One-Stage Visual Grounding(单阶段语言指示的视觉定位)论文略读_2019-2020
One-Stage Visual Grounding 2019-2020年论文略读
- 1.Zero-Shot Grounding of Objects from Natural Language Queries(2019 ICCV)
-
- 改进工作:
- 论文模型:
- 2.A Fast and Accurate One-Stage Approach to Visual Grounding(2019 ICCV)
- 3.A Real-Time Cross-modality Correlation Filtering Method for Referring Expression Comprehension(2020 CVPR)
-
- 改进工作:
- 论文模型:
- 4.Improving One-stage Visual Grounding by Recursive Sub-query Construction(2020 ECCV)
-
- 改进工作:
- 论文模型:
- 5.Linguistic Structure Guided Context Modeling for Referring Image Segmentation(2020 ECCV)
上一篇:One-Stage Visual Grounding 2017-2018年论文粗读
禁止以任何形式转载文章!
1.Zero-Shot Grounding of Objects from Natural Language Queries(2019 ICCV)
论文地址:http://openaccess.thecvf.com/content_ICCV_2019.
代码:https://github.com/TheShadow29/zsgnet-pytorch.
改进工作:
已有的定位方法在测试时,只能对训练集中出现过的单词或短语进行定位。本文提出一个新的任务——zero-shot grounding,致力于对训练集中没有出现的单词或短语进行定位。但是,由于检测器能够识别的种类受限于训练数据,两阶段的定位方法不适用于此任务。综上,本文提出了一阶段的zero-shot grounding方法(多模态特征融合+SSD)。作者还引入了新的数据集(从Flickr30k Entities和Visual Genome中进行抽样),这些数据集支持对作者假设的四种条件进行评估。
论文模型:

系统的输入是一个图像查询对。利用深度网络生成不同分辨率的K幅图像特征图。锚点生成器使用图像大小来产生不同尺度和分辨率的锚点。我们将锚点中心附加在每个特征图的每个单元格上。查询短语使用双向LSTM (Bi-LSTM)进行编码,并将获得的语言特征附加在通道维上每个特征映射的每个单元位置上。将得到的多模态特征映射输入到全卷积网络(FCN)块中,分别使用focal-loss和SmoothL1-loss训练输出预测分数和回归参数。
zero-shot grounding的四种情况:
- case0:之前的任何训练示例中都没有包含查询名词。我们只看归了类的词汇,所以同义词被认为是不同的(新)词。比如:car和automobile。自制数据集Flickr-Split-0
- case1:我们假设在训练时看到的对象属于一组预定义的类别,而引用的对象不属于这些类别,是一个新的类别物体。自制数据集Flickr-Split-1
- case2:测试时图像有新的类别物体,但是此类别和训练集中已有类别近似,且新类别和原类别没有同时出现在测试数据中。自制数据集VG-Split-2
- case3:同case2,但两种类别同时出现在测试数据中。自制数据集VG-Split-3
数据集:
Flickr30k Entities:每个图像包含5个句子,每个句子包含3.6个查询,并且包含被引用对象及其类别的边框信息。一共有30K张图片。
Visual Genome (VG):每个图像都有一个场景图。场景图中的对象用边框、区域描述和同义词集来标注。
ReferIt(RefClef):是Imageclef的子集,包含20k图像和85k查询短语。
2.A Fast and Accurate One-Stage Approach to Visual Grounding(2019 ICCV)
论文地址:https://openaccess.thecvf.com/content_ICCV_2019.
论文解读 点这里
3.A Real-Time Cross-modality Correlation Filtering Method for Referring Expression Comprehension(2020 CVPR)
论文地址:https://openaccess.thecvf.com/content_CVPR_2020.
