Lesson 4.6 逻辑回归的手动实现
Lesson 4.6 逻辑回归的手动实现
讨论完梯度下降的相关内容之后,接下来我们尝试使用梯度下降算法求解逻辑回归损失函数,并且通过一系列实验来观察逻辑回归的模型性能。
# 科学计算模块
import numpy as np
import pandas as pd
# 绘图模块
import matplotlib as mpl
import matplotlib.pyplot as plt
# 自定义模块
from ML_basic_function import *
一、逻辑回归损失函数的梯度计算表达式
对于任何模型的手动实现,首先我们都需要考虑关于其损失函数的梯度计算表达式。并且为了方便代码实现,我们需要尽可能的使用矩阵形式进行表示。在线性回归中,我们通过矩阵求导运算,可以非常快速的求解出用矩阵形式表示的损失函数梯度表达式,而在逻辑回归中,由于损失函数表达式的不同,这个过程会略微复杂一些。
在Lesson 4.2中,我们从极大似然估计和KL离散两个角度推导了逻辑回归损失函数,对于二分类为逻辑回归模型来说,假设数据集是m行n列的一个数据集,则二分类交叉熵损失函数如下: b i n a r y C E ( w ^ ) = − 1 m ∑ i = 1 m [ y ( i ) ⋅ l o g ( p 1 ( x ^ ( i ) ; w ^ ) ) + ( 1 − y ( i ) ) ⋅ l o g ( 1 − p 1 ( x ^ ( i ) ; w ^ ) ) ] binaryCE(\hat w)= -\frac{1}{m}\sum^m_{i=1}[y^{(i)} \cdot log(p_1(\hat x^{(i)};\hat w))+(1-y^{(i)}) \cdot log(1-p_1(\hat x^{(i)};\hat w))] binaryCE(w^)=−m1i=1∑m[y(i)⋅log(p1(x^(i);w^))+(1−y(i))⋅log(1−p1(x^(i);w^))]
其中n为样本数量, x ^ ( i ) \hat x^{(i)} x^(i)为第i条样本(添加了最后全是1的列), w ^ \hat w w^为带截距项的线性方程系数向量, p 1 p_1 p1为某条样本在当前参数下逻辑回归输出结果,即预测该样本为1的概率, y ( i ) y^{(i)} y(i)为第 i i i条样本的真实类别。对于上述BCE损失函数,梯度表达式为:
∇ w ^ B C E ( w ^ ) = ∂ B C E ( w ^ ) ∂ w ^ \nabla_{\hat{w}} B C E(\hat{w})=\frac{\partial B C E(\hat{w})}{\partial \hat{w}} ∇w^BCE(w^)=∂w^∂BCE(w^)
其中 w ^ = [ w 1 , w 2 , w 3 , . . . , w n , b ] \hat w=[w_1, w_2, w_3, ..., w_n, b] w^=[w1,w2,w3,...,wn,b],因此上式可进一步展开:
∇ w ^ B C E ( w ^ ) = ∂ B C E ( w ^ ) ∂ w ^ = [ ∂ B C E ( w ^ ) ∂ w 1 , ∂ B C E ( w ^ ) ∂ w 2 , … , ∂ B C E ( w ^ ) ∂ w n , ∂ B C E ( w ^ ) ∂ b ] T \nabla_{\hat{w}} B C E(\hat{w})=\frac{\partial B C E(\hat{w})}{\partial \hat{w}}=\left[\frac{\partial B C E(\hat{w})}{\partial w_{1}}, \frac{\partial B C E(\hat{w})}{\partial w_{2}}, \ldots, \frac{\partial B C E(\hat{w})}{\partial w_{n}}, \frac{\partial B C E(\hat{w})}{\partial b}\right]^{T} ∇w^BCE(w^)=∂w^∂BCE(w^)=[∂w1∂BCE(w^),∂w2∂BCE(w^),…,∂wn∂BCE(w^),∂b∂BCE(w^)]T
而 l o g ( p 1 ( x ^ ( i ) ; w ^ ) ) = l o g ( S i g m o i d ( x ^ ( i ) ⋅ w ^ ) ) log(p_1(\hat x^{(i)}; \hat w)) = log(Sigmoid(\hat x^{(i)} \cdot \hat w)) log(p1(x^(i);w^))=log(Sigmoid(x^(i)⋅w^)),我们对带入某条数据后的某个参数进行求导,例如对 w i w_i wi进行求导,则可得: l o g ( p 1 ( x ^ ( i ) ; w ^ ) ) ′ = l o g ( S i g m o i d ( x ^ ( i ) ⋅ w ^ ) ) ′ = 1 S i g m o i d ( x ^ ( i ) ⋅ w ^ ) ⋅ S i g m o i d ′ ( x ^ ( i ) ⋅ w ^ ) log(p_1(\hat x^{(i)}; \hat w))' = log(Sigmoid(\hat x^{(i)} \cdot \hat w))'=\frac{1}{Sigmoid(\hat x^{(i)} \cdot \hat w)} \cdot Sigmoid'(\hat x^{(i)} \cdot \hat w) log(p1(x^(i);w^))′=log(Sigmoid(x^(i)⋅w^))′=Sigmoid(x^(i)⋅w^)1⋅Sigmoid′(x^(i)⋅w^)
对于Sigmoid函数来说,有 S i g m o i d ′ ( x ) = S i g m o i d ( x ) ( 1 − S i g m o i d ( x ) ) Sigmoid'(x) = Sigmoid(x)(1-Sigmoid(x)) Sigmoid′(x)=Sigmoid(x)(1−Sigmoid(x)),因此上式可进一步得到: l o g ( p 1 ( x ^ ( i ) ; w ^ ) ) ′ = ( 1 − S i g m o i d ( x ^ ( i ) ⋅ w ^ ) ) ⋅ ( x ^ ( i ) ⋅ w ^ ) ′ log(p_1(\hat x^{(i)}; \hat w))' = (1-Sigmoid(\hat x^{(i)} \cdot \hat w)) \cdot (\hat x^{(i)} \cdot \hat w)' log(p1(x^(i);w^))′=(1−Sigmoid(x^(i)⋅w^))⋅(x^(i)⋅w^)′
其中 x ^ ( i ) ⋅ w ^ = w 1 x 1 ( i ) + w 2 x 2 ( i ) + . . . + w n x n ( i ) + b \hat x^{(i)} \cdot \hat w=w_1x_1^{(i)}+w_2x_2^{(i)}+...+w_nx_n^{(i)}+b x^(i)⋅w^=w1x1(i)+w2x2(i)+...+wnxn(i)+b,对 w i w_i wi求导可得: ( x ^ ( i ) ⋅ w ^ ) ′ = x i ( i ) (\hat x^{(i)} \cdot \hat w)' = x_i^{(i)} (x^(i)⋅w^)′=xi(i)
