人体三维重建——参数化人体方法简述
三维人体形状指的是以三维网格形式表示的人体几何形状模型。按照[1]中的分类方式,可以将三维人体形状重建粗略的分为参数化方法与非参数化方法。本次先介绍参数化方法。
参数化人体形状重建方法依赖于某个基于统计得到的人体参数化模型,仅需一组低维向量(即人体参数)即可描述人体形状。目前常见的参数化人体模型如SCAPE[2]、SMPL[3]、SMPL-X[4]等。
以SCAPE为例,它定义了两个独立的低维参数空间:人体体型(Shape)空间与人体姿态(Pose)空间。给定空间下的一组人体体型参数与人体姿态参数,即可直接合成一个人体形状。其中人体体型空间是通过对相同姿态、不同体型的人体数据库进行PCA(Principal Component Analysis,主成分分析)降维得到的子空间进行表示,体型参数则是该子空间中各个基的系数。图1(a)显示SCAPE体型基上的参数变化影响人体体型变化。SCAPE的姿态参数则以17个人体部分相对于标准模板人体相应部分的旋转表示。

图1(a) 经典人体参数化模型-SCAPE
随着SCAPE模型的成功,一些研究者在其基础上不断改进,提出了各种升级版本,较为知名的如Blend Scape[5],Breath Scape[6],S-Scape[7]等等。但是SCAPE模型的变形依赖于三角形面片的旋转变形,而不是以动画软件中常用的顶点变形方法(如骨骼蒙皮)进行变形,因此SCAPE生成的人体几何模型难以在现有的动画软件(如Maya, Blender等)直接使用。
最近,德国马克思-普朗克研究所开源了一个基于顶点变形的人体参数化模型SMPL[3]。SMPL模型同样由人体体型参数与人体姿态参数控制变形。其体型参数与SCAPE的体型参数相同,都以PCA提取出的体型变形基的参数进行表示。而姿态参数则是以人体的全局旋转以及23个关节的关节角旋转表示,并通过LBS(Linear Blend Skinning,线性混合蒙皮)进行人体姿态变形。SMPL的人体生成如图1(b)所示。
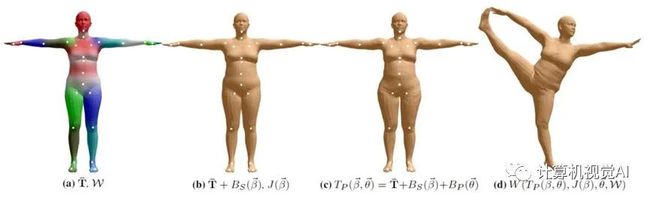
图1(b) 经典人体参数化模型-SMPL人体形变示意
传统的参数化人体重建方法通常利用特殊的设备获得人体的稠密三维点云数据或者深度数据,然后通过点云配准、模板变形等方式拟合SCAPE参数,进而重建出三维人体形状。
近年来,许多研究者利用Kinect深度相机捕获的人体深度数据以及SCAPE模型重建三维人体形状。Zhang等人[8]通过单个Kinect相机采集中间转动人体的多视图局部点云数据,并进行配准,然后采用类似SCAPE构建人体的方法对多个视图的点云进行拟合。
Weiss等人[9]也采用单个Kinect相机,不同于转动人体来获得多视图局部点云,他们捕获单人在Kinect前移动的多个单目深度图,通过最小化SCAPE人体模型的轮廓重投影与深度图轮廓之间的配准误差进行优化求解,如图2所示。但是该方法的求解过程非常耗时(重建一个人体需超过1小时)。
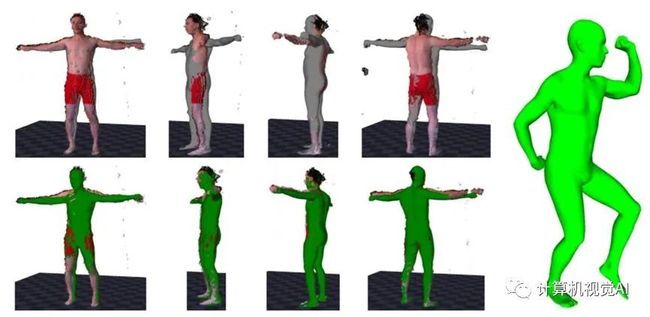
图2 Weiss等人的工作
Zhao等人[10]也提出了基于单个Kinect的参数化人体重建方法。他们首先利用Kinect拍摄人体正面和背面两张深度图,随后分别利用这两张深度图重建人体的半身网格,最后将其缝合在一起。上述方法的人体重建结果依赖于Kinect采集的深度图质量。但是由于Kinect的硬件限制,采集得到的深度图往往含有较大的噪声,严重影响重建质量。
此外,其它一些工作并不依赖于特殊设备捕获的稠密三维点云或者深度数据作为重建输入,而采用诸如人体二维关节点坐标[12,14]、人体轮廓[11,15,16]、人体描述参数[17–21]等其它数据形式来约束参数化人体几何形状重建。
Guan等人[12]依靠手动标注的人体二维关节点位置以及GrabCut[22]自动分割的人体轮廓,通过SFS(shape from shading,明暗恢复形状)的方式最小化渲染图与人体轮廓的配准误差来优化SCAPE参数,如图3所示。
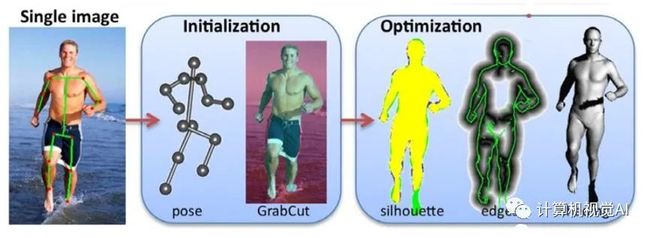
图3 Guan 等人 [12] 的工作
