强化学习与马尔科夫
序言
最近一直看论文,啃到了马尔科夫与强化学习这个硬骨头,非常痛苦,看了一些讲解书籍,为了不忘记,就随便写下这篇博客,写的都是很浅显的知识,今分给众,若能使汝亦损痛,是吾之幸。
一、强化学习的两个基本概念
首先在要了解在强化学习里有两个基本的概念,Environment和Agent。
Environment指的是外部环境,在游戏中就是游戏的环境。Agent指的是智能体,指的就是你写的算法,在游戏中就是玩家,智能体通过一套策略输出一个行为(Action)作用到环境,环境则反馈状态值,也就是Observation,和奖励值Reward到智能体,同时环境会转移到下一个状态。如此不断循环,最终找到一个最优的策略,使得智能体可以尽可能多的获得来自环境的奖励。整个过程如下图所示:
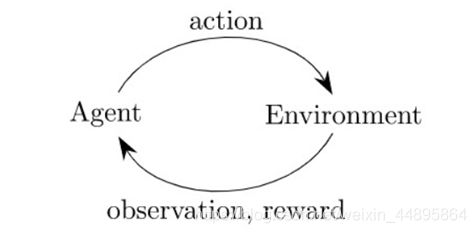
二、再来了解概念 reward,return以及value。
- 给定到目前为止的全部信息,处在当前状态,一直向后探索,得到一条样本轨道。
- 只看下一步的平均收益是reward。
- 把从下一步开始所有的后继过程全部考虑在内,可以得到这一条样本轨道的return。
- 把从下一步开始所有的后继过程全部考虑在内,全部可能样本轨道的平均是value。
换种直观的说法:
1.你在下棋,过去和现在的状态全部知道了,你把下一步所有可能全部考虑了求个平均,得到了你现在所处状态的reward。
2.你设想了一次对决直到决出胜负,这一场对决里后续所有下的棋放到函数里评估,得到的是return。
3.你是一个聪明的棋手,把所有可能决出胜负的走法全部想了一遍,对现在的状态进行评估,得到了value。
4.当然,有Bellman方程之后就可以用动态规划了。
三、一些专业术语(Terminologies)
如果上面没看懂,那么看完下面的专业术语解释,可能就懂了。在强化学习中,我们必须理解下面的这些专业术语。
1.state and action
首先最重要的概念就是state和action。假设你现在在贪吃蛇游戏,当前的状态就是下面这幅图片显示的画面。(当然了,这样说也许不太严谨,但是这样便于初学者理解)。
观测到当前的状态,就能操作蛇做出相应的动作,这个动作就是action,假设贪吃蛇能够做出向上、向下、向左、向右四个动作,如图2所示。蛇就是前面我们所说的agent,反正动作是由谁做的,谁就是agent。
图1 stats s (this frame)
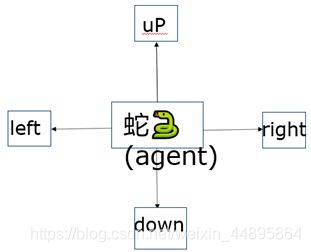
图2 action a∈(left up right down)
2.policy π
第二个就是policy 策略函数π,policy是什么意思呢?就是当你观测到图1所示的画面的时候,该让贪吃蛇做什么动作呢,该往上还是往左。很有可能往右走,因为能够吃到奖励,也有可能往上或者往走。Policy的意思是根据观测到的状态做出决策,控制agent运动。在数学上policy函数定义如下:
policy function π:(s,a)→[0,1]:
π(s│a)=P(A=a|S=s)
这个π就是概率密度函数,意思是给定状态s做出动作a的概率密度。我举个例子,观测到当前状态将会做出前面说的四种动作的一种,把图1显示的当前状态输入policy函数,它会告诉我往各个方向运动的概率:
π(left│s)=0.2
π(up│s)=0.1
π(down│s)=0.3
π(right│s)=0.4
所以在强化学习中,只要有了policy函数,就能让它自动操作蛇游戏了。在这个例子里agent动作是随机的,根据policy函数输出的概率做动作,也有确定的policy,那样输出的动作也是确定的。一般来讲policy还是随机的,如果不是随机的,那么别人将知道你的套路,以至于游戏很难赢。
3.reward R
当agent做出一个动作,游戏久会给一个奖励,这个奖励有我们自己定义,奖励定义的好坏非常影响强化学习的结果。比如,贪吃蛇吃掉一个小球就会增加积分,R=+1,在规定时间击杀别的蛇会得到奖励R=+10,碰到石头得到的奖励时R=-100,什么也没有发生的话R=0。
4.station transition
在agent做出动作后,贪吃蛇的状态变了,游戏到了新的一个状态,这就叫做状态转移。
![]()
状态转移可以是确定的也可以是随机的,随机性来自于环境,这里的environment就是游戏的程序。这里大家可能会疑惑,为什么是游戏程序决定了状态转移的随机性,举个例子说明一下,比如,当蛇往右动的时候,agent的动作是确定的,但是金币,石头的出现是随机的,还有敌人的动作也是随机的,所以状态转移也是随机的。状态转移概率p表示如下:
![]()
意思是观测到当前状态s和动作a,转移到s’的概率。
5. agent environment interaction

图3 agent和environment交互图
首先,在当前状态下,agent做出一个动作a,随后环境会更新状态到St+1,并给予奖励rt。
6.return
前面解释过return,我们以贪吃蛇为例子再继续聊一聊。
![]()
Return就是未来的累计奖励,我们把t时刻的累计奖励叫做U_t,把t时刻开始的奖励加起来,一直加到游戏结束后的最后一个奖励。这里有个问题,Rt和R(t+1)等价吗?
