基础算法-朴素贝叶斯分类器
一、算法简介
1.1 背景
监督学习分为生成模型 (generative model) 与判别模型 (discriminative model),贝叶斯方法正是生成模型的代表 (还有隐马尔科夫模型)。
在概率论与统计学中,贝叶斯定理 (Bayes' theorem) 表达了一个事件发生的概率,而确定这一概率的方法是基于与该事件相关的条件先验知识 (prior knowledge)。而利用相应先验知识进行概率推断的过程为贝叶斯推断 (Bayesian inference)。
1.2 贝叶斯定理
条件概率 (conditional probability) 是指在事件 B 发生的情况下,事件 A 发生的概率。通常记为 P(A | B)。
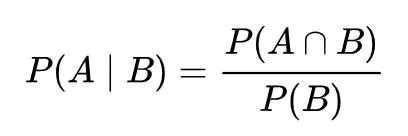
因此

可得
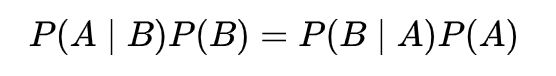
由此可以推出贝叶斯公式
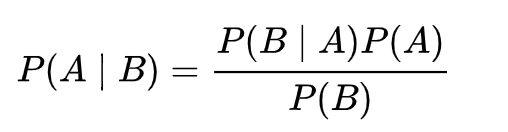
这也是条件概率的计算公式。
此外,由全概率公式,可得条件概率的另一种写法
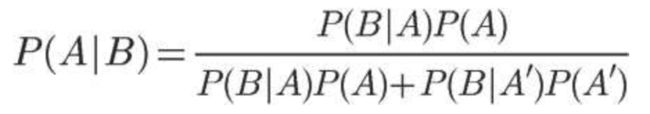
其中样本空间由A和A'构成,由此求得事件B的概率。
1.3 贝叶斯推断
贝叶斯公式中,P(A)称为"先验概率"(Prior probability),即在B事件发生之前,对A事件概率的一个判断。
P(A|B)称为"后验概率"(Posterior probability),即在B事件发生之后,对A事件概率的重新评估。
P(B|A)/P(B)称为"可能性函数"(Likelyhood),这是一个调整因子,使得预估概率更接近真实概率。
所以,条件概率可以理解成下面的式子:后验概率=先验概率 x 调整因子
这就是贝叶斯推断的含义。我们先预估一个"先验概率",然后加入实验结果,看这个实验到底是增强还是削弱了"先验概率",由此得到更接近事实的"后验概率"。因为在分类中,只需要找出可能性最大的那个选项,而不需要知道具体那个类别的概率是多少,所以为了减少计算量,全概率公式在实际编程中可以不使用。
而朴素贝叶斯推断,是在贝叶斯推断的基础上,对条件概率分布做了条件独立性的假设。因此可得朴素贝叶斯分类器的表达式。因为以自变量之间的独立(条件特征独立)性和连续变量的正态性假设为前提,就会导致算法精度在某种程度上受影响。
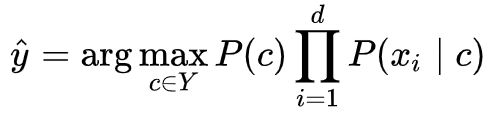
1.4 朴素贝叶斯的参数推断
实际在机器学习的分类问题的应用中,朴素贝叶斯分类器的训练过程就是基于训练集 D 来估计类先验概率 P(c) ,并为每个属性估计条件概率 P(xi | c) 。这里就需要使用极大似然估计 (maximum likelihood estimation, 简称 MLE) 来估计相应的概率。
令 Dc 表示训练集 D 中的第 c 类样本组成的集合,若有充足的独立同分布样本,则可容易地估计出类别的先验概率:
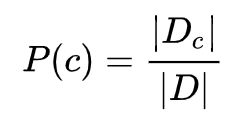
对于离散属性而言,令 Dc,xi 表示 Dc 中在第 i 个属性上取值为 xi 的样本组成的集合,则条件概率 P(xi | c) 可估计为:
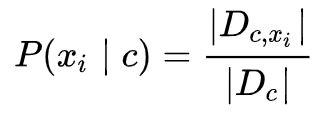
对于连续属性可考虑概率密度函数,假定
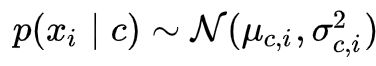
μ和sigma分别是第 c 类样本在第 i 个属性上取值的均值和方差,则有:
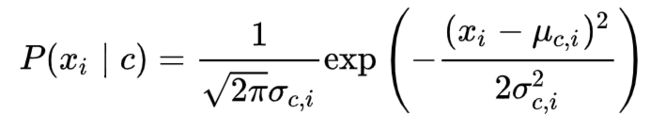
需注意,若某个属性值在训练集中没有与某个类同时出现过,为了避免,通常要进行“平滑”,拉普拉斯修正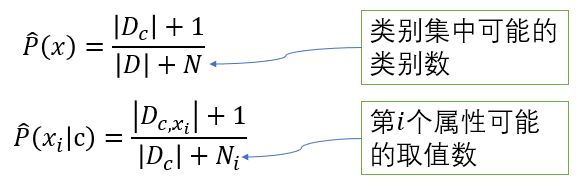
1.5 算法流程
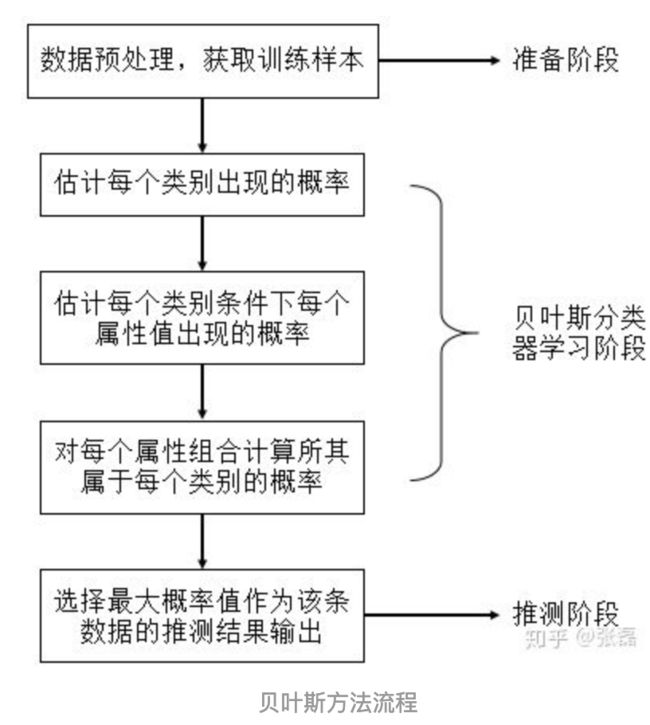
实际应用方式:
- 若任务对预测速度要求较高,则对给定的训练集,可将朴素贝叶斯分类器涉及的所有概率估值事先计算好存储起来,这样在进行预测时只需要 “查表” 即可进行判别;
- 若任务数据更替频繁,则可采用 “懒惰学习” (lazy learning) 方式,先不进行任何训练,待收到预测请求时再根据当前数据集进行概率估值;
- 若数据不断增加,则可在现有估值的基础上,仅对新增样本的属性值所涉及的概率估值进行计数修正即可实现增量学习。
3.贝叶斯分类器代码
