PyTorch模型开发使用PyTorch GPU2Ascend
PyTorch模型开发使用PyTorch GPU2Ascend
https://www.bilibili.com/video/BV1UK411U7x4/?spm_id_from=333.999.0.0&vd_source=0ae52993ebd370d1051f9dd886e17add
一、MindStudio介绍
MindStudio提供您在AI开发所需的一站式开发环境,支持模型开发、算子开发以及应用开发三个主流程中的开发任务。依靠模型可视化、算力测试、IDE本地仿真调试等功能,MindStudio能够帮助您在一个工具上就能高效便捷地完成AI应用开发。MindStudio采用了插件化扩展机制,开发者可以通过开发插件来扩展已有功能。
MindStudio具有如下功能:
- 针对安装与部署,MindStudio提供多种部署方式,支持多种主流操作系统,为开发者提供最大便利。
- 针对网络模型的开发,MindStudio支持TensorFlow、Pytorch、MindSpore框架的模型训练,支持多种主流框架的模型转换。集成了训练可视化、脚本转换、模型转换、精度比对等工具,提升了网络模型移植、分析和优化的效率。
- 针对算子开发,MindStudio提供包含UT测试、ST测试、TIK算子调试等的全套算子开发流程。支持TensorFlow、PyTorch、MindSpore等多种主流框架的TBE和AI CPU自定义算子开发。
- 针对应用开发,MindStudio集成了Profiling性能调优、编译器、MindX SDK的应用开发、可视化pipeline业务流编排等工具,为开发者提供了图形化的集成开发环境,通过MindStudio能够进行工程管理、编译、调试、性能分析等全流程开发,能够很大程度提高开发效率。
二、PyTorch GPU2Ascend介绍
2.1 PyTorch GPU2Ascend工具介绍
PyTorch GPU2Ascend工具可将基于GPU的训练脚本转换为支持NPU的脚本,大幅度提高脚本迁移速度,降低开发者的工作量。本样例指导可以让开发者快速体验PyTorch GPU2Ascend工具的迁移效率。原基于GPU的训练脚本转换成功后可在NPU上运行。PyTorch GPU2Ascend工具作用概述如下:
- 分析迁移工具根据适配规则,对用户脚本进行分析迁移,大幅度提高了 脚本迁移速度,降低了开发者的工作量。迁移成功后可直接运行,部分模型需要根据实际情况进行少量适配。
- 原脚本需要在GPU环境下且基于python3.7及以上能够跑通。
- 脚本迁移后的执行逻辑与迁移前保持一致。
- 此分析迁移工具当前支持PyTorch1.5.0和1.8.1版本的训练脚本进行迁移。
2.2 进行模型迁移的原因
NPU(Neural network Processing Unit), 即神经网络处理器。神经网络处理器(NPU)采用“数据驱动并行计算”的架构,特别擅长处理视频、图像类的海量多媒体数据。NPU处理器专门为物联网人工智能而设计,用于加速神经网络的运算,解决传统芯片在神经网络运算时效率低下的问题。
NPU是AI算力的发展趋势,但是目前训练和在线推理脚本大多还基于GPU。由于NPU与GPU的架构差异,基于GPU的训练和在线推理脚本不能直接在NPU上使用,需要迁移为支持NPU的脚本后才能使用。为了能让这些脚本在NPU架构上进行训练和推理,Mindstudio为我们提供了进行模型转换的接口,即将基于GPU的脚本经过转换后在华为昇腾系列(HUAWEI Ascend)AI处理器上能进行训练和推理。
三、环境配置
进行模型转换前需要配置好本地环境和远端环境。本地环境为windows环境,而远端环境为linux服务器。
3.1 远端环境配置
Linux服务器上需安装部署好对应固件与驱动、Ascend-cann-toolkit开发套件包(参考可参考《CANN 软件安装指南》的“安装开发环境”章节),并配置好torch1.5.0。
获取torch1.5.0二进制包。 用户可参考昇腾官网中的《pytorch1.5.0安装指南》进行安装,但由于安装过程中的网络限制,会导致此种方式安装过程较慢。因此提供另一种简便安装方式,用户可先在百度网盘(链接:https://pan.baidu.com/s/1I_q6RptnZCagPqzTucG0tg 提取码:69js)下载torch1.5.0的二进制包,并将包上传至linux服务器任意路径。
![]()
**安装torch1.5.0二进制包。**进入二进制包存放路径,在命令行输入pip install + 包名 进行安装

