生成交叉特征衍生新变量。2.对新变量进行one——hot编码)
import pandas as pd
pd.set_option('display.max_columns',None)#显示所有列
data=pd.read_csv(r"C:\Users\15187\Desktop\games1.csv")
#print(data)
colums=["firstBaron","firstDragon","firstRiftHerald"]
input=data[colums]
#首先定义特征衍生名称
new_colname=[]#存储新生成变量名
new_values=[]#存储重新生成的交叉特征值(1&0,1&1)
for col_index,col_name in enumerate(colums):
for col_sub_index in range(col_index+1,len(colums)):
newname=col_name+"&"+colums[col_sub_index]
new_colname.append(newname)
new_values_df=pd.Series(input[col_name].astype("str")+"&"+input[colums[col_sub_index]].astype("str"),name=newname)
new_values.append(new_values_df)
new_features=pd.concat(new_values,axis=1)#生成数据框形式的新变量
new_features.columns=new_colname#将数据框列名进行替代
new_df=pd.DataFrame()#存储one——hot编码最终结果
#one——hot编码过程
for name in new_colname:
new_df1=pd.get_dummies(new_features[name], prefix=name)
new_df=pd.concat([new_df,new_df1],axis=1)
2.1函数封装
输入:input形式为带列名的数据框()只包含交叉数据
def Cross_feature(input):
import pandas as pd
colums=list(input.columns)
new_colname=[]#存储新生成变量名
new_values=[]#存储重新生成的交叉特征值(1&0,1&1)
for col_index,col_name in enumerate(colums):
for col_sub_index in range(col_index+1,len(colums)):
newname=col_name+"&"+colums[col_sub_index]
new_colname.append(newname)
new_values_df=pd.Series(input[col_name].astype("str")+"&"+input[colums[col_sub_index]].astype("str"),name=newname)
new_values.append(new_values_df)
new_features=pd.concat(new_values,axis=1)
new_features.columns=new_colname
new_df=pd.DataFrame()#存储one——hot编码最终结果
for name in new_colname:
new_df1=pd.get_dummies(new_features[name], prefix=name)
new_df=pd.concat([new_df,new_df1],axis=1)
return new_df
result=Cross_feature(input)
print(result)
直接输入原始数据框和需要交叉的列名函数
def Cross_feature(colname,data):
import pandas as pd
colums=colname
input=data
new_colname=[]#存储新生成变量名
new_values=[]#存储重新生成的交叉特征值(1&0,1&1)
for col_index,col_name in enumerate(colums):
for col_sub_index in range(col_index+1,len(colums)):
newname=col_name+"&"+colums[col_sub_index]
new_colname.append(newname)
new_values_df=pd.Series(input[col_name].astype("str")+"&"+input[colums[col_sub_index]].astype("str"),name=newname)
new_values.append(new_values_df)
new_features=pd.concat(new_values,axis=1)
new_features.columns=new_colname
new_df=pd.DataFrame()#存储one——hot编码最终结果
for name in new_colname:
new_df1=pd.get_dummies(new_features[name], prefix=name)
new_df=pd.concat([new_df,new_df1],axis=1)
return new_df
3.分组汇总统计
3.1分组汇总统计之离散——连续(可以同时进行多字段分类计算)
3.1.1非函数形式
import pandas as pd
pd.set_option('display.max_columns',None)#显示所有列
data=pd.read_csv(r"C:\Users\15187\Desktop\games1.csv")
#print(data)
#保证列表第一列是分类变量
class_col=["firstBlood","firstDragon"]#分组字段
caculate_col=["gameDuration","t2_towerKills"]#分组统计字段
import copy
#这里分类变量做分组依据,连续变量做分组统计特征
aggs={}
for col in caculate_col:
aggs[col]=["mean","min","max"]
col_class_name="_".join(class_col)
cols=copy.deepcopy(class_col)
for key in aggs.keys():
cols.extend(key+"_"+col_class_name+"-"+i for i in aggs[key])
feature_new=data.groupby(by=class_col).agg(aggs).reset_index()
feature_new.columns=cols
result=pd.merge(data,feature_new,how="left",on=class_col)
print(result.head())
3.1.2函数封装形式
def class_satisfic(feature1,feature2,o_data):
#feature1(list):分组依据名,feature2(list):分组统计字段名,o_data(DF):原始数据框
import copy
# 这里分类变量做分组依据,连续变量做分组统计特征
class_col = feature1 # 分组字段
caculate_col = feature2 # 分组统计字段
data=o_data #原始数据
aggs = {}
for col in caculate_col:
aggs[col] = ["mean", "min", "max"]
col_class_name = "_".join(class_col)
cols = copy.deepcopy(class_col)
for key in aggs.keys():
cols.extend(key + "_" + col_class_name + "-" + i for i in aggs[key])
feature_new = data.groupby(by=class_col).agg(aggs).reset_index()
feature_new.columns = cols
#进行左连接,按照分组统计字段
result = pd.merge(data, feature_new, how="left", on=class_col)
