CPT:刷爆少样本REC任务!清华刘知远团队提出跨模态预训练Prompt Tuning
关注公众号,发现CV技术之美
本文分享论文『CPT: Colorful Prompt Tuning for Pre-trained Vision-Language Models』,由清华刘知远团队提出跨模态预训练 Prompt Tuning(CPT)刷爆少样本REC任务!
详细信息如下:

论文链接:https://arxiv.org/abs/2109.11797
项目链接:未开源
导言:
预训练的视觉语言模型(VL-PTM)在Visual Ground任务上表现出了良好的能力,促进了各种跨模态任务的完成。然而,作者注意到,模型预训练和微调的目标之间存在着巨大的差距,因此需要大量的标记数据来促进VL-PTM对下游任务的视觉ground能力。
为了应对这一挑战,作者提出了跨模态提示调优 (CPT,Cross-modal Prompt Tuning),这是一种用于微调VL-PTM的新范例,它将visual grounding任务重新定义为图像和文本中基于颜色标记的填空问题,最大限度地缩小了预训练和微调的任务差距。
通过这种方式,提示调优(Prompt Tuning)方法可以实现VL-PTM的强大的少样本甚至零样本的visual grounding能力。实验结果表明,提示调优的VL-PTM在很大程度上优于finetune方法。
01
Motivation
Visual Grounding是很多视觉语言任务的基础,该任务旨在通过给定的句子来定位图像中的区域。最近,预训练的视觉语言模型(VL-PTM)在Visual Grounding方面显示出了良好的性能。通常,通用跨模态表示首先以自监督的方式对大规模图像字幕数据进行预训练,然后进行微调以适应下游任务。VL-PTM的这种先预训练然后微调的范式极大地推动了许多跨模态任务的SOTA性能。

尽管取得了成功,但作者注意到VL-PTM的预训练和微调的任务目标之间存在明显的差距。如上图所示,在预训练期间,大多数VL-PTM都是基于屏蔽语言建模(MLM)目标进行优化的,试图从跨模态上下文中恢复被mask掉的token。
然而,在微调期间,下游任务需要将完整的token分类为语义标签,其中通常引入任务特定的参数。这一差距阻碍了VL-PTM对下游任务的有效适应。因此,需要大量的标记数据来激发VL-PTM对下游任务的Visual Grounding能力。

