spark和flink是什么、区别、共同点以及替换性
目录
- 声明
- 1. spark
-
- spark 计算速度快
- Spark与MR
- 2. flink
-
- flink是什么
- flink特点
- flink能做什么
- 四、flink , mapreduce , Spark 对比
- 另一篇flink介绍
- Spark和Flink的对比
-
- 一、数据抽象
- 二、如何进行容错恢复
- 三、计算模式
- 四、对迭代计算的支持
- 五、对交互式查询的支持
- 六、计算延迟
- 七、内存管理模型
- 八、如何选择使用哪种计算框架
声明
本文是对已有的几篇csdn博客的一个提炼与总结,仅用于自己学习理解
所有引用均有明确标注
1. spark
Spark是基于内存计算的大数据并行计算框架。除了扩展了广泛使用的MapReduce计算模型,而且高效地支持更多计算模式,包括交互式查询和流处理。Spark适用于各种各样原先需要多种不同的分布式平台的场景,包括批处理、迭代算法、交互式查询、流处理
Spark除了一站式的特点之外,另外一个最重要的特点,就是基于内存进行计算,从而让它的速度可以达到MapReduce、Hive的数倍甚至数十倍!
Spark主要用于大数据的计算,而Hadoop以后主要用于大数据的存储(比如HDFS、Hive,HBase等),以及资源调度(Yarn)。
Spark+Hadoop的组合,是未来大数据领域最热门的组合,也是最有前景的组合!
spark 计算速度快
spark将每个任务构建成DAG进行计算,内部的计算过程通过弹性式分布式数据集RDD在内存在进行计算,相比于hadoop的mapreduce效率提升了100倍。
Spark与MR
MapReduce能够完成的各种离线批处理功能,以及常见算法(比如二次排序、topn等),基于Spark RDD的核心编程,都可以实现,并且可以更好地、更容易地实现。而且基于Spark RDD编写的离线批处理程序,运行速度是MapReduce的数倍,速度上有非常明显的优势。
Spark相较于MapReduce速度快的最主要原因就在于, MapReduce的计算模型太死板,必须是map-reduce模式,有时候即使完成一些诸如过滤之类的操作,也必须经过map-reduce过程,这样就必须经过shuffle过程。 而MapReduce的shuffle过程是最消耗性能的,因为shuffle中间的过程必须基于磁盘来读写。而Spark的shuffle虽然也要基于磁盘,但是其大量transformation操作,比如单纯的map或者filter等操作,可以直接基于内存进行pipeline操作,速度性能自然大大提升。
但是Spark也有其劣势。 由于Spark基于内存进行计算,虽然开发容易,但是真正面对大数据的时候(比如一次操作针对10亿以上级别),在没有进行调优的情况下,可能会出现各种各样的问题,比如OOM内存溢出等等。 导致Spark程序可能都无法完全运行起来,就报错挂掉了,而MapReduce即使是运行缓慢,但是至少可以慢慢运行完。
此外,Spark由于是新崛起的技术新秀,因此在大数据领域的完善程度,肯定不如MapReduce,比如基于HBase、Hive作为离线批处理程序的输入输出,Spark就远没有MapReduce来的完善。实现起来非常麻烦。
————————————————
版权声明:本文为CSDN博主「<一蓑烟雨任平生>」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/weixin_45366499/article/details/110010589
2. flink
flink是什么
flink是一个面向流处理和批处理的分布式计算框架,即支持流处理,也支持批处理。
flink基于流处理引擎实现,正真做到了流处理,将批处理看作一种特殊的有界流
flink是基于java编程语言实现,支持java,scala,python进行编程开发
flink支持单机执行,或运行在大数据的yarn集群,或部署到k8s中执行
flink特点
支持有状态计算的Extactor-once语义及checkpoint
支持带有事件操作的流处理和窗口处理
支持灵活的窗口处理(时间,大小等多种窗口)
轻量级容错处理(使用savepoint进行错误恢复)
高吞吐,低延迟,高性能的流处理
支持savepoints机制(任务恢复)