当然,对截距求导可得: ( x ^ ( i ) ⋅ w ^ ) ′ = 1 (\hat x^{(i)} \cdot \hat w)' = 1 (x^(i)⋅w^)′=1因此,在 l o g ( p 1 ( x ^ ( i ) ; w ^ ) ) log(p_1(\hat x^{(i)}; \hat w)) log(p1(x^(i);w^))中对 w i w_i wi求导可得: l o g ( p 1 ( x ^ ( i ) ; w ^ ) ) ′ = ( 1 − S i g m o i d ( x ^ ( i ) ⋅ w ^ ) ) ⋅ x i ( i ) log(p_1(\hat x^{(i)}; \hat w))' = (1-Sigmoid(\hat x^{(i)} \cdot \hat w)) \cdot x_i^{(i)} log(p1(x^(i);w^))′=(1−Sigmoid(x^(i)⋅w^))⋅xi(i)而在 l o g ( p 1 ( x ^ i ; w ^ ) ) log(p_1(\hat x_i; \hat w)) log(p1(x^i;w^))中对 b b b求导可得: l o g ( p 1 ( x ^ ( i ) ; w ^ ) ) ′ = ( 1 − S i g m o i d ( x ^ ( i ) ⋅ w ^ ) ) ⋅ 1 log(p_1(\hat x^{(i)}; \hat w))' = (1-Sigmoid(\hat x^{(i)} \cdot \hat w)) \cdot 1 log(p1(x^(i);w^))′=(1−Sigmoid(x^(i)⋅w^))⋅1类似的,在 ( 1 − y ( i ) ) ⋅ l o g ( 1 − p 1 ( x ^ ( i ) ; w ^ ) ) (1-y^{(i)}) \cdot log(1-p_1(\hat x^{(i)};\hat w)) (1−y(i))⋅log(1−p1(x^(i);w^))中对 w i w_i wi求导可得: ( 1 − y ( i ) ) ⋅ l o g ′ ( 1 − p 1 ( x ^ ( i ) ; w ^ ) ) = ( 1 − y ( i ) ) ⋅ l o g ′ ( 1 − S i g m o i d ( x ^ ( i ) ⋅ w ^ ) ) = ( 1 − y ( i ) ) ⋅ 1 ( 1 − S i g m o i d ( x ^ ( i ) ⋅ w ^ ) ) ⋅ ( − S i g m o i d ′ ( x ^ ( i ) ⋅ w ^ ) ) \begin{aligned} (1-y^{(i)}) \cdot log'(1-p_1(\hat x^{(i)};\hat w)) & = (1-y^{(i)}) \cdot log'(1-Sigmoid(\hat x^{(i)} \cdot \hat w)) \\ &=(1-y^{(i)}) \cdot \frac{1}{(1-Sigmoid(\hat x^{(i)} \cdot \hat w))} \cdot (-Sigmoid'(\hat x^{(i)} \cdot \hat w)) \end{aligned} (1−y(i))⋅log′(1−p1(x^(i);w^))=(1−y(i))⋅log′(1−Sigmoid(x^(i)⋅w^))=(1−y(i))⋅(1−Sigmoid(x^(i)⋅w^))1⋅(−Sigmoid′(x^(i)⋅w^))同样,由于 S i g m o i d ′ ( x ) = S i g m o i d ( x ) ( 1 − S i g m o i d ( x ) ) Sigmoid'(x) = Sigmoid(x)(1-Sigmoid(x)) Sigmoid′(x)=Sigmoid(x)(1−Sigmoid(x)),所以上式可得: ( 1 − y ( i ) ) ⋅ l o g ′ ( 1 − p 1 ( x ^ ( i ) ; w ^ ) ) = ( 1 − y ( i ) ) ⋅ ( − S i g m o i d ( x ^ ( i ) ⋅ w ^ ) ) ⋅ ( x ^ ( i ) ⋅ w ^ ) ′ = ( 1 − y ( i ) ) ⋅ ( − S i g m o i d ( x ^ ( i ) ⋅ w ^ ) ) ⋅ x i ( i ) \begin{aligned} (1-y^{(i)}) \cdot log'(1-p_1(\hat x^{(i)};\hat w)) & = (1-y^{(i)}) \cdot (-Sigmoid(\hat x^{(i)} \cdot \hat w)) \cdot (\hat x^{(i)} \cdot \hat w)' \\ &=(1-y^{(i)}) \cdot (-Sigmoid(\hat x^{(i)} \cdot \hat w)) \cdot x_i^{(i)} \end{aligned} (1−y(i))⋅log′(1−p1(x^(i);w^))=(1−y(i))⋅(−Sigmoid(x^(i)⋅w^))⋅(x^(i)⋅w^)′=(1−y(i))⋅(−Sigmoid(x^(i)⋅w^))⋅xi(i)类似的,当对截距项b求导时 ( 1 − y ( i ) ) ⋅ l o g ′ ( 1 − p 1 ( x ^ ( i ) ; w ^ ) ) = ( 1 − y ( i ) ) ⋅ ( − S i g m o i d ( x ^ ( i ) ⋅ w ^ ) ) ⋅ 1 (1-y^{(i)}) \cdot log'(1-p_1(\hat x^{(i)};\hat w))= (1-y^{(i)}) \cdot (-Sigmoid(\hat x^{(i)} \cdot \hat w)) \cdot 1 (1−y(i))⋅log′(1−p1(x^(i);w^))=(1−y(i))⋅(−Sigmoid(x^(i)⋅w^))⋅1将上述结果带入 ∂ B C E ( w ^ ) ∂ w i \frac{\partial BCE(\hat w)}{\partial w_i} ∂wi∂BCE(w^),当对 w i w_i wi进行求导时: ∂ B C E ( w ^ ) ∂ w i = ( − 1 m ∑ i = 1 m [ y ( i ) ⋅ l o g ( p 1 ( x ^ ( i ) ; w ^ ) ) + ( 1 − y ( i ) ) ⋅ l o g ( 1 − p 1 ( x ^ ( i ) ; w ^ ) ) ] ) ′ = − 1 m ∑ i = 1 m [ y ( i ) ⋅ l o g ′ ( p 1 ( x ^ ( i ) ; w ^ ) ) + ( 1 − y ( i ) ) ⋅ l o g ′ ( 1 − p 1 ( x ^ ( i ) ; w ^ ) ) ] = − 1 m ∑ i = 1 m [ y ( i ) ⋅ ( 1 − S i g m o i d ( x ^ ( i ) ⋅ w ^ ) ) ⋅ x i ( i ) + ( 1 − y ( i ) ) ⋅ ( − S i g m o i d ( x ^ ( i ) ⋅ w ^ ) ) ⋅ x i ( i ) ) ] = − 1 m ∑ i = 1 m [ x i ( i ) y ( i ) − x i ( i ) y ( i ) S i g m o i d ( x ^ ( i ) ⋅ w ^ ) − x i ( i ) S i g m o i d ( x ^ ( i ) ⋅ w ^ ) + x i ( i ) y ( i ) S i g m o i d ( x ^ ( i ) ⋅ w ^ ) ] = 1 m ∑ i = 1 m ( x i ( i ) ( S i g m o i d ( x ^ ( i ) ⋅ w ^ ) − y ( i ) ) ) = 1 m ∑ i = 1 m ( x i ( i ) ( y ^ ( i ) − y ( i ) ) ) \begin{aligned} \frac{\partial BCE(\hat w)}{\partial w_i} &= (-\frac{1}{m}\sum^m_{i=1}[y^{(i)} \cdot log(p_1(\hat x^{(i)};\hat w))+(1-y^{(i)}) \cdot log(1-p_1(\hat x^{(i)};\hat w))])' \\ &=-\frac{1}{m}\sum^m_{i=1}[y^{(i)} \cdot log'(p_1(\hat x^{(i)};\hat w))+(1-y^{(i)}) \cdot log'(1-p_1(\hat x^{(i)};\hat w))] \\ &=-\frac{1}{m}\sum^m_{i=1}[y^{(i)} \cdot (1-Sigmoid(\hat