DCGAN---生成动漫头像
数据集
kaggle:https://www.kaggle.com/datasets/soumikrakshit/anime-faces
代码
import torch
import torch.nn as nn
import torch.nn.functional as F
import matplotlib.pyplot as plt
from torch.utils import data
from torchvision import transforms
import glob
from PIL import Image
# glob获取全部图像的路径
imgs_path = glob.glob(r'anime-faces/*.png')
# 画6张看看
# plt.figure(figsize=(12, 8))
# for i, img_path in enumerate(imgs_path[:6]):
# img = np.array(Image.open(img_path))
# plt.subplot(2, 3, i+1)
# plt.imshow(img)
# print(img.shape)
# plt.show()
# GAN 输入-1,1 便于训练
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(0.5, 0.5), # 数据减均值除方差
])
# 创建数据集
class Face_dataset(data.Dataset):
def __init__(self, imgs_path):
self.imgs_path = imgs_path
def __getitem__(self, index):
img_path = self.imgs_path[index]
pil_img = Image.open(img_path)
pil_img = transform(pil_img)
return pil_img
def __len__(self):
return len(self.imgs_path)
dataset = Face_dataset(imgs_path)
dataloader = data.DataLoader(dataset,
batch_size=32,
shuffle=True)
imgs_batch = next(iter(dataloader)) # 32,3,64,64
# 画出来看看
plt.figure(figsize=(12, 8))
for i, img in enumerate(imgs_batch[:6]):
img = (img.permute(1, 2, 0).numpy() + 1) / 2 # 64,64,3
plt.subplot(2, 3, i+1)
plt.imshow(img)
plt.show()
# 定义生成器,依然输入长度100的噪声
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
self.linear1 = nn.Linear(100, 256*16*16)
self.bn1 = nn.BatchNorm1d(256*16*16)
self.deconv1 = nn.ConvTranspose2d(256, 128, kernel_size=(3, 3), stride=1, padding=1)
self.bn2 = nn.BatchNorm2d(128)
self.deconv2 = nn.ConvTranspose2d(128, 64, kernel_size=(4, 4), stride=2, padding=1)
self.bn3 = nn.BatchNorm2d(64)
self.deconv3 = nn.ConvTranspose2d(64, 3, kernel_size=(4, 4), stride=2, padding=1)
def forward(self, x):
x = F.relu(self.linear1(x))
x = self.bn1(x)
x = x.view(-1, 256, 16, 16)
x = F.relu(self.deconv1(x))
x = self.bn2(x)
x = F.relu(self.deconv2(x))
x = self.bn3(x)
x = torch.tanh(self.deconv3(x))
return x
# 判别器,输入(64, 64)图片
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
self.conv1 = nn.Conv2d(3, 64, kernel_size=3, stride=2) # (64, 31, 31)
self.conv2 = nn.Conv2d(64, 128, 3, 2)
self.bn = nn.BatchNorm2d(128) # 128 * 15 * 15
self.fc = nn.Linear(128*15*15, 1)
def forward(self, x):
x = F.dropout2d(F.leaky_relu(self.conv1(x)), p=0.3)
x = F.dropout2d(F.leaky_relu(self.conv2(x)), p=0.3)
x = self.bn(x)
x = x.view(-1, 128*15*15)
x = torch.sigmoid(self.fc(x))
return x
device = 'cuda' if torch.cuda.is_available() else 'cpu'
if device == 'cuda':
print('using cuda:', torch.cuda.get_device_name(0))
else:
print(device)
Gen = Generator().to(device)
Dis = Discriminator().to(device)
loss_fun = nn.BCELoss()
d_optimizer = torch.optim.Adam(Dis.parameters(), lr=1e-5) # 小技巧
g_optimizer = torch.optim.Adam(Gen.parameters(), lr=1e-4)
def generate_and_save_image(model, test_input):
predictions = model(test_input).permute(0, 2, 3, 1).cpu().numpy()
# fig = plt.figure(figsize=(40, 80)) # 画布设置太大会导致错误
for i in range(predictions.shape[0]):
plt.subplot(2, 4, i+1)
plt.imshow((predictions[i]+1) / 2)
plt.axis('off')
plt.show()
test_seed = torch.randn(8, 100, device=device)
D_loss = []
G_loss = []
for epoch in range(500):
d_epoch_loss = 0
g_epoch_loss = 0
count = len(dataloader) # 批次数
for step, img in enumerate(dataloader):
img = img.to(device)
size = img.size(0)
random_noise = torch.randn(size, 100, device=device)
d_optimizer.zero_grad()
real_output = Dis(img) # 判别器输入真实图片
# 判别器在真实图像上的损失
d_real_loss = loss_fun(real_output,
torch.ones_like(real_output)
)
d_real_loss.backward()
gen_img = Gen(random_noise)
fake_output = Dis(gen_img.detach()) # 判别器输入生成图片,fake_output对生成图片的预测
# gen_img是由生成器得来的,但我们现在只对判别器更新,所以要截断对Gen的更新
# detach()得到了没有梯度的tensor,求导到这里就停止了,backward的时候就不会求导到Gen了
d_fake_loss = loss_fun(fake_output,
torch.zeros_like(fake_output)
)
d_fake_loss.backward()
d_loss = d_real_loss + d_fake_loss
d_optimizer.step()
# 更新生成器
g_optimizer.zero_grad()
fake_output = Dis(gen_img)
g_loss = loss_fun(fake_output,
torch.ones_like(fake_output))
g_loss.backward()
g_optimizer.step()
with torch.no_grad():
d_epoch_loss += d_loss.item()
g_epoch_loss += g_loss.item()
with torch.no_grad(): # 之后的内容不进行梯度的计算(图的构建)
d_epoch_loss /= count
g_epoch_loss /= count
D_loss.append(d_epoch_loss)
G_loss.append(g_epoch_loss)
print('Epoch:', epoch+1)
generate_and_save_image(model=Gen, test_input=test_seed)
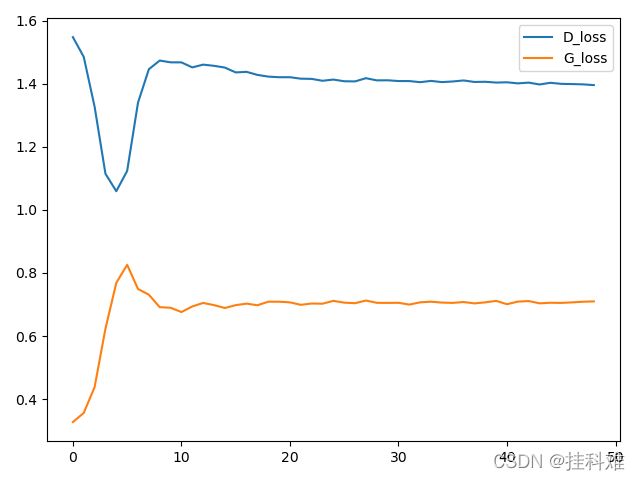
plt.plot(D_loss, label='D_loss')
plt.plot(G_loss, label='G_loss')
plt.legend()
plt.show()
效果
跑了50轮