支持大规模集群模式(yarn,Mesos,k8s)
内部实现了JVM内存管理
支持迭代计算和自动优化
flink能做什么
1、事件驱动型应用:一类具有状态的应用,它从一个或多个事件流提数据,并根据到来的事件触发计算,状态更新或其他外部操作(如:反欺诈,异常检测,规则告警)
2、数据分析应用:从原始数据中提取有价值的信息和指标。(如:数据监控,实验评估,实时数据分析)
3、数据管道应用:提取-转换-加载(ETL)是一种在存储系统之间进行数据转换和迁移的常用方式。 数据管道和 ETL 作业的用途相似,都可以转换、丰富数据。ETL会周期的将数据从某个存储系统移动到另一个。但数据管道是以持续流模式运行,而非周期性触发(如:检测文件系统目录,将新文件写到其他库)
四、flink , mapreduce , Spark 对比
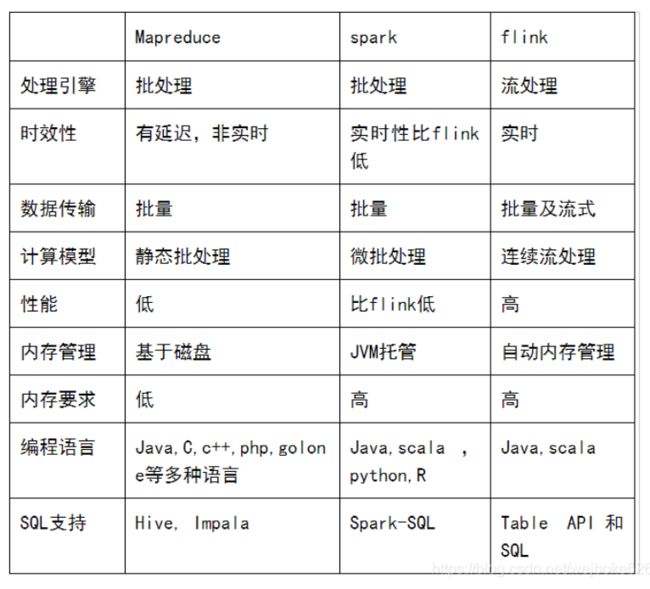
————————————————
版权声明:本文为CSDN博主「wejboke626」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/wejboke626/article/details/115567854
另一篇flink介绍
有很多人将大数据的计算引擎分成了 4 代
第 1 代:Hadoop MapReduc 批处理 Mapper、Reducer 2;
第 2 代:DAG 框架(Oozie 、Tez),Tez + MapReduce 批处理 1 个 Tez = MR(1) + MR(2) + … + MR(n) 相比 MR 效率有所提升;
第 3 代:Spark 批处理、流处理、SQL 高层 API 支持 自带 DAG 内存迭代计算、性能较之前大幅提;
第 4 代:Flink 批处理、流处理、SQL 高层 API 支持 自带 DAG 流式计算性能更高、可靠性更高。
Apache Flink 是为分布式、高性能、随时可用以及准确的流处理应用程序打造的开源流处理框架
————————————————
版权声明:本文为CSDN博主「数据人生coding」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/helloHbulie/article/details/120333974
Spark和Flink的对比
一、数据抽象
Spark:RDD(弹性分布式数据集)
Flink:stream(数据流:有界流和无界流),将批和流统一成流,只是批被抽象成一种有界流
二、如何进行容错恢复
Spark:通过DAG组成的谱系图(lineage)进行任务失败重计算,也可以设置检查点,为driver重启以及谱系截断使用。
Flink:通过检查点进行流重放(replay),Flink对分布式数据流和操作符的状态进行快照,对快照数据实施检查点。故障发生时,停止流处理,将运算重启并将输入置为上一个成功实施的检查点数据。
Spark检查点,前边有专门的文章描述,见如下链接:
https://blog.csdn.net/weixin_43878293/article/details/90752738
这里稍微说下Flink检查点,根据官网描述
Flink检查点通过对分布式数据流进行轻量级异步快照来完成。
首先,Flink的数据流由Barrier分隔,可以这么说,多个Barrier将流分成段。
Barrier与Barrier之间的流数据记录就被当做一个快照单位。
如果有多个流,则需要进行对齐,比如说多个源数据流达到第一个操作符,其中有些流的Barrier n先到达操作符,那么操作符会等待其它流的Barrier n到达,其它流的Barrier n全都到达之后,该操作符便发出Barrier n给下游操作符。
当到达Sink操作符时,每到达一个流的Barrier n进行一个确认,当所有流的Barrier n都到达并确认之后,系统便认为Barrier n已经完成。
操作符的状态快照进行时间:
当所有流的Barrier n均达到该操作符之后,并在将Barrier n发出到拓扑下游操作符之前。
此时,所有来自Barrier n之前的记录对状态的更新均已完成,状态被存储。
状态被存储之后,操作符发出checkpoint确认信息,标志该检查点完成,然后将用于快照的Barrier n发往输出流,并继续。
然后我们看看最终的快照包含些什么:
1、对于并行输入流,快照包含了快照开始时的流偏移。
