-文本分类
目录
第11章 文本分类
11.1 文本分类的概念
11.2 文本分类语料库
11.3 文本分类的特征提取
11.4 朴素贝叶斯分类器
11.5 支持向量机分类器
11.6 标准化评测
11.7 情感分析
11.8 总结
第11章 文本分类
上一章我们学习了文本聚类,体验了无须标注语料库的便利性。然而无监督学习总归无法按照我们的意志预测出文挡的类别,限制了文本聚类的应用场景。有许多场景需要将文档分门别类地归入具体的类别中,比如垃圾邮件过滤和社交媒体的自动标签推荐。在这一章中,我们将介绍如何实现这些需求,包括设计分类器来给文档分类,以及相应的语料库等。
11.1 文本分类的概念
文本分类(text classification),又称文档分类(document classification),指的是将一个文档归类到一个或多个类别中的自然语言处理任务。文本分类的应用场景非常广泛,涵盖垃圾邮件过滤、垃圾评论过滤、自动标签等任何需要自动归档文本的场合。此外,文档级别的情感分析也可以视作文本分类任务。此时情感分析的目的就是判断一段文本是否属于“正面”“负面”等情感。
文本的类别(category或class)有时又称标签(label),所有类别组成一个标注集。文本分类系统无法预测标注集之外的类别,换句话说,其输出结果一定属于标注集。比如说,假设标注集共含有“财经”“体育”这2个类別,则此时的文本分类系统的输出结果一定属于二者之一。哪怕将一篇“旅游”新闻作为输入,其结果依然是“财经”或“体育”。如果用户需要支持“旅游”的判别,则需要重新定义标注集。在自然语言处理中,标注集一般是固定不变的,需要提前谨慎设计。
每篇文档一般只属于一个类别,这是最常见的情形,也是本课程和HanLP的假设。如果一篇文档可能属于多个类别,此时问题称为多标签分类(multi-label classification)。
文本分类是一个典型的监督学习任务,其流程离不开人工指导:人工标注文档的类别,利用语料训练模型,利用模型预测文档的类别。在学习理论之前,需要先熟悉一下文本分类语料库,以便对我们处理的问题有一番具体印象。根据数据选择或设计算法也是数据科学工程师的良好习惯。
11.2 文本分类语料库
文本分类语料库的标注过程相对简单,只需收集一些文档,人工指定每篇文档的类别即可。另外,许多新闻网站的栏目是由编辑人工整理的,如果栏目设置符合要求,也可以用爬虫爬取下来作为语料库使用。其中,搜狗实验室就提供了这样一份语料库,我们在第10章已经使用过。搜狗文本分类语料库的形式是文件夹结构,我们可以用HanLP提供的IDataSet加载。IDataSet是对数据集的逻辑抽象,提供加载和遍历接口。其实现有基于内存的MemoryDataSet,以及基于文件系统的FileDataSet。它们的继承关系如图11-1所示。 图11-1数据集IDataSet的设计
图11-1数据集IDataSet的设计
搜狗语料库体积较小,此处选择用MemoryDataSet将其全部加载到内存中。代码(tests/book/ch11/demo_load_text_classification_corpus.py)如下:
from pyhanlp import *
from test_utility import ensure_data
sogou_corpus_path = ensure_data('搜狗文本分类语料库迷你版','http://file.hankcs.com/corpus/sogou-text-classification-corpus-mini.zip')
# AbstractDataSet = JClass('com.hankcs.hanlp.classification.corpus.AbstractDataSet')
# Document = JClass('com.hankcs.hanlp.classification.corpus.Document')
# FileDataSet = JClass('com.hankcs.hanlp.classification.corpus.FileDataSet')
MemoryDataSet = JClass('com.hankcs.hanlp.classification.corpus.MemoryDataSet')
# 演示加载文本分类语料库
if __name__ == '__main__':
dataSet = MemoryDataSet() # ①将数据集加载到内存中
dataSet.load(sogou_corpus_path) # ②加载data/test/搜狗文本分类语料库迷你版
dataSet.add("自然语言处理", "自然语言处理很有趣") # ③新增样本
allClasses = dataSet.getCatalog().getCategories() # ④获取标注集
print("标注集:%s" % (allClasses))
for document in dataSet.iterator():
print("第一篇文档的类别:" + allClasses.get(document.category))