因为之前安装过pytorch,可以看到我们是先卸载再安装
**配置环境变量。**首先以运行用户登录,在任意目录下执行vi ~/.bashrc命令,打开.bashrc文件,在文件最后一行后面添加以下内容(以非root用户的默认安装路径为例)。

然后执行:wq!命令保存文件并退出,最后执行source ~/.bashrc命令使其立即生效。
3.2 本地环境配置
本地环境选用Windows10 x86_64操作系统,需在本地环境即windows服务器上安装好mindstudio,本案例指导以5.0.RC2Windows为例:
步骤一 下载安装包
进入官网下载MindStudio 5.0.RC2Windows版本,下载免安装压缩版,解压后进入bin目录可直接运行

步骤二 运行程序启动文件
下载完成后,将文件进行解压,双击解压后文件,并进入bin目录,双击MindStudio64.exe

步骤三 导入配置
选择Do not import settings

- **Config or installation folder:**表示从自定义配置目录导入MindStudio设置。自定义配置目录所在路径:C:\Users\个人用户\AppData\Roaming\MindStudioMS-{version},MindStudio设置包括工程界面的个性化设置(例如背景色等信息)等。
- **Do not import settings:**不导入设置,若选择该选项,则创建新的配置文件,默认为该选项。
根据需要选择相关选项后,单击“OK”,进入下一步。
如果没有报错信息且能正常进入欢迎界面,则表示MindStudio安装成功

四、模型迁移
4.1获取项目代码
本样例选择resnet50模型,数据集为cifar100(无需提前准备,训练时可自动下载)。首先点击仓库地址进入代码仓,复制代码下载地址
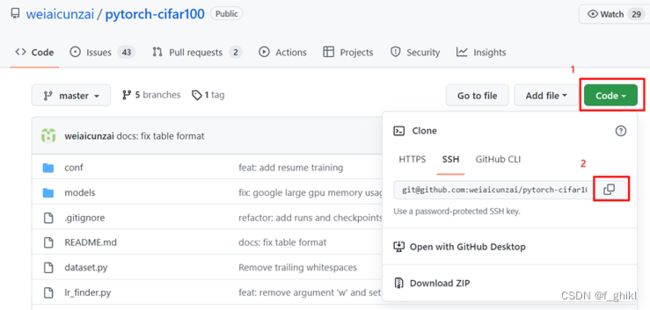
利用git克隆代码,在本地存放代码的路径右击Git Bash Here,输入命令git clone +下载地址,下载成功后如下图所示:

4.2创建PyTorch训练工程
本案例指导以MindStudio_5.0.RC2_win为例。
步骤一 新建工程
若首次登录MindStudio:单击New Project,如下图所示:
非首次登录MindStudio:在顶部菜单栏中选择File > New > Project…,如下图所示:

步骤二 创建PyTorch训练工程
在New Project窗口中,选择Ascend Training

然后输入训练工程名称

点击Change弹出setting界面

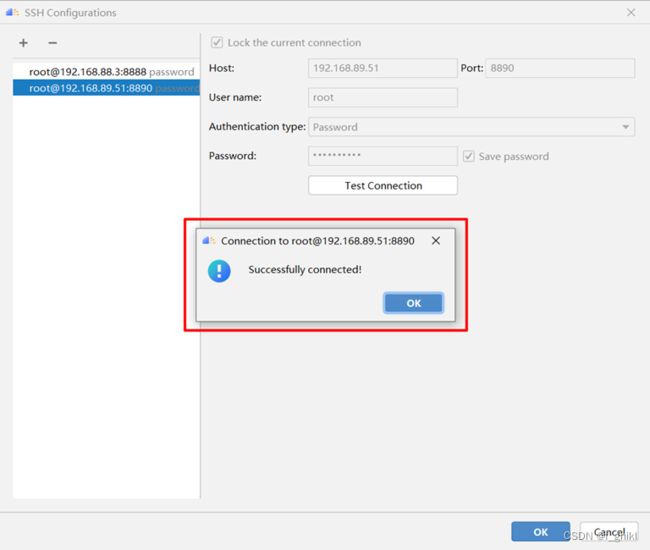
点击+号图标弹出SSH配置界面,输入linux服务器的ip、端口号、用户名与密码,如下图所示:

