Deconfounded Visual Grounding
**本文内容仅代表个人理解,如有错误,欢迎指正**
1. Background knowledge
* 这篇论文重度包含因果推理的相关知识,本文可能会粗略带过,感兴趣的可以去看看原论文,有比较详细的解释说明。
Q1: 什么是confounder?
- confounder在因果推理当中有确切的定义,即混杂因子。
举个例子,在图一中,“抽烟”容易导致“黄手指”与“肺癌”,因为“抽烟”这个共因,让“黄手指”和“肺癌”之间产生了关联,即手指黄的人很多都容易患肺癌,但不能够推出“黄手指”会导致“肺癌”,因为它们之间没有因果关系。那么,“抽烟”就是“黄手指”和“肺癌”的混杂因子,因为其让“黄手指”和“肺癌”出现了一种“伪相关”(Bias)。

图一
另一种更复杂的情况如图二,即混杂因子造成的伪相关关系和真正的因果关系混合在一起,造成“混杂”(confounding)的情形。个人理解,G是R与L、X与L的混杂因子,其代表了训练数据集上的数据分布,在进行训练的时候,能够影响R、X和L,从而产生R与L、X与L的伪相关。另一方面,R、X是L的因,本身也存在因果关系,从而产生了“混杂”的情形。

图二
因果推理的一大目标就是尽量消除混杂带来的偏倚(Bias),找出真正的因果关系。
在这篇论文中,其目的是使得模型学到R与L之间的因果关系,从而在无偏倚的情况下,习得更好的特征表示。
Q2: 什么是confounding bias between language and location in the visual grounding pipeline?
- 论文作者认为,模型在grounding的过程中,更依赖于query来框出target的location,而非去做visual reasoning。举个例子来说明Confounding bias,比如说在训练数据集中,包含“sheep”这个词的query,其target的location大多都在图像正中央,那么模型在做测试时,如果query中有包含“sheep”这个词,那么其框出的location有比较大的概率出现在图像正中央。
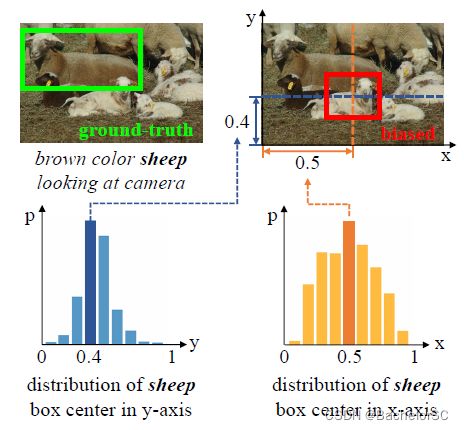
图三
图四
这有点类似于VQA中的强文本先验,举个例子,即如果在VQA训练数据集中,大多数问个数的问题的答案都是2,那么测试时给定一个问题(例如,图像中有几个苹果?How many apples in this picture?),模型有一定倾向不去对图像进行理解,而是直接回答2。
2. Points
1. 将Visual grounding pipeline转为因果图,从而分析G、R、X与L之间的关系,找到混杂因子。
2. 提出Referring Expression Deconfounder(RED)来减缓存在于Visual grounding pipeline中的confounding bias。
3. Main Components
主要工作分为两步:
@@@这部分看不是太懂,以下只是猜想
1. 训练一个生成模型M,在文中以自编码器来实现。其以Query R为输入,输出R',再针对(R, R')利用重构损失对生成模型M进行训练。训练这个生成模型M的原因,其实是为了做后门调整(Backdoor adjustment),即利用生成模型M学得的概率分布G'代替数据集的原始分布G,就是为了阻断R与L之间的伪相关关系,从而寻找R与L之间的因果关系。
- 在图五中灰色部分可以看到,在encode和decode中间有pink bar,应该是隐层空间中的高维向量。与该方法BERT提取出的Query feature一样,每一个bar都会biased location,表示该feature对location的一个偏倚。那么在训练完生成模型M之后,将每一个sample的pink bar都取出来,进行一个聚类,得到G'中的主要元素(主要有哪些偏倚的location),形成一个Dictionary。
2. 训练一个无偏倚的Grounding model。 其输入是Image的特征与Deconfounded之后的Query特征,其他部分与普通的Visual Grounding model大同小异。这个Deconfounded的Query feature其实是BERT提取出来的Query特征(Blue bar)与Dictionary中的所有偏倚location进行一个attention,从而得到purple bar(没有偏倚的Query feature,即location可以出现在任何地方,而不是像blue bar那样只有一个biased location)。

图五
4. Experimental Results
*从上文可以知道,RED其实就像一个插件,即插即用,可以放在众多模型上去验证其有效性。该论文主要在四个模型上验证其有效性,实验结果如下图。

图六
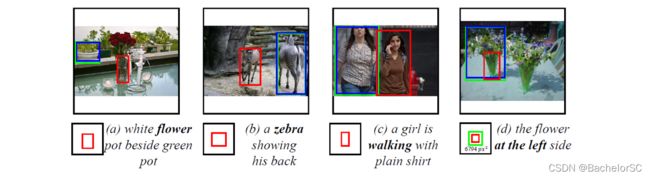
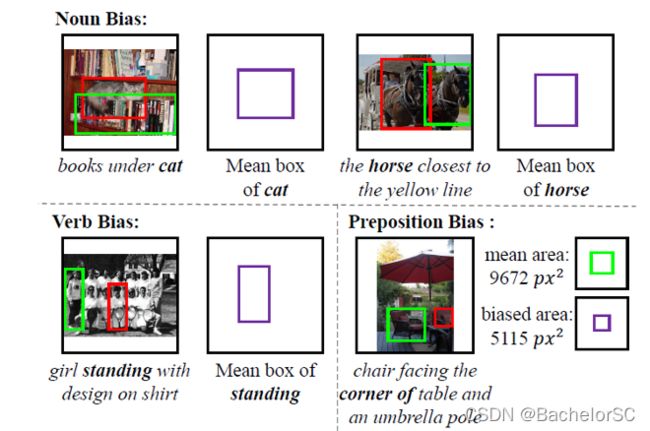
图七
** 文中因果推理相关部分主要参考知乎用户@望止洋 的文章,受益匪浅。