在飞书搞了个机器人,我让ChatGPT帮忙写算法
一、前言
环境:
系统:Windows 11 64位
Python版本:Python 3.9
注:本文不讲怎么实现,只讲实现的效果和一些思考。大家感兴趣再考虑去配置相关机器人。
先来问问ChatGPT两个问题:
1、ChatGPT是什么?
来看看ChatGPT对自己的定义:

ChatGPT是一种基于自然语言处理(NLP)的聊天机器人技术,它可以帮助用户与聊天机器人进行自然语言交流。ChatGPT使用深度学习技术来模拟人类的自然语言交流,从而实现自然语言处理(NLP)的聊天机器人功能。
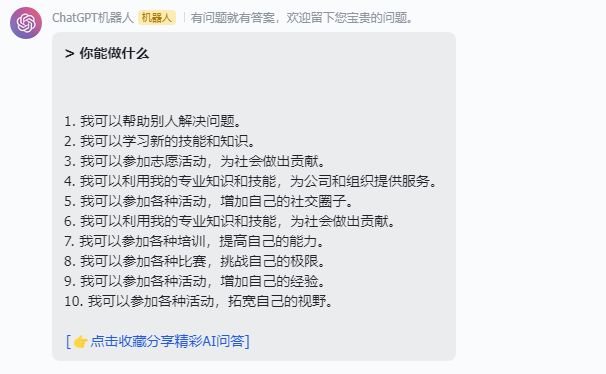
2、ChatGPT能做什么?
来看看ChatGPT对自己的定义:
试用一番之后,我有个强烈的感受——ChatGPT真的太强大了!
它像是一个全能型选手,可以帮助我了解一些未知的领域,帮我解答一些其他领域很小白的问题,只要你有问题,它可以不厌其烦地给你解答。
如果你在学习某个领域的知识,遇到难题了,问它,或许也可以给你答案或者一些启发。
更让我惊喜的是,它还可以帮我写算法,大大提高了我的学习效率,太爱了!接下来介绍三个算法小例子:
注:本篇文章只讲故事,不讲原理和操作
二、让ChatGPT帮我写算法
以下简述下ChatGPT为我写的3个算法。
2.1 二分法

def binary_search(list, item):
low = 0
high = len(list) - 1
while low <= high:
mid = (low + high) // 2
guess = list[mid]
if guess == item:
return mid
if guess > item:
high = mid - 1
else:
low = mid + 1
return None
my_list = [1, 3, 5, 7, 9]
print(binary_search(my_list, 3)) # => 1
print(binary_search(my_list, -1)) # => None
我记得之前一开始写二分法算法的时候,还遇到一个坑,就是不知道这种从[0, n-1]的边界值处理方式,后来采用了[-1, n]完美地解决了问题,今天AI教会了我,原来是要在重新赋值low和high变量的时候,进行加1和减1的处理,get到了!!!
2.2 Apriori算法
Apriori算法是一种用于发现关联规则的数据挖掘算法,它的基本思想是:如果某个项集是频繁项集,那么它的所有子集也是频繁项集。Apriori算法通过迭代的方式来寻找频繁项集,它的基本步骤如下:
- 从原始数据中构建候选项集,并计算每个项集的支持度;
- 根据支持度的阈值筛选出频繁项集;
- 从频繁项集中构建关联规则;
- 根据置信度的阈值筛选出有效的关联规则。
接下来问问ChatGPT怎么用Python实现该算法。

ChatGPT用Python帮我写的Apriori算法代码,还带了一个数据集,直接拿来跑就完事了。
如果想要用自己的数据集,直接替换以下代码的dataset即可,简直不要太容易!
