RCNN学习笔记-ShuffleNetV2源码分析
论文:ShuffleNet V2: Practical Guidelines for Ecient CNN Architecture Design
论文链接:https://pan.baidu.com/s/1so7aD3hLKO-0PB8h4HWliw
网络总体输出结构:
ShuffleNetV2(
(conv1): Sequential(
(0): Conv2d(3, 24, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(1): BatchNorm2d(24, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
(maxpool): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
(stage2): Sequential(
(0): InvertedResidual(
(branch1): Sequential(
(0): Conv2d(24, 24, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), groups=24, bias=False)
(1): BatchNorm2d(24, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): Conv2d(24, 58, kernel_size=(1, 1), stride=(1, 1), bias=False)
(3): BatchNorm2d(58, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(4): ReLU(inplace=True)
)
(branch2): Sequential(
(0): Conv2d(24, 58, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(58, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): Conv2d(58, 58, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), groups=58, bias=False)
(4): BatchNorm2d(58, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): Conv2d(58, 58, kernel_size=(1, 1), stride=(1, 1), bias=False)
(6): BatchNorm2d(58, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(7): ReLU(inplace=True)
)
)
(1): InvertedResidual(
(branch1): Sequential()
(branch2): Sequential(
(0): Conv2d(58, 58, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(58, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): Conv2d(58, 58, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=58, bias=False)
(4): BatchNorm2d(58, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): Conv2d(58, 58, kernel_size=(1, 1), stride=(1, 1), bias=False)
(6): BatchNorm2d(58, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(7): ReLU(inplace=True)
)
)
(2): InvertedResidual(
(branch1): Sequential()
(branch2): Sequential(
(0): Conv2d(58, 58, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(58, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): Conv2d(58, 58, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=58, bias=False)
(4): BatchNorm2d(58, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): Conv2d(58, 58, kernel_size=(1, 1), stride=(1, 1), bias=False)
(6): BatchNorm2d(58, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(7): ReLU(inplace=True)
)
)
(3): InvertedResidual(
(branch1): Sequential()
(branch2): Sequential(
(0): Conv2d(58, 58, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(58, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): Conv2d(58, 58, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=58, bias=False)
(4): BatchNorm2d(58, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): Conv2d(58, 58, kernel_size=(1, 1), stride=(1, 1), bias=False)
(6): BatchNorm2d(58, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(7): ReLU(inplace=True)
)
)
)
(stage3): Sequential(
(0): InvertedResidual(
(branch1): Sequential(
(0): Conv2d(116, 116, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), groups=116, bias=False)
(1): BatchNorm2d(116, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): Conv2d(116, 116, kernel_size=(1, 1), stride=(1, 1), bias=False)
(3): BatchNorm2d(116, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(4): ReLU(inplace=True)
)
(branch2): Sequential(
(0): Conv2d(116, 116, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(116, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): Conv2d(116, 116, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), groups=116, bias=False)
(4): BatchNorm2d(116, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): Conv2d(116, 116, kernel_size=(1, 1), stride=(1, 1), bias=False)
(6): BatchNorm2d(116, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(7): ReLU(inplace=True)
)
)
(1): InvertedResidual(
(branch1): Sequential()
(branch2): Sequential(
(0): Conv2d(116, 116, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(116, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): Conv2d(116, 116, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=116, bias=False)
(4): BatchNorm2d(116, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): Conv2d(116, 116, kernel_size=(1, 1), stride=(1, 1), bias=False)
(6): BatchNorm2d(116, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(7): ReLU(inplace=True)
)
)
(2): InvertedResidual(
(branch1): Sequential()
(branch2): Sequential(
(0): Conv2d(116, 116, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(116, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): Conv2d(116, 116, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=116, bias=False)
(4): BatchNorm2d(116, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): Conv2d(116, 116, kernel_size=(1, 1), stride=(1, 1), bias=False)
(6): BatchNorm2d(116, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(7): ReLU(inplace=True)
)
)
(3): InvertedResidual(
(branch1): Sequential()
(branch2): Sequential(
(0): Conv2d(116, 116, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(116, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): Conv2d(116, 116, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=116, bias=False)
(4): BatchNorm2d(116, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): Conv2d(116, 116, kernel_size=(1, 1), stride=(1, 1), bias=False)
(6): BatchNorm2d(116, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(7): ReLU(inplace=True)
)
)
(4): InvertedResidual(
(branch1): Sequential()
(branch2): Sequential(