break运行结果如下:
标注集:[体育, 健康, 军事, 教育, 汽车, 自然语言处理]
第一篇文档的类别:体育
其中③处模拟了人工标注的过程,新增了一篇标注文档。其类别为“自然语言处理”,内容为“自然语言处理很有趣”。由于引入了新的类别,所以后面输出标注集的大小为6。如果需要设计标注和训练一体化系统,可以考虑使用该接口灵活地加载来自其他数据源的语料。
当语料库就绪时,文本分类的流程一般分为特征提取和分类器处理两大步,接下来的几节将会逐一介绍其中的细节。
11.3 文本分类的特征提取
在机器学习中,我们需要对具体对象提取出有助于分类的特征,才能交给某个分类器进行分类。这些特征数值化后为一个定长的向量(数据点),用来作为分类器的输入。在训练时,分类器根据数据集中的数据点学习出决策边界(参考5.2.2节)。在预测时,分类器根据输入的数据点落在决策边界的位置来决定类别。
与第10章一样,我们依然使用词袋向量作为特征向量,词袋向量是词语颗粒度上的频次或 TF-IDF 向量,为此需要先进行分词。
11.3.1 分词
HanLP允许为数据集AbstractDataSet的构造函数指定一个分词器ITokenizer,用来实现包括分词在内的预处理逻辑。其中,ITokenizer接口如下:
目前HanLP实现了如表11-1所示的几种ITokenizer,适用于不同的场景。
表11-1 HanLP 预置的ITokenizer
| 实现 | 应用场景 |
|---|---|
| HanLPTokenizer | 中文文本,使用NotionalTokenizer分词并过滤停用词 |
| BlankTokenizer | 英文文本,使用空格分词 |
| BigramTokenizer | 中文文本,将相邻字符作为二元语法输出 |
HanLP中的文本分类模块不光适用于中文,还适用于任意语种,只需实现相应的ITokenizer即可。 此外,文本分类并不一定需要进行分词。根据清华大学2016年的工作THUCTC: An Efficient Chinese Text Classfier,将文本中相邻两个字符构成的所有二元语法作为“词”,反而能取得更好的分类准确率。在HanLP中相应的“分词器”实现为BigramTokenizer,我们将在后续节试验该方法的效果。当分词等预处理结束后,就可以从这些词语中挑出有用的子集作为特征。
11.3.2 卡方特征选择
对于文本分类而言,其特征提取过程与文本聚类相同,特征提取的结果都为词袋模型下的稀疏向量(词袋向量)。唯一有所不同的是,许多常用单词对分类决策的帮助不大,比如汉语的虚词“的”和标点符号等。也可能有一些单词在所有类别的文档中均匀出现。为了消除这些单词的影响,一方面可以用停用词表,另一方面可以用卡方非参数检验(Chi-squared test,χ2χ2)来过滤掉与类别相关程度不高的词语。
在统计学中,χ2χ2卡方检验常用于检验两个事件的独立性。如果两个随机事件 AA 和 BB 相互独立,则两者同时发生的概率P(AB)=P(A)P(B)P(AB)=P(A)P(B)。如果将词语的出现与类别的出现作为两个随机事件则类别独立性越高的词语越不适合作为特征。如果将某个事件的期望记作 EE,实际出现(观测)的频次记作 NN,则卡方检验χ2χ2衡量期望与观测的相似程度。卡方检验值χ2χ2越高,则期望和观测的计数越相似,也更大程度地否定了独立性。
比如在正负情感分析中,我们想要计算词语“高兴”的χ2χ2值。假设语料库D中所有词语在正负文档中出现频次的统计信息如表11-2所示。
表11-2 语料库的统计信息
为了形式化描述,需要引入一些记号。随机取一个词语,将该词语是否为 tt 记作etet;随机取一个文档,其类别是否为 cc 记作 ecec,则表11-2用记号重新表示为表11-3。
表11-3四个事件的观测
我们需要计算etet与ecec两个事件同时成立与否的4种组合(即E11,E10,E01,E00E11,E10,E01,E00)的期望。以E11E11(词语为“高兴”且文档为“正面”的期望)为例,其计算方法如下:
E11=N×P(t)×P(c)=N×N11+N10N×N11+N01N=N×49+27652N×49+141N≈6.6(11.1)(11.1)E11=N×P(t)×P(c)=N×N11+N10N×N11+N01N=N×49+27652N×49+141N≈6.6
其中NN为所有词语的词频之和,即N=E11+E10+E01+E00N=E11+E10+E01+E00。类似地,我们计算出E11,E10,E01,E00E11,E10,E01,E00填入表11-4。
表11-4四个事件的期望
将表11-3和表11-4代入χ2χ2的计算公式:
χ2(,t,c)=∑et∈{0,1}∑ec∈{0,1}(Netec−Eet,ec)2Eetec(11.2)(11.2)χ2(D,t,c)=∑et∈{0,1}∑ec∈{0,1}(Netec−Eet,ec)2Eetec