SMPLify[14]则引入基于卷积神经网络的人体二维姿态估计模型,他们通过最小化合成人体三维姿态与检测得到的二维关节点的重投影配准误差来优化SMPL参数(包括体型与姿态参数),同时加入人体穿透约束来降低从二维提升到三维的歧义性。但是该方法中并未对人体体型进行约束,而且容易陷入到局部最优解导致重建失败。
Lassner等人[23]在SMPLify的基础上,加入更加多的人体标记点约束(91个标记点),得到了更加准确的姿态重建结果。同时他们提出使用随机森林(RandomForest)模型学习人体轮廓到SMPL体型参数的映射关系。但是他们预测的人体轮廓质量较差,严重影响体型的预测结果。
近年来,基于深度学习的参数化人体形状重建方法开始变得流行[24]。Dibra等人[11]是最早利用CNN(Convolutionalneuralnetwork,卷积神经网络)来估计人体体型参数,他们直接将站立姿态人体的特定视角掩码作为卷积神经网络输入,直接回归SCAPE的体型参数。相比于人工设计特征,CNN能够自动提取体型特征,得到了比较准确的体型预测结果。如图4所示。
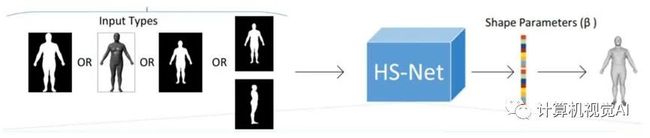
图4 Dibra 等人 [11] 的工作
随后,Dibra等人[25]又进一步提高了体型预测精度。他们首先学习了一个描述固定姿态下不同视角相同体型的特征隐空间,然后学习从该隐空间到体型参数的回归模型。该方法对于其它视角的人体掩码图像也可以预测得到可靠的体型参数。单一视图的人体掩码图像往往会缺失部分体型信息,比如男性的啤酒肚,在正面的掩码图像上无法显示该特征。
为了解决该问题,Ji等人[16]设计了一个新颖的双流网络结构,同时将正面与侧面的人体掩码作为输入来预测SCAPE形状参数。
不仅仅预测人体体型,许多研究者利用深度学习方法直接从图像[13,26–28]、视频[29,30]中估计人体体型与姿态。
HMR[26]将人体关节点的重投影配准误差加入到损失函数中,用于监督SMPL的姿态参数与体型参数。HMR借鉴了生成对抗网络(Generative Adversarial Network,GAN)[31]的思想,在损失函数中加入了一个判别器,用于监督预测人体参数的合法性。但是该方法并未有效对人体体型进行有效监督,导致预测的人体更加接近于平均身材,同时人体姿态也与输入图像中的人体相差较大。
Pavlakos等人[28]提出将姿态参数与体型参数解耦成两个子问题进行预测,分别利用预测得到的二维关节点热图和人体轮廓来分别回归姿态参数和体型参数。
最近,Xu等人[13]创新地在损失函数中加入人体网格顶点的稠密重投影误差。他们将Densepose[32]预测得到的IUV图(表示稠密网格顶点与图像像素的对应关系)作为输入,回归得到的人体网格,然后通过微分渲染器(Differential Renderer)渲染得到预测IUV图,并与输入IUV图之间计算配准误差。该方法在姿态和体型上都得到了更加准确的重建结果。如图5所示。

图5 Xu等人 [13]的工作
下期将介绍三维人体重建的非参数方法、SMPL人体参数化模型的详细论述。喜欢的小伙伴们可以点赞与收藏噢。
参考文献
【1】YE M, YANG R. Real-time simultaneouspose and shape estimation for articulated objects using a single depthcamera[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2014: 2345-2352.
【2】ANGUELOV D, SRINIVASAN P, KOLLER D, etal. SCAPE: Shape completion and animation of people[J]. ACM Trans. Graph.,2005, 24(3):408-416.
【3】LOPER M, MAHMOOD N, ROMERO J, et al.Smpl: A skinned multi-person linear model [J]. ACM transactions on graphics(TOG), 2015, 34(6):248.
【4】PAVLAKOS G, CHOUTAS V, GHORBANI N, etal. Expressive body capture: 3d hands, face, and body from a singleimage[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2019: 10975-10985.
