可信任的人工智能(三)
在本系列文章的前两章我们介绍了人工智能模型的公平性(Fairness)、可解释性(Explainability)以及模型质量(Quality)的基本概念。这些都是构建可信任的人工智能平台的重要因素。在本文中我们将介绍IBM为建立可信任的人工智能推出的解决方案——IBM Watson Studio Trusted AI。
IBM Watson Studio Trusted AI介绍
IBM Watson Studio Trusted AI(原IBM Watson OpenScale)是IBM所提供的一项云原生服务。该服务能够追踪和度量人工智能模型的输出,确保其公平、可解释和符合规范。Watson Studio Trusted AI还可以辅助用户修正模型在生产或者准生产环境中发生的模型漂移(Drift)。
Watson Studio Trusted AI在IBM Cloud,基于x86或者Linux on Z的IBM Cloud Pak for Data 上均可用。
Watson Studio Trusted AI不仅仅可以监控部署在IBM Cloud或者在IBM Cloud Pak for Data上的模型,还可以监控部署在AWS SageMaker、Azure ML Studio、Azure ML Service的模型。对于部署在其他服务之上的模型,用户也可以通过在服务中安装Watson OpenScale SDK来进行监控。
要使用Watson Studio Trusted AI对模型进行监控,需要在模型部署后持续对模型在准生产或者生产环境中的表现进行记录。这些记录包括反馈记录(Feedback Logging)和荷载记录(Payload Logging)。
反馈记录是指包含了特征(Feature)和人工标注了标签(Label)的数据集。反馈记录通常是在模型上线后由业务人员在新的生产数据上获知了被评分数据的实际结果后进行标注而得到的。反馈记录一般是批量生成的。客户可以将反馈记录以CSV或者JSON的格式存储起来,然后通过Watson Studio Trusted AI的界面上传。
荷载记录(Payload)则是指包含了特征(Feature)和模型预测结果(而不是业务人员确认的实际结果)的数据。荷载记录在模型被调用的过程中产生的。它更像是模型评分服务的日志。对于每一条评分调用请求,模型评分服务需要将请求(Request)和响应(Response)的荷载(Payload)都按照Watson Studio Trusted AI要求的格式发送给Watson Studio Trusted AI记录下来。评分服务的请求(Request)中应该包含模型需要的特征的值。而评分服务的响应(Response)中除了包含模型需要的特征的值,还需要包含模型预测的结果(Target),在可能的情况下还应该提供模型预测的一些中间结果——例如概率(probability)和原始预测(rawPrediction)。Watson Studio Trusted AI提供了SDK。利用这些SDK,客户可以在其模型评分服务中将上面提到的信息通过REST API发送给Watson Studio Trusted AI。
有些客户可能会对在模型评分服务中增加荷载带来的性能影响有所担心。针对这种情况,Watson Studio Trusted AI提供了批处理(Batch Processing)模式来处理荷载记录。在批处理模式下,荷载记录不会把每一个评分请求和响应都逐个发送给Watson Studio Trusted AI,而是会把这些信息记录在本地的Hive数据库里。对模型公平性、质量和漂移的分析可以使用本地的Spark分析引擎来完成,从而能大大提升分析的效率。Watson Studio Trusted AI的批处理模式即支持IBM分析引擎(Analytics Engine)的Spark也支持其他Hadoop生态系统中部署的Spark。
