分布式体系架构与分布式计算相关问题
分布式体系架构相关问题
分布式体系结构集中式架构中,Master 如何判断 Slave 是否存活呢?
Slave 故障的两类情况:
- Slave 进程退出;
- Slave 所在服务器宕机或重启了。
如下图所示,假设 Master 节点与 3 个 Slave 节点相连。Master 与 Slave 之间画了两条线,实线旁写的是 TCP 长连接,虚线旁写的是心跳。因为 Master 与 Slave 之间的监控关系是固定的,因此用两种机制协同来判断 Slave 是否存活。
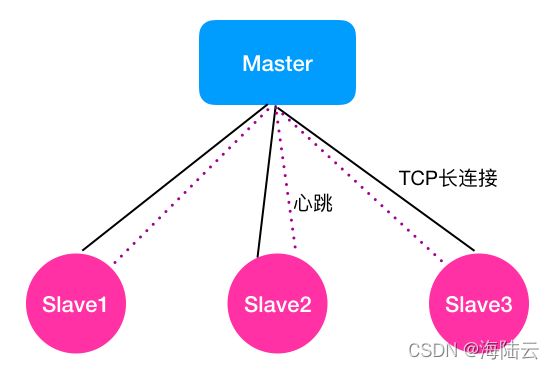
Slave 进程的退出:TCP 长连接就是针对 Slave 进程退出,但是 Slave 所在服务器未故障的情况。这种方式是借助 TCP 长连接的工作原理进行判断的。TCP 长连接中,TCP 会对对端的 Socket 进行检测,当发现对端 Socket 不可用时,比如不能发出探测包或探测包未收到响应,会返回 -1 的状态,表示连接断开。
Slave 所在服务器宕机或重启:由于服务器宕机或重启,那么系统环境等均不工作 了,这种情况 TCP 长连接也无法进行探测了,TCP 长连接方法在这种场景下无法判断节点是否故障。
对于这种场景,现有的软件架构中,基本都采用了心跳方式。其核心策略是,Master 按照周期性(比如每隔 1s)的方式给 Slave 发送心跳包,正常情况下 Slave 收到 Master 发送的心跳包后,会立即回复一个心跳包,告知 Master 自己还活着。当某个 Slave(比如 Slave1)所在服务器故障后,由于 Slave 无法接收到 Master 的心跳包,也就无法回复了。因此,Master 也无法接收到这个 Slave(比如 Slave1)的回复信息。
系统会设置一个阈值(一般设置为与心跳周期一致),若超过这个阈值还未收到 Slave 节点的回复,Master 就会标记自己与该 Slave 心跳超时。 设置阈值的目的是,解决 Slave 故障情况下,Master 一直收不到心跳信息而阻塞在那里等待心跳回复的问题。一般连续 k 次 Master 与 Slave 的心跳超时,Master 就会判断该 Slave 故障了。设置连续 k 次的目的是,降低因为系统做垃圾回收或网络延迟导致误判的概率。 这里的 k,主要是根据业务场景进行设置的。如果 k 设置得太小,容易导致故障误判率过高,因为系统在做垃圾回收或系统进程正在占用资源时,会阻塞心跳,导致心跳包无法及时回复而超时,从而被误判。如果 k 设置得太大,会导致故障发现的时间过长,因为故障发现时间 =k* 心跳发送周期。
追问 1:非集中式架构中,如何判断节点是否存活?
集中式架构中,采用了 TCP 连接和心跳协同判断节点是否存活,在非集中式架构与集中式架构中,判断节点是否存活的原理有所不同。因为非集中式架构中节点之间是对等的,没有 Master 与 Slave 之分。如果每个节点间都建立 TCP 长 连接,假设集群中有 n 个节点,那么每个节点均需要与其他 n-1 个节点建长连接,这将导致每个节点的资源占用都会非常多。因此非集中式架构是采用心跳的方式进行判断的。
如果像集中式架构那样,每个节点与其他 n-1 个节点都发送心跳的话, 整个集群中同一时间心跳消息为 n*(n-1),消息量也特别大,甚至会导致网络风暴。其实非集中式架构与集中式架构中的心跳包不同,非集中式架构中采用的心跳方式的核心思想是,每个节点被 b(1≤b
- 不设置 b 的值,b 默认取值的原则是:若集群中节点总数 n 小于 6, b=n-1;若 n 大于等于 6,b=5。
- 设置 b 的值,则 b 以用户设置的值为准。
Akka 集群中通过心跳方式判断节点是否存活:
- Akka 中集群组建完成后,每个节点拥有整个集群中的节点列表。
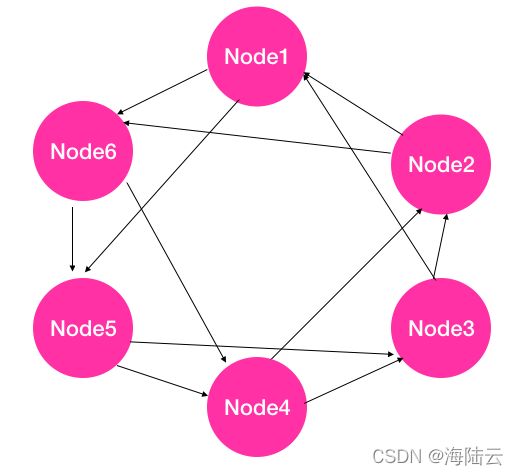