可以点击Test Connection进行服务器连接测试,如能按下图显示,则说明连接成功
配置Remote CANN location。该参数需填入ascend-toolkit在服务器上的路径地址。在这里,我们toolkit的路径为/usr/local/Ascend/ascend-toolkit/5.1.RC2。点击finish进行配置。初次配置时间稍长,请耐心等待。

配置完成后,会自动跳回创建昇腾训练工程界面,然后根据情况配置自己的工程存放路径
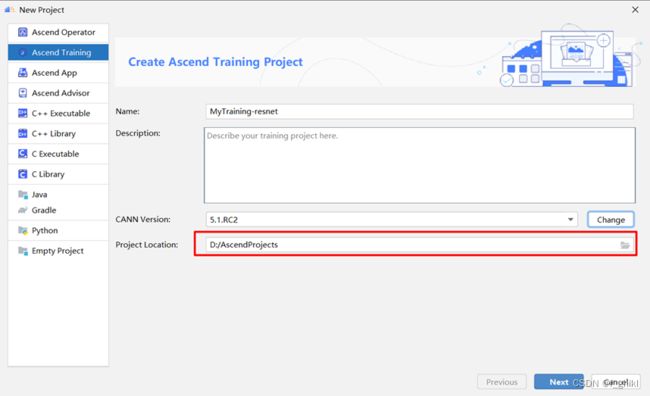
点击Next,选择Pytorch Project,然后点击finish
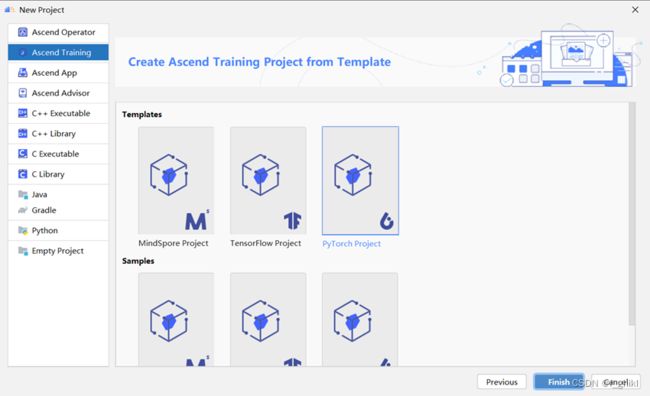
工程创建完成后如下图所示:
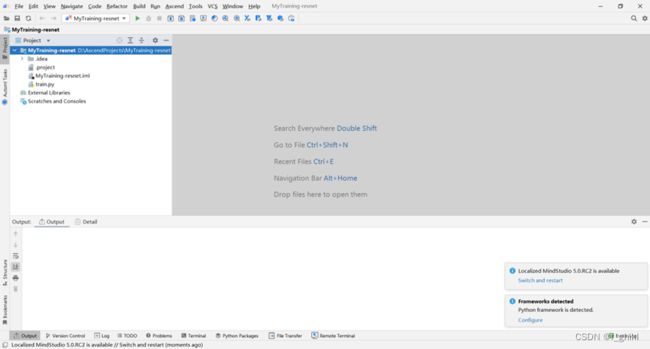
4.3 配置SDK
配置Module SDK,便于编码。右键点击项目名,选择Open Module Settings。因为我们的模型任务都是基于Python编程的,本机环境也是Python3.7.5,因此我们选择Python 3.7