(0): Conv2d(116, 116, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(116, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): Conv2d(116, 116, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=116, bias=False)
(4): BatchNorm2d(116, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): Conv2d(116, 116, kernel_size=(1, 1), stride=(1, 1), bias=False)
(6): BatchNorm2d(116, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(7): ReLU(inplace=True)
)
)
(5): InvertedResidual(
(branch1): Sequential()
(branch2): Sequential(
(0): Conv2d(116, 116, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(116, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): Conv2d(116, 116, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=116, bias=False)
(4): BatchNorm2d(116, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): Conv2d(116, 116, kernel_size=(1, 1), stride=(1, 1), bias=False)
(6): BatchNorm2d(116, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(7): ReLU(inplace=True)
)
)
(6): InvertedResidual(
(branch1): Sequential()
(branch2): Sequential(
(0): Conv2d(116, 116, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(116, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): Conv2d(116, 116, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=116, bias=False)
(4): BatchNorm2d(116, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): Conv2d(116, 116, kernel_size=(1, 1), stride=(1, 1), bias=False)
(6): BatchNorm2d(116, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(7): ReLU(inplace=True)
)
)
(7): InvertedResidual(
(branch1): Sequential()
(branch2): Sequential(
(0): Conv2d(116, 116, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(116, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): Conv2d(116, 116, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=116, bias=False)
(4): BatchNorm2d(116, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): Conv2d(116, 116, kernel_size=(1, 1), stride=(1, 1), bias=False)
(6): BatchNorm2d(116, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(7): ReLU(inplace=True)
)
)
)
(stage4): Sequential(
(0): InvertedResidual(
(branch1): Sequential(
(0): Conv2d(232, 232, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), groups=232, bias=False)
(1): BatchNorm2d(232, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): Conv2d(232, 232, kernel_size=(1, 1), stride=(1, 1), bias=False)
(3): BatchNorm2d(232, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(4): ReLU(inplace=True)
)
(branch2): Sequential(
(0): Conv2d(232, 232, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(232, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): Conv2d(232, 232, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), groups=232, bias=False)
(4): BatchNorm2d(232, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): Conv2d(232, 232, kernel_size=(1, 1), stride=(1, 1), bias=False)
(6): BatchNorm2d(232, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(7): ReLU(inplace=True)
)
)
(1): InvertedResidual(
(branch1): Sequential()
(branch2): Sequential(
(0): Conv2d(232, 232, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(232, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): Conv2d(232, 232, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=232, bias=False)
(4): BatchNorm2d(232, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): Conv2d(232, 232, kernel_size=(1, 1), stride=(1, 1), bias=False)
(6): BatchNorm2d(232, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(7): ReLU(inplace=True)
)
)
(2): InvertedResidual(
(branch1): Sequential()
(branch2): Sequential(
(0): Conv2d(232, 232, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(232, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): Conv2d(232, 232, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=232, bias=False)
(4): BatchNorm2d(232, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): Conv2d(232, 232, kernel_size=(1, 1), stride=(1, 1), bias=False)
(6): BatchNorm2d(232, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(7): ReLU(inplace=True)
)
)
(3): InvertedResidual(
(branch1): Sequential()
(branch2): Sequential(
(0): Conv2d(232, 232, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(232, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): Conv2d(232, 232, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=232, bias=False)
(4): BatchNorm2d(232, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): Conv2d(232, 232, kernel_size=(1, 1), stride=(1, 1), bias=False)
(6): BatchNorm2d(232, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(7): ReLU(inplace=True)
)
)
)
(conv5): Sequential(
(0): Conv2d(464, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
(fc): Linear(in_features=1024, out_features=1000, bias=True)
)
网络结构图
这里对应解释的是1.0版本
对应的是左边c,d的两个结构
代码解释
from typing import List, Callable
import torch
from torch import Tensor
import torch.nn as nn
#通道变换
def channel_shuffle(x: Tensor, groups: int) -> Tensor:
batch_size, num_channels, height, width = x.size()
channels_per_group = num_channels // groups
# reshape
# [batch_size, num_channels, height, width] -> [batch_size, groups, channels_per_group, height, width]
x = x.view(batch_size, groups, channels_per_group, height, width)
x = torch.transpose(x, 1, 2).contiguous()
# flatten
x = x.view(batch_size, -1, height, width)
return x
#实现block
class InvertedResidual(nn.Module):
def __init__(self, input_c: int, output_c: int, stride: int):
super(InvertedResidual, self).__init__()
#对stride进行判断,如果不是的话,就直接包出异常
if stride not in [1, 2]:
raise ValueError("illegal stride value.")