x^{(i)} \cdot \hat w)) \cdot x_i^{(i)} + (1-y^{(i)}) \cdot (-Sigmoid(\hat x^{(i)} \cdot \hat w)) \cdot x_i^{(i)})] \\ &=-\frac{1}{m}\sum^m_{i=1}[ x_i^{(i)}y^{(i)}-x_i^{(i)}y^{(i)}Sigmoid(\hat x^{(i)} \cdot \hat w) - x_i^{(i)}Sigmoid(\hat x^{(i)} \cdot \hat w)+x_i^{(i)}y^{(i)}Sigmoid(\hat x^{(i)} \cdot \hat w) ] \\ &=\frac{1}{m}\sum^m_{i=1}(x_i^{(i)}(Sigmoid(\hat x^{(i)} \cdot \hat w)-y^{(i)})) \\ &=\frac{1}{m}\sum^m_{i=1}(x_i^{(i)}(\hat y^{(i)}-y^{(i)})) \end{aligned} ∂wi∂BCE(w^)=(−m1i=1∑m[y(i)⋅log(p1(x^(i);w^))+(1−y(i))⋅log(1−p1(x^(i);w^))])′=−m1i=1∑m[y(i)⋅log′(p1(x^(i);w^))+(1−y(i))⋅log′(1−p1(x^(i);w^))]=−m1i=1∑m[y(i)⋅(1−Sigmoid(x^(i)⋅w^))⋅xi(i)+(1−y(i))⋅(−Sigmoid(x^(i)⋅w^))⋅xi(i))]=−m1i=1∑m[xi(i)y(i)−xi(i)y(i)Sigmoid(x^(i)⋅w^)−xi(i)Sigmoid(x^(i)⋅w^)+xi(i)y(i)Sigmoid(x^(i)⋅w^)]=m1i=1∑m(xi(i)(Sigmoid(x^(i)⋅w^)−y(i)))=m1i=1∑m(xi(i)(y^(i)−y(i)))对截距项b进行求导时: ∂ B C E ( w ^ ) ∂ b = 1 m ∑ i = 1 m 1 ⋅ ( y ^ ( i ) − y ( i ) ) \frac{\partial BCE(\hat w)}{\partial b} = \frac{1}{m}\sum^m_{i=1}1 \cdot (\hat y^{(i)}-y^{(i)}) ∂b∂BCE(w^)=m1i=1∑m1⋅(y^(i)−y(i))> 其实,根据定义, x ( i ) = [ x 1 ( i ) , x 2 ( i ) , . . . , x n ( i ) , 1 ] x^{(i)}=[x_1^{(i)}, x_2^{(i)}, ..., x_n^{(i)}, 1] x(i)=[x1(i),x2(i),...,xn(i),1], x n + 1 ( i ) = 1 x^{(i)}_{n+1}=1 xn+1(i)=1,1就是 x ( i ) x^{(i)} x(i)的第 n + 1 n+1 n+1个分量
∇ w ^ B C E ( w ^ ) = ∂ B C E ( w ^ ) ∂ w ^ = [ ∂ B C E ( w ^ ) ∂ w 1 ∂ B C E ( w ^ ) ∂ w 2 ⋅ ⋅ ⋅ ∂ B C E ( w ^ ) ∂ w n ∂ B C E ( w ^ ) ∂ b ] = [ 1 m ∑ i = 1 m ( x 1 ( i ) ( Sigmoid ( x ^ ( i ) ⋅ w ^ ) − y ( i ) ) ) 1 m ∑ i = 1 m ( x 2 ( i ) ( Sigmoid ( x ^ ( i ) ⋅ w ^ ) − y ( i ) ) ) ⋅ ⋅ ⋅ 1 m ∑ i = 1 m ( x n ( i ) ( Sigmoid ( x ^ ( i ) ⋅ w ^ ) − y ( i ) ) ) 1 m ∑ i = 1 m ( 1 ⋅ ( Sigmoid ( x ^ ( i ) ⋅ w ^ ) − y ( i ) ) ) ] = 1 m [ ∑ i = 1 m x 1 ( i ) Sigmoid ( x ^ ( i ) ⋅ w ^ ) − ∑ i = 1 m x 1 ( i ) y ( i ) ∑ i = 1 m x 2 ( i ) Sigmoid ( x ^ ( i ) ⋅ w ^ ) − ∑ i = 1 m x 2 ( i ) y ( i ) ⋅ ⋅ ⋅ ∑ i = 1 m x n ( i ) Sigmoid ( x ^ ( i ) ⋅ w ^ ) − ∑ i = 1 m x n ( i ) y ( i ) ∑ i = 1 m Sigmoid ( x ^ ( i ) ⋅ w ^ ) − ∑ i = 1 m y ( i ) ] \begin{array}{l} \nabla_{\hat{w}} B C E(\hat{w})=\frac{\partial B C E(\hat{w})}{\partial \hat{w}}\\ =\left[\begin{array}{c} \frac{\partial B C E(\hat{w})}{\partial w_{1}} \\ \frac{\partial B C E(\hat{w})}{\partial w_{2}} \\ \cdot \\ \cdot \\ \cdot \\ \frac{\partial B C E(\hat{w})}{\partial w n} \\ \frac{\partial B C E(\hat{w})}{\partial b} \end{array}\right]\\ =\left[\begin{array}{c} \frac{1}{m} \sum_{i=1}^{m}\left(x_{1}^{(i)}\left(\operatorname{Sigmoid}\left(\hat{x}^{(i)} \cdot \hat{w}\right)-y^{(i)}\right)\right) \\ \frac{1}{m} \sum_{i=1}^{m}\left(x_{2}^{(i)}\left(\operatorname{Sigmoid}\left(\hat{x}^{(i)} \cdot \hat{w}\right)-y^{(i)}\right)\right) \\ \cdot \\ \cdot \\ \cdot \\ \frac{1}{m} \sum_{i=1}^{m}\left(x_{n}^{(i)}\left(\operatorname{Sigmoid}\left(\hat{x}^{(i)} \cdot \hat{w}\right)-y^{(i)}\right)\right) \\ \frac{1}{m} \sum_{i=1}^{m}\left(1 \cdot\left(\operatorname{Sigmoid}\left(\hat{x}^{(i)} \cdot \hat{w}\right)-y^{(i)}\right)\right) \end{array}\right]\\ =\frac{1}{m}\left[\begin{array}{c} \sum_{i=1}^{m} x_{1}^{(i)} \operatorname{Sigmoid}\left(\hat{x}^{(i)} \cdot \hat{w}\right)-\sum_{i=1}^{m} x_{1}^{(i)} y^{(i)} \\ \sum_{i=1}^{m} x_{2}^{(i)} \operatorname{Sigmoid}\left(\hat{x}^{(i)} \cdot \hat{w}\right)-\sum_{i=1}^{m} x_{2}^{(i)} y^{(i)} \\ \cdot \\ \cdot \\ \cdot \\ \sum_{i=1}^{m} x_{n}^{(i)} \operatorname{Sigmoid}\left(\hat{x}^{(i)} \cdot \hat{w}\right)-\sum_{i=1}^{m} x_{n}^{(i)} y^{(i)} \\ \sum_{i=1}^{m} \operatorname{Sigmoid}\left(\hat{x}^{(i)} \cdot \hat{w}\right)-\sum_{i=1}^{m} y^{(i)} \end{array}\right] \end{array} ∇w^BCE(w^)=∂w^∂BCE(w^)=⎣⎢⎢⎢⎢⎢⎢⎢⎢⎢⎡∂w1∂BCE(w^)∂w2∂BCE(w^)⋅⋅⋅∂wn∂BCE(w^)∂b∂BCE(w^)⎦⎥⎥⎥⎥⎥⎥⎥⎥⎥⎤=⎣⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎡m1∑i=1m(x1(i)(Sigmoid(x^(i)⋅w^)−y(i)))m1∑i=1m(x2(i)(Sigmoid(x^(i)⋅w^)−y(i)))⋅⋅⋅m1∑i=1m(xn(i)(Sigmoid(x^(i)⋅w^)−y(i)))m1∑i=1m(1⋅(Sigmoid(x^(i)⋅w^)−y(i)))⎦⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎤=m1⎣⎢⎢⎢⎢⎢⎢⎢⎢⎢⎡∑i=1mx1(i)Sigmoid(x^(i)⋅w^)−∑i=1mx1(i)y(i)∑i=1mx2(i)Sigmoid(x^(i)⋅w^)−∑i=1mx2(i)y(i)⋅⋅⋅∑i=1mxn(i)Sigmoid(x^(i)⋅w^)−∑i=1mxn(i)y(i)∑i=1mSigmoid(x^(i)⋅w^)−∑i=1my(i)⎦⎥⎥⎥⎥⎥⎥⎥⎥⎥⎤我们令 X X X为添加最后一列全是1的特征矩阵, y y y是标签数组: X ^ = [ x ( 1 ) , x ( 2 ) , . . . , x ( m ) ] T = [ x 1 ( 1 ) , x 2 ( 1 ) , . . . , x n ( 1 ) , 1 x 1 ( 2 ) , x 2 ( 2 ) , . . . , x n ( 2 ) , 1 . . . x 1 ( m ) , x 2 ( m ) , . . . , x n ( m ) , 1 ] \begin{aligned} \hat X &= [x^{(1)}, x^{(2)}, ..., x^{(m)}]^T\\ & =\left [\begin{array}{cccc} x^{(1)}_1, x^{(1)}_2, ... ,x^{(1)}_n, 1 \\ x^{(2)}_1, x^{(2)}_2, ... ,x^{(2)}_n, 1 \\ . \\ . \\ . \\ x^{(m)}_1, x^{(m)}_2, ... ,x^{(m)}_n, 1 \\ \end{array}\right] \\ \end{aligned} X^=[x(1),x(2),...,x(m)]T=⎣⎢⎢⎢⎢⎢⎢⎢⎡x1(1),x2(1),...,xn(1),1x1(2),x2(2),...,xn(2),1...x1(m),x2(m),...,xn(m),1⎦⎥⎥⎥⎥⎥⎥⎥⎤ y = [ y ( 1 ) , y ( 2 ) , . . . , y ( m ) ] T y = [y^{(1)}, y^{(2)}, ..., y^{(m)}]^T y=[y(1),y(2),...,y(m)]T则上式前半部分可简化为: [ ∑ i = 1 m x 1 ( i ) S i g m o i d ( x ^ ( i ) ⋅ w ^ ) ∑ i = 1 m x 2 ( i ) S i g m o i d ( x ^ ( i ) ⋅ w ^ ) . . . ∑ i = 1 m x n ( i ) S i g m o i d ( x ^ ( i ) ⋅ w ^ ) ∑ i = 1 m S i g m o i d ( x ^ ( i ) ⋅ w ^ ) ] = [ x 1 ( 1 ) , x 1 ( 2 ) , . . . , x 1 ( m ) x 2 ( 1 ) , x 2 ( 2 ) , . . . , x 2 ( m ) . . . x m ( 1 ) , x m ( 2 ) , . . . , x m ( m ) 1 , 1 , . . . , 1 , 1 ] ⋅ [ S i g m o i d ( x ^ ( 1 ) ⋅ w ^ ) S i g m o i d ( x ^ ( 2 ) ⋅ w ^ ) . . . S i g m o i d ( x ^ ( m ) ⋅ w ^ ) ] = [ x 1 ( 1 ) , x 2 ( 1 ) , . . . , x n ( 1 ) , 1 x 1 ( 2 ) , x 2 ( 2 ) , . . . , x n ( 2 ) , 1 . . . x 1 ( m ) , x 2 ( m ) , . . . , x n ( m ) , 1 ] T ⋅ S i g m o i d ( [ x 1 ( 1 ) , x 2 ( 1 ) , . . . , x n ( 1 ) , 1 x 1 ( 2 ) , x 2 ( 2 ) , . . . , x n ( 2 ) , 1 . . . x 1 ( m ) , x 2 ( m ) , . . . , x n ( m ) , 1 ] ⋅ [ w 1 w 2 . . . w n b ] ) = X ^ T S i g m o i d ( X ^ ⋅ w ^ ) \begin{aligned} \left [\begin{array}{cccc} \sum^m_{i=1}x_1^{(i)}Sigmoid(\hat x^{(i)} \cdot \hat w) \\ \sum^m_{i=1}x_2^{(i)}Sigmoid(\hat x^{(i)} \cdot \hat w) \\ . \\ . \\ . \\ \sum^m_{i=1}x_n^{(i)}Sigmoid(\hat x^{(i)} \cdot \hat w) \\ \sum^m_{i=1}Sigmoid(\hat x^{(i)} \cdot \hat w) \\ \end{array}\right] &=\left [\begin{array}{cccc} x^{(1)}_1, x^{(2)}_1, ... ,x^{(m)}_1 \\ x^{(1)}_2, x^{(2)}_2, ... ,x^{(m)}_2 \\ . \\ . \\ . \\ x^{(1)}_m, x^{(2)}_m, ... ,x^{(m)}_m \\ 1, 1, ... ,1, 1 \\ \end{array}\right] \cdot \left [\begin{array}{cccc} Sigmoid(\hat x^{(1)} \cdot \hat w) \\ Sigmoid(\hat x^{(2)} \cdot \hat w) \\ . \\ . \\ . \\ Sigmoid(\hat x^{(m)} \cdot \hat w) \\ \end{array}\right] \\ &=\left [\begin{array}{cccc} x^{(1)}_1, x^{(1)}_2, ... ,x^{(1)}_n, 1 \\ x^{(2)}_1, x^{(2)}_2, ... ,x^{(2)}_n, 1 \\ . \\ . \\ . \\ x^{(m)}_1, x^{(m)}_2, ... ,x^{(m)}_n, 1 \\ \end{array}\right]^T \cdot Sigmoid( \left [\begin{array}{cccc} x^{(1)}_1, x^{(1)}_2, ... ,x^{(1)}_n, 1 \\ x^{(2)}_1, x^{(2)}_2, ... ,x^{(2)}_n, 1 \\ . \\ . \\ . \\ x^{(m)}_1, x^{(m)}_2, ... ,x^{(m)}_n, 1 \\ \end{array}\right] \cdot \left [\begin{array}{cccc} w_1 \\ w_2 \\ . \\ . \\ . \\ w_n \\ b \\ \end{array}\right]) \\ &= \hat X^T Sigmoid(\hat X \cdot \hat w) \end{aligned} ⎣⎢⎢⎢⎢⎢⎢⎢⎢⎢⎡∑i=1mx1(i)Sigmoid(x^(i)⋅w^)∑i=1mx2(i)Sigmoid(x^(i)⋅w^)...