ChatGPT提供的完整代码如下:
# > Python实现Apriori算法
# -*- coding:utf-8 -*-
# 导入相关库
import pandas as pd
import numpy as np
# 加载数据集
dataset = [['牛奶', '面包', '尿布', '啤酒', '鸡蛋'],
['牛奶', '尿布', '啤酒', '可乐'],
['面包', '牛奶', '尿布', '啤酒'],
['面包', '牛奶', '尿布', '可乐']]
# 将数据集转换为DataFrame格式
df = pd.DataFrame(dataset)
# 定义Apriori算法函数
def apriori(data, min_support=0.5):
# 将数据转换为集合格式
C1 = create_C1(data)
# 将数据集转换为二维列表
D = list(map(set, data))
# 构建初始候选项集C1
L1, support_data = scan_D(D, C1, min_support)
# 构建完整的候选项集Ck
L = [L1]
k = 2
while (len(L[k-2]) > 0):
Ck = apriori_gen(L[k-2], k)
Lk, supK = scan_D(D, Ck, min_support)
support_data.update(supK)
L.append(Lk)
k += 1
return L, support_data
# 构建初始候选项集C1
def create_C1(data):
C1 = []
for transaction in data:
for item in transaction:
if not [item] in C1:
C1.append([item])
C1.sort()
return list(map(frozenset, C1))
# 扫描数据集,从C1生成L1
def scan_D(D, Ck, min_support):
ss_cnt = {}
for tid in D:
for can in Ck:
if can.issubset(tid):
if can not in ss_cnt:
ss_cnt[can] = 1
else:
ss_cnt[can] += 1
num_items = float(len(D))
ret_list = []
support_data = {}
for key in ss_cnt:
support = ss_cnt[key] / num_items
if support >= min_support:
ret_list.insert(0, key)
support_data[key] = support
return ret_list, support_data
# 根据频繁项集的集合进行合并
def apriori_gen(Lk, k):
ret_list = []
len_Lk = len(Lk)
for i in range(len_Lk):
for j in range(i+1, len_Lk):
L1 = list(Lk[i])[:k-2]
L2 = list(Lk[j])[:k-2]
L1.sort()
L2.sort()
if L1 == L2:
ret_list.append(Lk[i] | Lk[j])
return ret_list
# 调用Apriori算法
L, support_data = apriori(dataset, min_support=0.5)
# 打印结果
print("频繁项集:", L)
print("所有候选项集的支持度信息:", support_data)
2.3 感知机
这个稍微复杂一些,返回的代码似乎有点问题,我用Python 3.9不能直接跑。
只要是格式化那部分%!s(MISSING)、%!f(MISSING)、%!((MISSING)self.weights, self.bias)、%!d(MISSING)和%!a(MISSING)nd_perception.predict([1, 1]))。
代码如下:
# > Python实现感知机
# 感知机
import numpy as np
# 定义激活函数
def sign(x):
if x >= 0:
return 1
else:
return -1
# 定义感知机
class Perceptron(object):
def __init__(self, input_num, activator):
self.activator = activator
# 权重向量初始化为0
self.weights = [0.0 for _ in range(input_num)]
# 偏置项初始化为0
self.bias = 0.0
def __str__(self):
return 'weights\t:%!s(MISSING)\nbias\t:%!f(MISSING)\n' %!((MISSING)self.weights, self.bias)
# 输入向量,计算感知机的输出
def predict(self, input_vec):
# 把input_vec[x1,x2,x3...]和weights[w1,w2,w3,...]打包在一起
# 变成[(x1,w1),(x2,w2),(x3,w3),...]
# 然后利用map函数计算[x1*w1, x2*w2, x3*w3]
# 最后利用reduce求和
return self.activator(
np.dot(input_vec, self.weights) + self.bias)
# 输入训练数据:一组向量、与每个向量对应的label;以及训练轮数,根据训练数据调整权重
def train(self, input_vecs, labels, iteration, rate):
for i in range(iteration):
self._one_iteration(input_vecs, labels, rate)
# 一次迭代,把所有的训练数据过一遍
def _one_iteration(self, input_vecs, labels, rate):
# 把输入和输出打包在一起,成为样本的列表[(input_vec, label), ...]
# 而每个训练样本是(input_vec, label)
samples = zip(input_vecs, labels)
# 对每个样本,按照感知机规则更新权重
for (input_vec, label) in samples:
# 计算感知机在当前权重下的输出
output = self.predict(input_vec)
# 更新权重
self._update_weights(input_vec, output, label, rate)
# 按照感知机规则更新权重
def _update_weights(self, input_vec, output, label, rate):