# 使用拉普拉斯修正的朴素贝叶斯分类器,这种情况是对第一行的数据进行测试
import numpy as np
import pandas as pd
from math import log, exp, pow, sqrt, pi
# exp(x):e的x次方;pow(x,y):x的y次方
df = pd.read_csv('watermelon_4_3.csv')
data = df.values[:, 1:-1]
m, n = np.shape(data)
test = df.values[0, 1:-1]
labels = df.values[:, -1].tolist()
for i in range(len(labels)):
if labels[i] == '否':
labels[i] = 0
else:
labels[i] = 1
# 第i个属性的可能取值
def class_number(index):
class_number = {}
for column in data:
if column[index] not in class_number.keys():
class_number[column[index]] = 0
class_number[column[index]] += 1
num = len(class_number)
return num
# 求出连续属性的均值和方差参数
def continue_para(num, index):
ave = 0.0 # 求均值
var = 0.0 # 求方差(此时没有开根号处理,套入公式抵消)
count = 0
for column in range(len(data)):
if labels[column] == num:
count += 1
ave += data[column, index]
ave = ave / count # 求均值
for column in range(len(data)):
if labels[column] == num:
var += (data[column, index] - ave) * (data[column, index] - ave)
var = var / count # 求方差
return ave, var
# 计算先验概率P
prob_good = log((8 + 1) / float(m + 2)) # P153
prob_bad = log((9 + 1) / float(m + 2)) # P153
for i in range(len(data[0])):
if type(test[i]).__name__ == 'float': # 当特征是连续的时候
ave0, var0 = continue_para(0, i) # 0
ave1, var1 = continue_para(1, i) # 1
# 带入到连续的公式中
prob0 = exp(- pow(test[i] - ave0, 2) / (2 * var0)) / sqrt(2 * pi * var0) # 连续属性0 坏瓜 P151
prob1 = exp(- pow(test[i] - ave1, 2) / (2 * var1)) / sqrt(2 * pi * var1) # 连续属性1 好瓜 P151
prob_bad += log(prob0)
prob_good += log(prob1)
# 离散
else:
count_good = 0
count_bad = 0
for column in range(len(data)):
if test[i] == data[column, i]:
if labels[column] == 1:
count_good += 1
if labels[column] == 0:
count_bad += 1
prob_good += log(float(count_good + 1) / (8 + class_number(i)))
prob_bad += log(float(count_bad + 1) / (9 + class_number(i)))
print('probability of good watermelon : %f' % prob_good)
print('probability of bad watermelon : %f' % prob_bad)
if prob_good >= prob_bad:
print('final result: good watermelon (是)')
else:
print('final result: bad watermelon (否)')