self.stride = stride
#对输出通道进行判断,一定是2的整数倍。因为最后还有一个相加操作。也因为有分支的原因。
assert output_c % 2 == 0
branch_features = output_c // 2
# 当stride为1时,input_channel应该是branch_features的两倍
# python中 '<<' 是位运算,可理解为计算×2的快速方法
assert (self.stride != 1) or (input_c == branch_features << 1)
#这个代表的是左边的分支
if self.stride == 2:
self.branch1 = nn.Sequential(
#dw卷积的输入是和输出通道是不变的。
self.depthwise_conv(input_c, input_c, kernel_s=3, stride=self.stride, padding=1),
nn.BatchNorm2d(input_c),
nn.Conv2d(input_c, branch_features, kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(branch_features),
nn.ReLU(inplace=True)
)
else:#当stride=1的时候,就是左边的图,对其不进行任何处理。
self.branch1 = nn.Sequential()
#这个代表的是右边的分支
self.branch2 = nn.Sequential(
#如果在这里self.stride是2的话,就是input_c
#如果在这里input_c是1的话,就是branch_features
nn.Conv2d(input_c if self.stride > 1 else branch_features, branch_features, kernel_size=1,
stride=1, padding=0, bias=False),
nn.BatchNorm2d(branch_features),
nn.ReLU(inplace=True),
self.depthwise_conv(branch_features, branch_features, kernel_s=3, stride=self.stride, padding=1),
nn.BatchNorm2d(branch_features),
nn.Conv2d(branch_features, branch_features, kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(branch_features),
nn.ReLU(inplace=True)
)
@staticmethod
def depthwise_conv(input_c: int,
output_c: int,
kernel_s: int,
stride: int = 1,
padding: int = 0,
bias: bool = False) -> nn.Conv2d:
return nn.Conv2d(in_channels=input_c, out_channels=output_c, kernel_size=kernel_s,
stride=stride, padding=padding, bias=bias, groups=input_c)
def forward(self, x: Tensor) -> Tensor:
if self.stride == 1:
#将其进行均分操作,dim=1指的是维度为通道数
x1, x2 = x.chunk(2, dim=1)
out = torch.cat((x1, self.branch2(x2)), dim=1)
else:
out = torch.cat((self.branch1(x), self.branch2(x)), dim=1)
#channel_shuffle在concat之后。根据论文提示。
out = channel_shuffle(out, 2)
return out
class ShuffleNetV2(nn.Module):
def __init__(self,
stages_repeats: List[int],#stage重复的次数
stages_out_channels: List[int],#conv输出通道数的大小
num_classes: int = 1000,#类别个数
#残差块的类别
inverted_residual: Callable[..., nn.Module] = InvertedResidual):
super(ShuffleNetV2, self).__init__()
#在这里做判断,如果输入错误直接报错。
if len(stages_repeats) != 3:
raise ValueError("expected stages_repeats as list of 3 positive ints")
if len(stages_out_channels) != 5:
raise ValueError("expected stages_out_channels as list of 5 positive ints")
#[24, 116, 232, 464, 1024],
self._stage_out_channels = stages_out_channels
# input RGB image
input_channels = 3
#第一个输出通道的卷积个数:24
output_channels = self._stage_out_channels[0]
#第一个卷积
#对应的是结构中的Conv1
self.conv1 = nn.Sequential(
#3,24
nn.Conv2d(input_channels, output_channels, kernel_size=3, stride=2, padding=1, bias=False),
nn.BatchNorm2d(output_channels),
nn.ReLU(inplace=True)
)
input_channels = output_channels
#再接着一个maxpooling
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
# Static annotations for mypy
# 在这里做声明变量的意思。
self.stage2: nn.Sequential