# 把input_vec[x1,x2,x3,...]和weights[w1,w2,w3,...]打包在一起
# 变成[(x1,w1),(x2,w2),(x3,w3),...]
# 然后利用感知器规则更新权重
delta = label - output
self.weights = list(map(
lambda x_w: x_w[1] + rate * delta * x_w[0],
zip(input_vec, self.weights)))
# 更新bias
self.bias += rate * delta
def f(x):
return 1 if x > 0 else 0
def get_training_dataset():
# 构建训练数据
# 输入向量列表
input_vecs = [[1,1], [0,0], [1,0], [0,1]]
# 期望的输出列表,注意要与输入一一对应
# [1,1] -> 1, [0,0] -> 0, [1,0] -> 0, [0,1] -> 0
labels = [1, 0, 0, 0]
return input_vecs, labels
def train_and_perceptron():
# 创建感知器,输入参数个数为2(因为and是二元函数),激活函数为f
p = Perceptron(2, f)
# 训练,迭代10轮, 学习速率为0.1
input_vecs, labels = get_training_dataset()
p.train(input_vecs, labels, 10, 0.1)
#返回训练好的感知器
return p
if __name__ == '__main__':
# 训练and感知器
and_perception = train_and_perceptron()
# 打印训练获得的权重
print(and_perception)
# 测试
print('1 and 1 = %!d(MISSING)' %!a(MISSING)nd_perception.predict([1, 1]))
print('0 and 0 = %!d(MISSING)' %!a(MISSING)nd_perception.predict([0, 0]))
print('1 and 0 = %!d(MISSING)' %!a(MISSING)nd_perception.predict([1, 0]))
print('0 and 1 = %!d(MISSING)' %!a(MISSING)nd_perception.predict([0, 1]))
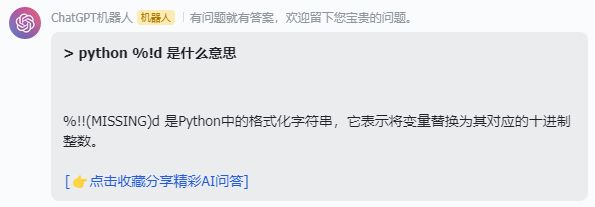
这些有点超出了我的认知,我问ChatGPTpython %!d 是什么意思,它说“%!!(MISSING)d 是Python中的格式化字符串,它表示将变量替换为其对应的十进制整数。 ”
怎么回答多了个!?
接着用它提供的信息,问%!!(MISSING)d 怎么使用,它回复的信息似乎有点问题:
%!n(MISSING)umber应该是%!(MISSING)number"%!d(MISSING)" %!(MISSING)10并不能直接跑,这是无效语法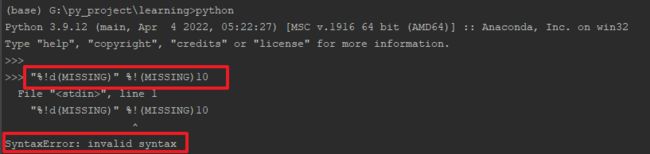

官网查了一下,也没有格式化+missing的相关资料,直接百度也没有找到。先姑且认为是一个bug吧。修改一下格式化部分,便可以正常跑了,改完具体代码如下:
# > Python实现感知机
# 感知机
import numpy as np
# 定义激活函数
def sign(x):
if x >= 0:
return 1
else:
return -1
# 定义感知机
class Perceptron(object):
def __init__(self, input_num, activator):
self.activator = activator
# 权重向量初始化为0
self.weights = [0.0 for _ in range(input_num)]
# 偏置项初始化为0
self.bias = 0.0
def __str__(self):
# return 'weights\t:%!s(MISSING)\nbias\t:%!f(MISSING)\n' %!((MISSING)self.weights, self.bias)
return 'weights\t:%s\nbias\t:%f\n' % (self.weights, self.bias)
