Hadoop 分布式计算系统(map-reduce)介绍
Hadoop 分布式计算系统(map-reduce)介绍
-
- hadoop组成
-
- 什么是分布式计算
- hadoop 1.x 分布式计算总体架构
- hadoop 2.x 分布式计算总体架构
- 分布式计算原理
- JAVA 代码实现
hadoop组成
hadoop 集群主要做了两件事: 分布式存储(hdfs) 和分布式计算(map-reduce)。本文主要对hadoop 分布式计算系统理解做一个记录 帮助以后快速记忆 。
什么是分布式计算
比如 统计非常大的一个文件 里面每个单词出现的次数 。 如果放到一个机器上运行需要解析很久 而且非常浪费很长时间。如果有很多机器帮你计算 最后在做一个汇总 岂不是要快很多。map-reduce 实现的任务也就是这么回事。
hadoop 1.x 分布式计算总体架构
首先强调一下 hdfs 和 map-reduce 是两种东西 。 刚开始学的时候 很容易将这两种东西混淆在一起。
跟存储系统一样的架构 JobTracker 管理了 一堆 TaskTracker
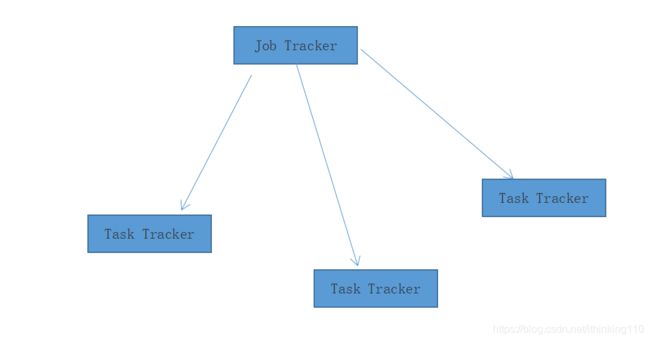
在机房中的摆放是这样的 DataNode 是hdfs 系统 TaskTracker 是分布式计算任务 两者不冲突 所以 可以部署在一起

Switch是交换机(路由器)、Rack代表机房里的一个机柜,每个机柜里都有很多台服务器,称之为节点。
当客户端提交分布式计算任务

JobTracker:
1, 客户端提交任务了 要分配 计算任务到各个机器上
2,记录所有的Task 机器 运行信息 如内存 等
3,管理所有的机器 失败处理 和 重启。
TaskTracker:
1,监视自己所在机器的资源情况 上报给JobTracker
2, 运行map-reduce 任务
注意: 计算要用到的数据一般是就近查看 本机器上有没有(本机也是hdfs 一个节点),如果没有会从远程拉取 。老是容易将 两个系统联想在一起 。
缺点:
1,JobTracker 是 Map-reduce 的集中处理点,存在单点故障;
,2,JobTracker 完成了太多的任务,造成了过多的资源消耗,当 map-reduce job 非常多的时候,会造成很大的内存开销,潜在来说,也增加了 JobTracker 失效的风险,这也是业界普遍总结出老 Hadoop 的 Map-Reduce 只能支持 4000 节点主机的上限;
hadoop 2.x 分布式计算总体架构

因为1.x jobTracker 既要管理各个节点 又要分配各种计算任务 。 而且后面还有很多的框架会涉及到 各种机器的管控比如spark . 所以干脆抽象一个YARN 出来做 各个硬件管控的事情。
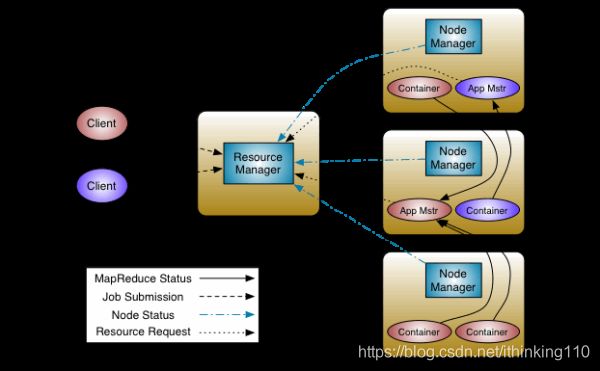
于是抽象出两个东西:ResourceManager 和ApplicationMaster
ResourceManager :
用于管理向应用程序分配计算资源
两个主要的组件:定时调用器(Scheduler)以及应用管理器(ApplicationManager)
①定时调度器(Scheduler):
定时调度器负责向应用程序分配资源,它不做监控以及应用程序的状态跟踪,并且它不保证会重启由于应用程序本身或硬件出错而执行失败的应用程序。
②应用管理器(ApplicationManager):
应用程序管理器负责接收新任务,协调并提供在ApplicationMaster容器失败时的重启功能。
NodeManager:
NodeManager是ResourceManager在每台机器的上代理,负责容器的管理,并监控他们的资源使用情况(cpu,内存,磁盘及网络等),以及向 ResourceManager/Scheduler提供这些资源使用报告。
ApplicationMaster:
每个应用程序的ApplicationMaster负责从Scheduler申请资源,以及跟踪这些资源的使用情况以及任务进度的监控。
分布式计算原理
上文是对总体一个架构,接下来在看看 计算架构。
下面这个图诠释了 所有的原理。

