Transformer主干网络——TNT保姆级解析
前言
论文地址:arxiv
代码地址:github
接收单位:NeurIPS 2021
系列文章
Transformer主干网络——ViT保姆级解析
Transformer主干网络——DeiT保姆级解析
Transformer主干网络——T2T-ViT保姆级解析
Transformer主干网络——TNT保姆级解析
Transformer主干网络——PVT_V1保姆级解析
Transformer主干网络——PVT_V2保姆级解析
Transformer主干网络——Swin保姆级解析
Transformer主干网络——PatchConvNet保姆级解析
持续更新…
动机
作者出发点也是ViT的Patch embed的不足(ViT留的这个坑真的是给后人留了发论文的机会…),作者将一张图片比作文章,一篇文章由句子(patchs)构成,一个句子由单词(pixels)构成。以往的attention只对句子和句子间的关系进行建模,作者认为句子内单词和单词间的关系也不可以忽视。
- 基于以上的动机作者设计了transformer in transformer的结构,相当于transformer嵌套,内层的transformer用来建模句子内单词和单词间的attention,外层的transformer用来建模句子和句子间的attention。
- 因为引入了TNT嵌套的transformer结构所以作者设计了针对TNT的位置编码。
网络分析
首先看下完整的结构示意图,源自作者论文:
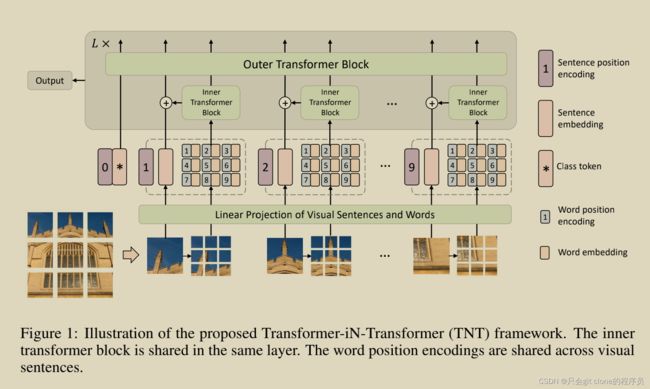
为了方便分析,本文给网络输入的数据大小为(1,3,224,224)
1、对于输入的224 * 224的图像,作者先执行了nn.Unfold的操作:
self.unfold = nn.Unfold(kernel_size=patch_size=16, stride=patch_size=16)
# input_shape (1,3,224,224)
x = self.unfold(x)
# output_shape (1,768,196)
这里196=14*14,196表示用16*16的patch可以遍历224*224次数(224/16 * 224/16)
然后768=16*16*3,前两个16是一个patch的长宽,3是彩色的三通道。相当于每个patch的pixel数。
这一步Unfold相当于卷积的“卷”过程用滑窗取出所有的块。
那么对应到图片上就是第一步将原图用分割成很多个patch了:

2、图片转单词级别的tokens:
self.proj = nn.Conv2d(in_chans, inner_dim, kernel_size=7, padding=3, stride=inner_stride)
# input_shape (1,196,768)
x = x.transpose(1, 2).reshape(B * self.num_patches, C, *self.patch_size)
# shape (196,3,16,16)
x = self.proj(x)
# shape (196,40,4,4)
x = x.reshape(B * self.num_patches, self.inner_dim, -1).transpose(1, 2)
# output_shape (196,16,40)
(196,3,16,16) 这个很好理解这是196个patch,每个patch是彩色的所以3通道,长宽是16
(196,40,4,4)这是卷积后的结果
(196,16,40)是变形后的结构,可以理解一张图有196个句子级别的tokens,每个句子级别的token有16个单词级别的tokens,每个单词级别的token的dim是40.