我们得到词语“高兴”与类别“正面”的卡方检验值χ2(,t=高兴,c=正面)≈284χ2(D,t=高兴,c=正面)≈284,这个值是高是低,究竟说明了什么呢?根据自由度为1的χ2χ2分布的临界值(如表11-5所示):当χ2>6.63χ2>6.63时,两个事件独立的置信度小于0.01。
表11-5自由度为1的χ2χ2分布的临界值表
由于χ2(,t=高兴,c=正面)≈284>10.83χ2(D,t=高兴,c=正面)≈284>10.83,所以词语“高兴”和类别“正面”的独立假设成立的置信度小于0.001。换句话说,两者相关的置信度大于99.9%,说明“高兴”是一个非常有用的特征。
另外,通过将式(11.1)代入式(11.2),我们可以得到一个简便的卡方检验值计算公式:
χ2(,t,c)=(N11+N10+N01+N00)×(N11N00−N10N01)2(N11+N01)×(N11+N10)×(N10+N00)×(N01+N00)χ2(D,t,c)=(N11+N10+N01+N00)×(N11N00−N10N01)2(N11+N01)×(N11+N10)×(N10+N00)×(N01+N00)
(11.3)(11.3)
上面我们解决的是情感极性二分类问题,更进一步,卡方检验还可以拓展到多分类问题。当cc有多个时,比如c∈{教育,汽车,健康,军事,体育}c∈{教育,汽车,健康,军事,体育},我们取最大的卡方值作为特征的最终卡方值,即下式所示:
χ2=max{χ2(,t,c);c∈C}(11.4)(11.4)χ2=max{χ2(D,t,c);c∈C}
计算出每个特征(词语或二元语法等)的卡方值后,去掉卡方值小于10.83(pp值为0.001)的特征,就可以减小计算量。
一旦确定了哪些特征有用,接下来就可以将文档转化为向量了。
11.3.3 词袋向量
我们提取的是 TF 特征,统计出每个特征及其频次。以特征的 id 作为下标,频次作为数值,假设一共有 nn 个特征,一篇文档就转化为 nn 维的词袋向量。沿用机器学习文献的习惯,将词袋向量记作x∈⊆ℝnx∈X⊆Rn,向量的第 ii 维记作 xixi。将类别记 作 y∈={c1,c2,⋯,cK}y∈Y={c1,c2,⋯,cK},其中 KK 为类别总数。则语料库(训练数据集) TT 可以表示为词袋向量 xx 和类别 yy 所构成的二元组的集合:
T={(x(1),y1),(x(2),y2),⋯,(x(N),yN)}(11.5)(11.5)T={(x(1),y1),(x(2),y2),⋯,(x(N),yN)}
在不进行特征选择的前提下,如果以词语作为特征,则 nn 大约在 10 万量级;如果以字符二元语法作为特征,则 nn 大约在 50 万量级。数十万维的向量运算开销不容小觑,一般利用卡方特征选择,可以将特征数量减小到10% ~ 20%左右。
当文档被转化为向量后,就可以利用机器学习进行训练了。
11.4 朴素贝叶斯分类器
在各种各样的分类器中,朴素贝叶斯法( naive Bayes)可算是最简单常用的一种生成式模型。朴素贝叶斯法基于贝叶斯定理将联合概率转化为条件概率,然后利用特征条件独立假设简化条件概率的计算。
11.4.1 朴素贝叶斯法原理
朴素贝叶斯法的目标是通过训练集学习联合概率分布 p(X,Y)p(X,Y),由贝叶斯定理可以将联合概率转换为先验概率分布与条件概率分布之积:
p(X=x,Y=ck)=p(Y=ck)p(X=x∣Y=ck)(11.6)(11.6)p(X=x,Y=ck)=p(Y=ck)p(X=x∣Y=ck)
类别的先验概率分布p(Y=ck)p(Y=ck)很容易估计,通过统计每个类别下有多少样本即可(极大似然),即:
p(Y=ck)=count(Y=ck)N(11.7)(11.7)p(Y=ck)=count(Y=ck)N
而 p(X=x|Y=ck)p(X=x|Y=ck)则难以估计,因为 xx 的量级非常大,可以从下式看出来:![]()
(11.8)(11.8)
假设第ii维xixi有mimi种取值,那么组合起来xx一共有∏nimi∏inmi种。该条件概率分布的参数数量是指数级的,特别是当特征数量达到十万量级时,参数估计实际上不可行。为此,朴素贝叶斯法“朴素”地假设了所有特征是条件独立的。该条件独立性假设为:
(11.9)(11.9)
于是,又可以利用极大似然来进行估计:![]()
(11.10)(11.10)
也就是说,给定类别为ckck的条件下,特征向量第ii维为某个特定值xixi的概率等于类别为ckck且第ii维为xixi的样本数量除以类别ckck下的所有样本数量。有了p(Y=ck)p(Y=ck)和p(Xi=xi∣Y=ck)p(Xi=xi∣Y=ck)之后,朴素贝叶斯模型的参数估计(训练)就结束了。
在预测时,朴素贝叶斯法依然利用贝叶斯公式找出后验概率 p(Y=ck|X=x)p(Y=ck|X=x) 最大的类别 ckck 作为输出 yy:![]()
(11.11)(11.11)
将贝叶斯公式带入上式得:![]()
(11.12)(11.12)
由于分母p(X=x)p(X=x)与 ckck 无关,,在求最大后验概率时可以省略掉,亦即:
y=argmaxckp(X=x∣Y=ck)p(Y=ck)(11.13)(11.13)y=argmaxckp(X=x∣Y=ck)p(Y=ck)
