Transformer主干网络——T2T-ViT保姆级解析
前言
论文地址:paper
代码地址:github
系列文章
Transformer主干网络——ViT保姆级解析
Transformer主干网络——DeiT保姆级解析
Transformer主干网络——T2T-ViT保姆级解析
Transformer主干网络——TNT保姆级解析
Transformer主干网络——PVT_V1保姆级解析
Transformer主干网络——PVT_V2保姆级解析
Transformer主干网络——Swin保姆级解析
Transformer主干网络——PatchConvNet保姆级解析
持续更新…
动机
作者针对ViT在中等大小数据集预训练效果不好的现象出发分析。
- 作者分析对比ViT和Resnet网络各个层输出的特征图发现ViT的一些block学习的特征比较差(下图红色的框),原因是ViT简单的对局部区域建模丢失了图像的线条以及边缘信息。
- 在有限的计算资源和有限的数据的情况下,ViT冗余的attention主干网络难以学得丰富的特征。就是说小数据集下主要是因为冗余的attention结构导致学习的特征不好!所以出现ViT在中等大小数据集预训练效果不好的现象。
网络分析
对比了一下ViT的代码,因为T2T主要在ViT魔改,所以主要有差异的地方在下图圈起来的部分:
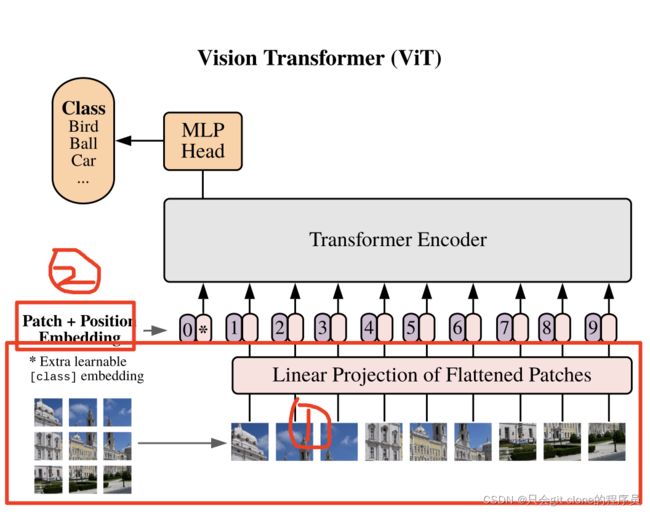
先看T2T的论文网络结构图:
其中Tokens-to-Tokens module就是圈起来魔改的第一部分,PE是小改的第二部分(将ViT原来硬训的可学习的位置编码改成了sinusoid position encoding)其他部分都相同。
看代码的话会更简洁一些,diff比较直观,左图是T2T-ViT右图是ViT:
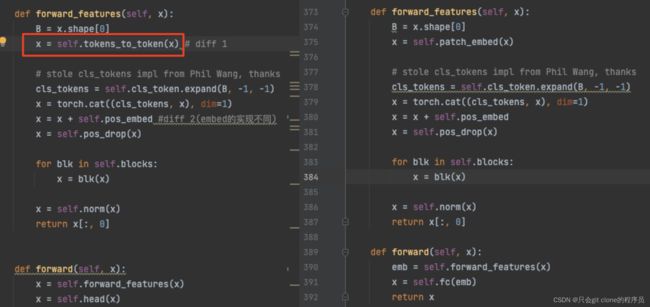
ok接下来从T2T module开始分析!