Watson Studio Trusted AI支持对模型的公平性、质量和漂移进行监控。用户可以对这些属性的性能指标设置阈值。当模型不能满足这些性能指标的阈值定义,Watson Studio Trusted AI会发出告警。
下面我们通过几个案例来了解Watson Studio Trusted AI如何帮助客户实现可信任的人工智能。
Watson Studio Trusted AI实战案例1 – 解释模型
某保险公司训练了一个机器学习模型来对车损理赔进行自动处理。在模型作出了它的判断之后,业务专员可以使用Watson Studio Trusted AI对模型的输出做出解释——通过了解一次理赔中哪些因素影响了模型的结果来判断模型的输出是否值得信赖。
如下图所示,模型对于此次理赔作出了拒赔的建议,其原因包括保单年限(Policy Age)低于一年、该客户理赔频繁(Claim Frequency - High)以及客户年龄(Age)低于18岁等。尽管账户类型(Account Type)——个人(Individual)更支持做出批准赔付的判断,但是对结果的影响(10%)远低于拒绝理赔的因素(90%)。您如果看过本系列的第一篇文章中,可能会发现模型可视化的解释很熟悉。下图中的模型解释正是基于我们在那篇文章中介绍的LIME做出的。
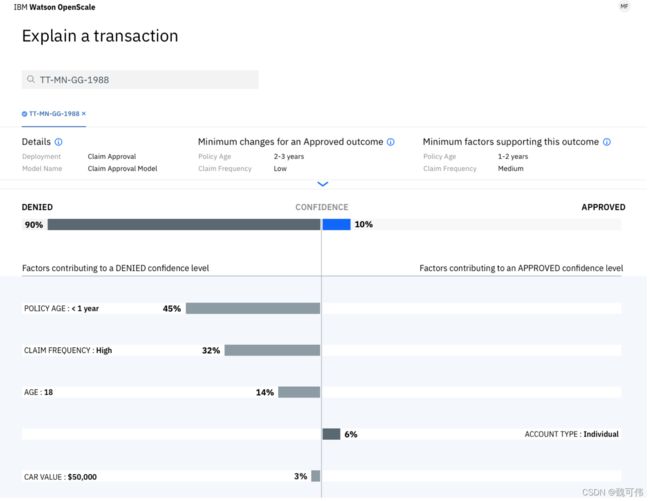
(图片来源: https://medium.com/trusted-ai/explaining-ai-model-behaviour-with-ibm-watson-openscale-86515702c177)
除LIME算法,Watson Studio Trusted AI还可以基于IBM研究院研发的技术对模型进行对比解释(Contrastive Explanations)。对比解释除了解释各特征对模型输出的影响还解释了特征的改变会如何影响模型的输出结果。例如,在上面的示例中,在其他条件不变的情况下,如果保单年限为2-3年同时理赔频率低的,该模型就会做出支持理赔的预测。而要让模型做出支持拒赔的预测,在其他条件不变的情况下,则需要保单年限为1-2年且理赔频率最高为为中等。有了这些信息,业务专员就能够对模型的预测是否符合实际更有信心。
Watson Studio Trusted AI实战案例2 – 消除偏见
在前文所述的保险公司使用机器学习模型来自动处理车损理赔的案例中,该保险公司非常重视公平性因而不希望该模型存在针对性别、年龄或者种族的偏见(Bias)。他们可以使用Watson Studio Trusted AI来消除偏见。下面的例子主要针对年龄这一受保护属性进行偏见分析。

(图片来源: https://medium.com/trusted-ai/bias-detection-in-ibm-watson-openscale-6f37f055a1aa)
如上图所示,25-75的年龄组中有70%的理赔申请得到了批准,而31-35的年龄组更是有90%的理赔申请得到了批准,但是18-24年龄组只有52%的申请得到了批准。在这个例子中,18-24年龄组可以被认为是非特权群体或者少数派。其与其他群体的差别影响(Disparate Impact)达到了 52/70 = 0.74。该保险公司希望对于差别影响小于0.8的模型进行审查,所以Watson Studio Trusted AI中的模型公平性阈值被设置为0.8,大于0.74。在偏见分析中,Watson Studio Trusted AI对年龄为18-24的区间现实为红色,也就是说该模型对年龄18-24的群体可能存在偏见。