改进工作:
现有方法由于采用两阶段框架(proposal generation、proposal ranking),在不降低精度的同时,无法达到实时推理。本文从以上问题出发,提出RCCF方法,可以在单GPU上达到40FPS,约为两阶段方法的两倍。为了不提取候选框,作者将问题理解为一个跨模态模板匹配问题。在RCCF中,首先利用语言引导的滤波内核对图像特征进行相关滤波,从而定位表达式所描述的目标中心点。然后,应用一个回归模块来回归对象的大小和中心偏移量。相关热图中的峰值、回归的对象大小和中心点偏移共同形成目标包围框。
论文模型:
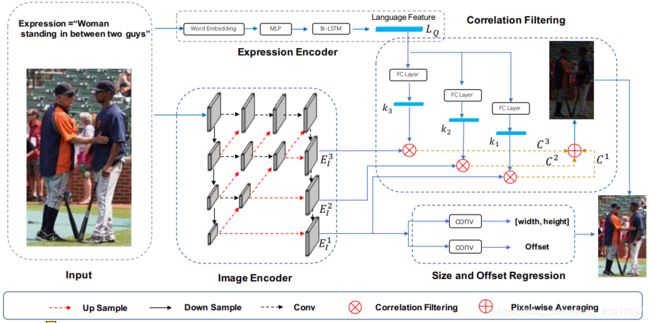
RCCF框架概述:
a)指涉文字和图像编码器:使用Bi-LSTM和DLA结构进行表达式和视觉特征提取。
b) cross -modal Correlation Filtering:将提取的语言特征映射到三个不同的filter kernel中。然后用相应的核函数对三层图像特征进行相关滤波,分别生成三幅相关映射。最后,我们通过像素平均融合三个相关图。中心点对应于熔合热图的峰值。
c)大小和偏移量回归:二维的对象大小和中心点的局部偏移量仅根据最后一级图像特征进行回归。结合估计的中心点、目标大小和局部偏移量,得到目标目标区域。
4.Improving One-stage Visual Grounding by Recursive Sub-query Construction(2020 ECCV)
论文地址:https://arxiv.org/pdf/2008.01059.pdf.
改进工作:
这篇文章同样来自于腾讯AI实验室,在19年的One-Stage VG基础上进行了改进和提升,加入了递归子查询模块Recursive Sub-query Construction(ReSC 代码),解决当前对长而复杂的查询进行定位的弱点。
现有的单阶段方法将整个查询编码为单个嵌入向量,例如直接从BERT中采用第一个令牌的嵌入或从LSTM中聚合隐藏状态。然后将单个向量在所有具有视觉特征的空间位置进行连接,以获得用于定位预测的融合特征。将整个语言查询建模为单个嵌入向量往往会增加表示的模糊性,例如只关注某些单词,而忽略其他重要的单词。这样的问题可能会导致引用信息的丢失,特别是在那些长而复杂的查询上。
虽然,两阶段已经出现了一些解决此弱点的方法,例如:MattNet将查询内容解析为主题、位置和关系短语,并将每个短语与相关的对象区域链接起来进行匹配得分计算。NMTREE使用依赖树解析器解析查询,并将每个树节点与一个可视区域链接起来。DGA以文本自我注意来解析查询,并通过动态图形注意将文本与区域连接起来。但是两阶段方法不能直接应用于单阶段框架。
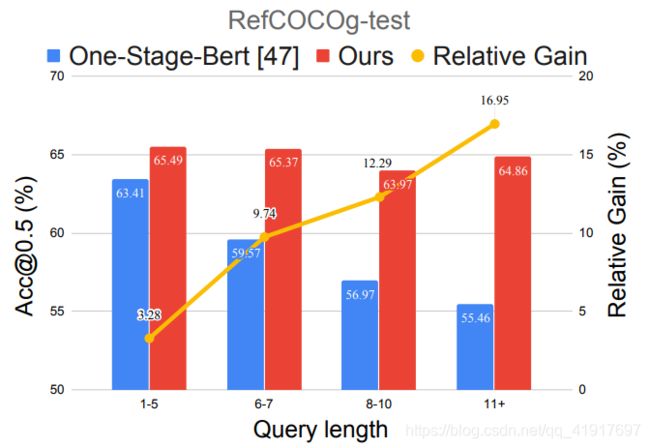
因此,为了在统一的单阶段框架中解决查询建模问题,作者提出了一种递归的子查询构造框架,该框架可以对图像和查询进行多轮的推理,逐步减少引用歧义。这个方法在ReferItGame, RefCOCO, RefCOCO+, and RefCOCOg,数据集上得到了5到12个百分点的提高,尤其是在长和复杂句子描述查询上的表现。
论文模型:
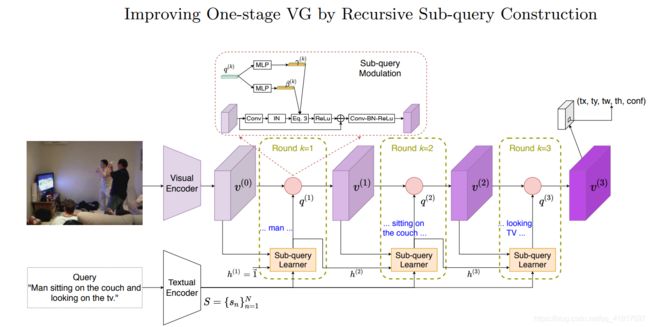
- Visual Encoder:使用的是YOLO V3在COCO数据集上预训练的Darknet-53网络。输入图片resize到3×256×256,第102个卷积层输出32 × 32 × 256,将原始的视觉特征映射到视觉输入v(0),通过一个1 × 1的卷积层进行批处理归一化和ReLU,设置共享维数C = 512。