T2T-module
为了方便观察,传入网络的tensor的shape为(1,3,224,224)
1、首先进行Unfold的操作,注意nn.Unfold和nn.functional.unfold是两个不同的函数,实现的功能不一样。
代码对应:
input_shape:(1,3,224,224)
self.soft_split0 = nn.Unfold(kernel_size=(7, 7), stride=(4, 4), padding=(2, 2))
x = self.soft_split0(x).transpose(1, 2)
output_shape:(1,3136,147)
Unfold就是对图像进行滑窗取窗口里的值,相当于卷积的“卷”部分。
- 首先padding=2原图外圈加两层0,所以input的尺寸变成(1,3,228,228)
- 用size为7stride为4的窗口可以遍历228一共(228-7)/4=56次(向上取整,所以这里padding改成3其实也是ok的,(230-7)/4=56)
- 所以对于整张图可以遍历56*56=3136次,就算出了output的第二个维度
- 每次遍历窗口大小是77的,因为原图有3个通道,所以一次遍历的点总共是77*3=147个,就算出了output的第三个维度。
对应的论文图示:
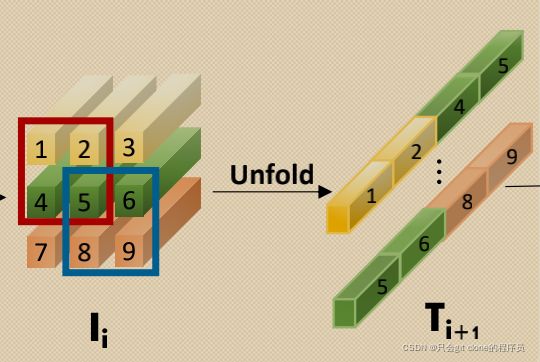
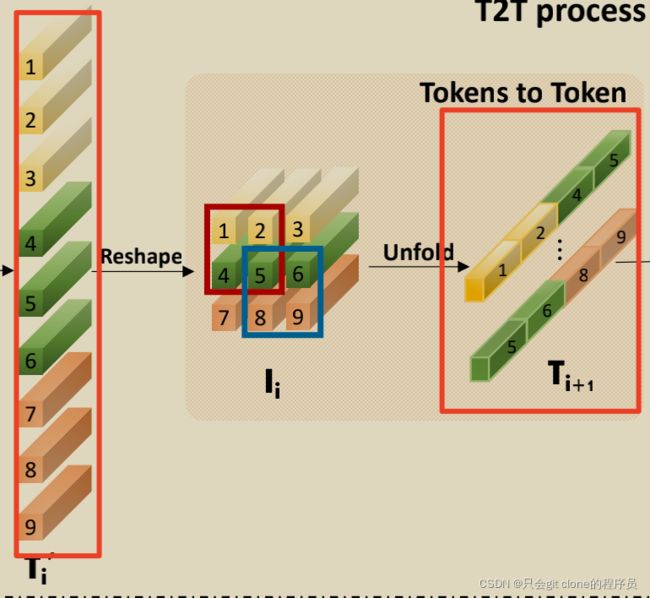
相当于 T i + 1 T_{i+1} Ti+1有3136根这样的条,每条的长度是147.
所以“根数”变少了,长度变长了:
2、然后把(1,3136,147)送入到t2t-transformer-encoder中,目的就是计算3136"根"长度147的"条"和"条"之间的attention! 结构和ViT的transformer-encoder差不多,可以参考他的forward函数:
def forward(self, x):
# input_shape:(1,3136,147)
x = self.norm1(x)
# shape:(1,3136,147)
x = self.single_attn(x)
# shape:(1,3136,64)
x = x + self.mlp(self.norm2(x))
# out_shape:(1,3136,64)
return x
ViT的transformer encoder结构如下:
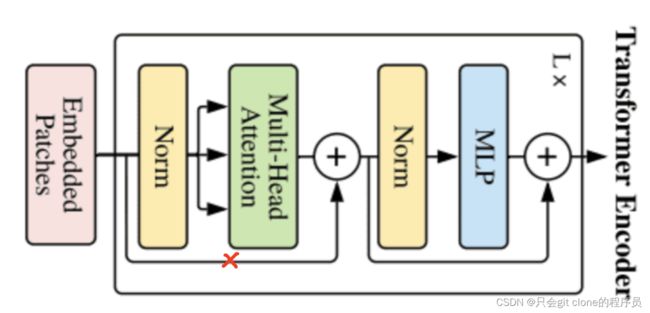
有一丢丢不一样就是少了input和attention相加的shortcut,然后这个single_attn的实现也和ViT有点不同,文章末最后再分析single_attn。
为什么少了这个shortcut呢,因为作者再single_attn里面调整了输出的shape,输入的shape当然是Unfold得到的(1,3136,147),过single_attn输出的shape是(1,3136,64),所以不可以用short cut相加啦~
3、通过single_attn之后我们得到(1,3136,64)的tensor,
根据作者的论文描述T2T模块里面使用了两次Unfold和t2t-transformer-encoder,
因此第二次执行Unfold再执行t2t-transformer-encoder之前需要把(1,3136,64)还原成四维:
(1,3136,64)->(1,56,56,64)->(1,64,56,56)
第一维度还是batchsize,第二维度是通道数,原来彩色图片是3通道,这个tensor是64通道的,56*56相当于是图片的长宽。
和第一次的输入对比:
(bs,C,H,W)
↓
第一次的输入:(1,3,224,224)
第二次的输入:(1,64,56,56)
那么这样就可以继续做Unfold加t2t-transformer-encoder了!!!