∑i=1mxn(i)Sigmoid(x^(i)⋅w^)∑i=1mSigmoid(x^(i)⋅w^)⎦⎥⎥⎥⎥⎥⎥⎥⎥⎥⎤=⎣⎢⎢⎢⎢⎢⎢⎢⎢⎢⎡x1(1),x1(2),...,x1(m)x2(1),x2(2),...,x2(m)...xm(1),xm(2),...,xm(m)1,1,...,1,1⎦⎥⎥⎥⎥⎥⎥⎥⎥⎥⎤⋅⎣⎢⎢⎢⎢⎢⎢⎡Sigmoid(x^(1)⋅w^)Sigmoid(x^(2)⋅w^)...Sigmoid(x^(m)⋅w^)⎦⎥⎥⎥⎥⎥⎥⎤=⎣⎢⎢⎢⎢⎢⎢⎢⎡x1(1),x2(1),...,xn(1),1x1(2),x2(2),...,xn(2),1...x1(m),x2(m),...,xn(m),1⎦⎥⎥⎥⎥⎥⎥⎥⎤T⋅Sigmoid(⎣⎢⎢⎢⎢⎢⎢⎢⎡x1(1),x2(1),...,xn(1),1x1(2),x2(2),...,xn(2),1...x1(m),x2(m),...,xn(m),1⎦⎥⎥⎥⎥⎥⎥⎥⎤⋅⎣⎢⎢⎢⎢⎢⎢⎢⎢⎡w1w2...wnb⎦⎥⎥⎥⎥⎥⎥⎥⎥⎤)=X^TSigmoid(X^⋅w^)同时,后半部分可简化为: [ ∑ i = 1 m x 1 ( i ) y ( i ) ∑ i = 1 m x 2 ( i ) y ( i ) . . . ∑ i = 1 m x n ( i ) y ( i ) ∑ i = 1 m y ( i ) ] = [ x 1 ( 1 ) , x 2 ( 1 ) , . . . , x n ( 1 ) , 1 x 1 ( 2 ) , x 2 ( 2 ) , . . . , x n ( 2 ) , 1 . . . x 1 ( m ) , x 2 ( m ) , . . . , x n ( m ) , 1 ] T ⋅ [ y ( 1 ) y ( 2 ) . . . y ( m ) ] = X ^ T ⋅ y \begin{aligned} \left [\begin{array}{cccc} \sum^m_{i=1}x_1^{(i)}y^{(i)} \\ \sum^m_{i=1}x_2^{(i)}y^{(i)} \\ . \\ . \\ . \\ \sum^m_{i=1}x_n^{(i)}y^{(i)} \\ \sum^m_{i=1}y^{(i)} \\ \end{array}\right] = \left [\begin{array}{cccc} x^{(1)}_1, x^{(1)}_2, ... ,x^{(1)}_n, 1 \\ x^{(2)}_1, x^{(2)}_2, ... ,x^{(2)}_n, 1 \\ . \\ . \\ . \\ x^{(m)}_1, x^{(m)}_2, ... ,x^{(m)}_n, 1 \\ \end{array}\right]^T \cdot \left [\begin{array}{cccc} y^{(1)} \\ y^{(2)} \\ . \\ . \\ . \\ y^{(m)} \\ \end{array}\right]=\hat X^T \cdot y \end{aligned} ⎣⎢⎢⎢⎢⎢⎢⎢⎢⎢⎡∑i=1mx1(i)y(i)∑i=1mx2(i)y(i)...∑i=1mxn(i)y(i)∑i=1my(i)⎦⎥⎥⎥⎥⎥⎥⎥⎥⎥⎤=⎣⎢⎢⎢⎢⎢⎢⎢⎡x1(1),x2(1),...,xn(1),1x1(2),x2(2),...,xn(2),1...x1(m),x2(m),...,xn(m),1⎦⎥⎥⎥⎥⎥⎥⎥⎤T⋅⎣⎢⎢⎢⎢⎢⎢⎡y(1)y(2)...y(m)⎦⎥⎥⎥⎥⎥⎥⎤=X^T⋅y因此,逻辑回归损失函数的梯度计算公式为:
∇ w ^ B C E ( w ^ ) = 1 m X ^ T ( Sigmoid ( X ^ ⋅ w ^ ) − y ) \nabla_{\hat{w}} B C E(\hat{w})=\frac{1}{m} \hat{X}^{T}(\operatorname{Sigmoid}(\hat{X} \cdot \hat{w})-y) ∇w^BCE(w^)=m1X^T(Sigmoid(X^⋅w^)−y)
并且,据此我们可以定义逻辑回归的梯度计算公式:
def logit_gd(X, w, y):
"""
逻辑回归梯度计算公式
"""
m = X.shape[0]
grad = X.T.dot(sigmoid(X.dot(w)) - y) / m
return grad
其实,无论是理论推导还是手动实现,对于机器学习的建模流程来说,只要我们采用梯度下降方法进行参数求解,就需要有以下环节:根据算法原理构建损失函数——根据损失函数构建梯度更新表达式——根据梯度表达式进行参数更新,而在这个过程中,损失函数的构建和梯度表达式的计算其实都是涉及理论部分内容相对较深而实践过程高度重复的,即一旦我们推导出逻辑回归模型的梯度计算公式,在未来长期建模过程中该式都无须更改甚至无须关注,而这部分功能代码,往往都是封装在更高级框架里面的函数或者类。这也是导致我们在调库实现机器学习建模时往往会忽视损失函数和梯度更新表达式的函数形式,而只看重最终建模结果。
当然,这么做其实无可厚非,对于初中级用户来说,首先最重要的是完成建模整个流程,然后在此基础之上不断精进建模技巧。但无论何时,我们都需要知道工具和框架都只是实现的一种途径,其背后的原理才是能够解决问题的关键。
二、创建分类数据集生成器
1.手动创建分类数据
为了方便展开逻辑回归和后续分类模型的性能探讨,我们考虑通过创建可自定义分类难度的分类数据生成器来辅助后续实验的开展。在此前的回归数据生成器定义的过程中,我们曾介绍,对于回归数据集来说,越是服从高阶多项式回归规律、或者干扰项越大,建模难度就越高,而对于分类问题来说,有一种非常简单的方式去划分数据集的分类难度,那就是:在样本空间(特征空间)中观察不同类别的样本分布,各类别样本点重合度越高、边界约不明显,则分类难度越高。例如我们通过创建各列都服从高斯分布的分类数据集如下:
# 创建初始标记值
num_inputs = 2 # 数据集特征
num_examples = 500 # 每一类样本数
np.random.seed(24)
data0 = np.random.normal(4, 2, size=(num_examples, num_inputs))
data1 = np.random.normal(-2, 2, size=(num_examples, num_inputs))
data0[:10]
#array([[6.65842435, 2.4599331 ],
# [3.36743928, 2.01837923],
# [1.85836749, 1.12257344],
# [5.1288337 , 4.59144378],
# [0.74719153, 4.4391304 ],
# [5.3576096 , 7.77854546],
# [5.9230768 , 4.20802239],
# [3.03766937, 5.70045706],
# [6.90684933, 6.11547487],
# [4.33112321, 5.03003676]])
值得注意的是,对于random.normal函数来说,参数size决定接下来数组的基本形状,而在创建任意维度数组时,在均值参数和标准差参数都是标量的情况下,实际上均值和方差约束的是所有数据
data0.mean()
#4.027189146259833
data0.std()
#2.026404030444323
当然,对于其中的每一列数据来说,其实都是从整体数据中抽样而来,因此各列也都服从均值为4、标准差为2的正态分布
data0.mean(0)
#array([3.90407794, 4.15030035])
data0.std(0)
#array([2.05961619, 1.98501764])
另外,如果希望对二维数组中的每一列进行均值和标准差进行单独设置,则可以将均值参数和标准差参数也设置为array_like的参数