差别影响是公平性分析的重要指标,但是差别影响低并不意味着模型一定不够公平。Watson Studio Trusted AI不仅仅会考虑差别影响,还会进行数据扰动(Data Perturbation)分析。数据扰动针对的是结合受保护属性和其他属性进行分析的方法。例如,在上例中用作公平性分析的数据集中,如果18-24年龄组的申请中存在大量频繁理赔的申请,而31-35年龄组则是很少理赔的申请。在这种情况下实际影响模型选择的是另一个属性理赔频率,所以模型的预测其实是合理的。但是在实际情况下,很难发现到底究竟是哪些属性起了作用,因而数据扰动分析就会很有帮助。数据扰动是一种黑盒分析,会通过更改受保护属性的值来验证模型的输出是否仅仅是受保护属性的影响。例如,将一名20岁申请人的被拒绝的理赔记录中的年龄从20改为40,其他条件不变,然后检查修改过的记录是否会被批准,就能知道年龄是否是模型输出的关键因素。
当Watson Studio Trusted AI确定一个模型在某些属性上存在偏见时,Watson Studio Trusted AI可以通过对交易中的原始输入进行修改来消除偏见。例如,当一个理赔的请求来自于一个非特权群体——18-25年龄组,Watson Studio Trusted AI可以通过将请求中的申请者年龄从非特权群体修改成随机的特权群体才有的属性值——比如说将年龄改成40岁。这个过程就可以将偏见消除。如下图所示,经过Watson Studio Trusted AI消除偏见,18-24年龄组的理赔赔付率从52%提升到了65%,公平性评分从0.74提升到了0.93。模型的准确性则只是略有下降(90%到89%)。
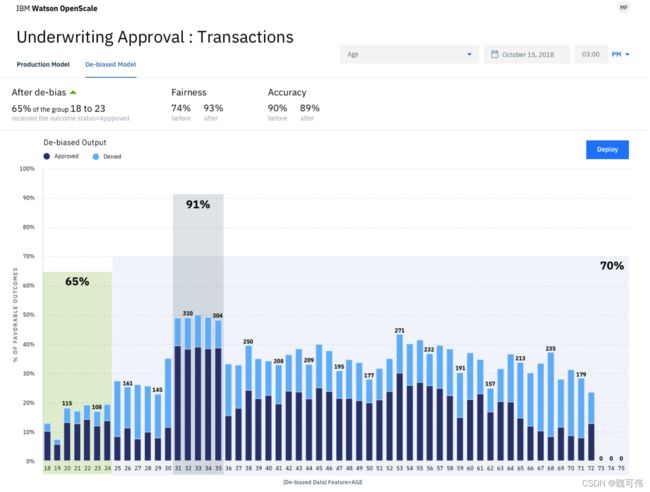
(图片来源: https://medium.com/trusted-ai/de-biasing-in-ibm-watson-openscale-95ca89fa2072)
Watson Studio Trusted AI实战案例3 – 监测漂移
在本系列文章的第二篇中,我们介绍了模型漂移的概念。Watson Studio Trusted AI可以有效监控概念漂移和数据漂移。
最直接的监控模型准确性的方法是取得模型的反馈数据集。但是对模型的结果进行反馈通常需要额外的工作而导致模型监控的滞后性。Watson Studio Trusted AI可以在未取得完整标注过的反馈数据集的情况下发现模型准确性的变化,从而更及时的发现漂移。
要使用Watson Studio Trusted AI监测漂移,Watson Studio Trusted AI首先需要理解客户模型在训练数据集和测试数据集上的行为模式。Watson Studio Trusted AI会根据客户模型在训练数据集和测试数据集上的表现构建漂移监测模型(Drift Detection Model)。该漂移监控模型可以在客户模型上线后分析实时预测的结果,根据该模型在训练集和测试集上的表现,结合客户模型的输入给出对模型输出准确性的评估。
另一方面,Watson Studio Trusted AI还可以收集客户模型上线后收到的输入数据,分析数据的特性并和训练数据集的特性比较,如果发现了特性的变化,就会提示数据漂移的发生——也就是数据不一致的现象。
下图所示的是Watson Studio Trusted AI监控漂移的例子。蓝线所表示的是模型准确性的下降;绿线所表示的发生数据漂移的数据在所有数据中的占比。在该例子中,模型的准确性下降了20%,模型的数据一致性下降了10%。该客户对模型准确性下降设置的阈值时10%,因而Watson Studio Trusted AI会对模型准确性的变化告警。
