大数据计算框架Spark、Flink、MapReduce入门
1、安装scala环境
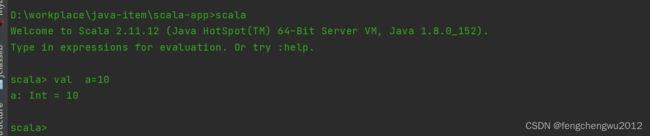
官网下载地址 Download | The Scala Programming Language,本次使用版本为sacla2.11.12,将压缩包解压至指定目录,配置好环境变量,控制台验证是否安环境是否可用
2、使用maven 创建一个scala项目
pom文件加入scala的sdk依赖
2.11.12
org.scala-lang
scala-library
${scala.version}
org.scala-lang
scala-compiler
${scala.version}
org.scala-lang
scala-reflect
${scala.version}
加入spark的相关依赖
org.apache.spark
spark-core_2.11
2.4.8
org.apache.spark
spark-streaming_2.11
2.4.8
provided
加入flink相关依赖
org.apache.commons
commons-compress
1.21
org.apache.flink
flink-scala_2.11
1.14.0
org.apache.flink
flink-clients_2.11
1.14.0
3、sprk实现WordCount
准备数据源 text_spark.txt
中国 河南
中国 浙江
河南 郑州
浙江 杭州
河南 洛阳
浙江 宁波
美国 纽约
纽约 华尔街
美国 吉利福尼亚
加利福尼亚 落砂机
上代码
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object SparkWordCount {
def main(args: Array[String]): Unit = {
///使用本地模式连接spark
val conf = new SparkConf().setAppName("WordCount").setMaster("local")
val sc = new SparkContext(conf)
///读取文件中每一行字符 存入到是数据集合RDD中
val lines: RDD[String] = sc.textFile("D:/workplace/java-item/res/file/test_spark.txt")
/// 将数据集合进行扁平化操作 以字符空格分割
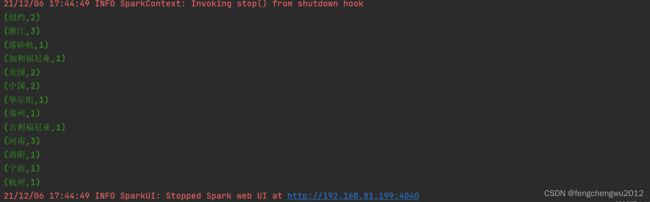
val tuples = lines.flatMap(_.split(" ")).groupBy(word => word).map({ case (w, l) => (w, l.size) }).collect()
tuples.foreach(println)
}
}运行结果
4、Flink实现WordCount
准备数据源text_flink.txt
河南 郑州
河南 信阳
郑州 金水区
河南 开封
郑州 管城区
信阳 浉河区
信阳 平桥区
开封 龙亭区入门编码
import org.apache.flink.api.scala._
import org.apache.flink.api.scala.ExecutionEnvironment
object FlinkWordCount {
def main(args: Array[String]): Unit = {
//创建执行环境
val environment = ExecutionEnvironment.getExecutionEnvironment
//读取文件
val dataSet = environment.readTextFile("D:/workplace/java-item/res/file/test_flink.txt")
//将读取的字符扁平化操作,并且按照空字符分割装入到元祖之中,按照元组的第一个元素分组,分组后按照元组的第二个值求和
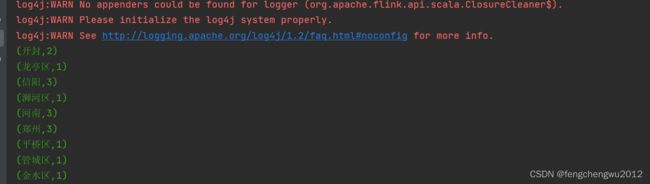
val aggregateDataSet = dataSet.flatMap(_.split(" ")).map((_, 1)).groupBy(0).sum(1)
///打印聚合数据
aggregateDataSet.print()
}
}
运行结果
5、MapReduce实现WordCount
hadoop的离线计算框架MapReduce,实现WordCount就稍许麻烦了,在计算效率上比Flink 、Spark还是要逊色很多
编写Map类
public class WordCountMapper extends Mapper {
Text k = new Text();
IntWritable v = new IntWritable(1);
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 1 获取一行
String line = value.toString();
// 2 切割
String[] words = line.split(" ");
// 3 输出
for (String word : words) {
k.set(word);
context.write(k, v);
}
}
} 编写Reduce类
public class WordCountReduce extends Reducer {
int sum;
IntWritable v = new IntWritable();
@Override
protected void reduce(Text key, Iterable values, Context context) throws IOException, InterruptedException {
// 1 累加求和
sum = 0;
for (IntWritable count : values) {
sum += count.get();
}
// 2 输出
v.set(sum);
context.write(key,v);
}
}
提交计算
/**
*MapReduce 编程 yarn
*/
public static void mapReduceDriver(String ... args) throws IOException, ClassNotFoundException, InterruptedException {
// 1 获取配置信息以及封装任务
Configuration configuration = new Configuration();
Job job = Job.getInstance(configuration);
// 2 设置jar加载路径
job.setJarByClass(HadoopApp.class);
// 3 设置map和reduce类
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReduce.class);
// 4 设置map输出
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
// 5 设置最终输出kv类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// 6 设置输入和输出路径
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
// 7 提交
boolean result = job.waitForCompletion(true);
System.exit(result ? 0 : 1);
}测试
String inPath="D:/workplace/java-item/res/file";
String outPath = inPath+"/hadoop";
try {
HadoopUtils.mapReduceDriver(inPath+"/hadoop_word_count.txt", outPath+"/out_word_count.txt");
} catch (IOException | ClassNotFoundException | InterruptedException e) {
e.printStackTrace();
System.out.println("执行任务调度失败");
}