回答这个问题之前,咱们先讨论一个问题,现在有两个选择,第一个是我现在给你100块钱,第二个是我明年给你100块钱,我认为理性的人都会选择前者,因为未来的不确定性很大。那咱们改一下,现在给60块钱,明年给100块钱,或许就会右不同的选择了。
所以未来的100不如现在的100好,未来的100或许就等于现在的60。随所以我们应该未来的奖励打折扣λ。也就是强化学习中用得比较多的折扣回报return,Ut表示如下:
![]()
在t时刻U_t是随机的,这个随机性的来源有两个:
1.动作是随机的
2.新状态是随机的
对于未来的任意时刻i≥t,奖励Ri取决于Si和Ai。
假设我们已经观测到了t时刻的状态St,那么returnUt就依赖于随机变量:
![]()
7.action-value fuction
前面我们定义了Ut是未来奖励打折后的总和,所以agent的目标就是获得return,让return越大越好。那是不是我们知道了Ut就知道了这局游戏是快赢了还是快输了。非也!Ut只是个随机变量,在t时刻,你并不知道Ut是什么。打个比方,假设你抛硬币,正面记作1.反面记作0,在t时刻你没有把硬币抛出去,你不知道你会得到1还是0。
所以在t时刻,我们不知道U_t是什么,那么我们怎么评估当前的形势呢?我们可以对 Ut求期望,把随机性用积分给搞掉,得到的就是实数。
就比如你抛硬币之前不知道会得到什么,但你知道正反面各有一半的概率,那么期望就是0.5。公式如下:
![]()
Ut是一个随机变量,它依赖于未来的所有动作At,A(t+1),A(t+2)……和状态S(t+1),S(t+2),S(t+3)……。
在这里我们把Ut当成未来所有动作和状态的一个函数,S和A都有随机性,除了St和At,其他的随机变量都被积分积掉了(不懂得可以自己写一下随机概率的求期望公式)。Qπ称为动作价值函数,Action-value function for policy π.它只和st,at有关,还与policy函数π有关。我们得到直观意思,如果用π函数,那么在st情况下做动作at是好还是坏。
现在进一步消除π函数,我们可以定义一个最有状态价值函数:
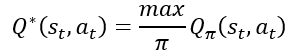
在很多个policy π函数中,找一个最好的,那么Q* (st,a_t )就只与st,at有关,直观意思是在状态st下,动作at是好还是坏的。这个函数的作用很大,就好比在玩贪吃蛇时,这某个状态下,向上得的分数多还是向下分数多。
8.state -value fuction
有动作价值函数,那就有状态价值函数,我们再定义一个状态价值函数:
![]()
Vπ是Qπ (st,A)的期望,前面我们说过,Qπ与S和A都有关,所以,在这里我们把A看成随机变量,然后关于A求期望,把这个A积分掉,得到Vπ,它只跟s_t和π有关。Vπ函数的直观意思就是告诉我们当前的局势好不好,加入我们用Policy函数π来下围棋,Vπ就能告诉我们是快赢了还是快输了,还是和和对手不分高下。
四、马尔可夫决策
现在回过头来,我们再谈马尔可夫决策。为什么再强化学习中会用到马尔可夫决策模型呢?
在强化学习中,agent与environment一直在互动。在每个时刻t,agent会接收到来自环境的状态s,基于这个状态s,agent会做出动作a,然后这个动作作用在环境上,于是agent可以接收到一个奖赏R(t+1),并且agent就会到达新的状态。所以,其实agent与environment之间的交互就是产生了一个序列:
S0,A0,R1,S1,A1,R2,…
我们称这个为序列决策过程。而马尔科夫决策过程就是一个典型的序列决策过程的一种公式化。有了马尔科夫的假设,在解决这个序列决策过程才比较方便,而且实用。所以这也是为何要学习马尔科夫决策过程的原因了。
在学习马尔科夫决策的时候,注意状态转移概率的获取以及最优价值函数。并且建议大家多看看贝尔曼方程,MDP求解时用的迭代算法。
关于马尔可夫决策过程更多的理解学习,大家可以自己去看看,网上有很多我这里就不再赘述了(其实是不想写了)。
第一次写博客,随便写写,问题很多,大家如果真的想学强化学习,还是去看大神们写的为好,有什么建议和问题可以在下面评论,谢谢!
参考
[1]: Webbley强化学习(二):马尔科夫决策过程(Markov decision process)