国科大&港中文提出带视觉语言验证和迭代推理的Visual Grounding框架,性能SOTA,代码已开源!(CVPR2022)...
关注公众号,发现CV技术之美
本文分享 CVPR 2022 的一篇论文『Improving features Visual Grounding with Visual-Linguistic Verification and Iterative Reasoning』,由国科大&港中文提出带视觉语言验证和迭代推理的Visual Grounding框架,性能SOTA,代码已开源!
详细信息如下:

论文链接:https://arxiv.org/abs/2205.00272
项目链接:https://github.com/yangli18/VLTVG
01
摘要
Visual grounding是一项定位自然语言表达所指示目标的任务。现有的方法将通用目标检测框架扩展到这个问题上。他们将Visual grounding建立在来自预先生成的proposals或anchors,并将这些特征与文本嵌入融合,以定位文本提到的目标。然而,从这些阶段预定义的位置建模视觉特征可能无法充分利用文本查询中的视觉交叉模态文本和属性信息,这限制了解码器的性能。
在本文中,作者提出了一个基于Transformer的框架,通过建立文本条件下的辨别特征和执行多阶段跨模态推理来实现精确的Visual grounding。具体而言,作者开发了一个视觉语言验证模块,将视觉特征集中在与文本描述相关的区域,同时抑制不相关的区域。作者还设计了一种语言引导的特征编码器来聚合目标对象的视觉上下文,以提高对象的区分性。
为了从编码后的视觉特征中提取目标,作者进一步提出了一种多级交叉模态解码器,用于迭代推测图像和文本之间的相关性,以实现精确的目标定位。在五个广泛使用的数据集上进行的大量实验验证了本文提出的组件的有效性,并展示了SOTA的性能。
02
Motivation
Visual grounding的目的是通过自然语言的表达来定位图像中所指的对象或区域。这项任务因其在弥合视觉感知和语言表达之间的差距方面的巨大潜力而受到越来越多的关注。这种技术的发展对于其他多模态推理任务也非常重要。在Visual grounding中,所指对象通常由语言表达中的一条或多条信息指定。这些信息可能包括对象类别、外观属性和视觉关系上下文等。因此,为了避免推理中的歧义,充分利用文本信息并为Visual grounding建模有区别的视觉特征至关重要。
现有的方法,无论是两阶段的还是一阶段的,都将Visual grounding视为检测到的候选区域的排序问题。两阶段方法通常首先检测一组对象proposal,然后将其与语言查询匹配,以检索排名靠前的proposal。
一阶段方法将文本嵌入与图像特征直接融合,生成密集检测,从中选择可信度最高的检测。因为这些方法基于一般的目标检测器,其推理程序依赖于所有可能候选区域的预测,这使得性能受到预定方案质量或预定anchor配置的限制。此外,它们用区域特征(对应于预测的方案)或点特征(密集anchor框)来表示候选对象,以与文本嵌入匹配或融合。
对于捕捉语言描述中提到的详细视觉概念或上下文,此类特征表示可能不太灵活。这种不灵活性可能会增加识别目标对象的难度。虽然有些方法利用模块化注意力、图形和树结构来更好地建模视觉和语言之间的关系,但它们的处理pipeline很复杂,性能仍然受到对象proposal输入的限制。
最近,transformer在自然语言处理和计算机视觉领域的蓬勃发展显示了其在语言和视觉领域的强大建模能力。受此启发,TransVG提出了一种基于Transformer的Visual grounding框架。它们以视觉和语言特征token为输入,堆叠一组Transformer编码器层进行跨模态融合,并直接预测目标位置。
尽管它很有效,但共享的transformer编码器层负责多项任务,包括编码视觉语言特征、识别对象实例和获取最终位置,这可能会增加学习难度,并且只能获得折衷的结果。使用特征融合机制检索目标对象的视觉特征也不太容易。因此,作者提出为准确的Visual grounding建立一个更专门的框架。