2、对于操作运算符,快照包含了指向其存储的状态数据的指针。
这里有一点可以知道,对齐操作肯定是会带来延迟的。
Flink做了一个开关,可以跳过对齐操作。
不用对齐,也就是说,在快照时,Barrier n内的记录快照也将包含Barrier n+1的部分记录,而包含的这部分Barrier n+1的数据,会在Barrier n+1的checkpoint中被重放,也就是是说,这部分数据将是重复的。
对齐仅仅发生在像join、reparationing/shuffle等具有多上游作为输入、或者其结果会发往多个下游的操作符。
Flink异步状态快照实现方式:
同步会耽误时间。异步的话,需要使得后续的继续处理对该Barrier n之前的快照状态不产生影响,于是需要一个对象来保存状态。Flink利用写时复制,操作符在产生Barrier n状态输出的同时对状态输出进行一份拷贝,之后的流记录状态更新对拷贝的对象不产生影响。
由后台进程进行状态存储工作,当操作符所有的输入流Barrier n均已到达之后,操作符便启动拷贝其状态的工作,并立即往输出流发出Barrier n,然后继续处理后续流记录。以此达到异步检查点的效果。
恢复:
遇到失败时,Flink选择上一个完整的checkpoint数据。系统重部署整个分布式数据流,输入源置为上一个checkpoint记录的位置,并将所有操作符的状态置为checkpoint中进行的各操作符快照状态数据。
如果快照是增量快照,那么操作符从上一个完整状态快照开始,并进行一系列的状态快照增量更新操作。
运算符快照实现:
分为两个部分,同步部分和异步部分
同步部分:运算符和状态backends将其状态快照提供为Java FutureTask,FutureTask包含了同步操作已经完成而异步操作处于挂起的状态数据,执行checkpoint时后台线程就执行挂起的异步操作。
异步部分:操作符同步返回已经完成的FutureTask,如果异步操作需要执行,则异步操作在FutureTask的run()方法中执行。
三、计算模式
Spark:本质上还是批处理,流处理是微批处理,计算框架仍然是MapReduce
Flink:连续运算符模式
四、对迭代计算的支持
Spark:由于是内存计算,并且Spark的RDD模型能够与机器学习训练模型很好的契合,可以很好的支持迭代计算,并且有很多库可以使用,API很方便。
Flink:定义step function并将其嵌入到迭代运算符中来实现迭代计算,对并行的所有的step function进行求值得到superstep,并在superstep的粒度上进行同步,也就是说保证一次迭代全部完成才开始下一次迭代。
五、对交互式查询的支持
Spark:提供Spark SQL满足用户交互式查询需求
Flink:提供顶层SQL抽象
六、计算延迟
Spark:批处理因为启动任务等等,延迟大概在100ms范围内,continus模式延迟大概1ms范围
Flink:由于是基于运算符的连续流处理,流处理延迟小于Spark,这点优于Spark
七、内存管理模型
Spark:统一内存模型,内存主要被划分为Storage内存、Execution内存、Other内存。
Flink:以MemorySegment为最小内存单位抽象,由MemoryPool来管理,MemorySegment有两种实现,堆和非堆,可配置。由MemoryPool来管理内存,分配、回收等,大大减小了GC压力。
八、如何选择使用哪种计算框架
Spark:特点,高吞吐、高性能、低延迟。能满足大部分流处理应用(如官方所讲,因为传感器触发、人为事件等的延迟均为ms级以上,所以说Spark能满足大部分流处理应用),但是由于Spark任务启动、stage执行的等待(需要等到一个stage执行完才能进行下一个stage)等带来的延迟,使得Spark并不适合实时性要求极高的流处理。另外,Spark有着丰富的库支持,使得使用起来非常方便。
Flink:特点,高吞吐、高性能、实时性高于Spark,由于其基于操作的运算完成后可立即将结果发往下游算子进行计算,因此其延迟非常小。适合对实时性要求严格的需求。可以说Flink是Spark强有力的竞争者。
————————————————
版权声明:本文为CSDN博主「初心江湖路」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/weixin_43878293/article/details/102790252