在这项工作中,受自然语言处理中预训练的语言模型最新进展的启发,作者提出了了跨模态提示调优 (CPT,Cross-modal Prompt Tuning),用于微调VL-PTM。
该方法的关键是,通过在图像和文本中添加基于颜色的共指标记(也就是图像和文本基于颜色的对应标记),Visual Grounding可以被表述为一个填空问题,最大限度地减轻预训练和微调之间的差距。
如上图所示,要将图像数据和自然语言表达式进行ground,CPT需要由两个组件组成:
视觉子提示(visual sub-prompt):用颜色块唯一地标记图像区域,
文本子提示(textual sub-prompt):将查询文本放入基于颜色的查询模板中。
然后,可以通过从查询模板中的mask token恢复对应的颜色文本来实现对目标图像区域的显式ground。通过减少和预训练之间的差距,CPT可以实现VL-PTM强大的少样本甚至零样本的visual grounding性能。
02
方法
2.1. Preliminary
Visual Grounding可以看做是指向性表达理解 (REC)任务。给定图像和包含表达式的查询文本,REC旨在定位与相对应的中的目标区域。REC的常见做法是首先通过目标检测器检测一组区域proposal ,然后对proposal进行分类或排序以选择目标区域。
具体而言,视觉和文本输入首先转换为一系列输入token:
其中 是的文本token,、 和 是特殊的token。然后将token输入到预训练的Transformer,以产生隐藏表示
。最后,通过分类或排名损失对目标区域的隐藏表示进行优化,这个过程引入了新的任务特定参数。因此,微调VL-PTM需要大量的标记样本来激发模型visual grounding的能力。
2.2. Overview
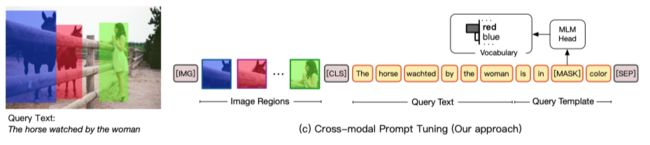
visual grounding的关键是在图像区域和文本表达之间建立细粒度的联系。因此,一个好的跨模态提示调优框架应该充分利用来自图像和文本的共同参考信号,并最大限度地减少预训练和微调之间的差距。如上图所示,作者将visual grounding定义为了一个填空问题。
具体而言,CPT框架由两部分组成:(1)一个视觉子提示,用色块唯一标记图像区域;(2)一个文本子提示,将查询文本放入基于颜色的查询模板中。配备CPT后,VL-PTM可以直接通过用目标图像区域颜色的文本填空,实现ground查询文本的目标,这个任务与预训练任务相同。
2.3. Visual sub-prompt
给定图像及其区域proposal,视觉子提示旨在用visual makers来唯一地标记图像区域。作者发现,在目标检测任务中,彩色边框被广泛用于标记图像中的目标,以便可视化。受此启发,作者通过一组颜色关联图像区域和文本表达式,其中每个颜色通过其视觉外观(比如:RGB (255,0,0)和彩色文本 (例如,red)来表示。
然后用一个不同的颜色标记图像中的每个区域proposal ,从而产生一组颜色-图像proposal ,其中 表示视觉子提示。在实验中,作者发现用实心块为目标着色比边界框产生更好的结果,因为纯色对象在现实世界的图像中更常见 (例如,红色衬衫和蓝色汽车)。由于视觉子提示被添加到原始图像中,因此它不会更改VL-PTM的结构或参数。
2.4. Textual sub-prompt
文本子提示旨在提示VL-PTM建立查询文本与视觉子提示标记的图像区域之间的连接。具体而言,查询文本(例如,“the horse watched by the woman”)使用模板转换为填空查询,如下所示:
![]()
通过这种方式,VL-PTM被提示决定哪个区域的颜色更适合填充在mask中(例如,红色或黄色),如下所示:
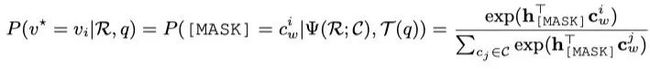
其中,是目标区域,是预训练MLM head中的embedding。注意,该过程不引入任何新参数,并且还减小了预训练和微调之间的差距,因此提高了微调VL-PTM的效率。
2.5. Training and inference
配备CPT后,VL-PTMs可以在没有任何标记数据的情况下执行零样本visual grounding,因为VL-PTMs在预训练中已经很好地学习了颜色的跨模态表示及其与其他概念(例如,对象、属性和关系)的组合。当有少量或全部已标记的实例可用时,也可以基于目标函数进一步对CPT进行微调,其中是训练集。
尽管通过基于颜色的提示来关联图像和文本很有吸引力,但其设计中的两个关键挑战:
如何确定颜色集C的配置 ;
如何处理有限预训练颜色的图像区域的数量。
Cross-modal Prompt Search
NLP 中提示调优(prompt tuning)方面的研究表明,提示设置(例如,文本模板)对性能有显著的影响。在这项工作中,作者对搜索跨模态提示配置 (即颜色集) 进行了研究。直观地说,应该由VL-PTM最敏感的颜色组成。
为了获得颜色,一种直观的方法是采用预训练文本中最频繁的颜色文本作为,并且将其标准RGB作为(例如,,,,)。但是,该解决方案是次优的,因为它在不考虑其视觉外观的情况下确定了颜色文本,并且现实世界图像中颜色的视觉外观通常与标准RGB不同。
在本文的跨模态提示搜索中,作者首先确定所有彩色文本的候选集。对于RGB空间中的每个可能颜色,作者将纯色块与文本子提示“[CLS] a photo in [MASK] color. [SEP]”进行拼接之后输入到VL-PTM中,即可获得所有颜色的解码分数。较大的解码分数表示和之间的相关性较高。
然后,作者删除了在任何颜色视觉外观中都不是排名靠前的颜色文本。最后,对于每个剩余的颜色文本,其视觉外观由确定。在实验中,作者发现该颜色配置的性能明显优于直观的颜色配置。
Image Region Batching
在Visual Grounding中,图像中区域proposal的数量通常超过的大小。此外,作者观察到严重重叠的色块会阻碍Visual Grounding。因此,作者将图像区域划分为多个Batch,其中每个Batch包含少量中等重叠的图像区域,并分别用视觉子提示标记每个Batch。为了处理不包含目标区域的Batch,作者在解码词汇中引入一个新的候选文本,表示Batch中没有目标区域。
03
实验
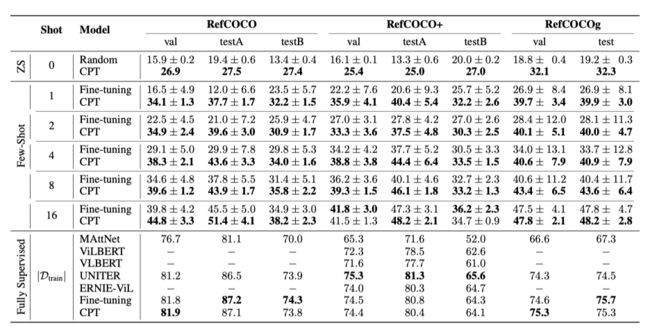
从上表中,可以看出,在少样本和零样本设置下,CPT的性能显著优于微调的结果,提升非常明显;在全部数据训练下,CPT的性能也是接近或者超过了以前的SOTA性能。
04
总结
在这项工作中,作者提出了VL-PTM的第一个跨模态提示调优(CPT)框架。实验结果证明了CPT在零样本和少样本的Visual Grounding任务上的有效性。然而,尽管它在Visual Grounding方面的性能很不错,但CPT有几个局限性:
颜色干扰 。CPT通过在图像和文本中添加基于颜色的提示,利用颜色来连接视觉和文本语义。但是,基于颜色的提示可能会受到原始图像和文本中颜色的干扰。
计算效率 。在实验中,为了最大限度地避免颜色干扰,并考虑到候选颜色的数量有限,作者采用了较小的图像区域batch。这意味着一个数据实例需要多次输入到模型中才能获得结果。
在这项工作中,作者以Visual Grounding为例,以证明CPT的有效性。但实际上,CPT可以适应其他视觉语言任务。比如Object detection、Predicate classification和Scene graph classification,方法如下图所示:

▊ 作者简介
研究领域:FightingCV公众号运营者,研究方向为多模态内容理解,专注于解决视觉模态和语言模态相结合的任务,促进Vision-Language模型的实地应用。
知乎/公众号:FightingCV

END
欢迎加入「视觉语言」交流群备注:VL