【5】HIRSHBERG D A, LOPER M, RACHLIN E, etal. Coregistration: Simultaneous alignment and modeling of articulated 3dshape[C]//European conference on computer vision. Springer, 2012: 242-255.
【6】TSOLI A, MAHMOODN, BLACKM J. Breathinglife into shape: Capturing, modeling and animating 3d human breathing[J]. ACMTransactions on graphics (TOG), 2014, 33(4):1-11.
【7】JAIN A, THORMÄHLEN T, SEIDEL H P, etal. Moviereshape: Tracking and reshaping of humans in videos[J]. ACMTransactions on Graphics (TOG), 2010, 29(6):1-10.
【8】ZHANG Q, FU B, YE M, et al. Qualitydynamic human body modeling using a single lowcost depth camera[C]//Proceedingsof the IEEE Conference on Computer Vision and Pattern Recognition. 2014:676-683.
【9】WEISS A, HIRSHBERG D, BLACKM J. Home 3dbody scans from noisy image and range data[C]//2011 International Conference onComputer Vision. IEEE, 2011: 1951-1958.
【10】ZHAO T, LI S, NGAN K N, et al. 3-dreconstruction of human body shape from a single commodity depth camera[J].IEEE Transactions on Multimedia, 2018, 21(1):114-123.
【11】DIBRA E, JAIN H, OZTIRELI C, et al.Hs-nets: Estimating human body shape from silhouettes with convolutional neuralnetworks[C]//2016 fourth international conference on 3D vision (3DV). IEEE,2016: 108-117.
【12】GUAN P, WEISS A, BALAN A O, et al.Estimating human shape and pose from a single image[C]//IEEE InternationalConference on Computer Vision. 2009: 1381-1388.
【13】XUY, ZHUS C,TUNGT. Denserac: Joint 3dpose and shape estimation by dense render-and compare[C]//Proceedings of theIEEE International Conference on Computer Vision. 2019:7760 - 7770.
【14】BOGO F, KANAZAWA A, LASSNER C, et al.Keep it SMPL: Automatic estimation of 3D human pose and shape from a singleimage[C]//European Conference on Computer Vision. 2016: 561-578.