a = np.random.normal([0, 1], [1, 2], size=(num_examples, num_inputs))
a[:10]
#array([[ 0.96604603, 4.53246719],
# [ 0.57852053, -1.68056849],
# [-0.54625943, 2.08126231],
# [ 1.17934488, -3.87849635],
# [-0.56712052, 1.31693223],
# [ 0.23258861, 4.09162486],
# [ 1.0491485 , -0.24942084],
# [-0.03904771, 0.77754885],
# [-1.15375907, -2.14538106],
# [ 0.40636534, 3.74512035]])
a.mean(0)
#array([-0.04871211, 0.9915323 ])
a.std(0)
#array([0.97824254, 1.90314288])
同时,我们令data0的标签为label0,data1标签为label1
label0 = np.zeros(500)
label1 = np.ones(500)
一般来说,用于表示分类数据集类别的数字可以自行定义,对于二分类问题,一般会用0/1来表示两个类别,更进一步的,我们往往会令有待重点识别的类为1,其他类别为0。
最终我们将两类数据和两类数据对应的标签分别合并为features和labels,即数据集的整体特征矩阵和标签数组
features = np.concatenate((data0, data1), 0)
labels = np.concatenate((label0, label1), 0)
由于数据集只包含两个特征,因此我们可以通过绘制样本空间的样本点的分布来进行观察,其中每个点代表每一条样本,而每个点的不同着色则代表不同类别。
plt.scatter(features[:, 0], features[:, 1], c = labels)
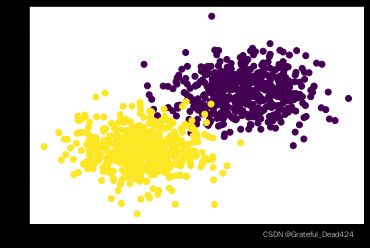
而对于上述两个类别来说,很明显,第一类(data0,列均值为4)位于样本空间的右上角,而第二类(data0,列均值为-2)则位于样本空间的左下角。并且,我们可以从另一个角度来理解两类数据的分布,首先,均值实际上也就代表着样本分布的中心,因此第一类数据的中心点为(4,4),而第二类的数据的中心点为(-2,-2),此外,方差(及标准差)其实表示数据的离散程度,方差越大、数据距离中心点的离散程度就越大
a1 = np.random.normal(0, 1, size=(100, 2))
a2 = np.random.normal(0, 5, size=(100, 2))
plt.scatter(a1[:, 0], a1[:, 1])
plt.scatter(a2[:, 0], a2[:, 1])
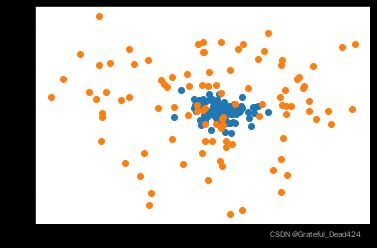
因此,对于上述创建数据集过程而言,如果我们缩短中心点之间的距离、增加每一个点簇的方差,则能够进一步加深两个点簇彼此交错的情况
np.random.seed(24)
data0 = np.random.normal(2, 4, size=(num_examples, num_inputs))
data1 = np.random.normal(-2, 4, size=(num_examples, num_inputs))
features = np.concatenate((data0, data1), 0)
labels = np.concatenate((label0, label1), 0)
plt.scatter(features[:, 0], features[:, 1], c = labels)

能够看出,此时两个点簇(两类数据)在样本空间中的边界非常模糊。
反之,如果提高中心点间距、减少每个点簇方差,则会减少各点簇彼此交错的情况,并且能够呈现出一条更加清晰的边界。
np.random.seed(24)
data0 = np.random.normal(5, 2, size=(num_examples, num_inputs))
data1 = np.random.normal(-5, 2, size=(num_examples, num_inputs))
features = np.concatenate((data0, data1), 0)
labels = np.concatenate((label0, label1), 0)
plt.scatter(features[:, 0], features[:, 1], c = labels)

对于上述分布的分类数据集来说,我们甚至能够清楚的在样本空间中找出一条线性边界对两类数据进行切分。而对于分类数据来说,边界越清晰,彼此交错的情况越少、则分类越简单。
2.创建分类数据生成器
在有了上述基础只是铺垫之后,接下来我们考虑创建分类数据生成器函数,并且拥有以下两点额外功能:能够创建多分类数据集,并且可以通过参数手动调整数据分类难度。
def arrayGenCla(num_examples = 500, num_inputs = 2, num_class = 3, deg_dispersion = [4, 2], bias = False):
"""分类数据集创建函数。
:param num_examples: 每个类别的数据数量
:param num_inputs: 数据集特征数量
:param num_class:数据集标签类别总数
:param deg_dispersion:数据分布离散程度参数,需要输入一个列表,其中第一个参数表示每个类别数组均值的参考、第二个参数表示随机数组标准差。
:param bias:建立模型逻辑回归模型时是否带入截距,为True时将添加一列取值全为1的列
:return: 生成的特征张量和标签张量,其中特征张量是浮点型二维数组,标签张量是长正型二维数组。
"""
cluster_l = np.empty([num_examples, 1]) # 每一类标签数组的形状
mean_ = deg_dispersion[0] # 每一类特征数组的均值的参考值
std_ = deg_dispersion[1] # 每一类特征数组的方差
lf = [] # 用于存储每一类特征的列表容器
ll = [] # 用于存储每一类标签的列表容器
k = mean_ * (num_class-1) / 2 # 每一类特征均值的惩罚因子
for i in range(num_class):
data_temp = np.random.normal(i*mean_-k, std_, size=(num_examples, num_inputs)) # 生成每一类特征
lf.append(data_temp) # 将每一类特征添加到lf中
labels_temp = np.full_like(cluster_l, i) # 生成某一类的标签
ll.append(labels_temp) # 将每一类标签添加到ll中
features = np.concatenate(lf)
labels = np.concatenate(ll)
if bias == True:
features = np.concatenate((features, np.ones(labels.shape)), 1) # 在特征张量中添加一列全是1的列
return features, labels
其中,需要注意的是关于离散程度参数的理解和使用。参数deg_dispersion是一个包含两个元素的list,其中第二个元素为每一类数据的方差,而第一个元素则是每一类数据的均值的一个参考值(mean_),而最终每一类数据的均值则由mean_、总类别数num_class和当前类别标签三者共同决定。这里如此进行设计的一个重要原因是,我们希望无论最终创建几个类别的数据,最终各类中心点的均值基本是围绕原点分布的。即假设总共创建两个类别的数据,并且假设mean_取值为2,i为每一类的编号(0,1),则相比采用i*mean_创建中心点分别为(0, 0)、(2, 2)的两个簇,我们更希望创建中心点为(-1, -1)、(1, 1)为中心点的两个簇。