- 每个节点根据集群节点列表,计算哈希值(比如根据节点 ID 计算一个哈希值),然后基于哈希值,将所有节点组成一个哈希环(比如,从小到大的顺序),如下图所示。由于每个节点上的计算方法一致,因此虽然每个节点独立计算,但每个节点上维护的哈希环是一致的。
- 根据哈希环,针对每个节点逆时针或顺时针方向选择 b(图中设置 b=2)个临近节点作为监控节点,比如图中 Node 2 和 Node3 监控 Node1,Node 3 和 Node4 监控 Node2,以此类推。由于每个节点被 b 个节点监控,反过来也可以说,在这个环上每个节点监控 b 个节点,因此具体的实现方式是每个节点按照逆时针或顺时针方向选择 b 个 节点进行监控。
- 当某个节点发现自己监控的节点心跳超时时(比如 Node 2 发现 Node1 心跳超时), 则标记该节点不可达(Node2 标记 Node1 不可达),并将该信息通过 Gossip 协议传播给集群中的其他节点。
- 如果某个节点被标记为不可达之后(比如 Node1 不可达),若不将该节点踢出集群, 那么 Node2 和 Node3 仍然会给 Node1 发送心跳,若后面 Node2 又发现 Node1 心跳可达时,则重新将 Node1 更新为可达状态,然后同步给集群中其他节点。
这里的判断心跳超时机制,可采用集中式方法中的连续 k 次心跳超时的方法进行判断,也可以通过历史心跳信息进行预测。
追加 2: 一个集群为什么会存在双主的场景呢?
判断节点存活的方法主要是通过心跳的方式。如果是因为网络连接断开,那么节点之间就会被误判为对方故障了。在主备场景下,通常会出现双主的情况。
在主备场景下,正常情况下,主节点提供服务,备节点是对主节点的数据、状态进行备份,以确保主故障后备升主后业务可以正常运行。主备节点之间通常会通过心跳的方式进行检测,目的是监控主节点是否故障,若故障则备升主,保证业务运行。
如果主备节点之间的网络连接断开了,那么主节点与备节点之间心跳均不可达, 因此主节点会认为备节点故障,此时主节点会继续提供服务,而备节点会认为主节点故障, 备升主。集群中就出现了双主的场景。
分布计算技术相关问题
在分布式计算技术中,离线计算、批量计算、实时计算、流式计算这四个概念常常会弄混。离线计算和批量计算,实时计算和流式计算到底是什么呢?离线计算和批量计算、实时计算和流式计算分别是等价的吗?
离线计算:主要的应用场景是对时延要求不敏感、计算量大、需要计算很长时间(比如需要数天、数周甚至数月)的场景,比如大数据分析、复杂的 AI 模型训练(比如神经网络)等。这种场景如果采用在线计算或实时计算的话,通常会存在数据量不够或大量计算影响正在运 行的业务等问题,因此往往会采用离线计算的方式。
离线计算方式的核心思想是,先采集数据,并将这些数据存储起来,待数据达到一定量或规模时再进行计算,然后将计算结果(比如离线训练的模型)应用到实际业务场景中。
批量计算:批量计算通常是指,将原始数据集划分为多个数据子集,然后每个任务负责处理一个数据子集,多个任务并发执行,以加快整个数据的处理。比如,分布式计算模式 MR 计算模式,MapReduce 中的 Map 其实就属于批量计算,Map 计算的结果会通过 Reduce 进行汇总。
实时计算:实时计算其实是和离线计算相对应的,离线计算对时延要求不敏感,相反,实时计算对时延的要求比较敏感。这种模式需要短时间执行完成并输出结果,比如秒级、分钟级,强调时效,通常用于秒杀、抢购等场景。实时计算由于时延要求低,因此计算量通常不大、数据量也不会太多,所计算的数据往往是 K、M 级别的。
流式计算:分布式计算模式 Stream 流计算强调的是实时性,数据一旦产生就会被立即处理,当一条数据被处理完成后,会立刻通过网络传输到下一个节点,由下一个节点继续处理。这种模式通常用于商业场景中每天的报表统计、持续多天的促销活动效果分析等。
- 离线计算和批量计算对任务执行的时延不敏感;
- 实时计算和流式计算对任务执行的时延敏感;
- 离线计算和实时计算是从计算时延的维度进行分类的;
- 批量计算和流式计算是从计算方式的维度进行分类的;
因此不能将离线计算和批量计算直接等同,也不能将实时计算和流式计算直接等同。