4、第二次Unfold加t2t-transformer-encoder过程一样,输入的tensor是(1,64,56,56)输出的是(1,784,64),就是得到784“根”长度为64的“条”。过程不赘述了。
5、T2Tmodule经过两个Unfold和t2t-transformer-encoder之后还加了些操作,感觉目的是降低特征的维度,操作如下:
input_shape(1,784,64)
转四维:torch.Size([1, 64, 28, 28])
Unfold:torch.Size([1, 196, 576])
FC层降维:torch.Size([1, 196, 384])
应该是对应图中的fix token部分:

ViT Part
上一小节我们得到了T2T module输出的tokens,shape为(1,196,384)分别对应(bs,num_tokens,dim)
接下来的操作基本等同ViT:
1、创建相同shape的cls token用于分类:
cls_tokens = self.cls_token.expand(B,-1,-1)
2、将分类的token和图片的token拼接:
x = torch.cat((cls_tokens, x), dim=1)
拼接后的shape(1,197,384)
3、矩阵加位置编码:
x = x + self.pos_embed
shape不变
4、加drop path
x = self.pos_drop(x)
shape不变
5、送入transformer encoder
for blk in self.blocks:
x = blk(x)
6、norm以及返回分类token
x = self.norm(x)
return x[:, 0] # shape (1, 384)
对应图中:

这里也有点点不同,作者搜索了各种网络结构发现,用深且窄的结构可以提高ViT网络特征的丰富性,所以例如T2T-ViT-14有14个transformer layer输出的dim是384,对比ViT-B/16(12个transformer layer输出的dim768),parameters and FLOPs都是它的三分之一.
single_attn
原理就是单头的attention,但是!将输入的x经过fc得到q,k,v的时候,这个v要留着和最后输出的结构捷径相加:y = v + self.dp(self.proj(y)),这个捷径相加的目的应该是代替原transformer encoder中norm前的特征和multi head attention输出shortcut相加(对应本博客第六张transformer encoder图中打岔的那条线!!!)
def single_attn(self, x):
k, q, v = torch.split(self.kqv(x), self.emb, dim=-1)
kp, qp = self.prm_exp(k), self.prm_exp(q) # (B, T, m), (B, T, m)
D = torch.einsum('bti,bi->bt', qp, kp.sum(dim=1)).unsqueeze(dim=2) # (B, T, m) * (B, m) -> (B, T, 1)
kptv = torch.einsum('bin,bim->bnm', v.float(), kp) # (B, emb, m)
y = torch.einsum('bti,bni->btn', qp, kptv) / (D.repeat(1, 1, self.emb) + self.epsilon) # (B, T, emb)/Diag
# skip connection
y = v + self.dp(self.proj(y)) # same as token_transformer in T2T layer, use v as skip connection
return y
作者动机里说的,ViT冗余的attention主干网络难以学得丰富的特征应该就是改动了这里的multi head attention为single attention!