然后将独立性假设式(11.9)代入上式,得到 最终的分类预测函数: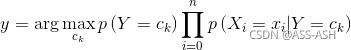
(11.14)(11.14)
其中两个概率分布的参数已经通过式(11.7)和式(11.10)估计出了,而且都是简单的计数统计,相信读者能够轻松地在脑海中勾画出大体的实现。
11.4.2 朴素贝叶斯分类器实现
HauLP中的分类器由IClassifier接口提供,一共实现了朴素贝叶斯分类器NaiveBayesClassifier以及线性支持向量机分类器LinearSVMClassifier。文本分类模块的架构设计如图11-2所示。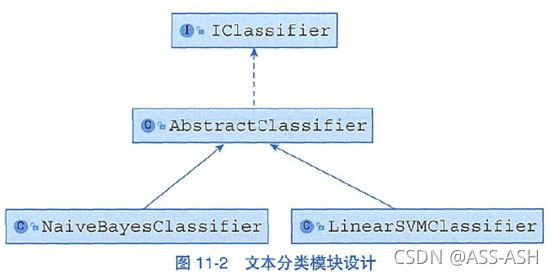
Iclassifier中最重要的两个方法为训练和分类接口:

至于具体实现,我们将在下一节介绍支持向量机,本节则介绍HanLP实现的朴素贝叶斯分类器的基本使用和核心代码。朴素贝叶斯模型中最重要的两个成员为先验概率p(Y=ck)p(Y=ck)和条件概率p(X(i)=x(i)∣Y=ck)p(X(i)=x(i)∣Y=ck),如下所示:
为了数值稳定性,代码对概率取了对数。训练基本思路是统计式(11.7)和式(11.10)中的计数,填充这两个成员。利用式(11.14)计算随机变量YY的分布,取最大后验概率对应的ckck作为结果返回。
为了使用贝叶斯分类器,必须训练或加载一个模型,调用方法为:

代码如下:
import os
from pyhanlp import SafeJClass
from test_utility import ensure_data
NaiveBayesClassifier = SafeJClass('com.hankcs.hanlp.classification.classifiers.NaiveBayesClassifier')
IOUtil = SafeJClass('com.hankcs.hanlp.corpus.io.IOUtil')
sogou_corpus_path = ensure_data('搜狗文本分类语料库迷你版',
'http://file.hankcs.com/corpus/sogou-text-classification-corpus-mini.zip')
def train_or_load_classifier():
'''该函数检查给定路径中是否存在已训练的模型,若有则加载,否则在搜狗语料库上
训练模型并保存到磁盘。调用该函数后得到一个贝叶斯模型,传入贝叶斯分类器
NaiveBayesClassifier后即可对任意文本进行分类了。'''
model_path = sogou_corpus_path + '.ser'
if os.path.isfile(model_path):
return NaiveBayesClassifier(IOUtil.readObjectFrom(model_path))
classifier = NaiveBayesClassifier()
classifier.train(sogou_corpus_path)
model = classifier.getModel()
IOUtil.saveObjectTo(model, model_path)
return NaiveBayesClassifier(model)
def predict(classifier, text):
print("《%16s》\t属于分类\t【%s】" % (text, classifier.classify(text)))
# 如需获取离散型随机变量的分布,请使用predict接口
# print("《%16s》\t属于分类\t【%s】" % (text, classifier.predict(text)))
if __name__ == '__main__':
classifier = train_or_load_classifier()
predict(classifier, "C罗获2018环球足球奖最佳球员 德尚荣膺最佳教练")
predict(classifier, "英国造航母耗时8年仍未服役 被中国速度远远甩在身后")
predict(classifier, "研究生考录模式亟待进一步专业化")
predict(classifier, "如果真想用食物解压,建议可以食用燕麦")
predict(classifier, "通用及其部分竞争对手目前正在考虑解决库存问题")运行结果如下:
《C罗获2018环球足球奖最佳球员 德尚荣膺最佳教练》 属于分类 【体育】
《英国造航母耗时8年仍未服役 被中国速度远远甩在身后》 属于分类 【军事】
《 研究生考录模式亟待进一步专业化》 属于分类 【教育】
《如果真想用食物解压,建议可以食用燕麦》 属于分类 【健康】
《通用及其部分竞争对手目前正在考虑解决库存问题》 属于分类 【汽车】
朴素贝叶斯法实现简单,但由于特征独立性假设过于强烈,有时会影响准确性,下面开始介绍更加健壮的支持向量机分类器。
11.5 支持向量机