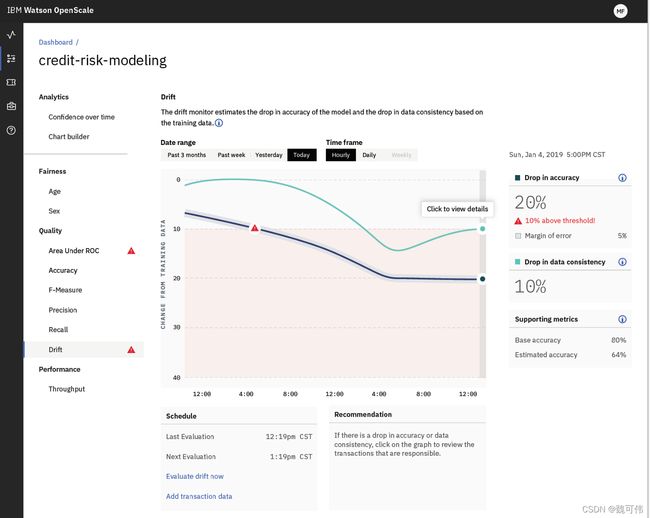
(图片来源: https://medium.com/trusted-ai/understanding-model-drift-with-ibm-watson-openscale-4c5401aa8da4)
在侦测到模型漂移后,利用Watson Studio Trusted AI还可以进一步分析模型漂移的原因。如下图所示,Watson Studio Trusted AI会对有模型准确性下降和数据一致性下降的交易进行分组。用户可以通过点击相应的分组查看有关的交易,进而请业务人员对这些可能存在准确性或者数据一致性问题的交易重新标注,这样数据科学家就可以使用这些重新打标签的数据进行再次训练,从而修正模型质量的问题。

至此,我们对可信任的人工智能的介绍告一段落。在系列的三篇文章,我们分别介绍了可信任的人工智能的基本概念和IBM解决方案Watson Studio Trusted AI。希望这一系列能对您理解可信任的人工智能有所帮助。如果您对IBM的解决方案感兴趣,欢迎访问IBM Cloud上的Watson Studio免费试用 - Watson Studio | IBM。
参考文献:
IBM Watson Studio
Watson Studio | IBM
Explaining AI Model Behaviour with IBM Watson OpenScale
https://medium.com/trusted-ai/explaining-ai-model-behaviour-with-ibm-watson-openscale-86515702c177
Bias Detection in IBM Watson OpenScale
https://medium.com/trusted-ai/bias-detection-in-ibm-watson-openscale-6f37f055a1aa
De-Biasing in IBM Watson OpenScale
https://medium.com/trusted-ai/de-biasing-in-ibm-watson-openscale-95ca89fa2072
Understanding Model Drift with IBM Watson OpenScale
https://medium.com/trusted-ai/understanding-model-drift-with-ibm-watson-openscale-4c5401aa8da4
关于作者:
本文由IBM主机机器学习平台开发团队共同完成
魏可伟(Kewei Wei, [email protected]),IBM主机机器学习平台首席架构师,资深技术主管(Senior Technical Staff Member)
万蒙(Meng Wan, [email protected]),IBM主机机器学习平台资深架构师
刘旺(Wang Liu, [email protected]),IBM主机机器学习平台资深架构师
司美琴(Mei Qin Si, [email protected]),IBM主机机器学习平台资深软件工程师
胡雪瑞(XueRui Hu, [email protected]),IBM主机机器学习平台开发工程师
郭丽娜(Lina Guo, [email protected]),IBM主机机器学习平台开发工程师
矫冬颖(Dongying Jiao, [email protected]),IBM主机机器学习平台开发工程师