self.stage3: nn.Sequential
self.stage4: nn.Sequential
stage_names = ["stage{}".format(i) for i in [2, 3, 4]]
#self._stage_out_channels[1:]===[ 116, 232, 464, 1024],
#stage_names==stage{2},stage{3},stage{4}
#stages_repeats==[4, 8, 4]=={1,3.1,7.1,3}
'''
('stage2', 4, 116)
('stage3', 8, 232)
('stage4', 4, 464)
'''
for name, repeats, output_channels in zip(stage_names, stages_repeats,
self._stage_out_channels[1:]):
#第一个步距是2,这是第一个所以需要进行特殊处理。同时通道数的大小也是在这里进行修改的。后面的不会改变通道数目的。
seq = [inverted_residual(input_channels, output_channels, 2)]
#剩下的就是步距为1的卷积结构
for i in range(repeats - 1):
seq.append(inverted_residual(output_channels, output_channels, 1))
#给每一个sequential设置一个name。
setattr(self, name, nn.Sequential(*seq))
input_channels = output_channels
#最后一个通道数
output_channels = self._stage_out_channels[-1]
#这里对应的是最后一个卷积层Conv5
self.conv5 = nn.Sequential(
nn.Conv2d(input_channels, output_channels, kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(output_channels),
nn.ReLU(inplace=True)
)
#全局池化层加入到了forward里面了。
self.fc = nn.Linear(output_channels, num_classes)
def _forward_impl(self, x: Tensor) -> Tensor:
# See note [TorchScript super()]
x = self.conv1(x)
x = self.maxpool(x)
x = self.stage2(x)
x = self.stage3(x)
x = self.stage4(x)
x = self.conv5(x)
#这里使用mean方法做全局池化操作0,1,2,3通过mean之后,就只剩下batch和channel维度了。
x = x.mean([2, 3]) # global pool
x = self.fc(x)
return x
def forward(self, x: Tensor) -> Tensor:
return self._forward_impl(x)
def shufflenet_v2_x0_5(num_classes=1000):
"""
Constructs a ShuffleNetV2 with 0.5x output channels, as described in
`"ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design"
`.
weight: https://download.pytorch.org/models/shufflenetv2_x0.5-f707e7126e.pth
:param num_classes:
:return:
"""
model = ShuffleNetV2(stages_repeats=[4, 8, 4],
stages_out_channels=[24, 48, 96, 192, 1024],
num_classes=num_classes)
return model
def shufflenet_v2_x1_0(num_classes=1000):
"""
Constructs a ShuffleNetV2 with 1.0x output channels, as described in
`"ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design"
`.
weight: https://download.pytorch.org/models/shufflenetv2_x1-5666bf0f80.pth
:param num_classes:
:return:
"""
model = ShuffleNetV2(stages_repeats=[4, 8, 4],
stages_out_channels=[24, 116, 232, 464, 1024],
num_classes=num_classes)
return model
def shufflenet_v2_x1_5(num_classes=1000):
"""
Constructs a ShuffleNetV2 with 1.0x output channels, as described in
`"ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design"
`.
weight: https://download.pytorch.org/models/shufflenetv2_x1_5-3c479a10.pth
:param num_classes:
:return:
"""
model = ShuffleNetV2(stages_repeats=[4, 8, 4],
stages_out_channels=[24, 176, 352, 704, 1024],
num_classes=num_classes)
return model
def shufflenet_v2_x2_0(num_classes=1000):
"""
Constructs a ShuffleNetV2 with 1.0x output channels, as described in
`"ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design"
`.