支持向量机(Support Vector Machine,SVM)是一种二分类模型,其学习策略在于如何找出一个决策边界,使得边界到正负样本的最小距离都最远。这种策略使得支持向量机有别于感知机,能够找到一个更加稳健的决策边界。支持向量机最简单的形式为线性支持向量机,其决策边界为一个超平面(参考5.2.2节),适用于线性可分数据集。
11.5.1 线性支持向量机
给定训练集:
T={(x(1),y1),(x(2),y2),⋯,(x(N),yN)},y∈={±1}T={(x(1),y1),(x(2),y2),⋯,(x(N),yN)},y∈Y={±1}
(11.15)(11.15)
线性支持向量机的学习目标是找到一个分离超平面w⋅x+b=0w⋅x+b=0,将二类样本分离开来。当数据集线性可分时,存在无数个满足要求的超平面,如图11-3所示。
虽然三条分离超平面都将正负样本完全分离开了,但直觉上只有中间的实线才是最佳的。因为两条虚线离样本点太近了,没有预留出足够的“安全距离”。如果测试集中的数据稍微偏离训练集分布一点,则很有可能带来误分类的风险。支持向量机的学习策略就是尽量找出离正负样本的间隔最大的分离超平面,以降低测试集上的风险。
如何计算间隔呢?定义样本点(x(i),y)(x(i),y)到超平面的距离为几何间隔:
γi=yiw⋅x(i)+b∥w∥(11.16)(11.16)γi=yiw⋅x(i)+b∥w∥
对整个数据集来讲,几何间隔为所有样本点的几何间隔之最小值:
γ=mini=1,⋯,Nγi(11.17)(11.17)γ=mini=1,⋯,Nγi
支持向量机的训练思路是最大化所有样本点的集合间隔之最小值,即下列约束最优化问题:
maxw,bγ s.t. yiw⋅x(i)+b∥w∥⩾γ,i=1,2,⋯,N(11.18)(11.18)maxw,bγ s.t. yiw⋅x(i)+b∥w∥⩾γ,i=1,2,⋯,N
定义函数间隔为:
γ̂ =γ∥w∥(11.19)(11.19)γ^=γ∥w∥
取函数间隔为1,得到:
γ=1∥w∥(11.20)(11.20)γ=1∥w∥
将式(11.20)代入式(11.18)中,得到:
maxw,b s.t. 1∥w∥yi(w⋅x+b)⩾1,i=1,2,⋯,Nmaxw,b1∥w∥ s.t. yi(w⋅x+b)⩾1,i=1,2,⋯,N
(11.21)(11.21)
由于最大化1∥w∥1∥w∥等价于最小化12∥w∥212∥w∥2 ,所以式(11.21)等价于:
minw,b s.t. 12∥w∥2yi(w⋅xi+b)−1⩾0,i=1,2,⋯,Nminw,b12∥w∥2 s.t. yi(w⋅xi+b)−1⩾0,i=1,2,⋯,N
(11.22)(11.22)
式(11.22)是一个凸二次规划问题,可以利用拉格朗日法求解出最优解w∗,b∗w∗,b∗。于是得到分类决策函数:
y=f(x)=sign(w∗⋅x+b∗)(11.22)(11.22)y=f(x)=sign(w∗⋅x+b∗)
也就是说,通过在训练集上进行的一系列数值优化,我们得到了超平面方程w∗⋅x+b∗w∗⋅x+b∗。对于新的实例xx,只要代入式(11.23),就能预测出类别yy。此时y∈{±1}y∈{±1}即属于二分类问题,我们可以通过5.1.1节介绍的one-vs-one或one-vs-rest拓展到多分类问题。
备注
有关支持向量机(SVM)的原理也可以参考博客http://mantchs.com/2019/07/11/ML/SVM/
11.5.2 线性支持向量机文本分类器实现
from pyhanlp import *
from pyhanlp.static import STATIC_ROOT, download
import os
from test_utility import ensure_data
def install_jar(name, url):
dst = os.path.join(STATIC_ROOT, name)
if os.path.isfile(dst):
return dst
download(url, dst)
return dst
install_jar('text-classification-svm-1.0.2.jar', 'http://file.hankcs.com/bin/text-classification-svm-1.0.2.jar')
install_jar('liblinear-1.95.jar', 'http://file.hankcs.com/bin/liblinear-1.95.jar')
LinearSVMClassifier = SafeJClass('com.hankcs.hanlp.classification.classifiers.LinearSVMClassifier')
IOUtil = SafeJClass('com.hankcs.hanlp.corpus.io.IOUtil')
sogou_corpus_path = ensure_data('搜狗文本分类语料库迷你版',
'http://file.hankcs.com/corpus/sogou-text-classification-corpus-mini.zip')