图 1 总体流程
其中 左图方块 代表 map 右图方块代表 reduce . map 和reduce 可能是两台机器 也可能是一台机器上的两个过程
我们拿hadoop 最经典的wordcount 来演示过程
- 对HDFS输入的文件进行切割为KV形式

图 2 map 过程
1,这file–>split过程 就是将一个大文件放在hdfs 上 hdfs 自动会将大文件切割成各个小块
2,split1 ,splt2–> 切割 也就是图1 中的 InputSplite 1 将 各个block 小块送给 map 起始计算。
2.在mapper方法中执行,分割单词为KV形式。

也即是 图1 中的 map 2 输入的是 这样的键值对 < 行号,每一个行的字符串> 输出的是 切割好的键值对<单词,1>
3.shuffle在Map端的三个操作:partition(同一个节点上 分区),merge,combine(单节点上相同K合并)

partition 将单词在本机器上进行分区也就是图1 中的 4
merge 在每个分区中进行整合<单词,数组个数>
combine 在本机上进行一次 reduce 整合 。
最后的结果写入本机硬盘 方便后面reduce的拉取。
4.shuffle在Reduce端的两个个操作:拉取partition,merge,sort

1,每个reduce 拉取每台机器上 对应的分区 有几个reduce 就有几个分区。
在reduce 机器上进行merge 整合成
在sort 进行排序输出给 reduce
-
Reduce操作

-
写出到HDFS:在每一台reducer节点上将文件写入,实际上是写成一个一个的文件块,但对外的表现形式是一整个大的结果文件。

JAVA 代码实现
Mapper类的声明如下:
public class Mapper
这个类的声明上有四个泛型,对于KEYOUT、VALUEOUT表示的经过mapper阶段映射后输出的内容。这个很好理解。我们在上一节已经讲过,Map阶段作用就是将原始的内容映射为key-value集合,然后将结果传递给Reducer。因为我们这里统计的是单词的个数,因此KEYOUT表示的应该就是单词内容(字符串类型),VALUEOUT表示的是单词的出现的次数(整数类型)。
对于KEYIN和KEYOUT是什么呢?因为我们统计的时候文本的内容是一行一行读取的,所以KEYIN就是行号(整数类型),VALUEIN是这一行的内容(字符串类型)。
在确定了四个泛型参数之后,我们就可以开始写代码了,不过需要注意的是,在Hadoop中,定义了自己的数据类型,字符串类型用Text表示,而整数类型用IntWriteable表示。在后文,我们将会对Hadoop的数据类型进行详细讲解。
实现:
TokenizerMapper.java
public static class TokenizerMapper
extends Mapper<IntWritable, Text, Text, IntWritable>{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
@Override
public void map(IntWritable key, Text value, Context context
) throws IOException, InterruptedException {
//StringTokenizer是java工具类,将字符串按照空格进行分割
StringTokenizer itr = new StringTokenizer(value.toString());
//每次出现一个单词,单词次数加1
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
Reducer实现
分析:
Reducer的声明如下所示:
public class Reducer
这个类依然有四个泛型。我们已经知道,Reducer是接受Map阶段的输出,按照相同key进行归一。那么map阶段的输出类型肯定就是reduce阶段的输入类型。
因此,在我们的案例中,KEYIN应该单词(字符串),VALUEIN应该是单词出现的次数(整数)。那么KEYOUT、VALUEOUT是什么?因为我们统计的就是各个单词出现的次数(字符串),所以还应该是单词和出现的次数(整数)。
实现
public static class IntSumReducer
extends Reducer<Text,IntWritable,Text,IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values,
Context context
) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
Job实现
一个mapreduce任务分为map阶段和reduce阶段,现在我们只是单独了实现了这两个这段的代码。
我们还需要将上述代码组合成一个完整的MapReduce任务,用Job对象表示。
public class WordCount {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
final String nameNodeUrl = "hdfs://115.28.65.149:9000";
conf.set(CommonConfigurationKeysPublic.FS_DEFAULT_NAME_KEY, nameNodeUrl);
//1 构建job对象,因为hadoop中可能会同时运行多个任务,每个任务都会有一个名字,以示区分
final String jobName = "word count";
Job job = Job.getInstance(conf, jobName);
job.setJarByClass(WordCount.class);
// 任务内容的输入路径
FileInputFormat.addInputPath(job, new Path("/mapreduce/word.txt"));
// 任务计算结果的而输出路径,如果输出目录已经存在,就删除
final Path outputPath = new Path("/out");
FileSystem fileSystem = outputPath.getFileSystem(conf);
if(fileSystem.exists(outputPath)){
fileSystem.delete(outputPath, true);
}
FileOutputFormat.setOutputPath(job, outputPath);
//2 设置Mapper
job.setMapperClass(TokenizerMapper.class);
//规约,后文会详细介绍
// job.setCombinerClass(IntSumReducer.class);
//3 设置Reducer
//设置分区
job.setReducerClass(IntSumReducer.class);
//设置reducer任务数,默认为1
job.setNumReduceTasks(1);
//设置分区类
job.setPartitionerClass(HashPartitioner.class);
//设置输出的key与Value
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// 提交任务并等待执行完成
job.waitForCompletion(true);
}
}
}