【15】SIGAL L, BALAN A, BLACK M. Combineddiscriminative and generative articulated pose and non-rigid shapeestimation[J]. Advances in neural information processing systems, 2007,20:1337-1344.
【16】JI Z, QI X, WANG Y, et al.Shape-from-mask: A deep learning based human body shape reconstruction frombinary mask images[J]. arXiv preprint arXiv:1806.08485, 2018.
【17】STREUBER S, QUIROS-RAMIREZ M A, HILL MQ, et al. Body talk: Crowdshaping realistic 3d avatars with words[J]. ACMTransactions on Graphics (TOG), 2016, 35(4):1-14.
【18】SEO H, MAGNENAT-THALMANN N. Anexample-based approach to human body manipulation[J]. Graphical Models, 2004,66(1):1-23.
【19】WUHRER S, SHU C. Estimating 3d humanshapes from measurements[J]. Machine vision and applications, 2013,24(6):1133-1147.
【20】ALLEN B, CURLESS B, POPOVIĆ Z. The space of human body shapes: reconstruction andparameterization from range scans[J]. ACM transactions on graphics (TOG), 2003,22 (3):587-594.
【21】谢昊洋. 高精度三维人体重建及其在虚拟试衣中的应用[D]. 东华大学, 2020.
【22】ROTHER C, KOLMOGOROVV, BLAKE A. ” grabcut” interactive foreground extraction using iterated graphcuts[J]. ACM transactions on graphics (TOG), 2004, 23(3):309-314.
【23】LASSNER C, ROMERO J, KIEFEL M, et al.Unite the people: Closing the loop between 3D and 2D humanrepresentations[C]//IEEE Conf. on Computer Vision and Pattern Recognition(CVPR). 2017: 6050-6059.
【24】许豪灿, 李基拓, 陆国栋. 由 LeNet-5 从单张着装图像重建三维人体[J]. 浙江大学学报, 2021, 55(1):153-161.
【25】DIBRA E, JAIN H, OZTIRELI C, et al.Human shape from silhouettes using generative hks descriptors and cross-modalneural networks[C]//Proceedings of the IEEE conference on computer vision andpattern recognition. 2017: 4826-4836.
【26】KANAZAWAA, BLACKM J, JACOBSDW, et al.End-to-end recovery ofhuman shape and pose[C]//IEEE Conference on ComputerVision and Pattern Recognition. 2018: 7122-7131.
【27】Joo H, Neverova N, Vedaldi A. Exemplarfine-tuning for 3d human pose fitting towards inthe-wild 3d human poseestimation[J]. arXiv preprint arXiv:2004.03686, 2020.
【28】ZIMMERMANN C, BROX T. Learning toestimate 3D hand pose from single RGB images [C]//IEEE International Conferenceon Computer Vision. 2017: 4903-4911.
【29】KOCABAS M,ATHANASIOUN, BLACKM J. Vibe:Video inference for human body pose and shape estimation[C]//Proceedings of theIEEE/CVF Conference on Computer Vision and Pattern Recognition. 2020:5253-5263.
【30】KANAZAWA A, ZHANG J Y, FELSEN P, etal. Learning 3d human dynamics from video [C]//Proceedings of the IEEE/CVFConference on Computer Vision and Pattern Recognition. 2019: 5614-5623.
【31】GOODFELLOWI J, POUGET-ABADIE J,MIRZAM, et al. Generative adversarial networks [J]. arXiv preprintarXiv:1406.2661, 2014.
【32】GÜLER R A, NEVEROVA N, KOKKINOS I.Densepose: Dense human pose estimation in the wild[C]//IEEE Conference onComputer Vision and Pattern Recognition. 2018: 7297-7306.
作者:计算机视觉AI
|关于深延科技|
深延科技成立于2018年,是深兰科技(DeepBlue)旗下的子公司,以“人工智能赋能企业与行业”为使命,助力合作伙伴降低成本、提升效率并挖掘更多商业机会,进一步开拓市场,服务民生。公司推出四款平台产品——深延智能数据标注平台、深延AI开发平台、深延自动化机器学习平台、深延AI开放平台,涵盖从数据标注及处理,到模型构建,再到行业应用和解决方案的全流程服务,一站式助力企业“AI”化。