def train_or_load_classifier():
model_path = sogou_corpus_path + '.svm.ser'
if os.path.isfile(model_path):
return LinearSVMClassifier(IOUtil.readObjectFrom(model_path))
classifier = LinearSVMClassifier()
classifier.train(sogou_corpus_path)
model = classifier.getModel()
IOUtil.saveObjectTo(model, model_path)
return LinearSVMClassifier(model)
def predict(classifier, text):
print("《%16s》\t属于分类\t【%s】" % (text, classifier.classify(text)))
# 如需获取离散型随机变量的分布,请使用predict接口
# print("《%16s》\t属于分类\t【%s】" % (text, classifier.predict(text)))
if __name__ == '__main__':
classifier = train_or_load_classifier()
predict(classifier, "C罗获2018环球足球奖最佳球员 德尚荣膺最佳教练")
predict(classifier, "潜艇具有很强的战略威慑能力与实战能力")
predict(classifier, "研究生考录模式亟待进一步专业化")
predict(classifier, "如果真想用食物解压,建议可以食用燕麦")
predict(classifier, "通用及其部分竞争对手目前正在考虑解决库存问题")第一次运行会有失败可能,是java类没有加载的缘故,重启环境运行就可以,运行结果如下:
《C罗获2018环球足球奖最佳球员 德尚荣膺最佳教练》 属于分类 【体育】
《潜艇具有很强的战略威慑能力与实战能力》 属于分类 【军事】
《 研究生考录模式亟待进一步专业化》 属于分类 【汽车】
《如果真想用食物解压,建议可以食用燕麦》 属于分类 【健康】
《通用及其部分竞争对手目前正在考虑解决库存问题》 属于分类 【汽车】
11.6 标准化评测
本节介绍文本分类任务的准确率评测指标,并且对两种分类器与两种分词器的搭配进行评估。所有试验采用的数据集皆为搜狗文本分类语料库,特征裁剪算法皆为卡方检验。
11.6.1 评测指标PP、RR、F1F1
类似于2.9节,文本分类釆用分类任务常用的F1F1作为评测指标。对每一个类别cc的分类结果,正确分入该类的样本数量记作TP,错误分入该类的样本数量记作FP,本该分入该类却错误地分入其他类的样本数量记为FN。则精确率PP、召回率RR和F1F1值的定义如下:
P=TPTP+FPR=TPTP+FNF1=2×P×RP+R(11.24)(11.24)P=TPTP+FPR=TPTP+FNF1=2×P×RP+R
如此我们就能得出每个分类独立的准确率指标,用来反映模型对某一类别的分类性能。如果需要衡量模型在所有类目上的整体性能,则可以利用将这些指标在文档级別进行微平均(micro-average):
P¯=∑ci∈CTP∑ci∈CTP+∑ci∈CFPR¯=∑ci∈CTP∑ci∈CTP+∑c∈∈CFNF¯1=2×P¯×R¯P¯+R¯(11.25)(11.25)P¯=∑ci∈CTP∑ci∈CTP+∑ci∈CFPR¯=∑ci∈CTP∑ci∈CTP+∑c∈∈CFNF¯1=2×P¯×R¯P¯+R¯
其中,C={c1,c2,⋯,ck}C={c1,c2,⋯,ck}。也即是将所有类目下的TP、FP和FN求和然后计算这些评测指标。
11.6.2 试验结果
我们在搜狗文本分类语料库上对{朴素贝叶斯法, 支持向量机}×{中文分词, 二元语法}的4种搭配组合做评测,具体代码如下:
from pyhanlp import *
from test_utility import ensure_data
sogou_corpus_path = ensure_data('搜狗文本分类语料库迷你版',
'http://file.hankcs.com/corpus/sogou-text-classification-corpus-mini.zip')
IClassifier = JClass('com.hankcs.hanlp.classification.classifiers.IClassifier')
NaiveBayesClassifier = JClass('com.hankcs.hanlp.classification.classifiers.NaiveBayesClassifier')
LinearSVMClassifier = JClass('com.hankcs.hanlp.classification.classifiers.LinearSVMClassifier')