在这项工作中,作者提出了一个基于Transformer的Visual grounding框架,该框架直接检索目标对象的特征表示以进行定位。为此,如上图所示,模型首先通过视觉语言验证和上下文聚合建立区分性特征表示,然后通过多阶段推理识别对象。具体而言,视觉语言验证模块将视觉特征与文本嵌入的语义概念进行比较,重点关注与语言表达相关的区域。同时,语言引导的上下文编码器收集上下文特征,以使目标对象的视觉特征更易于区分。基于这些增强的特性,作者提出了一种多级跨模态解码器,它可以迭代地比较和考虑视觉和语言信息。这使模型能够逐步获得参考对象的更好表示,从而更准确地确定其位置。
本文的贡献有三个方面:
为了建立Visual grounding的区别特征,作者提出了一个视觉语言验证模块,将编码特征集中在与语言表示相关的区域上。并进一步设计了一种语言引导的上下文编码器,用于聚合重要的视觉上下文,以便更好地识别对象。
为了更准确地检索所引用对象的特征表示,作者提出了一种多级跨模态解码器,该解码器迭代查询和考虑视觉和语言信息,以减少推理过程中的歧义。
作者在RefCOCO、RefCOCO+、RefCOCOg、ReferItGame和Flickr30k Entities上对本文的方法进行了基准测试。与之前最先进的方法相比,本文的方法表现出显著的性能改进。大量的实验和消融研究验证了本文提出的组件的有效性。
03
方法
在本节中,作者将介绍本文提出的visual grounding框架。首先介绍总体网络架构。然后,详细阐述了作者提出的视觉语言验证模块、语言引导的上下文编码器和多级跨模态解码器。最后,详细介绍了用于训练的损失函数。

3.1. The Overall Network
与以前基于排名的visual grounding方法不同,作者直接检索对象特征用于目标定位。如上图所示,给定图像和语言表达式,作者首先将它们输入到两个单独的分支中进行特征提取。对于图像,作者利用卷积神经网络(如ResNet50)和一组Transformer编码器层来生成二维视觉特征图。对于输入语言表达式,作者用BERT将其编码为一系列文本嵌入。
然后,基于这两种模态的特征,作者应用视觉语言验证模块和语言引导的上下文编码器来编码。视觉语言验证模块定义视觉特征,重点关注与参考表达相关的区域,而语言引导的上下文编码器收集信息性视觉上下文,以便于识别目标对象。最后,采用多级跨模态解码器对编码后的视觉和文本特征进行迭代分析,以更准确地检索目标表示,实现目标定位。
3.2. Visual-Linguistic Verification Module
输入图像首先由卷积网络编码,然后由后续Transformer编码器层编码为视觉特征图。该特征映射包含图像中对象实例的特征,但没有语言表达式所引用对象的先验知识。在没有任何先验知识的情况下检索引用对象的表示可能会被其他对象或区域分散注意力,导致定位结果不太准确。为了解决这个问题,作者提出了视觉语言验证模块来计算视觉和文本特征之间的细粒度相关性,并将特征集中在与文本描述中的语义相关的区域。
如上图(c)所示,视觉语言验证模块基于多头注意力。其中视觉特征图用作查询和文本嵌入作为键和值。通过多头注意,将为视觉特征图的每个视觉特征向量收集相关语义特征。将收集到的语义特征组织为语义特征图,与视觉特征图在空间上对齐。此后,作者将特征映射和投影到相同的语义空间(通过线性投影和L2归一化),获得和,并将其语义相关性计算为每个空间位置(x,y)的验证分数,如下所示:

其中α和σ是可学习的参数。验证分数为每个视觉特征与语言表达的语义相关性建模。因此,通过合理调整视觉特征和验证分数像素,可以为参考对象建立更显著的特征图:

视觉特征自然会抑制与文本表达式无关的区域,使得在后期更容易识别和定位引用对象。
3.3. Language-guided Context Encoder
除了在视觉和语言表达之间建立语义关联外,对视觉上下文(例如,交互关系和相对位置)进行建模对于区分参考目标对象与其他部分也至关重要。为此,作者提出了一种语言引导的上下文编码器,以在文本描述的指导下收集上下文特征。
如上图(d)所示,基于多头注意力模块(最左侧),输入视觉特征图作为查询,从文本嵌入中收集相关语义信息,生成特征图作为视觉特征的相应语言表示。基于,作者使用另一个多头注意模块对视觉特征进行语言引导的自注意,以编码所涉及的视觉上下文。具体而言,作者将和之和作为多头注意模块的查询和键,以计算视觉和语言表示中的特征相关性。对于多头注意模块中的每个注意头,作者定义从位置i到位置j的attention值:
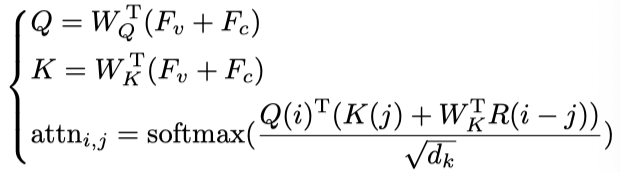
其中和是查询和键的线性投影权重,是投影通道维度,是正弦位置编码。这种语言引导的自注意使模型能够学习根据给定的文本描述为所指对象收集重要的上下文特征。多头注意模块将上下文特征表示的映射输出为。为了为目标对象建立更多的鉴别特征,作者将上下文特征与视觉特征基于视觉语言验证分数融合为:

然后,在最终的多级解码器中利用产生的鉴别特征表示进行目标识别和定位。
3.4. Multi-stage Cross-modal Decoder
作者利用已建立的视觉特征图和文本嵌入进行最终目标定位。为了减少推理过程中的歧义,作者提出了一种多级跨模态解码器,该解码器迭代地考虑视觉和语言信息,以将目标对象与其他部分区分开来,并检索相关特征进行对象定位。
上图(b)中展示了解码器的架构。解码器由N个阶段组成,每个阶段由相同的网络结构(具有非共享权重)构成,用于迭代跨模态推理。在第一阶段,作者使用可学习的目标查询作为目标对象的初始表示。该目标查询被输入解码器,以基于语言表达式提取视觉特征,并迭代地将其特征表示更新为 。上图(b)展示了每个解码器级的特征更新过程。
具体而言,在第i个阶段,目标查询被输入(作为查询)到第一个多头注意模块,以从文本嵌入中收集有关所指对象的信息性语义描述,生成语言表示。然后,在第二个多头注意模块中,作者使用该语言表示作为查询,计算其与先前建立的鉴别特征的相关性,然后从视觉特征图收集感兴趣的特征。以这种方式,收集的视觉特征根据中收集的语义描述生成引用对象。此后,作者使用此收集的特征将目标查询更新为:

其中LN(·)表示层归一化,FFN(·)是由两个线性投影层和ReLU激活函数组成的前馈网络。然后将更新后的目标查询输入到下一个解码器阶段,用于迭代跨模态推理和特征表示更新。
基于这种多级结构,每个阶段的目标查询能够聚焦于referring expression中的不同描述,从而可以收集到目标对象更完整、更可靠的特征。目标查询逐步与收集的特征相匹配,以形成目标对象的更精确表示。最后,作者在每个阶段的目标查询输出中添加一个带有ReLU激活函数的三层MLP来预测引用对象的边界框。对所有阶段的预测边界框进行同等监督,以便于多阶段解码器训练。
3.5. Training Loss
本文的训练过程比以前基于排名的方法更简洁、直接。由于本文的网络直接回归最终的边界框,避免了正/负样本分配,并且可以使用ground-truth框直接计算回归损失。设表示从阶段1到N的预测边界框,b表示ground-truth框。预测框和ground-truth框在所有阶段的损失为:

其中,和分别是GIoU损失和L1损失。和是平衡这两个损失的超参数。
04
实验

在上表中,作者报告了本文方法在RefCOCO、RefCOCO+和RefCOCOg数据集上与其他最先进方法的性能比较。本文的方法在三个数据集的所有split中都优于其他方法。值得注意的是,与先进的两阶段方法Ref NMS相比,本文的方法在RefCOCO、RefCOCO+、RefCOCOg上分别实现了高达4.45%、5.94%和5.49%的绝对提升。
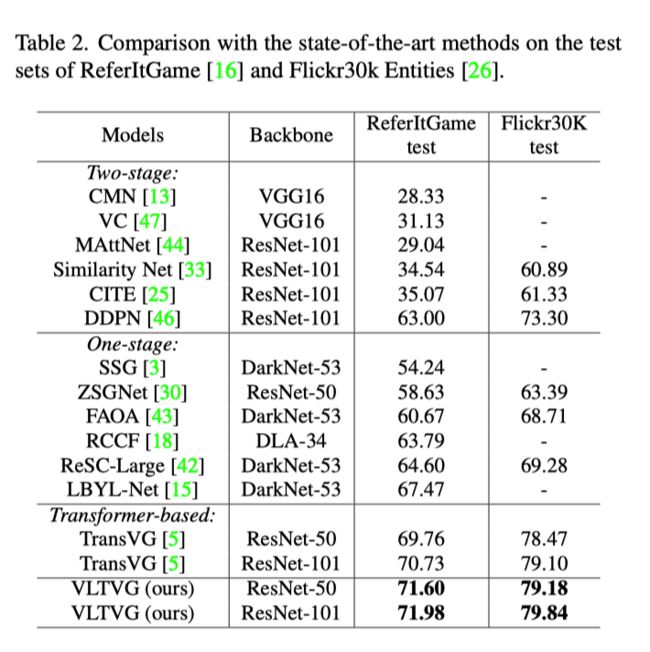
上表报告了本文的方法在ReferItGame和Flickr30k Entities的测试集上的性能。
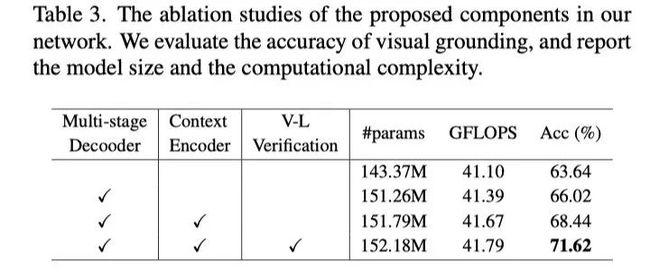
在上表中,作者对本文提出的组件进行了彻底的消融研究,以验证其有效性。可以看出,本文提出的模块对于提升Visual Grounding的性能都是有效的。

如上表所示,随着使用更多的解码器级,精度稳步提高,直到达到N=6附近67.57%的饱和点。这反映了多阶段推理对Visual Grounding的重要性,多阶段解码器查询语言信息并通过多轮收集视觉特征,从而更准确地识别和定位参考对象。

在本文的网络中,作者利用视觉语言验证模块和语言引导的上下文编码器来学习这两种模态的特征。为了进一步验证该方法的必要性和有效性,作者将该方法与上表中常见的基于Transformer的视觉语言特征学习设计进行了比较。

在上图中,作者将生成的验证分数、多级解码器的注意图以及不同输入的最终定位结果可视化。可以观察到,与语言表达中的描述相关的对象或区域的验证分数通常较高。

在上图中,给定一个语言表达,作者可视化了语言引导上下文编码器的attention map。
05
总结
作者提出了一个基于Transformer的Visual Grounding框架,该框架建立了区分特征并执行迭代交叉模态推理以实现精确的目标定位。本文的视觉语言验证模块将视觉特征编码集中在与文本描述相关的区域,而语言引导的上下文编码器则收集信息丰富的视觉上下文,以提高目标的独特性。
此外,多级跨模态解码器反复考虑视觉和语言信息以进行定位。在公共数据集上的大量实验显示了本文方法的SOTA性能。这项工作的一个局限性是,本文的模型仅在语料库规模有限的Visual Grounding数据集上训练,因此,经过训练的模型可能无法很好地泛化到更开放的语言表达式。
参考资料
[1]https://arxiv.org/abs/2205.00272
[2]https://github.com/yangli18/VLTVG

END
欢迎加入「视觉语言」交流群备注:VL
