【机器学习】强化学习的概念及马尔科夫决策
系列文章目录
第十八章 Python 机器学习入门之强化学习
目录
系列文章目录
前言
一、什么是强化学习?
二、强化学习算法的示例:火星探测器
三、强化学习的回报及折扣因子
四、 强化学习中的策略
五、 总结强化学习关键概念(马尔科夫决策)
总结
前言
之前学习的监督学习需要给定输入x 和输出标签y;半监督学习需要给定输入x;对于强化学习算法,它的关键思想不是告诉算法每个输入x ,标签y 是什么 ,而是给它指定一个奖励函数,告诉它什么时候做的好,什么时候做的不好。算法的工作是自动找出如何选择好的动作。
一、什么是强化学习?
什么是强化学习?
Reinforcement learning
以使用强化学习让直升机自行飞行为例。
在强化学习中,我们将直升机的位置、方向和速度等称为状态 s,任务就是找到一个函数,将直升机的状态映射到动作 a, 让直升机在空中保持平衡飞行而不坠毁。
我们也可以尝试使用监督学习来解决这个问题,不过监督学习需要大量的数据,如果我们有一堆直升机状态的观察结果,也许可以使用监督学习来解决这个问题,直接从状态 s 中学习映射, 不过这些数据都是很难获得的。
说回强化学习,强化学习的一个关键输入是一种叫奖励或奖励函数(reward function )的东西,它告诉直升机什么时候做得好,什么时候做的坏。强化学习算法的工作就是弄清楚如何获得更多的好直升机和更少的坏直升机结果。
对于强化学习,你必须告诉它该做什么而不是如何去做。我们可以设置一个奖励函数,比如说直升机的例子,如果直升机飞行的好时,奖励函数就会给它一个正奖励 例如 + 1;如果飞行不佳时,奖励函数会给它一个负奖励例如 -100。这样一来就会激励直升机花费更多时间飞行良好。
强化学习算法的关键思想不是告诉算法每个输入x 的正常输出y 是什么 ,而是给它指定一个奖励函数,告诉它什么时候做的好,什么时候做的不好。算法的工作是自动找出如何选择好的动作。
二、强化学习算法的示例:火星探测器
下面我们将使用火星探测器的简化示例来开发强化学习。
如图,我们有6个状态,漫游车一开始在状态4,现在漫游车被送到火星上,尝试执行不同的科学任务,它可以去不同的地方使用它的传感器,例如雷达或钻头或光谱仪来分析火星上不同地方的岩石。例如状态1 和 6 的动作是我们想要,那我们可以设置一个奖励函数,状态1 的奖励是100, 状态6 的奖励是40 ,其他的奖励为 0 .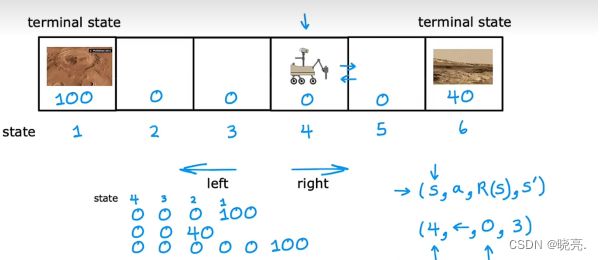
这时候漫游车可以选择向左或者向右走了,向左走虽然步骤更多,但是可以得到100 奖励,向右则可以得到 40 奖励。它也可能向左走一步后发现0 激励而又向右走,最终会的40 的奖励,这些都是可能的。
可以用一个公式表达4 件事,(S, a, R(S), S')(状态,动作,奖励,新状态) ,注意这个奖励是与当前状态相关的,而不是与新状态相关。
三、强化学习的回报及折扣因子
The return in reinforcement learning
什么是强化学习的回报,打个不恰当的比方,一个是你什么都不干我给你5块钱;一个是你帮忙干活半小时,我给你10快。你会选择哪一个呢?这在算法中就涉及到了回报的概念。
回报的概念, 捕捉到 你可以更快获得的奖励 可能 比你需要花费很长时间才能获得的奖励 更有吸引力。
让我们拿火星探测器的例子来说明这个。
如果从状态4,你开始往左走到状态3,得到的给奖励是0 ,继续往左走到状态2,得到的给奖励是0 ,再往左走到状态1(终端位置),得到的给奖励是 100 。
回报被定义为这些奖励总和,但有一个附加因素加权 称为折扣因子。折扣因子是一个略小于1的数字。
如果选择0.9作为折扣因子,我们要权衡第一步的奖励是0,第二步的奖励是0,第三步的奖励是100.