FileDataSet = JClass('com.hankcs.hanlp.classification.corpus.FileDataSet')
IDataSet = JClass('com.hankcs.hanlp.classification.corpus.IDataSet')
MemoryDataSet = JClass('com.hankcs.hanlp.classification.corpus.MemoryDataSet')
Evaluator = JClass('com.hankcs.hanlp.classification.statistics.evaluations.Evaluator')
FMeasure = JClass('com.hankcs.hanlp.classification.statistics.evaluations.FMeasure')
BigramTokenizer = JClass('com.hankcs.hanlp.classification.tokenizers.BigramTokenizer')
HanLPTokenizer = JClass('com.hankcs.hanlp.classification.tokenizers.HanLPTokenizer')
ITokenizer = JClass('com.hankcs.hanlp.classification.tokenizers.ITokenizer')
def evaluate(classifier, tokenizer):
training_corpus = FileDataSet().setTokenizer(tokenizer).load(sogou_corpus_path, "UTF-8", 0.9)
classifier.train(training_corpus)
testing_corpus = MemoryDataSet(classifier.getModel()).load(sogou_corpus_path, "UTF-8", -0.1)
result = Evaluator.evaluate(classifier, testing_corpus)
print(classifier.getClass().getSimpleName() + "+" + tokenizer.getClass().getSimpleName())
print(result)
if __name__ == '__main__':
evaluate(NaiveBayesClassifier(), HanLPTokenizer())
evaluate(NaiveBayesClassifier(), BigramTokenizer())
evaluate(LinearSVMClassifier(), HanLPTokenizer())
evaluate(LinearSVMClassifier(), BigramTokenizer())评测结果如下表:
表11-6 {朴素贝叶斯法, 支持向量机}×{中文分词, 二元语法}4种搭配组合的性能评测
| 算法+分词 | P | R | F1 | 文档/秒 |
|---|---|---|---|---|
| 朴素贝叶斯+中文分词 | 96.16 | 96 | 96.08 | 6172 |
| 朴素贝叶斯+二元语法 | 96.36 | 96.2 | 96.28 | 3378 |
| SVM + 中文分词 | 97.24 | 97.2 | 97.22 | 27777 |
| SVM + 二元语法 | 97.83 | 97.8 | 97.81 | 12195 |
比较上表,可以得出如下结论:
- 中文文本分类的确不需要分词,不分词直接用二元语法反而能够取得更高的准确率。只不过由于二元语法数量比单词多,导致参与运算的特征更多,相应的分类速度减半。
- 线性支持向量机的分类准确率更高,而且分类速度更快,推荐使用。
11.7 情感分析
文本情感分析指的是提取文本中的主观信息的一种NLP任务,其具体目标通常是找出文本所对应的正负情感态度。情感分析可以在实体、句子、段落乃至文档上进行。本节主要介绍文档级别的情感分析,当然也适用于段落和句子等短文本。任何NLP任务都离不开语料库,尤其是标注语料库。对于情感分析而言,只需要准备标注了正负情感的大量文档,就能将其视作普通的文本分类任务来解决。此外,一些带有评分的电影、商品评论也可以作为“天然”的标注语料库(五星评论可以作为5种类别)。
本节首先介绍一个常用的情感分析语料库,接着训练分类器来分析文本的情感极性。
11.7.1 ChnsentiCorp情感分析语料库
该语料库由谭松波博士整理发布,包含酒店、电脑与书籍三个行业的评论与相应情感极性。此处以酒店评论为例,该部分由正负评论各1000条组成,目录结构如下:
文档内容为数十字的简短评论,比如类似“商务大床房,房间很大,床有2M宽,整体感觉经济实惠不错!”的正面评价,或者类似“标准间太差房间还不如3星的而且设施非常陈旧。建议酒店把老的标准间从新改善。”的负面评价。
11.7.2 训练情感分析模型