4.4 执行迁移
迁移前需安装好如下必要的依赖包:
pip3 install pandas #pandas版本号需大于或等于1.2.4
pip3 install libcst
首先点击顶部菜单栏PyTorch GPU2Ascend按钮,出现如下界面:

- PyTorch Version:PyTorch版本。
- Input Path:待转换脚本文件的路径。
- Output Path:脚本转换后的输出路径。
- Replace Unsupported APIs:用功能相似的API替换不支持的API。
- Custom Rule:打开自定义转换规则。可选。
- Rule File:“Custom Rule”开启后此参数才会体现。单击文件夹图标选择用户自定义通用转换规则的json文件路径。该json文件主要包括函数参数修改、函数名称修改和模块名称修改三部分。必选。
- Distributed Rule:将GPU单卡脚本转换为NPU多卡脚本,此参数仅支持使用torch.utils.data.DataLoader方式加载数据的场景。可选。
- Main File:"Distributed Rule"开启后此参数才会体现。单击文件夹图标选择训练脚本的入口python文件。必选。
- Target Model: "Distributed Rule"开启后此参数才会体现。目标模型变量名,默认为“model”,可选。
- Amp Transplant:"PyTorch Version"选择1.5.0时此参数才会体现。开启此参数,可将torch.cuda.amp混合精度训练脚本转换为apex.amp混合精度训练脚本。可选。
- Target Model:"Amp Transplant"开启后此参数才会体现。输入模型名称。默认为“model”。可选。当同时使用“Distributed Rule”时,两个Target Model需保持一致。
参数设置完成后,单击Transplant,执行转换

若出现“Transplant success!”的回显信息,即转换成功,同时转换后的代码也会出现在相应路径。
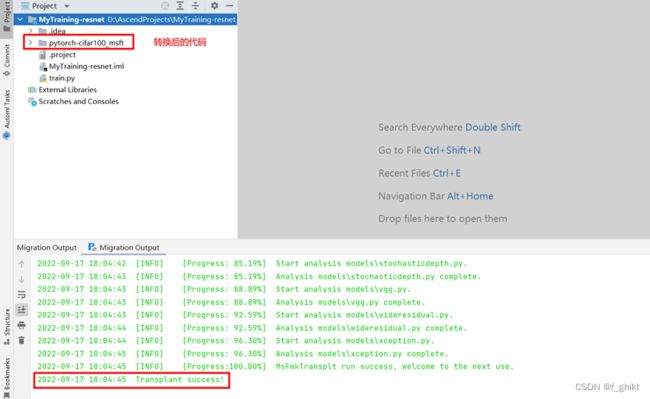
最后查看迁移报告,其对应位置如下图
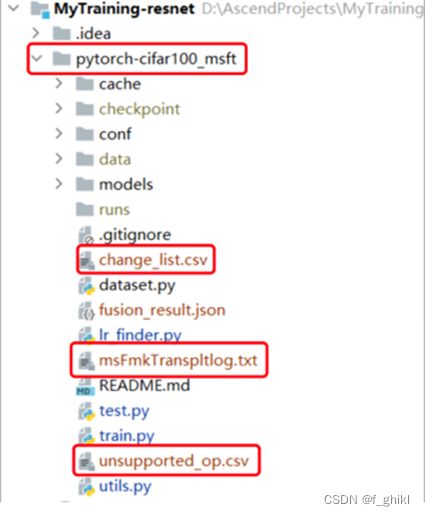
说明:脚本转换结果输出目录,默认为原始脚本路径。不开启单卡转多卡功能场景下,输出目录名为pytorch-cifar100_msft. - msFmkTranspltlog.txt:脚本转换过程日志文件,日志文件限制大小为1M,若超过限制将分多个文件进行存储,最多不会超过10个。
- unsupported_op.xlsx :不支持算子列表文件。
- change_list.csv :修改记录文件。
五、模型训练
5.1训练前准备
注意:训练前远端环境需安装好 PyTorch1.5.0 以及必要的依赖包
为保证后续训练能够顺利跑通,可先注释掉训练脚本(train.py)中引用到tensorboard的相关代码(以下行数仅为参考,请以实际所在行数为准)。
第23行