以上的操作得到了单词级别的tokens,对应图中所有的圈起来部分:
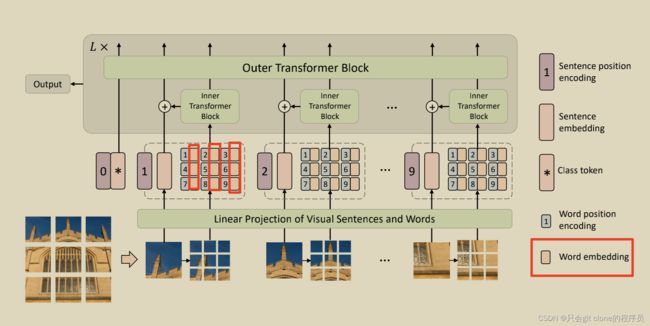
3、单词级别的tokens矩阵加上位置编码:
inner_tokens = self.patch_embed(x) + self.inner_pos
按位相加shape不变!
这个inner_pos和ViT一样的,硬训一个位置编码。
4、图片转句子级别的tokens:
由于已经有单词级别的tokens了所以句子级别的tokens可以直接由单词级别的tokens组成:
self.proj_norm1 = norm_layer(num_words * inner_dim)
self.proj = nn.Linear(num_words * inner_dim, outer_dim)
self.proj_norm2 = norm_layer(outer_dim)
# input_shape (196, 16, 40)
outer_tokens = self.proj_norm2(self.proj(self.proj_norm1(inner_tokens.reshape(B, self.num_patches, -1))))
# output_shape (1, 196, 640)
(1, 196, 640)就是一张图由196个句子级别的tokens构成,每个tokens的dim是640
那么上述就完成了本文最重要的部分,组成句子级别的tokens和单词级别的tokens!对应图示:
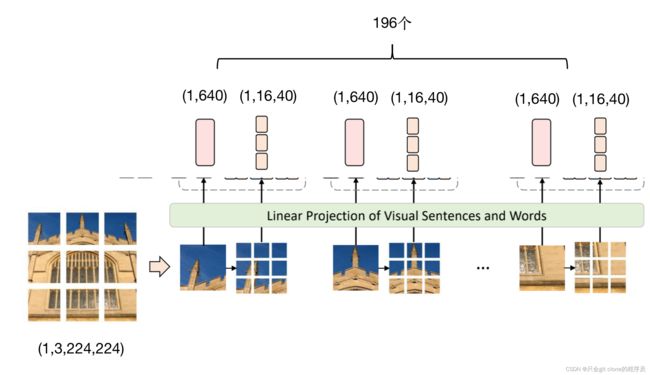
5、句子级别的tokens拼接分类头用于分类:
# input_shape (1,196,640)
outer_tokens = torch.cat((self.cls_token.expand(B, -1, -1), outer_tokens), dim=1)
# output_shape (1,197,640)

6、句子级别的tokens矩阵加上位置编码:
outer_tokens = outer_tokens + self.outer_pos
按位相加shape不变!
这个outer_pos和ViT一样的,硬训一个位置编码。
outer_tokens = self.pos_drop(outer_tokens)
加drop path
7、接下来就是把word tokens和sentence tokens一起送到block中,
这个block和ViT的block一样,但是因为这里的输出有两种tokens,
所以有一下的变动,看图!整个block的返回是红色圈出来的两个部分!
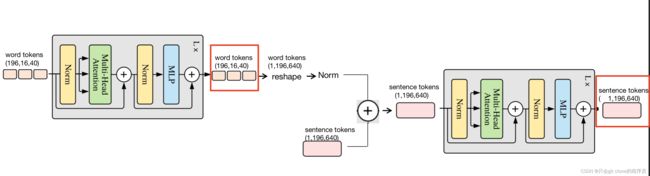
完结撒花~
再好的模型,也得经得起业务的考验,自己数据集上的实验效果会在后续更新出…
完整测试代码
# 2021.06.15-Changed for implementation of TNT model
# Huawei Technologies Co., Ltd.