由于文件夹结构符合惯例,我们可以直接将语料库路径传入IClassifier#train()接口训练分类模型。实现代码如下(代码与普通的文本分类并无二致,唯一的不同仅仅在于语料库):
from pyhanlp import *
import zipfile
import os
from pyhanlp.static import download, remove_file, HANLP_DATA_PATH
def test_data_path():
"""
获取测试数据路径,位于$root/data/test,根目录由配置文件指定。
:return:
"""
data_path = os.path.join(HANLP_DATA_PATH, 'test')
if not os.path.isdir(data_path):
os.mkdir(data_path)
return data_path
## 验证是否存在语料库,如果没有自动下载
def ensure_data(data_name, data_url):
root_path = test_data_path()
dest_path = os.path.join(root_path, data_name)
if os.path.exists(dest_path):
return dest_path
if data_url.endswith('.zip'):
dest_path += '.zip'
download(data_url, dest_path)
if data_url.endswith('.zip'):
with zipfile.ZipFile(dest_path, "r") as archive:
archive.extractall(root_path)
remove_file(dest_path)
dest_path = dest_path[:-len('.zip')]
return dest_path
# 中文情感挖掘语料-ChnSentiCorp 谭松波
chn_senti_corp = ensure_data("ChnSentiCorp情感分析酒店评论", "http://file.hankcs.com/corpus/ChnSentiCorp.zip")
## ===============================================
## 以下开始 情感分析
IClassifier = JClass('com.hankcs.hanlp.classification.classifiers.IClassifier')
NaiveBayesClassifier = JClass('com.hankcs.hanlp.classification.classifiers.NaiveBayesClassifier')
def predict(classifier, text):
print("《%s》 情感极性是 【%s】" % (text, classifier.classify(text)))
if __name__ == '__main__':
classifier = NaiveBayesClassifier()
# 创建分类器,更高级的功能请参考IClassifier的接口定义
classifier.train(chn_senti_corp)
# 训练后的模型支持持久化,下次就不必训练了
predict(classifier, "前台客房服务态度非常好!早餐很丰富,房价很干净。再接再厉!")
predict(classifier, "结果大失所望,灯光昏暗,空间极其狭小,床垫质量恶劣,房间还伴着一股霉味。")
predict(classifier, "可利用文本分类实现情感分析,效果不是不行")运行结果如下:
《前台客房服务态度非常好!早餐很丰富,房价很干净。再接再厉!》 情感极性是 【正面】
《结果大失所望,灯光昏暗,空间极其狭小,床垫质量恶劣,房间还伴着一股霉味。》 情感极性是 【负面】
《可利用文本分类实现情感分析,效果不是不行》 情感极性是 【负面】
值得注意的是,最后一个测试案例“可利用文本分类实现情感分析,效果不是不行”虽然不属于酒店评论,但结果依然正确,这说明该统计模型有一定的泛化能力,能处理一些其他行业的文本。
11.7.3 拓展试验
词袋模型的缺点就是丟失了词序,导致“人吃鱼”和“鱼吃人”对应到同一个词袋向量。具体到情感分析任务,词袋模型无法处理一些“否定词”或“双重否定”的句子。我们可以在上一节模型的基础上试验下列句子:
不是不行
不 是不行
不优秀
优秀不
词袋模型在处理这些句子时将它们两两混为一谈,因为它们分完词摇一摇得到的词袋一模一样。一种解决方案是利用n元语法来保留一些词序,以期望捕捉至少简短的否定句式。当然,语料库中也必须含有类似的样本才能使模型学习到否定句式的知识。
11.8 总结
本章我们学习了朴素贝叶斯法和线性支持向量机两种机器学习模型,并且将其应用到了文本分类。通过替换语料库,可以将文本分类拓展到了情感分析。这再次体现了统计自然语言处理的魅力,使用NLP工程师设计通用的分类器,搭配上不同行业的语料库就能适用于不同领域。