为了满足该要求,我们需要在原始i*mean_的基础上进行修改。这里我们创建了一个惩罚因子k=mean_ * (num_class-1) / 2,用于修正i*mean_。在进行每个簇中心点计算时,计算公式为i*mean_-k,当总类别为2、mean_=2时,每个中心点计算公式为i*2_-1,i为0时,第一类中心点计算结果为(-1,-1),当i为1时,第二类中心点计算结果为(1, 1),能够满足上述中心点围绕原点分布的基本要求。
接下来,测试上述函数性能
# 设置随机数种子
np.random.seed(24)
# 创建数据
f, l = arrayGenCla(num_class = 2, deg_dispersion = [6, 2], bias = True) # 离散程度较小
# 绘图展示
plt.scatter(f[:, 0], f[:, 1], c = l)

# 设置随机数种子
np.random.seed(24)
# 创建数据
f1, l1 = arrayGenCla(num_class = 2, deg_dispersion = [6, 4], bias = True) # 离散程度较大
# 绘制图像查看
plt.scatter(f1[:, 0], f1[:, 1], c = l1)
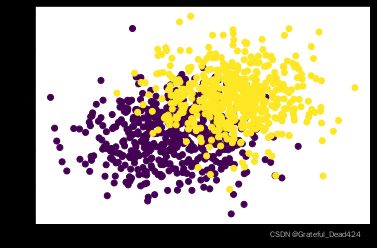
f[:10]
#array([[-0.34157565, -4.5400669 , 1. ],
# [-3.63256072, -4.98162077, 1. ],
# [-5.14163251, -5.87742656, 1. ],
# [-1.8711663 , -2.40855622, 1. ],
# [-6.25280847, -2.5608696 , 1. ],
# [-1.6423904 , 0.77854546, 1. ],
# [-1.0769232 , -2.79197761, 1. ],
# [-3.96233063, -1.29954294, 1. ],
# [-0.09315067, -0.88452513, 1. ],
# [-2.66887679, -1.96996324, 1. ]])
至此,分类数据生成器创建完毕。
需要说明的是,由于目前各列仍然是服从高斯分布,因此上述数据生成器在每一个特征的基本分布上保有较好的数据特性。
三、逻辑回归的手动实现
接下来,尝试进行逻辑回归的手动实现。其基本建模流程依然遵照机器学习的一般流程,可以通过如下方式来执行。
- 数据准备
此处直接利用上述数据f和l进行模型模型训练,在无其他特殊要求情况下,我们对数据集进行训练集和测试集的切分,并进行数据归一化处理
# 设置随机数种子
np.random.seed(24)
# 数据切分
Xtrain, Xtest, ytrain, ytest = array_split(f, l)
Xtrain
#array([[-1.8548796 , -2.70483481, 1. ],
# [-1.87637683, -2.41926232, 1. ],
# [ 1.94989069, 4.23222036, 1. ],
# ...,
# [ 2.87532044, 0.3972172 , 1. ],
# [ 3.40818137, 3.98428395, 1. ],
# [-0.25339125, -8.61214233, 1. ]])
Xtest[:10]
#array([[ 3.89897105, 4.36406577, 1. ],
# [-1.34183767, -5.4001881 , 1. ],
# [ 2.51468003, 2.5656945 , 1. ],
# [ 6.44964778, 2.68891653, 1. ],
# [ 2.09992517, 1.45376719, 1. ],
# [ 3.29152071, -1.84196332, 1. ],
# [-0.30325369, -4.82751704, 1. ],
# [ 3.6890838 , 3.12407552, 1. ],
# [ 2.18449546, 2.28340341, 1. ],
# [ 2.26674673, 1.52043045, 1. ]])
数据归一化过程
mean_ = Xtrain[:, :-1].mean(axis=0)
std_ = Xtrain[:, :-1].std(axis=0)
Xtrain[:, :-1] = (Xtrain[:, :-1] - mean_) / std_
Xtest[:, :-1] = (Xtest[:, :-1] - mean_) / std_
Xtrain
#array([[-0.54046519, -0.81824522, 1. ],
# [-0.54654998, -0.73750376, 1. ],
# [ 0.53647537, 1.14310619, 1. ],
# ...,
# [ 0.79841834, 0.05881485, 1. ],
# [ 0.94924468, 1.07300578, 1. ],
# [-0.08716377, -2.48845047, 1. ]])
Xtest[:10]
#array([[ 1.08816274, 1.18038356, 1. ],
# [-0.39524863, -1.58031715, 1. ],
# [ 0.69633905, 0.67192025, 1. ],
# [ 1.81013201, 0.70675949, 1. ],
# [ 0.57894265, 0.35753899, 1. ],
# [ 0.91622387, -0.57428086, 1. ],
# [-0.10127734, -1.41840274, 1. ],
# [ 1.02875413, 0.82979436, 1. ],
# [ 0.60288027, 0.59210656, 1. ],
# [ 0.6261615 , 0.37638705, 1. ]])
- 初始化参数与核心参数设置
接下来定义参数初始值及核心参数
# 设置随机数种子
np.random.seed(24)
# 参数初始值
n = f.shape[1]
w = np.random.randn(n, 1)
# 核心参数
batch_size = 50
num_epoch = 200
lr_init = 0.2
w
#array([[ 1.32921217],
# [-0.77003345],
# [-0.31628036]])
并且,由于要执行学习率调度,因此需要定义匿名函数
lr_lambda = lambda epoch: 0.95 ** epoch
- 模型训练
然后,带入训练数据进行模型训练
for i in range(num_epoch):
w = sgd_cal(Xtrain, w, ytrain, logit_gd, batch_size=batch_size, epoch=1, lr=lr_init*lr_lambda(i))
w
#array([[3.1894049 ],
# [2.30553244],
# [0.1691708 ]])
- 模型结果测试
模型训练完成后,测试模型效果。首先,对于逻辑回归来说,在给出线性方程参数后,模型输出的概率结果为:
yhat = sigmoid(Xtrain.dot(w))
yhat[:10]
#array([[0.03103592],
# [0.03646214],
# [0.9891821 ],
# [0.08059581],
# [0.0043602 ],
# [0.05225521],
# [0.96094581],
# [0.00100699],
# [0.60388201],
# [0.99752817]])
然后我们利用logit_cla函数将其转化为分类结果
logit_cla(yhat, thr=0.5)[:10]
