Python--numpy 应用案例
文章目录
- 1. 需要分析的文件
- 2. 读取文件
- 3. 分析数据
- 3.1 平均值、最大值、最小值
- 3.2 数据占比统计
- 3.3 数据数量统计
- 4. 总代码
1. 需要分析的文件
【需要分析的文件链接】

2. 读取文件
import numpy as np
def load_csv():
"""
加载 CustomerSurvival.csv 文件
并根据文件中的数据,创建一个 ndarray 数组
:return: 返回创建的 ndarray 数组
"""
# 表头
header = []
# 数据
datas = []
# 以读取的方式打开文件
with open('CustomerSurvival.csv', 'r') as f:
for index, line in enumerate(f.readlines()):
# 第一行为表头单独处理
if index == 0:
# 每行后面都有一个换行符,裁去换行符
header = line[:-1].split(',')
else:
datas.append(tuple(line[:-1].split(',')))
# 构建 ndarray 数组
result = np.array(datas, dtype={'names': header, 'formats': ['f8', 'f8', 'f8', 'f8', 'f8', 'f8']})
return result
data = load_csv()
print(data.shape, data[0])

3. 分析数据
3.1 平均值、最大值、最小值
求 extra_time、extra_flow、use_month 的平均值、最大值、最小值。
print('extra_time')
extra_time = data['extra_time']
print('avg:', sum(extra_time) / len(extra_time))
print('max:', max(extra_time))
print('min:', min(extra_time))
print('extra_flow')
extra_flow = data['extra_flow']
print('avg:', sum(extra_flow) / len(extra_flow))
print('max:', max(extra_flow))
print('min:', min(extra_flow))
print('use_month')
use_month = data['use_month']
print('avg:', sum(use_month) / len(use_month))
print('max:', max(use_month))
print('min:', min(use_month))

3.2 数据占比统计
统计所有有额外剩余通话时长的人数占总人数的比例。
统计所有有额外剩余流量的人数占总人数的比例。
print('有额外剩余通话时长的人数占总人数的比例: ')
extra_time = data['extra_time']
# 使用掩码
# 取出 extra_time 大于 0 的数据元素
extra_time_h = extra_time[extra_time > 0]
print(len(extra_time_h) / len(extra_time))
print('有额外剩余流量的人数占总人数的比例: ')
extra_flow = data['extra_flow']
# 使用掩码
# 取出 extra_flow 大于 0 的数据元素
extra_flow_h = extra_flow[extra_flow > 0]
print(len(extra_flow_h) / len(extra_flow))

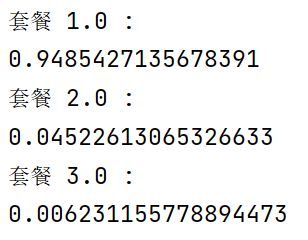
3.3 数据数量统计
统计每一类套餐的人数与总人数的占比。
# 获取套餐的种类
# 利用集合去重
pack_type = data['pack_type']
types = set(pack_type)
# 计算每种套餐的占比
for t in types:
print('套餐', t, ':')
# 获取当前套餐的个数
l = len(pack_type[pack_type == t])
print(l / len(pack_type))
4. 总代码
import numpy as np
def load_csv():
"""
加载 CustomerSurvival.csv 文件
并根据文件中的数据,创建一个 ndarray 数组
:return: 返回创建的 ndarray 数组
"""
# 表头
header = []
# 数据
datas = []
# 以读取的方式打开文件
with open('CustomerSurvival.csv', 'r') as f:
for index, line in enumerate(f.readlines()):
if index == 0:
header = line[:-1].split(',')
# print(header)
else:
datas.append(tuple(line[:-1].split(',')))
result = np.array(datas, dtype={'names': header, 'formats': ['f8', 'f8', 'f8', 'f8', 'f8', 'f8']})
return result
data = load_csv()
# print(data.shape, data[0])
# print('extra_time')
# extra_time = data['extra_time']
# print('avg:', sum(extra_time) / len(extra_time))
# print('max:', max(extra_time))
# print('min:', min(extra_time))
#
# print('extra_flow')
# extra_flow = data['extra_flow']
# print('avg:', sum(extra_flow) / len(extra_flow))
# print('max:', max(extra_flow))
# print('min:', min(extra_flow))
#
# print('use_month')
# use_month = data['use_month']
# print('avg:', sum(use_month) / len(use_month))
# print('max:', max(use_month))
# print('min:', min(use_month))
# print('有额外剩余通话时长的人数占总人数的比例: ')
# extra_time = data['extra_time']
# # 使用掩码
# extra_time_h = extra_time[extra_time > 0]
# print(len(extra_time_h) / len(extra_time))
#
# print('有额外剩余流量的人数占总人数的比例: ')
# extra_flow = data['extra_flow']
# # 使用掩码
# extra_flow_h = extra_flow[extra_flow > 0]
# print(len(extra_flow_h) / len(extra_flow))
# 获取套餐的种类
# 利用集合去重
pack_type = data['pack_type']
types = set(pack_type)
# 计算每种套餐的占比
for t in types:
print('套餐', t, ':')
# 获取当前套餐的个数
l = len(pack_type[pack_type == t])
print(l / len(pack_type))