如何使用折扣因子 gamma γ,如图,计算出来的结果是72.9。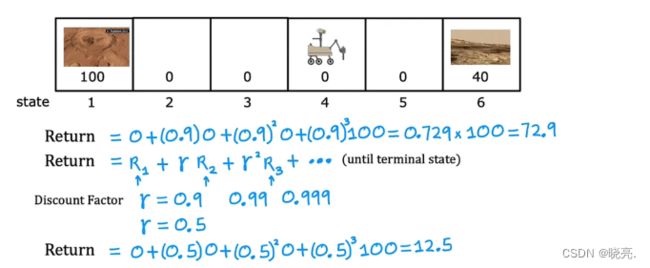
更一般的回报公式是,如果机器人经历了一些状态并在第一步获得奖励R1,第二步获得奖励R2……
那么返回公式就是,R1+ γ* R2 + γ^2 * R3……..
折扣因子gamma 的作用 使得越早得到回报,最后得到的总回报的价值就越高。
γ一般设置为接近于1的数,如果我们设置为0.5,如图最后得到的总回报就只有12.5 了。
如果我们总是向左走,可以看见离状态1越远,奖励越低(状态6开始,奖励是40,因为状态6本身就是终端位置,获得奖励直接停止)
总是向右走,结果也是一样。
所以,算法会根据总回报,在状态5之前的往左走,状态5及之后的往右走,这就是折扣因子的作用。
四、 强化学习中的策略
Make decisions: policies in reinforcement learning
形式化强化学习算法如何选择动作。
在强化学习问题中,我们可以采取多种不同的方式,例如,我们可以决定总是追求更接近的奖励。或总是追求更大或更小的奖励。
在强化学习中,我们的目标是提出一个称为 策略 Pi 的函数,它的工作是将任何状态作为输入并对其进行映射,例如,对底部的这个方案,策略Pi 会说,如果你处于状态2,然后它将我们映射到左侧的动作;如果处于状态5,它将我们映射到右侧的动作……
策略Pi 应用于状态S ,它告诉我们它希望我们在该状态下采取什么行动。
强化学习的目标是找到一个策略Pi ,来告诉我们要采取什么行动,采取每个状态,以最大化回报。
五、 总结强化学习关键概念(马尔科夫决策)
我们以火星探测器为例,说明了强化学习的形式。
我们学习了状态,行动,回报,折扣因子,回报,策略 Pi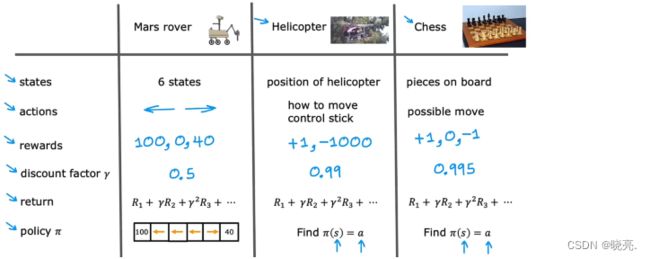
不管是火星探测器,直升机还是国际象棋,这种强化学习应用程序的形式实际上有一个名字,它被称为马尔科夫决策过程 markov decision process(MDP) 。
马尔科夫决策过程是指未来怎么行动只取决于当前状态而不取决于任何事物,这可能发生在进入状态之前。
换句话说,在马尔科夫决策过程中,未来只取决于你现在在哪里,不是关于你是怎么到这里的。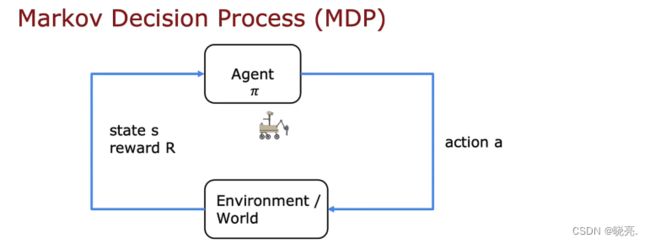
马尔科夫决策过程形式化的另一种表示方法是,我们有一个机器人,我们希望控制它,我们要做的是选择动作a ,让机器人去做某些事,我们选择动作a 的方式是使用策略Pi,并基于机器人做的事情,然后我们可以看到或观察到我们所处的状态,以及我们得到什么奖励。找到一种可以获得最大的奖励的最优方案。
强化学习的目标是给定一个马尔科夫决策过程,寻找最优策略,策略就是状态到动作的映射,使得最终的累计回报最大。
总结
强化学习的形式,无非就是状态,行动,回报,折扣因子,回报,策略 Pi。其中最重要的就是策略Pi, 我们的目的就是要找到这个策略,它可以根据状态告诉我们下一步的行动。而将强化学习应用的过程就叫做马尔科夫决策(MDP),这是一个术语。强化学习的目标是给定一个马尔科夫决策过程,寻找最优策略,策略就是状态到动作的映射,使得最终的累计回报最大。