#array([[0.],
# [0.],
# [1.],
# [0.],
# [0.],
# [0.],
# [1.],
# [0.],
# [1.],
# [1.]])
至此我们即得出了模型在训练数据集上的预测结果。当然,我们还可以利用其与训练集的真是标签进行比较,来计算模型在训练集上的预测准确率
(logit_cla(yhat, thr=0.5) == ytrain).mean()
#0.9871428571428571
注意,此处我们借助了隐式转化,将布尔型对象转化为浮点型对象。当然,我们也可以将上述准确率计算过程封装为一个函数
def logit_acc(X, w, y, thr=0.5):
yhat = sigmoid(X.dot(w))
y_cal = logit_cla(yhat, thr=thr)
return (y_cal == y).mean()
# 训练集准确率
logit_acc(Xtrain, w, ytrain, thr=0.5)
#0.9871428571428571
# 测试集准确率
logit_acc(Xtest, w, ytest, thr=0.5)
#0.98
至此,我们即完成了整个逻辑回归手动建模过程。
- 模型准确率变化函数
更进一步的,我们可以借助Lesson 4.5节中观察损失函数伴随迭代不断变化的过程中的代码思路,来观察伴随迭代过程模型准确率逐渐提升的过程
# 设置随机数种子
np.random.seed(24)
# 参数初始值
n = f.shape[1]
w = np.random.randn(n, 1)
# 记录迭代过程模型准确率计算结果
train_acc = []
test_acc = []
w
#array([[ 1.32921217],
# [-0.77003345],
# [-0.31628036]])
for i in range(num_epoch):
w = sgd_cal(Xtrain, w, ytrain, logit_gd, batch_size=batch_size, epoch=1, lr=lr_init*lr_lambda(i))
train_acc.append(logit_acc(Xtrain, w, ytrain, thr=0.5))
test_acc.append(logit_acc(Xtest, w, ytest, thr=0.5))
# 观察计算结果
plt.plot(list(range(num_epoch)), np.array(train_acc).flatten(), label='train_acc')
plt.plot(list(range(num_epoch)), np.array(test_acc).flatten(), label='test_acc')
plt.xlabel('epochs')
plt.ylabel('Accuracy')
plt.legend(loc = 4)
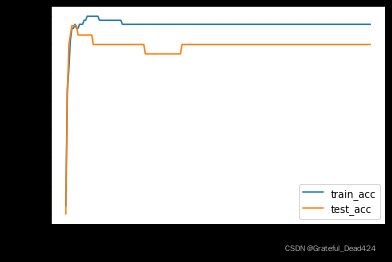
能够发现,由于数据集本身性质较好,即数据集中各类别边界较为明显,因此整体迭代收敛速度较快,并且模型最终准确率较高。
四、逻辑回归的分类性能瓶颈与算法评价
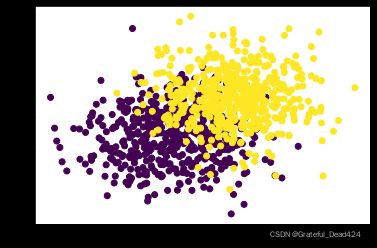
尽管上述建模结果较好,但是像上述数据集一般、不同类别数据边界如此明显的数据集却并不常见。一种更加常见的情况是不同类别的数据集彼此之间存在一定的交叉、数据集之间的边界并不明显。因此,我们尝试带入更加复杂的数据集,即带入f1、l1带入进行建模,来测试逻辑回归模型性能。
# 数据分布
plt.scatter(f1[:, 0], f1[:, 1], c = l1)
# 设置随机数种子
np.random.seed(24)
# 数据切分与归一化
Xtrain, Xtest, ytrain, ytest = array_split(f1, l1)
mean_ = Xtrain[:, :-1].mean(axis=0)
std_ = Xtrain[:, :-1].std(axis=0)
Xtrain[:, :-1] = (Xtrain[:, :-1] - mean_) / std_
Xtest[:, :-1] = (Xtest[:, :-1] - mean_) / std_
Xtrain
#array([[-0.13869677, -0.53505829, 1. ],
# [-0.14755539, -0.41940515, 1. ],
# [ 0.19293434, 1.05939775, 1. ],
# ...,
# [ 0.574287 , -0.49372856, 1. ],
# [ 0.79386924, 0.95898674, 1. ],
# [ 0.52124727, -2.92744086, 1. ]])
# 设置随机数种子
np.random.seed(24)
# 核心参数
batch_size = 50
num_epoch = 200
lr_init = 0.2
# 参数初始值
n = f1.shape[1]
w = np.random.randn(n, 1)
# 记录迭代过程模型准确率计算结果
train_acc = []
test_acc = []
w
#array([[ 1.32921217],
# [-0.77003345],
# [-0.31628036]])
for i in range(num_epoch):
w = sgd_cal(Xtrain, w, ytrain, logit_gd, batch_size=batch_size, epoch=1, lr=lr_init*lr_lambda(i))
train_acc.append(logit_acc(Xtrain, w, ytrain, thr=0.5))
test_acc.append(logit_acc(Xtest, w, ytest, thr=0.5))
# 观察计算结果
plt.plot(list(range(num_epoch)), np.array(train_acc).flatten(), label='train_acc')
plt.plot(list(range(num_epoch)), np.array(test_acc).flatten(), label='test_acc')
plt.xlabel('epochs')
plt.ylabel('Accuracy')
plt.legend(loc = 4)
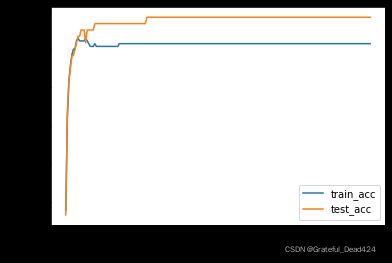
能够看出,模型准确率大幅下降。当然,随着数据集中不同簇彼此交错情况越多、边界越模糊,最终模型准确率还将进一步下降。当然,我们在下一小节中,还将通过绘制决策边界的方法来探讨逻辑回归的算法性能,我们将发现对于逻辑回归模型来说,对于二维样本空间的数据来说,只能构建线性决策边界来对数据类别进行划分,因此如果我们单独只看模型对于复杂数据的分类判别能力,那么在所有分类模型中,逻辑回归其实并不属于性能最强的第一梯队。
但是,逻辑回归仍然凭借其线性方程的模型结构,拥有非常好的可解释性,使得其在金融风控领域应用广泛(如评分卡模型),同时我们也可以借助逻辑回归进行特征选择,并且与其他算法进行集成等。跟多关于逻辑回归的模型应用,我们将在下一个阶段重点展开讨论。