return result
print(class_satisfic(class_col,caculate_col,data))
3.1.3 黄金组合特征、流量平滑特征、归一化(一般形式和函数封装形式)
import pandas as pd
import math
pd.set_option('display.max_columns',None)#显示所有列
data=pd.read_csv(r"C:\Users\15187\Desktop\games1.csv")
#print(data)
#保证列表第一列是分类变量
class_col=["firstBlood","firstDragon"]#分组字段
caculate_col=["gameDuration","t2_towerKills"]#分组统计字段
import copy
#这里分类变量做分组依据,连续变量做分组统计特征
aggs={}
for col in caculate_col:
aggs[col]=["mean","std"]
col_class_name="_".join(class_col)
cols=copy.deepcopy(class_col)
for key in aggs.keys():
cols.extend(key+"_"+col_class_name+"-"+i for i in aggs[key])
feature_new=data.groupby(by=class_col).agg(aggs).reset_index()
feature_new.columns=cols
result=pd.merge(data,feature_new,how="left",on=class_col)
cols1=[]
aggs={}
for col in caculate_col:
aggs[col]=["mean"]
for key in aggs.keys():
cols1.extend(key+"_"+col_class_name+"-"+"GOLD_"+i for i in aggs[key])
cols1.extend(key + "_" + col_class_name + "-" + "FSC_" + i for i in aggs[key])
cols1.extend(key + "_" + col_class_name + "-" + "std_" + i for i in aggs[key])
FSC_feature=pd.DataFrame()
for i in range(len(caculate_col)):
D2 =pd.DataFrame(result[caculate_col[i]] /((result[cols[(len(cols) - len(class_col) + i)]]))+math.exp(-5))
D1=pd.DataFrame(result[caculate_col[i]]-result[cols[(len(cols)-len(class_col)+i)]])
D3=pd.DataFrame((result[caculate_col[i]]-result[cols[(len(class_col)+i*2)]])/result[cols[(len(class_col)+i*2+1)]])
FSC_feature=pd.concat([FSC_feature,D1,D2,D3],axis=1)
FSC_feature.columns=cols1
result1=pd.concat([result,FSC_feature],axis=1)
封装
def class_satisfic(feature1,feature2,o_data):
#feature1(list):分组依据名,feature2(list):分组统计字段名,o_data(DF):原始数据框
import copy
# 这里分类变量做分组依据,连续变量做分组统计特征
class_col = feature1 # 分组字段
caculate_col = feature2 # 分组统计字段
data=o_data #原始数据
# 这里分类变量做分组依据,连续变量做分组统计特征
aggs = {}
for col in caculate_col:
aggs[col] = ["mean", "std"]
col_class_name = "_".join(class_col)
cols = copy.deepcopy(class_col)
for key in aggs.keys():
cols.extend(key + "_" + col_class_name + "-" + i for i in aggs[key])
feature_new = data.groupby(by=class_col).agg(aggs).reset_index()
feature_new.columns = cols
result = pd.merge(data, feature_new, how="left", on=class_col)
cols1 = []
aggs = {}
for col in caculate_col:
aggs[col] = ["mean"]
for key in aggs.keys():
cols1.extend(key + "_" + col_class_name + "-" + "GOLD_" + i for i in aggs[key])
cols1.extend(key + "_" + col_class_name + "-" + "FSC_" + i for i in aggs[key])
cols1.extend(key + "_" + col_class_name + "-" + "std_" + i for i in aggs[key])
FSC_feature = pd.DataFrame()
for i in range(len(caculate_col)):
D2 = pd.DataFrame(result[caculate_col[i]] / ((result[cols[(len(cols) - len(class_col) + i)]])) + math.exp(-5))
D1 = pd.DataFrame(result[caculate_col[i]] - result[cols[(len(cols) - len(class_col) + i)]])
D3 = pd.DataFrame((result[caculate_col[i]] - result[cols[(len(class_col) + i * 2)]]) / result[
cols[(len(class_col) + i * 2 + 1)]])
FSC_feature = pd.concat([FSC_feature, D1, D2, D3], axis=1)
FSC_feature.columns = cols1
result1 = pd.concat([result, FSC_feature], axis=1)
return result1
3.2.分组汇总统计之离散——离散
def class_satisfic(feature1,feature2,o_data):
#feature1(list):分组依据名,feature2(list):分组统计字段名,o_data(DF):原始数据框
import copy
# 这里分类变量做分组依据,连续变量做分组统计特征
class_col = feature1 # 分组字段
caculate_col = feature2 # 分组统计字段
data=o_data #原始数据
aggs = {}
for col in caculate_col:
aggs[col] = ["count", "nunique"]#可以通过更改这里的函数进行其他函数添加
col_class_name = "_".join(class_col)
cols = copy.deepcopy(class_col)
for key in aggs.keys():
cols.extend(key + "_" + col_class_name + "-" + i for i in aggs[key])
feature_new = data.groupby(by=class_col).agg(aggs).reset_index()
feature_new.columns = cols
#进行左连接,按照分组统计字段
result = pd.merge(data, feature_new, how="left", on=class_col)
return result