weight: https://download.pytorch.org/models/shufflenetv2_x2_0-8be3c8ee.pth
:param num_classes:
:return:
"""
model = ShuffleNetV2(stages_repeats=[4, 8, 4],
stages_out_channels=[24, 244, 488, 976, 2048],
num_classes=num_classes)
return model
if __name__ == '__main__' :
x = torch.rand([1, 3, 224, 224])
model = shufflenet_v2_x1_0(x)
print(model)
对其中的函数channel shuffle的解释代码块,此部分和上面整体代码没有直接联系。
import random
import torch
import torch.nn as nn
#通道变换
class ChannelShuffle(nn.Module):
def __init__(self, groups):
super(ChannelShuffle, self).__init__()
self.groups = groups
#分别为三次x的通道数所做出的改变。
'''
tensor([[[[-1.5256, -0.7502],
[-0.6540, -1.6095]],
[[-0.1002, -0.6092],
[-0.9798, -1.6091]],
[[ 0.4391, 1.1712],
[ 1.7674, -0.0954]],
[[ 0.1394, -1.5785],
[-0.3206, -0.2993]],
[[-0.7984, 0.3357],
[ 0.2753, 1.7163]],
[[-0.0561, 0.9107],
[-1.3924, 2.6891]]]])
'''
'''
tensor([[[[[-1.5256, -0.7502],
[-0.6540, -1.6095]],
[[-0.1002, -0.6092],
[-0.9798, -1.6091]],
[[ 0.4391, 1.1712],
[ 1.7674, -0.0954]]],
[[[ 0.1394, -1.5785],
[-0.3206, -0.2993]],
[[-0.7984, 0.3357],
[ 0.2753, 1.7163]],
[[-0.0561, 0.9107],
[-1.3924, 2.6891]]]]])
1,2,3,2,2
'''
'''
tensor([[[[-1.5256, -0.7502],
[-0.6540, -1.6095]],
[[ 0.1394, -1.5785],
[-0.3206, -0.2993]],
[[-0.1002, -0.6092],
[-0.9798, -1.6091]],
[[-0.7984, 0.3357],
[ 0.2753, 1.7163]],
[[ 0.4391, 1.1712],
[ 1.7674, -0.0954]],
[[-0.0561, 0.9107],
[-1.3924, 2.6891]]]])
1,6,2,2
'''
def forward(self, x):
B, C, H, W = x.shape
chnls_per_group = C // self.groups#总通道数除以通道数,就是每一个组内的通道数。
assert C % self.groups == 0
#在这里的shape为1,2,3,2,2,改变数据的通道数的
x = x.view(B, self.groups, chnls_per_group, H, W) # 通道分组 (B,C,H,W)->(B,group,C,H,W)
#到这里改变为1,3,2,2,2
x = torch.transpose(x, 1, 2).contiguous() # 通道洗牌
x = x.view(B, -1, H, W) # 重新展开为(B,C,H,W)
return x
channel_shuffle = ChannelShuffle(2)
random.seed(1)
torch.manual_seed(1)
input = torch.randn(1, 6, 2, 2)
print(input)
output = channel_shuffle(input)
print(output)
参考链接:
https://blog.csdn.net/kdongyi/article/details/108180250
https://blog.csdn.net/guhuoone/article/details/125173067
https://blog.csdn.net/u014380165/article/details/81322175?spm=1001.2101.3001.6650.8&utm_medium=distribute.pc_relevant.none-task-blog-2%7Edefault%7EBlogCommendFromBaidu%7ERate-8-81322175-blog-124691076.pc_relevant_multi_platform_whitelistv3&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2%7Edefault%7EBlogCommendFromBaidu%7ERate-8-81322175-blog-124691076.pc_relevant_multi_platform_whitelistv3&utm_relevant_index=8
模型选择

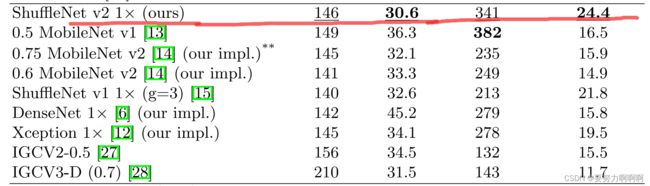


从图中可以看出来模型版本的优点。