# 输入向量,计算感知机的输出
def predict(self, input_vec): #input_vec相当于X
# 把input_vec[x1,x2,x3...]和weights[w1,w2,w3,...]打包在一起
# 变成[(x1,w1),(x2,w2),(x3,w3),...]
# 然后利用map函数计算[x1*w1, x2*w2, x3*w3]
# 最后利用reduce求和
return self.activator(np.dot(input_vec, self.weights) + self.bias)
# 输入训练数据:一组向量、与每个向量对应的label;以及训练轮数,根据训练数据调整权重
def train(self, input_vecs, labels, iteration, rate):
for i in range(iteration):
self._one_iteration(input_vecs, labels, rate)
# 一次迭代,把所有的训练数据过一遍
def _one_iteration(self, input_vecs, labels, rate):
# 把输入和输出打包在一起,成为样本的列表[(input_vec, label), ...]
# 而每个训练样本是(input_vec, label)
samples = zip(input_vecs, labels)
# 对每个样本,按照感知机规则更新权重
for (input_vec, label) in samples:
# 计算感知机在当前权重下的输出
output = self.predict(input_vec)
# 更新权重
self._update_weights(input_vec, output, label, rate)
# 按照感知机规则更新权重
def _update_weights(self, input_vec, output, label, rate):
# 把input_vec[x1,x2,x3,...]和weights[w1,w2,w3,...]打包在一起
# 变成[(x1,w1),(x2,w2),(x3,w3),...]
# 然后利用感知器规则更新权重
delta = label - output #实际值-预测值
self.weights = list(map(
lambda x_w: x_w[1] + rate * delta * x_w[0], #速率*(实际值-预测值)*x值
zip(input_vec, self.weights)))
# 更新bias
self.bias += rate * delta
def f(x):
return 1 if x > 0 else 0
def get_training_dataset():
"""
input_vecs相当于X_train
labels相当于y_train
:return:
"""
# 构建训练数据
# 输入向量列表
input_vecs = [[1,1], [0,0], [1,0], [0,1]]
# 期望的输出列表,注意要与输入一一对应
# [1,1] -> 1, [0,0] -> 0, [1,0] -> 0, [0,1] -> 0
labels = [1, 0, 0, 0]
return input_vecs, labels
def train_and_perceptron():
# 创建感知器,输入参数个数为2(因为and是二元函数),激活函数为f
p = Perceptron(2, f)
# 训练,迭代10轮, 学习速率为0.1
input_vecs, labels = get_training_dataset()
p.train(input_vecs, labels, 10, 0.1)
#返回训练好的感知器
return p
if __name__ == '__main__':
# 训练and感知器
and_perception = train_and_perceptron()
# 打印训练获得的权重
print(and_perception)
# 测试
# print('1 and 1 = %!d(MISSING)' %!(MISSING)and_perception.predict([1, 1]))
# print('0 and 0 = %!d(MISSING)' %!(MISSING)and_perception.predict([0, 0]))
# print('1 and 0 = %!d(MISSING)' %!(MISSING)and_perception.predict([1, 0]))
# print('0 and 1 = %!d(MISSING)' %!(MISSING)and_perception.predict([0, 1]))
print('1 and 1 = %d' % and_perception.predict([1, 1]))
print('0 and 0 = %d' % and_perception.predict([0, 0]))
print('1 and 0 = %d' % and_perception.predict([1, 0]))
print('0 and 1 = %d' % and_perception.predict([0, 1]))
三、小结
不得不说,ChatGPT很给力!不然也不会那么火爆,对于未知的领域,我们经常会有各种各样的“傻”问题,或许也会有一些不好意思问导师或者专家,生怕问题太小白了,被“嫌弃”,而且脑子里无穷的问号,需要占用别人很长的时间才能够一一解答,通过ChatGPT可以解决我们类似的绝大多数比较小白的问题,帮助我们一定程度入门相关知识领域。
上面的描述,或许当过父母的会有更“痛”的领悟,小孩在4岁前后脑袋瓜里就会装这各种各样的奇思妙想,或许ChatGPT会更配,可以满足孩子各种各样的好奇心,当然,这只是一个设想,具体需要验证一下~~