- Textual Encoder:用不加大小写的BERT基版本将查询中的每个单词编码为768D向量。我们将最后四层中每个单词的表示形式相加,然后将特征映射到两个全连接层中得到S,不包含[CLS], [SEP] and [PAD]。
- Sub-query Learner:子查询学习者在每轮k中构造一个子查询,以一组单词为对象给出得分向量α。作者认为每一轮中,当前的文本环境视觉特征很重要,同时也需要之前的历史子查询信息来避免过于关注当前的关键词信息。所以每轮中计算得分α,是根据查询语言的特征S,历史子查询信息h以及文本环境的视觉特征v综合得出分数:
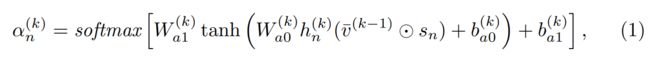
哈达玛乘积:矩阵对应位置的元素相乘。
从直觉上来讲,每轮构建的子查询应该关注查询的不同元素,最后,查询中的大多数单词都应该被查看。因此,加入两个正则化项Ldiv和 Lcover,Ldiv避免任何一个词语在多于一轮中收到关注,从而加强了多样性。Lcover帮助模型查找查询中的所有单词,从而提高了覆盖率。 - Sub-query Modulation:子查询调制的目的是用新的子查询特征q来细化文本条件视觉特征v,使细化后的特征v在预测方面有更好的表现。其中,子查询特征q,就是将得到的分数α与单词的特征S乘积求和。然后利用q经MLP(tanh作为激活函数)得到的γ和β对v进行缩放和偏移:(这里作者尝试了每一个空间位置设置一个γ和β,计算复杂效果还没提升)
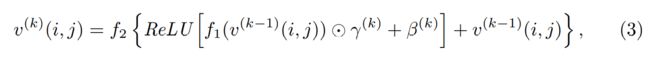
i,j代表特征图上空间坐标,f1,f2分别是图上1x1conv+instance normalization、3x3conv+batch normalization+ReLU。 - Grounding module:这里是利用最后一个v进行边框回归和计算置信度分数。这里一共32 × 32 = 1024个锚点,每个点9个锚框, 1024×9 = 9216 anchor boxes。分类和回归损失函数同One-Stage VG,此外多加入了前面提到的两个正则化。
数据集分析和划分:
RefCOCO有19,994张图片和142,210个对象实例的引用表达式。RefCOCO+有19,992张图片和49,856个对象实例的141,564个引用表达式。RefCOCOg有25,799个图像,95,010个引用表达式,用于49,822个对象实例。
RefCOCO and RefCOCO+:划分为train/ validation/ testA/ testB,“testA”中的图像是多人的,“testB”中的图像包含所有其他对象。
RefCOCOg:分成RefCOCOg-google and RefCOCOg-umd,划分为val-g, val-u, and test-u,RefCOCOg比RefCOCO和RefCOCO+的查询更长,平均查询长度分别为3.61、3.53、8.43。
Flickr30K Entities:有31,783个图像,427K个引用表达。大部分是名词短语。
ReferItGame:有20,000张来自SAIAPR12的图片。
5.Linguistic Structure Guided Context Modeling for Referring Image Segmentation(2020 ECCV)
论文地址:https://www.ecva.net/papers/eccv_2020/papers_ECCV.
论文解读 点这里
禁止以任何形式转载文章!!!
上一篇:One-Stage Visual Grounding 2017-2018年论文粗读
参考:One-Stage Visual Grounding论文汇总.