第48~52行
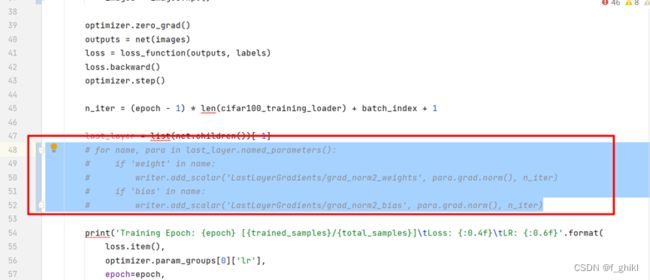
第63行

第71行

第113~115行
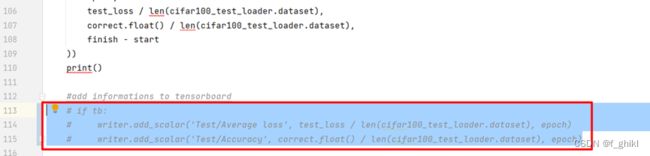
第171、172和176行
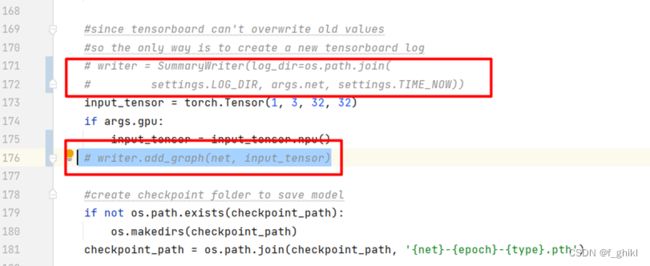
第228行

5.2开始训练
步骤1 运行参数配置
单击菜单栏“Run > Edit Configurations…”,会弹出运行参数配置界面。选择Remote Run,其中Deployment的配置已经在创建PyTorch训练工程的时候完成,因此会默认选择配置好的数据。Executable为训练工程中的执行入口文件,即启动训练的文件,注意不要选错,然后按要求配置好运行参数。其中参数设置如下图所示。最后单击“OK”即可。

其中,各参数功能如下:
- **Name:**工程名称,用户自行配置。名称必须以字母开头,数字或字母结尾,只能包含字母、数字、中划线和下划线,且长度不能超过64个字符。
- **Executable:**训练工程中的执行入口文件。
- **Run Mode:**运行环境选择。选择“Remote Run”表示远程运行,“Local Run”为本地运行,默认为“Remote Run”。
- **SSH Connection:**远程训练服务器地址,在“File>Settings…>Tools>SSH Configurations”中配置。
- **Command Argument:**训练工程执行参数。
- **Environment Variables:**训练工程环境变量。
步骤2 执行训练
单击 ,执行训练。训练过程中如遇protobuf相关报错,可根据报错提示安装相应版本的protobuf。成功运行后会显示如下界面,表示正在在线下载数据集,下载进度会实时更新。

数据集下载完成后模型会进入训练阶段,正常训练过程如下图所示。检查训练过程是否正常,loss是否收敛。
步骤3 查看训练完成后生成的文件
运行成功后会生成模型训练后的pth格式的权重文件,其存放位置如下图:

另外由于数据集是模型训练时在线下载的,可以看到数据集存放路径如下

六、训练时可能遇到的问题
libhccl.so:cannot open shard object file…
如果遇到如图所示问题,应该考虑是否成功配置好linux服务器上的环境,特别是有没有按要求成功修改配置文件,具体操作见本指南第二节远端环境配置中修改配置文件部分。

七、从昇腾论坛获得更多支持
如果遇到其他上述步骤中未能出现的错误,欢迎大家到昇腾论坛(进入昇腾论坛_开发者论坛-华为云论坛 (huaweicloud.com),选择开发者选项,点击进入昇腾论坛或者昇腾)中提出自己的问题在这里有很多技术大拿可以解决你的问题。或者也可以访问昇腾博客,搜索他人的独到见解。